博主介紹:Java領域優質創作者,博客之星城市賽道TOP20、專注于前端流行技術框架、Java后端技術領域、項目實戰運維以及GIS地理信息領域。
🍅文末獲取源碼下載地址🍅
👇🏻 精彩專欄推薦訂閱👇🏻 歡迎點贊收藏評論拍磚........
【Docker Swarm總結】《容器技術 Docker+K8S專欄》?
【uniapp+uinicloud多用戶社區博客實戰項目】《完整開發文檔-從零到完整項目》?
【Springcloud Alibaba微服務分布式架構 | Spring Cloud】《系列教程-更新完畢》?
【SpringSecurity-從入門到精通】《學習完整筆記-附(完整demo源碼)》?
【從零開始Vue項目中使用MapboxGL開發三維地圖教程】《系列教程-不定時更新》?
【Vue.js學習詳細課程系列】《共32節專欄收錄內容???????》????????
感興趣的可以先收藏起來相關問題都可以給我留言咨詢,希望幫助更多的人。
???????
目錄
8、service 操作
8.1 task 伸縮
8.2 task 容錯
8.3 服務刪除
8.4 滾動更新
8.5 更新回滾
9、service 全局部署模式
9.1 環境變更
9.2 創建 service
9.3 task 伸縮
10、overlay 網絡
10.1 測試環境 1搭建
10.2 overlay 網絡概述
10.3 docker_gwbridg 網絡基礎信息
10.4 ingress 網絡基礎信息
10.5 宿主機的 NAT 過程
10.6 ingress_sbox 的負載均衡
10.7 VXLAN
11 Raft 算法
11.1 基礎
11.2 角色、任期及角色轉變
11.3 leader 選舉
11.4 數據同步
11.5 腦裂
11.6 Leader 宕機處理
11.7 Raft 算法動畫演示
8、service 操作
8.1 task 伸縮
根據訪問量的變化,需要在不停止服務的前提下對服務的 task 進行擴容/縮容,即對服
務進行伸縮變化。有兩種實現方式:
(1) docker service update 方式
通過 docker service update --replicas 命令可以實現對指定服務的 task 數量進行變更。
docker service lsdocker service update --replicas 4 tomcates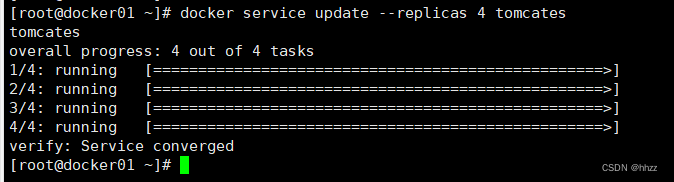
此時可以看到新增了一個 task 節點。
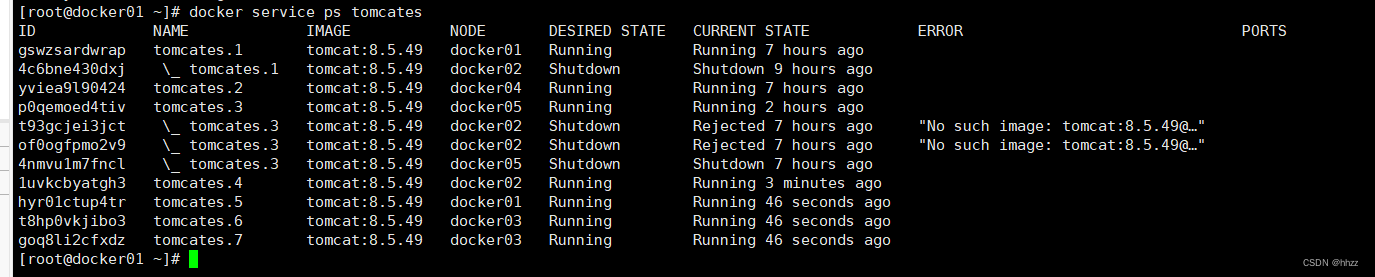
docker service ps tomcates

(2) docker service scale 方式
通過 docker service scale 命令可以為指定的服務變更 task 數量。
docker service scale tomcates=7此時可以看到新增了 3 個 task 節點。由于共有 5 臺主機,現有 7 個 task,所以就出現了
一個主機上有多個 task 的情況。docker01上有兩個tom服務分別為tom1和tom5.
當然,也可以使 task 數量減小。例如,下面的命令使 task 又變回了 3 個。
docker service scale tomcates=3這三個 task 分別在 docker01、docker04 與 docker05 主機。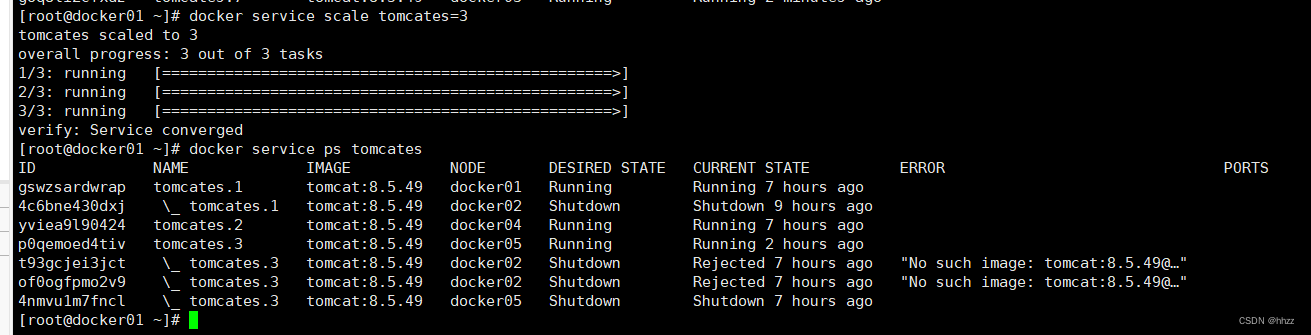
(3) 暫停節點的 task 分配
docker node update --help
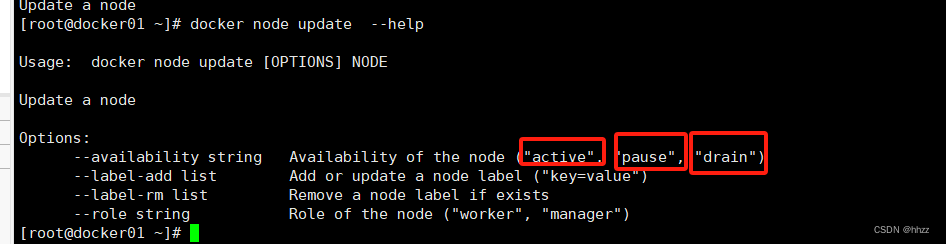
生產環境下,可能由于某主機性能不高,在進行 task 擴容時,不想再為該主機再分配更多的 task,此時可通過 pause 暫停該主機節點的可用性來達到此目的。
例如,當前 docker01、docker04 與 docker05三個主機上的tomcates 服務的 task 情況如下。

