這篇文章是c++入門基礎的第一站的中篇,涉及的知識點函數重載:函數重載的原理--名字修飾引用:概念、特性、使用場景、常引用、傳值、傳引用效率比較的知識點

目錄
5. 函數重載 (續)
C++支持函數重載的原理--名字修飾(name Mangling)
為什么C++支持函數重載,而C語言不支持函數重載呢?
6. 引用
引用概念
關于引用的應用:
引用特性
🚩引用在定義時必須初始化
🚩一個變量可以有多個引用
🚩引用一旦引用一個實體,再不能引用其他實體
使用場景
傳值、傳引用效率比較
值和引用的作為返回值類型的性能比較
關于順序表的讀取與修改
c語言接口
Cpp的接口設計:
常引用
5. 函數重載 (續)
C++支持函數重載的原理--名字修飾(name Mangling)
編譯器是如何編譯的?
Test.cpp
預處理頭文件展開/宏替換/去掉注釋/條件編譯
Test.i
編譯檢查語法,生成匯編代碼(指令級代碼) -- 右擊鼠標打開反匯編
Test.s
匯編將匯編代碼生成二進制機器碼
Test.o
鏈接合并鏈接,生成可執行程序(a.out / xxx.exe)
在整個編譯的過程中涉及到的一個問題是什么呢?