現準備將 tomcates 服務的 task 擴容為 10,但保持 docker02 節點中的 task 數量仍為 1 不變,
此時就可通過 docker node update --availability pause 命令修改 docker02 節點的可用性。
docker node update --availability pause docker02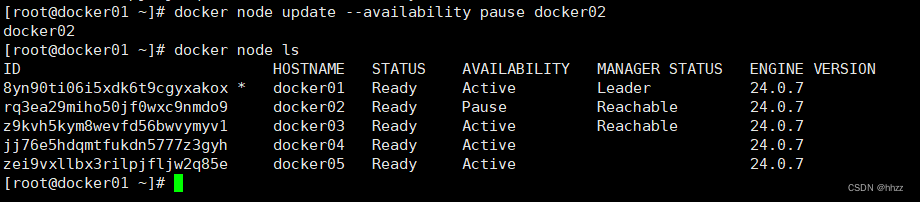
將 tomcates 服務的 task 擴容為 10。
docker service scale tomcates=10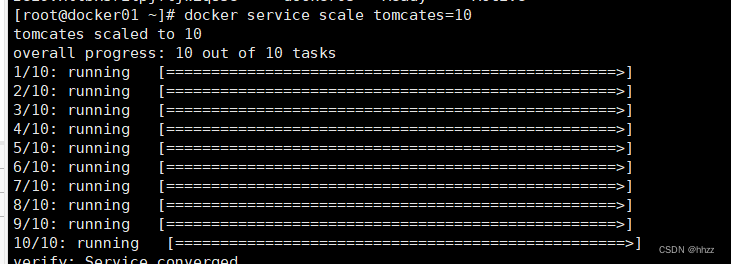
查看各節點分配的 task 情況會發現 docker02的 task 數量并未增加,其它節點主機有變化了。
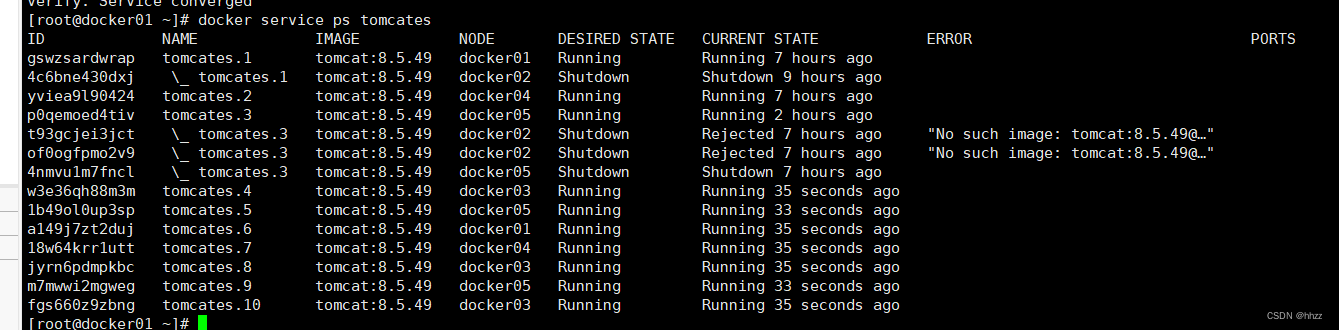
(4) 清空 task
? ? 默認情況下,manager 節點同時也具備 worker 節點的功能,可以由分發器為其分配 task。
但 manager 節點使用 raft 算法來達成 manager 間數據的一致性,對資源較敏感。因此,阻
止 manager 節點接收 task 是比較好的選擇。或者,由于某節點出現了性能問題,需要停止服務進行維修,此時最好是將該節點上的task 清空,以不影響 service 的整體性能。
通過 docker node update –availability drain 命令可以清空指定節點中的所有 task。
例如,目前各個節點的對于 tomcates服務的 task 分配情況如下:
docker service ps tomcates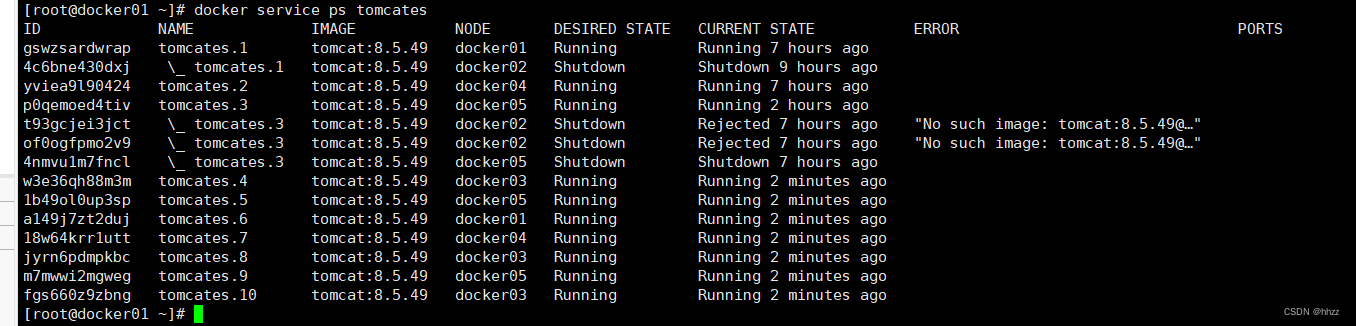
現對 docker02 與 docker05 兩個節點進行 task 清空操作。
docker node update --availability drain docker02docker node update --availability drain docker05
此時可以看到,tomcates服務的 task 總量并沒有減少,只是 docker02 與 docker05 兩個節點上
是沒有 task 的,而全部都分配到了 docker01、docker03 與 docker04 三個節點上了。這個結果就是由編排器與分發器共同維護的。
8.2 task 容錯
當某個 task 所在的主機或容器出現了問題時,manager 的編排器會自動再創建出新的
task,然后分發器會再選擇出一臺 available node 可用節點,并將該節點分配給新的 task。
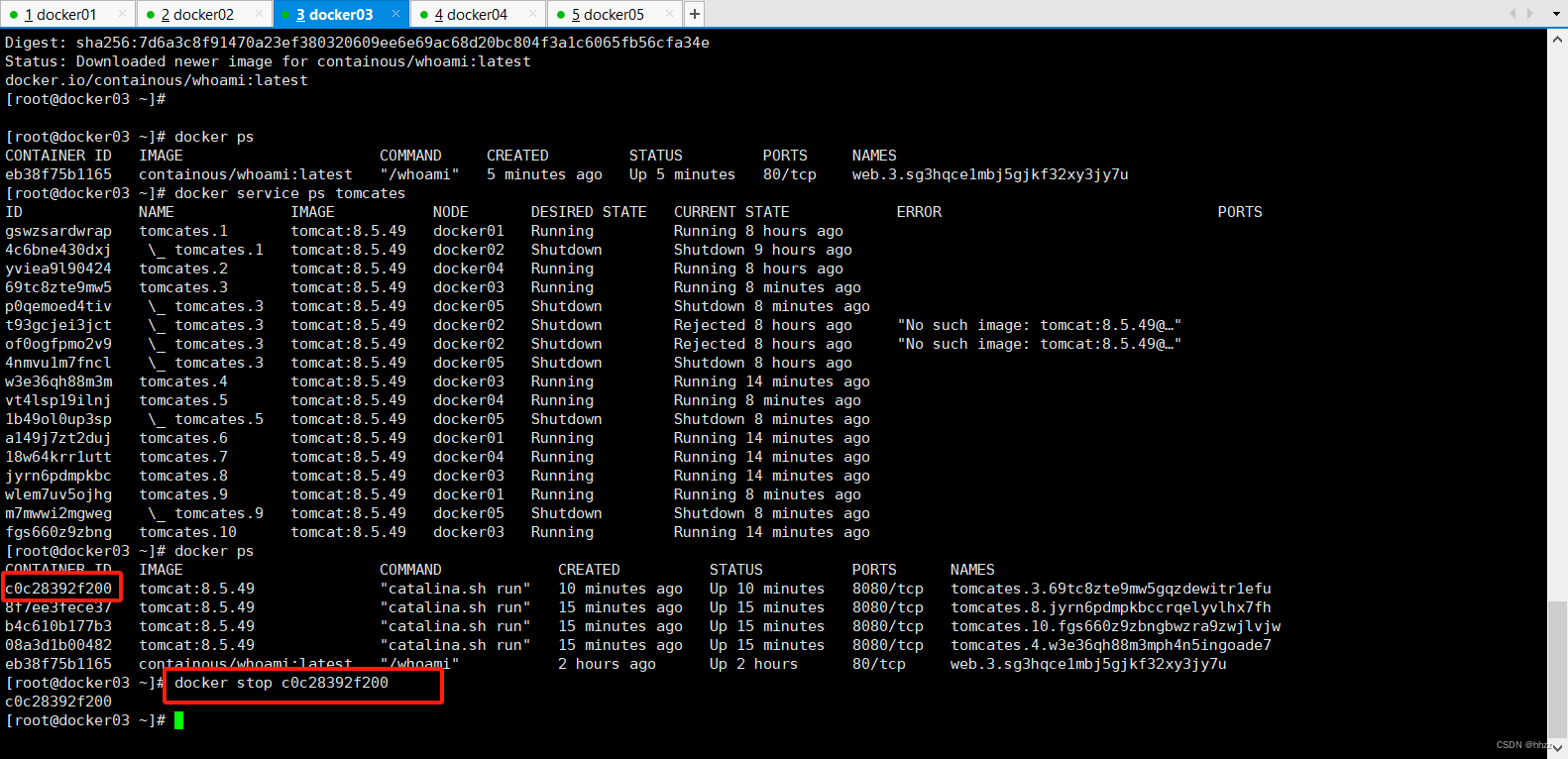
(1) 停掉容器
現在通過停掉 docker03、docker02或 docker05 中某個主機容器的方式來模擬故障情況。例
如停掉 docker03 的容器。
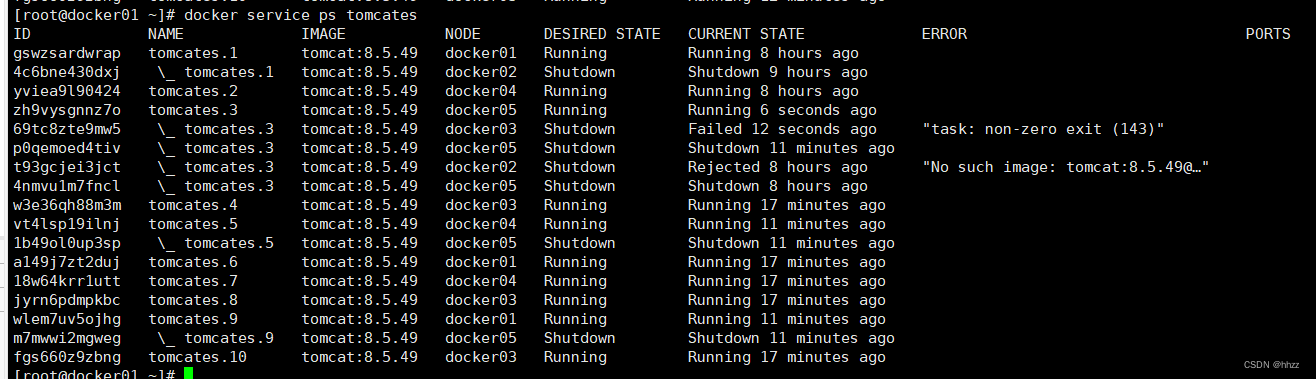
(2) 查看 task 節點
此時再查看服務的 task 節點信息可以看到?task分配到其他 主機。
8.3 服務刪除
通過 docker service rm [service name|service ID]可以刪除指定的一個或多個 service。
docker service rm tomcates刪除后,該 service 消失,當然,該 service 的所有 task 也全部刪除,task 相關的節點容器全部消失。