????????在一個項目里面寫了一個stack.h(棧定義的各種接口)和stack.cpp ,這些各種接口不在Test.o內,而在stack.o內,那么怎么去這里找呢。那就涉及到名字去找地址,在鏈接的時候怎么用名字去找地址呢?
?C語言的特點呢 -- 直接用函數名去充當函數的名字
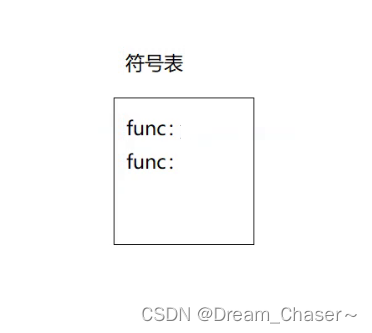
? ? ? ? 這樣的后果就是自己都區分不開來,所以C語言是不允許重名的。
那么C++是如何這塊的問題呢?如何把兩個同名的但參數類型順序不一樣的函數區分開來呢?
🎯 那就是函數名修飾規則解決這個問題
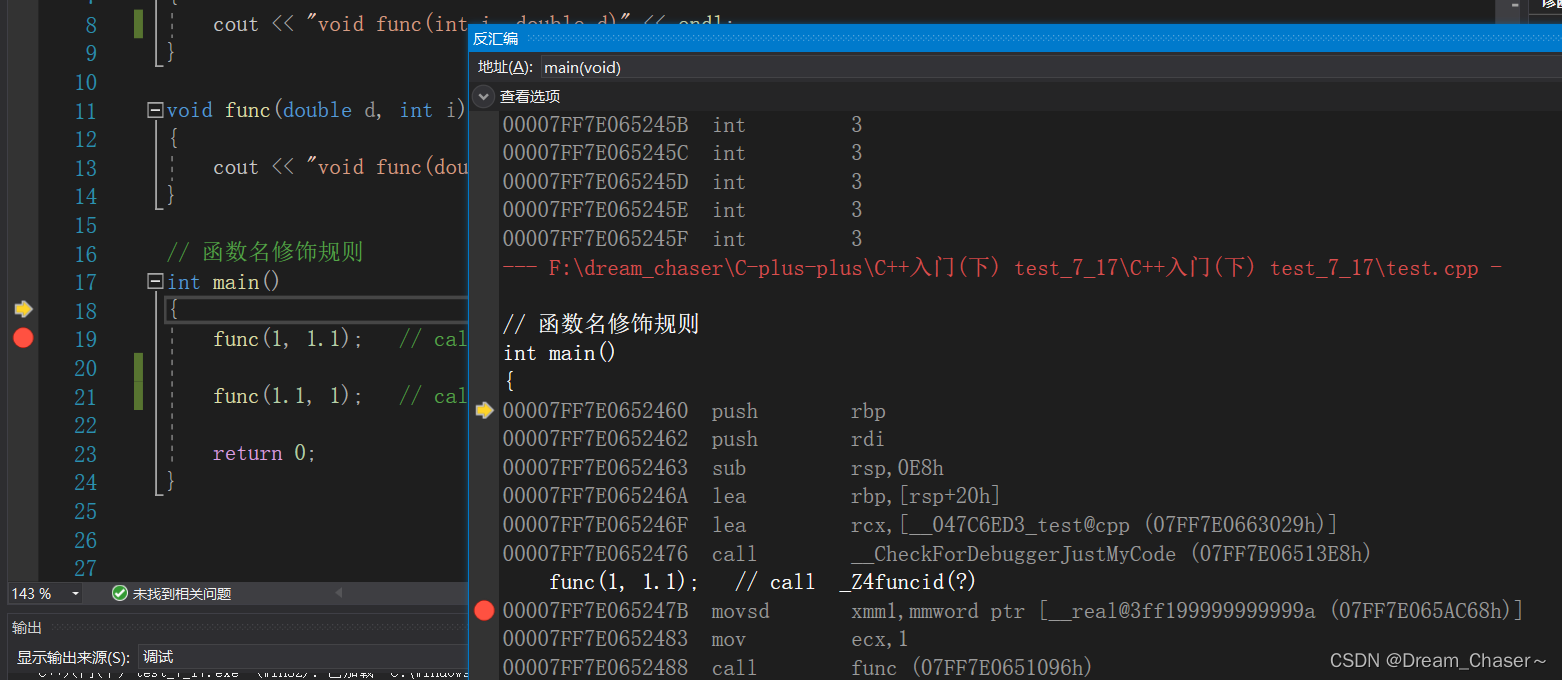
當函數只有聲明沒有定義的時候,就會出現以下的鏈接錯誤
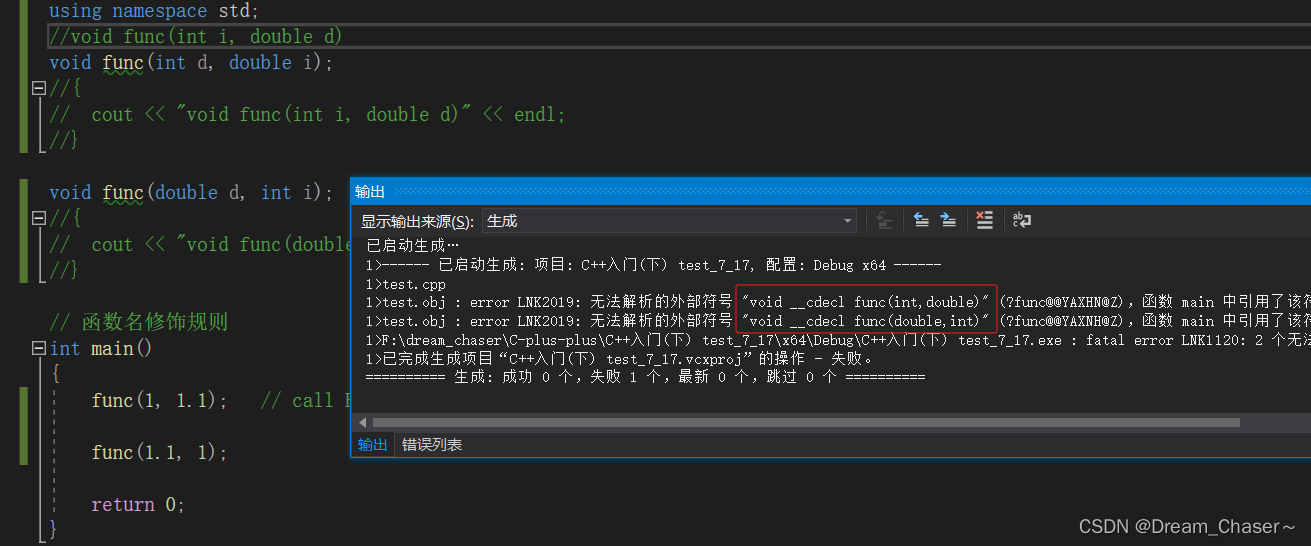
? ? ? ? 🌼當函數只有定義的時候,沒有實現的時候,它就沒有一堆匯編指令,沒有指令就不能生成地址(就沒有建立函數棧幀的過程,寄存器沒有存地址)。所以在符號表里面拿這個名字去找的時候就找不到,以下是修飾以后的函數名,本質上它是用類型帶入這個名字里面去了(函數修飾規則)