8.4 滾動更新
當一個 service 的 task 較多時,為了不影響對外提供的服務,在對 service 進行更新時可
采用滾動更新方式。
(1) 需求
這里要實現的更新時,將原本鏡像為 tomcat:8.5.49 的 service 的鏡像滾動更新為tomcat:8.5.39。
(2) 創建 service
創建一個包含 10 個副本 task 的服務,該服務使用的鏡像為 tomcat:8.5.49。
docker service create \
--name toms \
--replicas 10 \
--update-parallelism 2 \
--update-delay 3s \
--update-max-failure-ratio 0.2 \
--update-failure-action rollback \
--rollback-parallelism 2 \
--rollback-delay 3s \
--rollback-max-failure-ratio 0.2 \
--rollback-failure-action continue \
-p 9000:8080 \
tomcat:8.5.39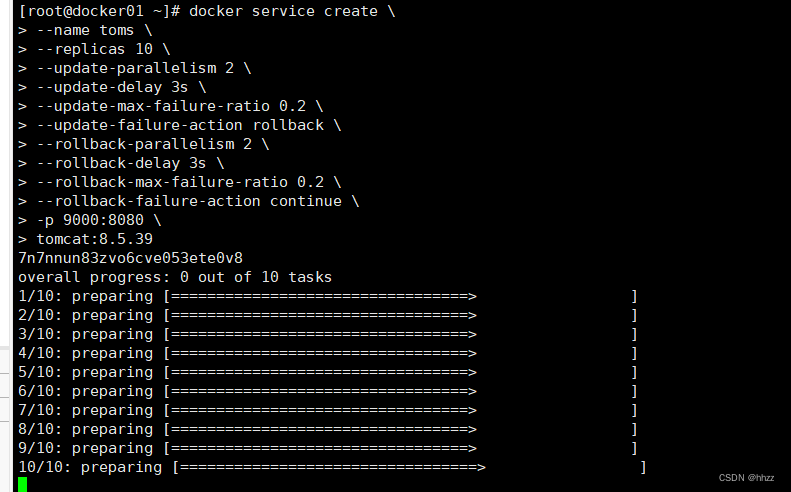
這 10 個 task 被非常平均的分配到了 5 個 swarm 節點上了。
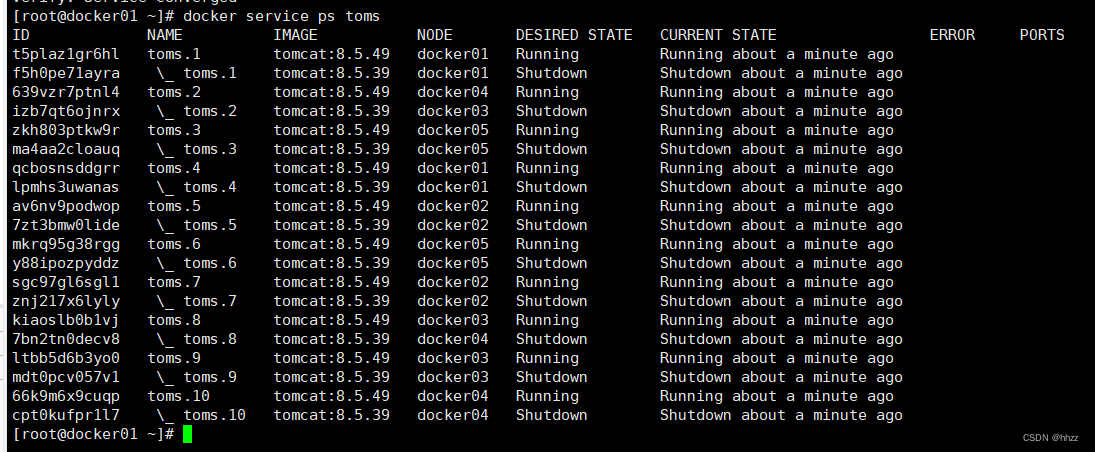
docker service ps toms
(3) 更新 service
現要將 service 使用的鏡像由 tomcat:8.5.39 更新為 tomcat:8.5.49。
docker service update --image tomcat:8.5.49 toms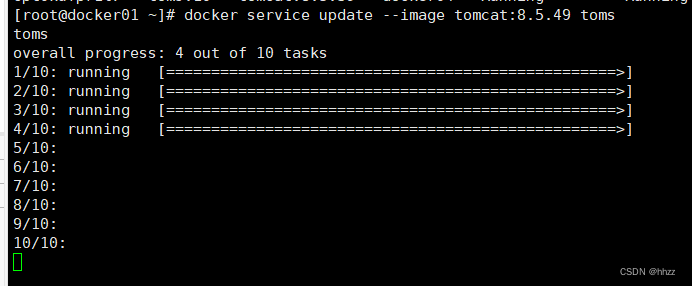
會發現這個更新的過程就是前面在創建服務時指定的那樣,每次更新 2 個 task,更新間隔為 3 秒。更新完畢后再查看當前的 task 情況發現,已經將所有任務的鏡像更新為了 8.5.49 版本。
8.5 更新回滾
在更新過程中如果更新失敗,則會按照設置的回滾策略進行回滾,回滾到更新前的狀態。
但用戶也可通過命令方式手工回滾。
下面的命令會按照前面設置的每次回滾 2 個 task,每次回滾間隔 3 秒進行回滾。下面的
是回滾過程中的某個回滾瞬間。
docker service update --rollback toms

以下是回滾完畢后的結果。
回滾完畢后再查看當前的 task 情況發現,已經將所有任務的鏡像恢復為了 8.5.39 版本。
但需要注意,task name 保持未變,但 task ID 與原來的 task ID 也是不同的,并不是恢復到了
更新之前的 task ID。即編排器新創建了 task,并由分發器重新為其分配了 node。
docker service ps toms
9、service 全局部署模式
根據 task 數量與節點數量的關系,常見的 service 部署模式有兩種:replicated 模式與
global 模式。前面創建的 service 是 replicated 模式的,下面來創建 global 模式的 service。

9.1 環境變更
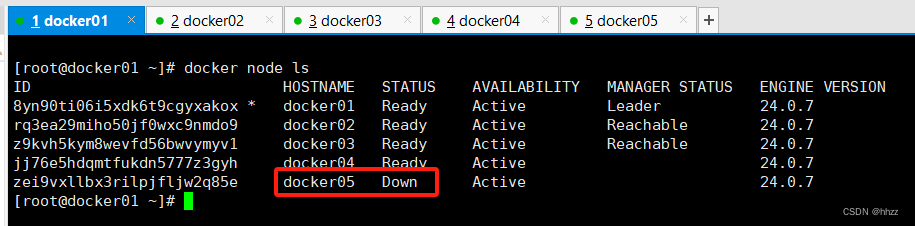
為了后面的演示效果,讓 swarm 集群的節點變為 4 個。這里先使 docker5 退群。
docker swarm leave
此時 docker5 的節點狀態變為了 Down。
docker node ls
將此節點再從 swarm 集群中刪除。
docker node rm docker05
現在 docker5 節點才徹底被刪除。

9.2 創建 service
在 docker service create 命令中通過--mode 選項可以指定要使用的 service 部署模式,默
認為 replicated 模式。
docker service create --name toms2 --mode global -p 9001:8080 tomcat:8.5.39

該模式會在每個節點上分配一個 task。
docker service lsdocker service ps toms2
9.3 task 伸縮
對于 global 模式來說,若要實現對 service 的 task 數量的變更,必須通過改變該 servicve所依附的 swarm 集群的節點數量來改變。節點增加,則 task 會自動增加;節點減少,則 task會自動減少。
下面要在這個 4 節點的 swarm 集群中增加一個節點,以使 toms 服務的 task 也增一。
首先在 manager 節點獲取新增一個節點的 token。
docker swarm join-token worker

在 docker5 上運行加入命令,完成 swarm 的入群。
?
docker swarm join --token SWMTKN-1-4xrmirqfkb41hzrqjtqtehzjom484oi77dq8u1cqgrx9dqqw21-0y0n33l0vjxfxj4lai4r5hi80 192.168.162.201:2377此時查看 toms2 服務的 task 詳情,發現已經自動增加了一個 task。
docker service ps toms2

10、overlay 網絡
10.1 測試環境 1搭建
(1) 暫停分配 task

現讓 docker2 主機暫停分配 task
?
docker node update --availability pause docker02
(2) 創建 service
現啟動一個 service,包含 10 個 task。
docker service create --name toms --replicas 10 -p 9000:8080 tomcat:8.5.39
當前 swarm 集群共有 5 個節點,10 個 task 被分配到了 4 個可用節點上,其中除了被暫
停的 docker2 節點上是沒有分配 task 外,其余節點都分配了多個 task。
docker service ps toms
此時,訪問docker02主機http://192.168.162.202:9000/