而C語言是直接用函數名去找:

在linux環境底下去看:
以下兩張圖均是函數名修飾規則

? ? ? ? Linux底下:c++區分函數不同的依據是去找函數的地址(本質也就是第一句指令的地址),找到地址之后,將其函數名修飾成特殊函數名:
<_Z4funcid> 意思是:四個字節,func(int,double)
<_Z4funcdi> 意思是:四個字節,func(double,int)
🍔在符合表里面:
? ? ? ? 用一個獨特的符號去代表一個類型,跟據類型的個數不同、類型不同、類型的順序不同,修飾出了的名字就是不一樣的,所以根據這點,就可以在函數名相同的情況下區分不同的函數。

vs2019底下:
void __cdecl func(int,double)" (?func@@YAXHN@Z)
void __cdecl func(double,int)" (?func@@YAXNH@Z)
因為這兩個函數雖然函數名字相同,但是函數類型的順序不同,所以編譯器會根據情況修飾成特殊的函數名
問題:
函數名修飾規則帶入返回值,返回值不能能否構成重載? 不能。

為什么C++支持函數重載,而C語言不支持函數重載呢?

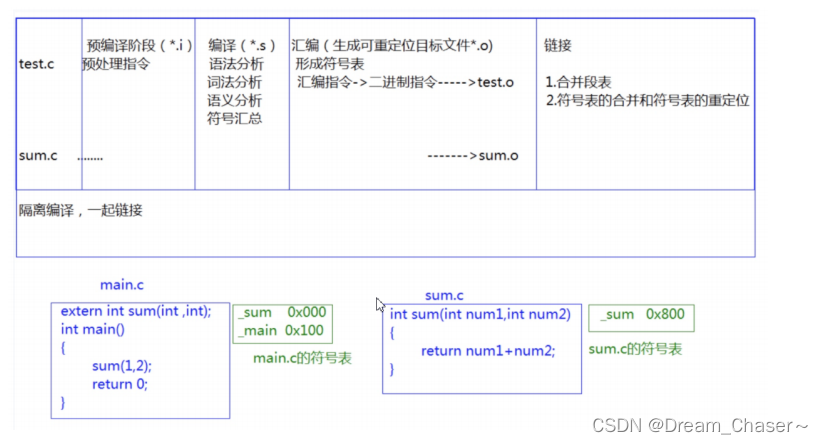 1.實際項目通常是由多個頭文件和多個源文件構成,而通過C語言階段學習的編譯鏈接,我們可以知道,【當前a.cpp中調用了b.cpp中定義的Add函數時】,編譯后鏈接前,a.o的目標文件中沒有Add的函數地址,因為Add是在b.cpp中定義的,所以Add的地址在b.o中。那么怎么辦呢?2. 所以鏈接階段就是專門處理這種問題,鏈接器看到a.o調用Add,但是沒有Add的地址,就會到b.o的符號表中找Add的地址,然后鏈接到一起。(老師要帶同學們回顧一下)3. 那么鏈接時,面對Add函數,鏈接接器會使用哪個名字去找呢?這里每個編譯器都有自己的函數名修飾規則。4. 由于Windows下vs的修飾規則過于復雜,而Linux下g++的修飾規則簡單易懂,下面我們使用了g++演示了這個修飾后的名字。5. 通過下面我們可以看出gcc的函數修飾后名字不變。而g++的函數修飾后變成:【_Z+函數長度+函數名+類型首字母】