居然能訪問????問題解決請繼續看下一節overlay網絡。
10.2 overlay 網絡概述
(1) overlay 網絡簡介
overlay 網絡,也稱為重疊網絡或覆蓋網絡,是一種構建于 underlay 網絡之上的邏輯虛擬網絡。即在物理網絡的基礎上,通過節點間的單播隧道機制將主機兩兩相連形成的一種虛擬的、獨立的網絡。
Docker Swarm 集群中的 overlay 網絡主要是通過 iptables、ipvs、vxlan 等技術實現的、基于其本身通信需求的網絡模型。
(2) overlay 網絡模型
這里要說的 overlay 網絡模型,確切地說,是 Docker Swarm 集群的 overlay 網絡模型。
Docker Swarm 集群的 overlay 網絡模型在創建時,會創建出兩個網絡:docker_gwbidge
網絡與 ingress 網絡。這就是典型的 overlay 網絡——在宿主機的物理網絡之上又創建出新的
網絡。同時還創建出了 docker_gwbidge 網關與 br0 網關,及 ingress-sbox 容器。
當請求到達后會首先經由 docker_gwbidge 網關跳轉到 ingress-sbox 容器,在其中具有當
前整個service的所有容器IP,在其中通過輪詢負載均衡方式選擇一個容器IP作為目標地址,
然后再跳轉到 br0 網關。在 br0 網關中會根據目標地址所在主機進行判斷。若目標地址為本
地容器 IP,則直接將請求轉發給該容器處理即可。若目標地址非本地容器 IP,則會將請求經
由 vxlan 接口,通過 vxlan 隧道技術將請求轉發給目標地址容器。
10.3 docker_gwbridg 網絡基礎信息
在詳細分析 overlay 網絡模型的通信原理之前,首先來了解一下 docker swarm 的 overlay
網絡的基礎信息。
(1) 查看 docker_gwbridge 網絡詳情
docker swarm 集群的 overlay 網絡模型在創建時,會自動創建兩個網絡:docker_gwbridge
網絡與 ingress 網絡。

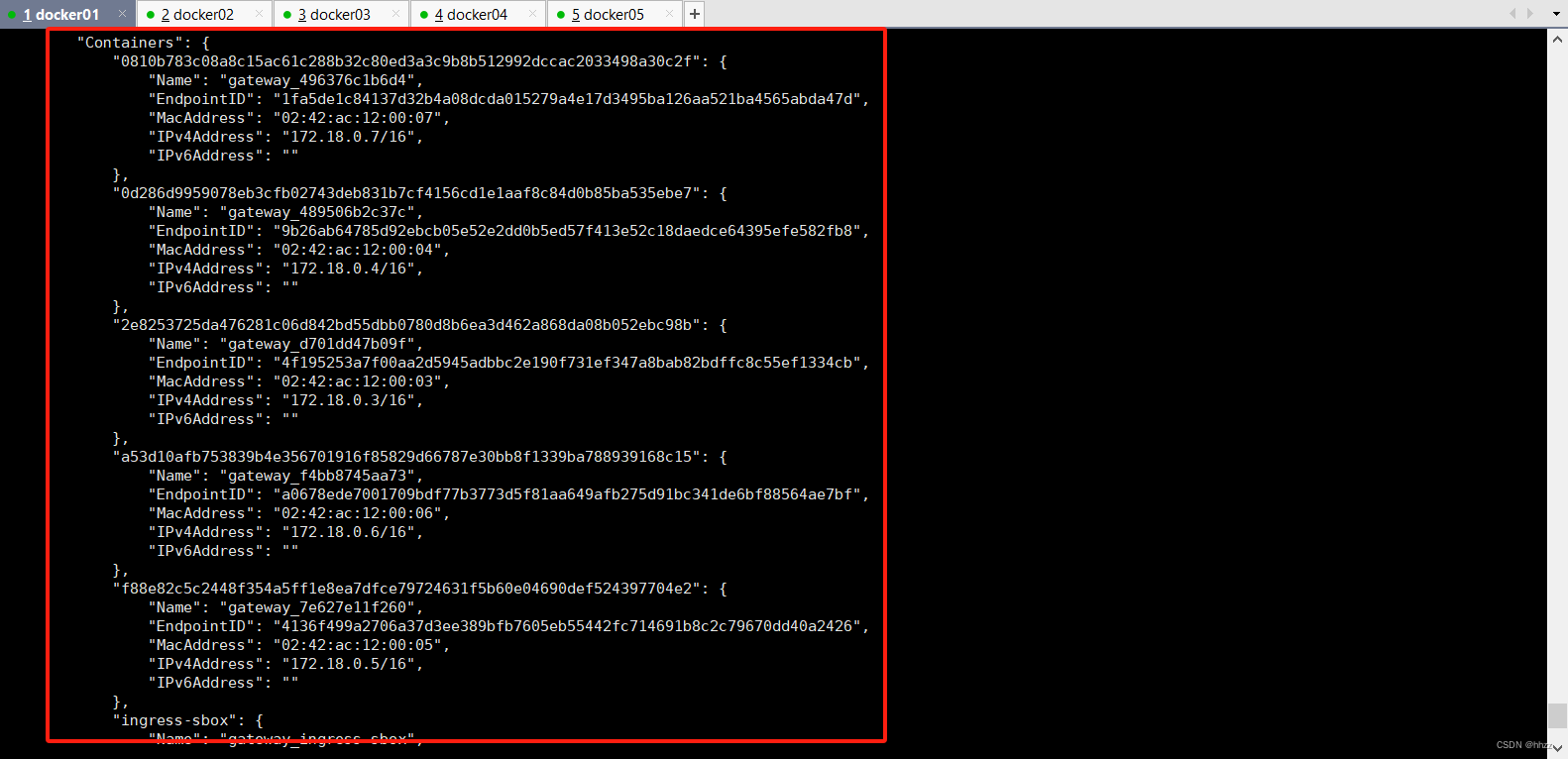
查看 docker_gwbridge 網絡詳情可以看到,docker_gwbridge 網絡包含的子網為
172.18.0.0/16,其網關為 172.18.0.1。那么,這個網關是誰呢?

同時還看到,該網絡中包含了 6 個容器。其中 5 個為 service 的 task 容器,另一個的容
器 ID 為 ingress-sbox。
(2) ingress-sbox 容器

通過 docker ps –a 命令查看當前主機中的所有容器,發現并沒有 ingress-sbox 容器。為
什么?因為 docker ps 命令的本質是 docker process status,查看的是當前主機中真實存在的
容器進程的狀態。而 ingress-sbox 容器是由 overlay 網絡虛擬出的,并不是真實存在的進程,
所以通過 docker ps 命令是查看不到的。
從 docker_gwbridge 的網絡詳情中可以看到,其中 2 個為 service 的 task 容器,其 ID 由
64 位 16 進制數構成,而 ingress-sbox 容器的 ID 就是 ingress-sbox,與其它 2 個容器的 ID 構
成方式完全不同。
(3) docker_gwbridge 網關
docker_gwbridge 的網絡詳情中的網關 172.18.0.1 是誰呢?
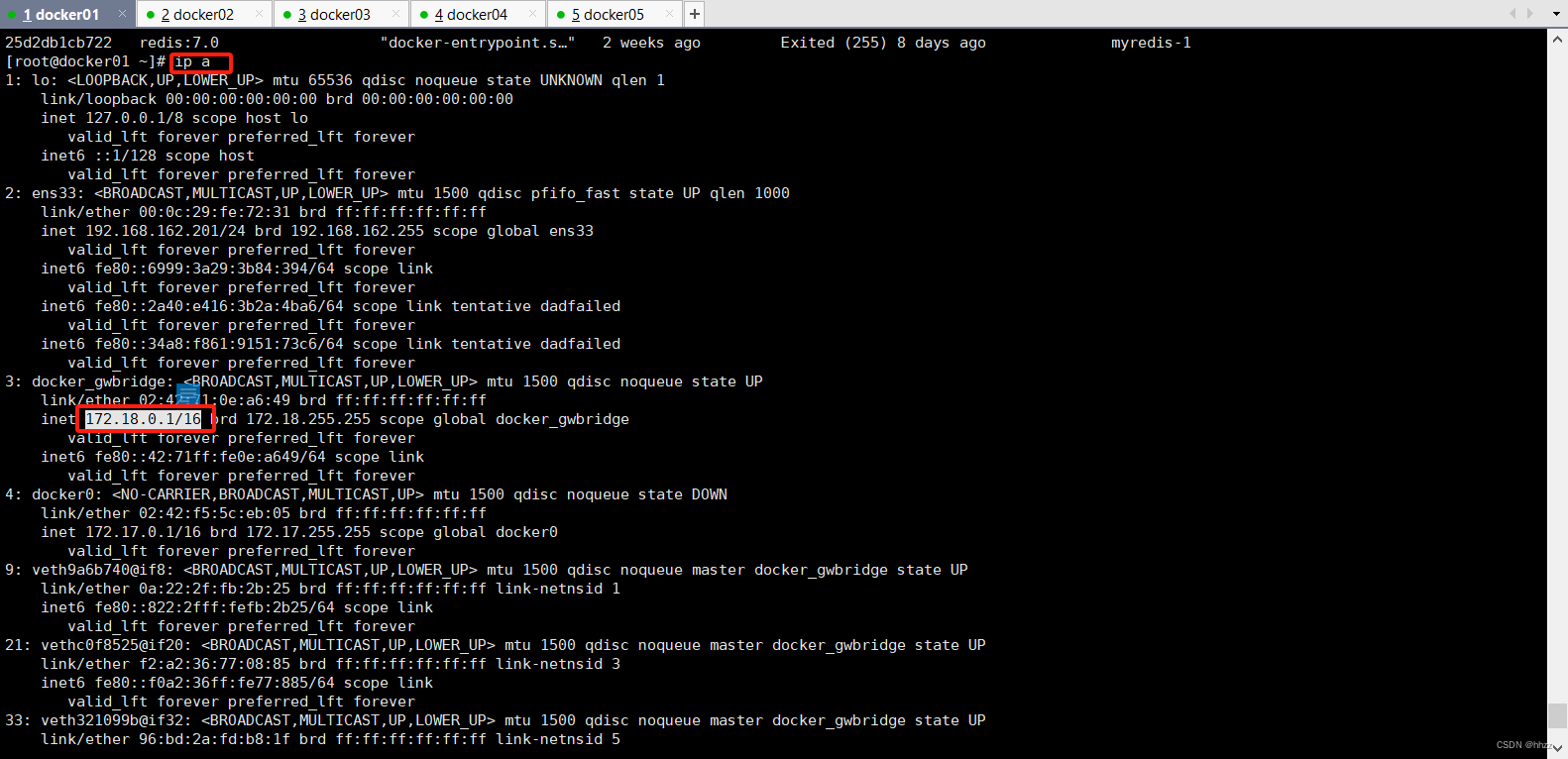
在宿主機中通過 ip a 命令查看宿主機的網絡接口,可以看到 docker_gwbridge 接口的 IP
為 172.18.0.1。即 docker_gwbridge 網絡中具有一個與網絡名稱同名的網關。同時還看到,下
面的 3 個接口全部都是連接在 docker_gwbridge 上的。
(4) 查看 task 容器的接口
查看 docker_gwbridge 網絡的 task 容器的接口情況,可以看到這些容器中正好有接口與
docker_gwbridge 網關中的相應接口構成 veth paire。