1.實際項目通常是由多個頭文件和多個源文件構成,而通過C語言階段學習的編譯鏈接,我們可以知道,【當前a.cpp中調用了b.cpp中定義的Add函數時】,編譯后鏈接前,a.o的目標文件中沒有Add的函數地址,因為Add是在b.cpp中定義的,所以Add的地址在b.o中。那么怎么辦呢?2. 所以鏈接階段就是專門處理這種問題,鏈接器看到a.o調用Add,但是沒有Add的地址,就會到b.o的符號表中找Add的地址,然后鏈接到一起。(老師要帶同學們回顧一下)3. 那么鏈接時,面對Add函數,鏈接接器會使用哪個名字去找呢?這里每個編譯器都有自己的函數名修飾規則。4. 由于Windows下vs的修飾規則過于復雜,而Linux下g++的修飾規則簡單易懂,下面我們使用了g++演示了這個修飾后的名字。5. 通過下面我們可以看出gcc的函數修飾后名字不變。而g++的函數修飾后變成:【_Z+函數長度+函數名+類型首字母】
- 采用
結論:在linux下,采用gcc編譯完成后,函數名字的修飾沒有發生改變。
- 采用C語言編譯器編譯后結果
結論:在linux下,采用g++編譯完成后,函數名字的修飾發生改變,編譯器將函數參數類型信息添加到修改后的名字中。
- Windows下名字修飾規則
對比Linux會發現,windows下vs編譯器對函數名字修飾規則相對復雜難懂,但道理都是類似的,我們就不做細致的研究了。6. 通過這里就理解了C語言沒辦法支持重載,因為同名函數沒辦法區分。而C++是通過函數修飾規則來區分,只要參數不同,修飾出來的名字就不一樣,就支持了重載。7. 如果兩個函數函數名和參數是一樣的,返回值不同是不構成重載的,因為調用時編譯器沒辦法區分。



6. 引用
引用概念
????????引用不是新定義一個變量,而 是給已存在變量取了一個別名 ,編譯器不會為引用變量開辟內存空間,它和它引用的變量共用同一塊內存空間。
????????
????????C++為了在拓展語法的過程中,為了防止創新符號太多不好記憶,直接沿用C語言的符號,讓其一個符號賦予了多重意思,&在這邊不是取地址的意思,而是引用操作符
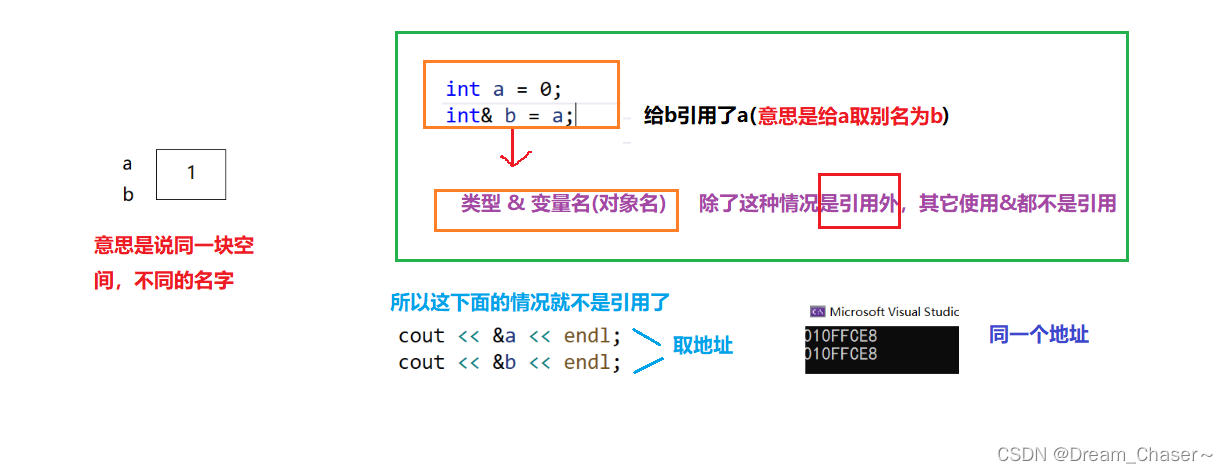
當b++時,a也會同時++,當兩條語句都++時,那么這個值就變為2
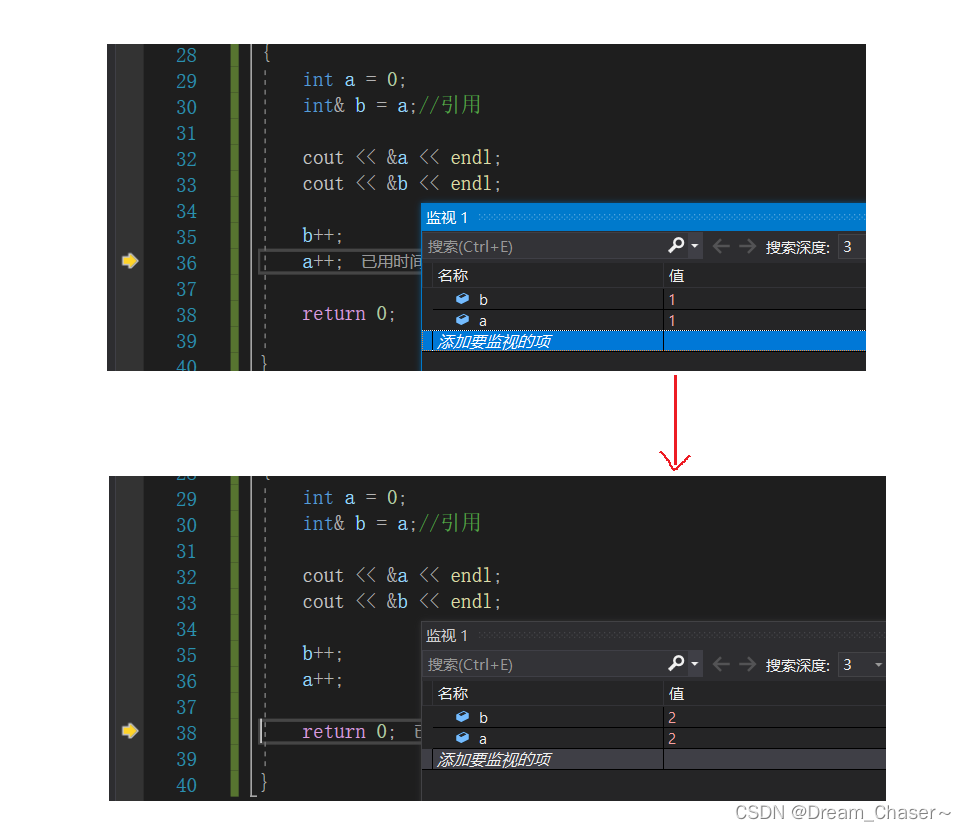
代碼實現:
int main()
{int a = 0;int& b = a;//引用cout << &a << endl;cout << &b << endl;return 0;}輸出:
關于引用的應用:
void swap(int& x1, int& x2){int tmp = x1;x1 = x2;x2 = tmp;}int main(){int size;int x = 0, y = 1;swap(x,y);printf("%d %d", x, y);}執行:

int TreeSize(struct TreeNode* root){//寫法一if (root == NULL)return 0;//寫法二return TreeSize(root->left)+ TreeSize(root->right)+ 1;}void _preorder(struct TreeNode* root, int* a, int& pi){if (root == NULL)return;//用指針的方式是為了不在不同棧幀內創建ia[pi] = root->val;pi++;_preorder(root->left, a, pi);_preorder(root->right, a, pi);}int* preorderTraversal(struct TreeNode* root, int& returnSize){int size = TreeSize(root);int* a = (int*)malloc(sizeof(int) * sizeof(int));int i = 0;_preorder(root,a,i);return a;}int main(){int size = 0;preorderTraversal(nullptr, size);}

引用特性
🚩引用在定義時必須初始化

🚩一個變量可以有多個引用
int main()
{int a = 0;int& b = a;int& c = a;int& d = b;//給別名取別名,實際上是同一塊空間。int x = 1;//賦值b = x;return 0;
}代碼執行變化:

🚩引用一旦引用一個實體,再不能引用其他實體
int main()
{int a = 0;int& b = a;int x = 1;int&b = x;return 0;
}代碼執行:

使用場景
傳引用返回和傳值返回:
以下的兩者返回的方式有什么區別呢?
? ? ? ? 答:這兩種情況的區別,在于傳值調用在函數銷毀時有寄存器,傳引用調用沒有寄存器保存值,因為是同一個空間,引用不同于傳值和傳址,既然直接傳的就是這個空間本身,因此既不用創建臨時拷貝,也不需要傳變量地址。而是直接變量進行賦值。
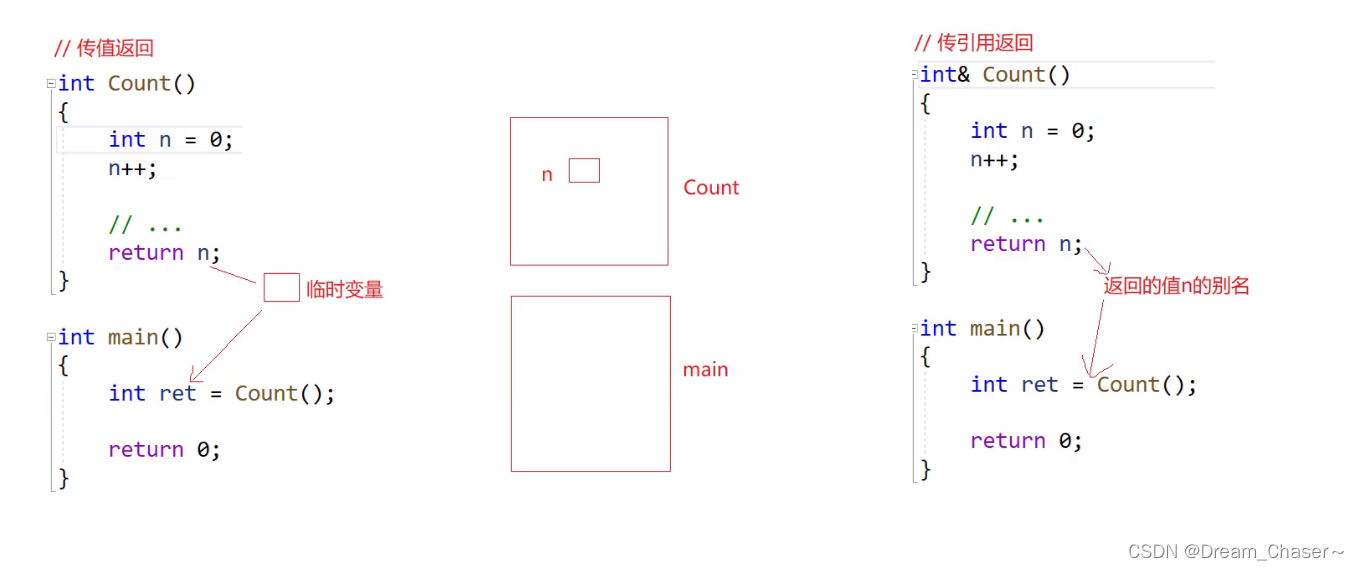
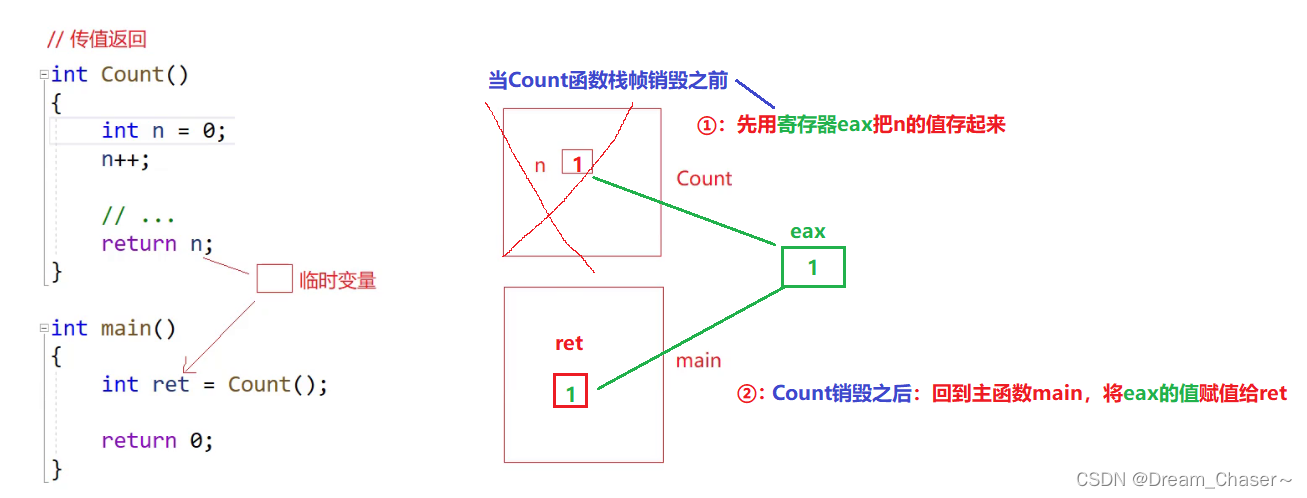
💥先來看傳值返回:
????????用了一個全局的寄存器eax把返回值保存起來,待Count函數棧幀銷毀后,回到主函數main,再將寄存器里面的值賦值給ret
💨傳引用返回:
????????這個n的別名,出了作用域就銷毀(這意味著返回的值是對已被銷毀的變量的引用),還給操作系統了,在還給操作系統的時候,可能將這塊空間里面的值給清理了,變成隨機值了。由于Count函數的返回值是無效的(引用已被銷毀),所以打印ret的值將導致未定義的行為。它可能打印1,也可能打印隨機值,或者可能導致程序崩潰。

💢那如果對代碼再修改一下呢:
????????這段代碼是非法的。當函數?Count()?執行完畢后,局部變量?n?將被銷毀,引用?ret?將會成為懸空引用(dangling reference),它指向了已經歸還給操作系統的空間,該空間里面的值可能已經被初始化為隨機值。因此,將對n的引用返回給調用函數是無效的,導致未定義的行為。
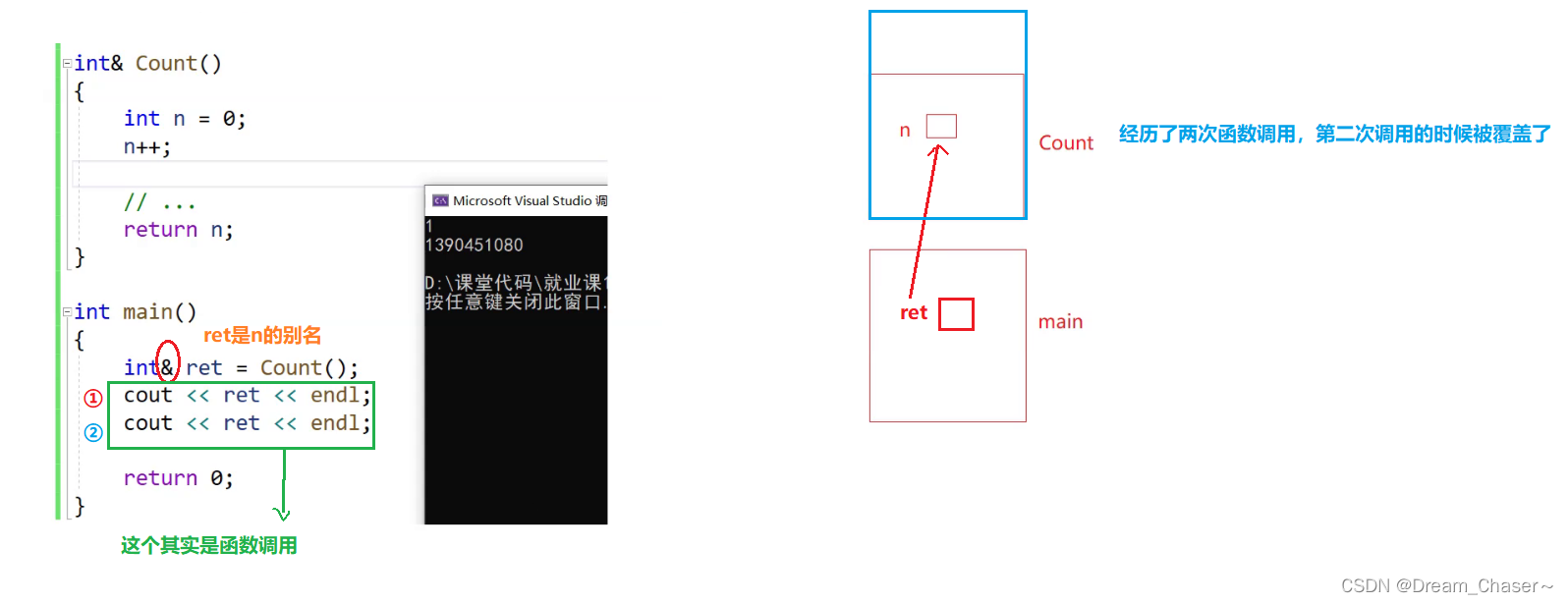
?總結:
?傳引用的第一個示例還是第二個示例中,代碼都是非法的,并且會導致未定義的行為
????????如果函數返回時,離開函數作用域后,其棧上空間已經還給系統,因此不能用棧上的空間作為引用類型返回。如果以引用類型返回,返回值的生命周期必須不受函數的限制(即比函數生命周期長)。
????????只有當出了這個作用域,這個對象還在的情況下,才可以加引用比如便用static將變量設成靜態變量,或是全局變量,函數生命周期就不會影響到引用

代碼示例:
//傳引用調用
int& Count()
{int n = 0;n++;return n;
}
int main()
{int& ret = Count();//這里打印的結果可能是1,也可能是隨機值cout << ret << endl;cout << ret << endl;return 0;
}
//傳值調用
int Count()
{int n = 0;n++;return n;
}
int main()
{int ret = Count();cout << ret << endl;cout << ret << endl;return 0;
}當變量前面有很大一塊空間被占用時,有可能不會被覆蓋:

? ? ? ? 寫一個相加兩個變量值的代碼:
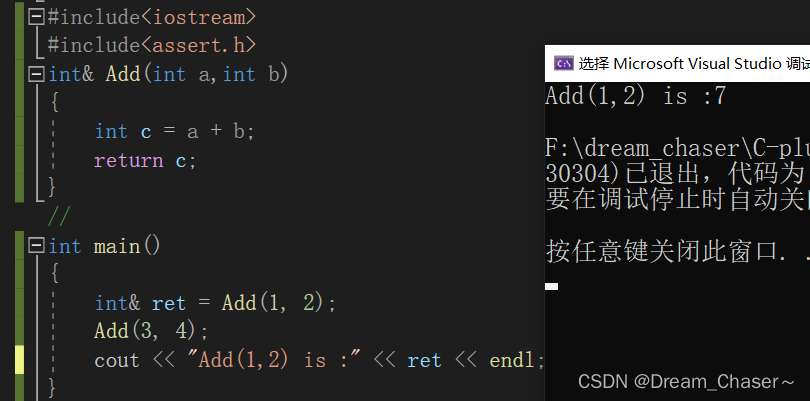
代碼實現:
?#include<iostream>
#include<assert.h>
int& Add(int a,int b)
{int c = a + b;return c;
}int main()
{int& ret = Add(1, 2);Add(3, 4);cout << "Add(1,2) is :" << ret << endl;
}解析:

????????注意:如果函數返回時,出了函數作用域,如果返回對象還在(還沒還給系統),則可以使用 引用返回,如果已經還給系統了,則必須使用傳值返回。
傳值、傳引用效率比較
傳引用傳參(任何時候都可以用)
1、提高效率
2、輸出型參數(形參的修改,影響的實參)
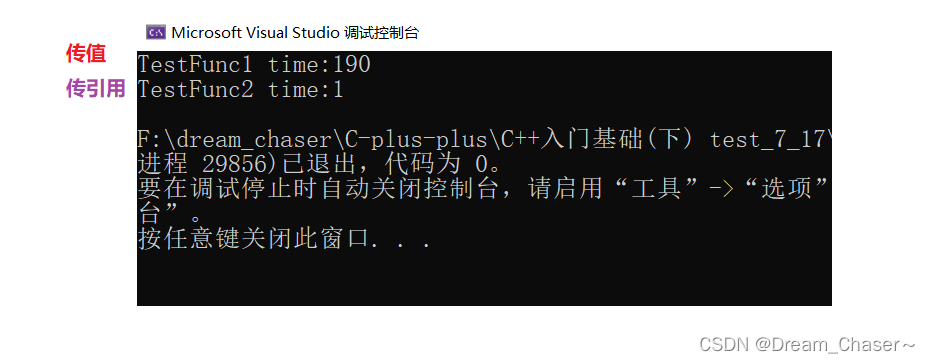
#include <time.h>
#include<iostream>struct A { int a[10000]; };
A a;//全局變量!!!
// 值返回
A TestFunc1() { return a; }//全局變量是可以使用傳引用返回的!!!// 引用返回
A& TestFunc2() { return a; }void TestReturnByRefOrValue()
{// 以值作為函數的返回值類型size_t begin1 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc1();size_t end1 = clock();// 以引用作為函數的返回值類型size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc2();size_t end2 = clock();// 計算兩個函數運算完成之后的時間cout << "TestFunc1 time:" << end1 - begin1 << endl;cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
int main()
{TestReturnByRefOrValue();return 0;
}?值和引用的作為返回值類型的性能比較
?傳引用返回(出了函數作用域對象還在才可以用)-- static修飾的,全局變量,堆空間等等
?1、提高效率
?2、修改返回對象
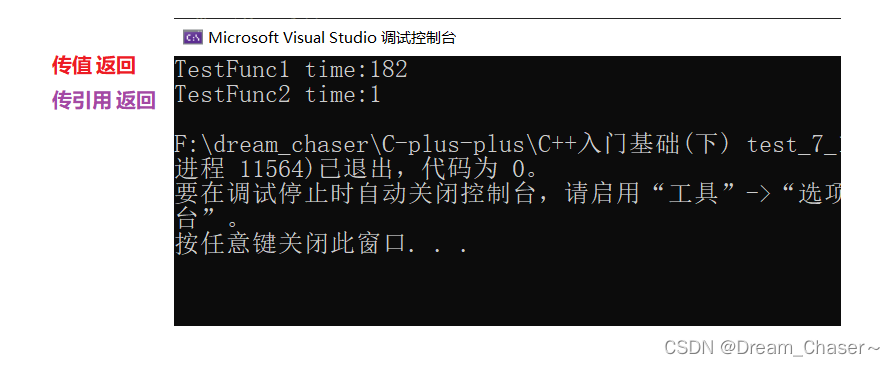
#include <time.h>
struct A { int a[10000]; };
A a;
// 值返回
A TestFunc1() { return a; }
// 引用返回
A& TestFunc2() { return a; }
void TestReturnByRefOrValue()
{// 以值作為函數的返回值類型size_t begin1 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc1();size_t end1 = clock();// 以引用作為函數的返回值類型size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc2();size_t end2 = clock();// 計算兩個函數運算完成之后的時間cout << "TestFunc1 time:" << end1 - begin1 << endl;cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
int main()
{TestReturnByRefOrValue();return 0;
}關于順序表的讀取與修改
c語言接口
struct SeqList
{int a[10];int size;
};//C的接口設計
//讀取第i個位置
int SLAT(struct SeqList* ps, int i)
{assert(i<ps->size);//防止越界//...return ps->a[i];
}
//修改第i個位置的值
void SLModify(struct SeqList* ps, int i, int x)
{assert(i< ps->size);// ...ps->a[i] = x;
}????????可以看待以上代碼,C語言實現讀取和修改結構體成員--數組元素時,是非常繁瑣的,實現功能就要編寫一個功能函數,但是如果換成c++的引用,那就可以一個函數實現兩個功能
Cpp的接口設計:

代碼示例:
CPP接口設計
//讀 or 修改第i個位置的值
#include<iostream>
#include<assert.h>
int& SLAT(struct SeqList& ps, int i)
{assert(i < ps.size);return(ps.a[i]);}
int main()
{struct SeqList s;s.size = 3;SLAT(s, 0) = 10;SLAT(s, 1) = 20;SLAT(s, 2) = 30;cout << SLAT(s, 0) << endl;cout << SLAT(s, 1) << endl;cout << SLAT(s, 2) << endl;return 0;
}特別注意:
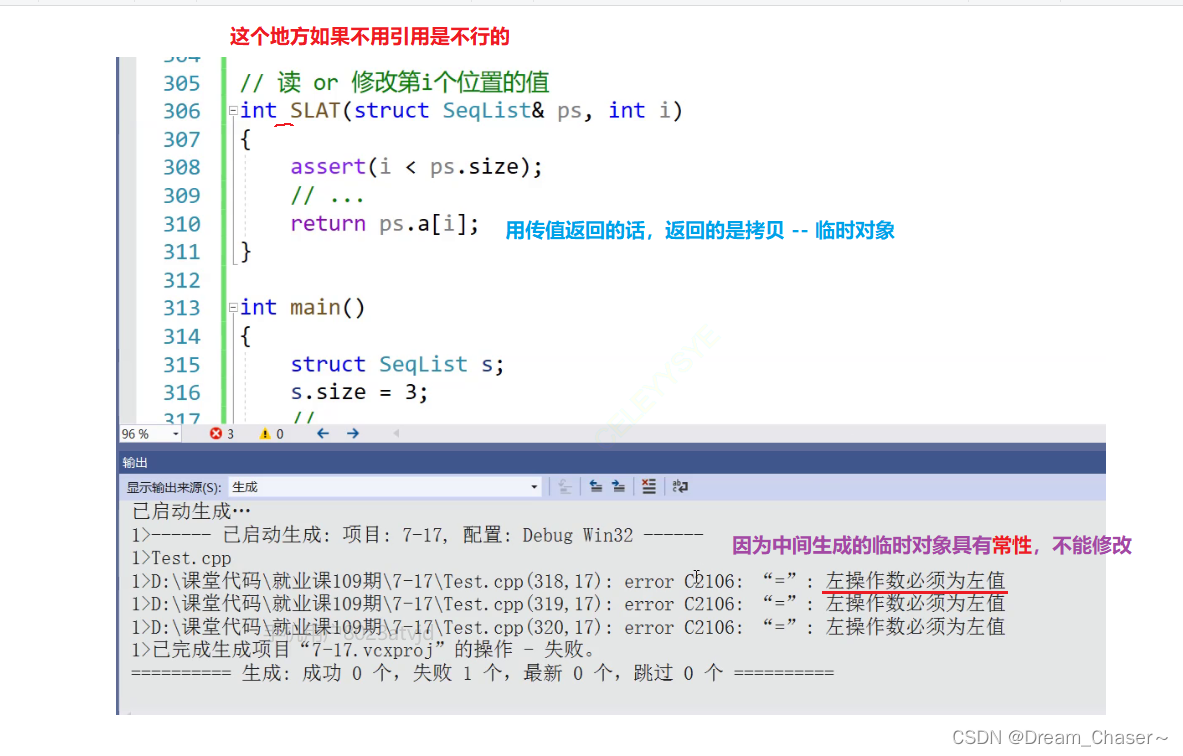
?
常引用
在引用的過程中:
1.權限可以平移
2.權限可以縮小
3.權限不能放大!!!
int main()
{const int a = 0;//權限的放大int& b = a;//這個是不行的!!!//權限的平移const int& c = a;//權限的縮小
//形象地理解: int x = 0;//齊天大圣const int& y = x;//戴上緊箍咒的孫悟空return 0;
}賦值:
int b = a;//可以的,因為這里是賦值拷貝,b修改不影響a類型轉換:
? ? ? ? 在c/c++里面有個規定:表達式轉換的時候會產生一個臨時變量,具有常性
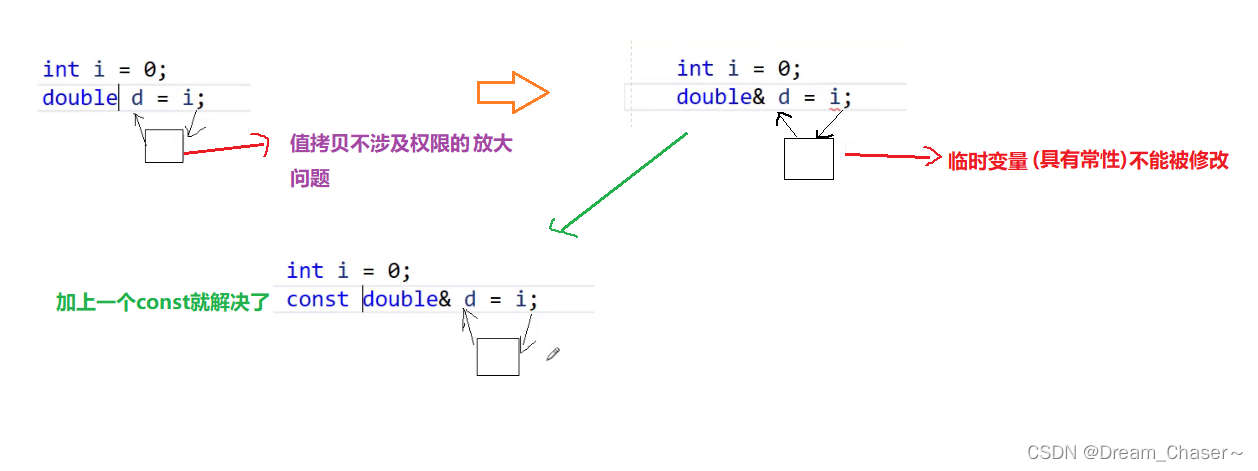
以及函數返回的時候也會產生一個臨時對象
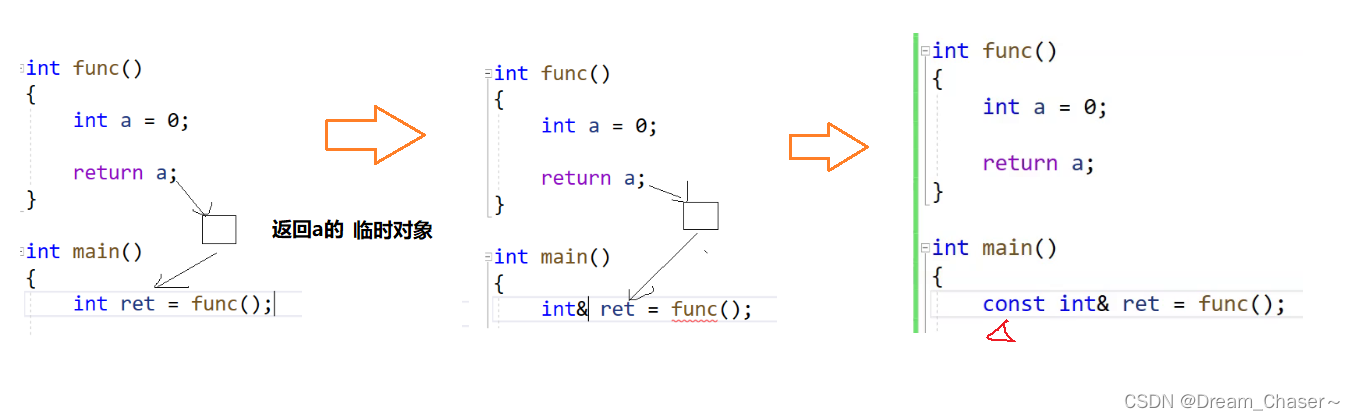
? ? ? ? 本章未結束,盡快更新下一章完結此篇。





)
)










)