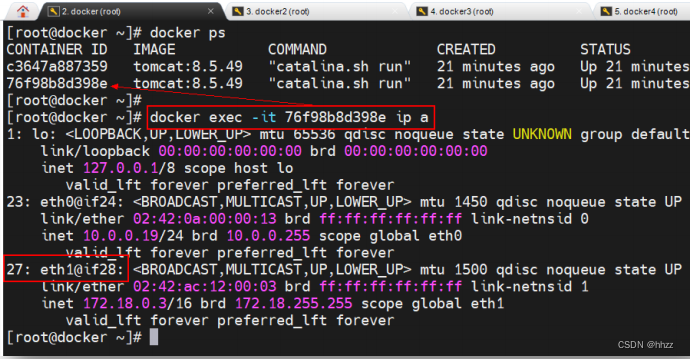
(5) 查看 ingress-sbox 容器的接口
如何查看docker_gwbridge網絡的ingress-sbox容器的接口情況呢?每個容器都具有一個
獨立的網絡命名空間,而每個 docker 主機中的網絡命名空間,都是以文件的形式保存在目
錄/var/run/docker/netns 中。

其中 ingress_sbox 就是容器 ingress-sbox 的網絡命名空間。通過 nsenter 命令可進入該命
名空間并查看其接口情況。可以看到該命名空間中正好也存在接口與 docker_gwbridge 網關
中的相應接口構成 veth paire。

10.4 ingress 網絡基礎信息
(1) 查看 ingress 網絡詳情
overlay 網絡除了創建了 docker_gwbridge 網絡外,還創建了一個 ingress 網絡。
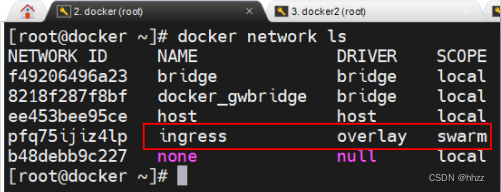
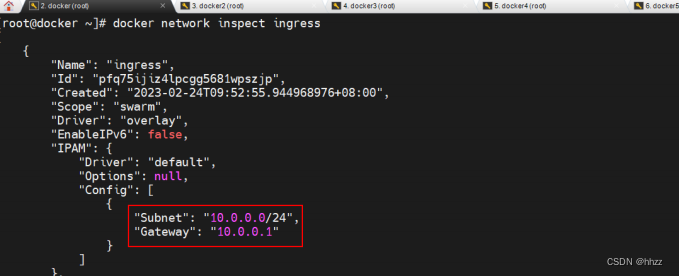
查看 ingress 網絡詳情可以看到,ingress 網絡包含的子網為 10.0.0.0/24,其網關為 10.0.0.1。
那么,這個網關是誰呢?
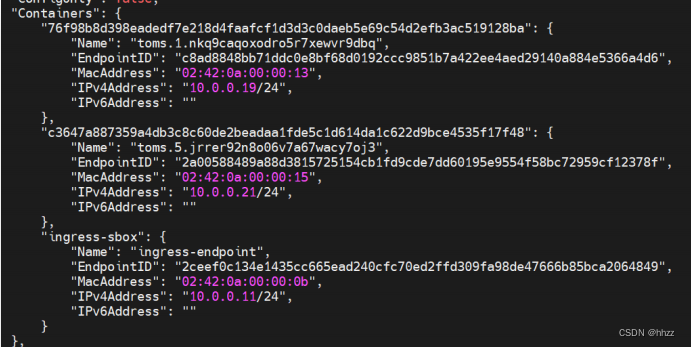
同時還看到,該網絡中也包含了 3 個容器,這 3 個容器與 docker_gwbridge 網絡中的 3
個容器是相同的容器,雖然 Name 不同,IP 不同,但容器 ID 相同。說明這 3 個容器都同時
連接在 2 個網絡中。
(2) br0 網關
10.0.0.1 網關是誰呢?
每個容器都具有一個獨立的網絡空間,而每個 docker 主機中的網絡命名空間,都是以
文件的形式保存在/var/run/docker/netns 目錄中。查看當前主機的網絡空間:
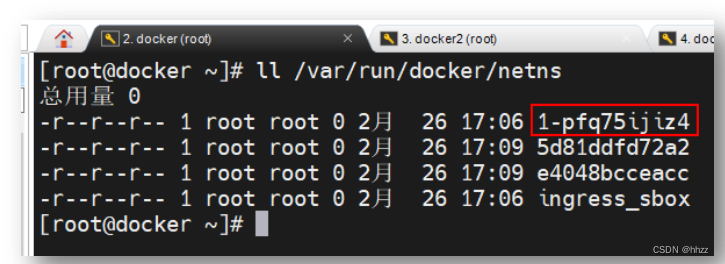
查看/var/run/docker/netns 目錄中的命名空間發現,其包含的 4 個命名空間中,有 2 個
命名空間是 2 個 task 容器的,它們的名稱由 12 位長度的 16 進制數構成;ingress_sbox 是
ingress-sbox 容器的命名空間。那么,1-pfq75ijiz4 命名空間是誰呢?進入該命名空間,查看
其接口信息。
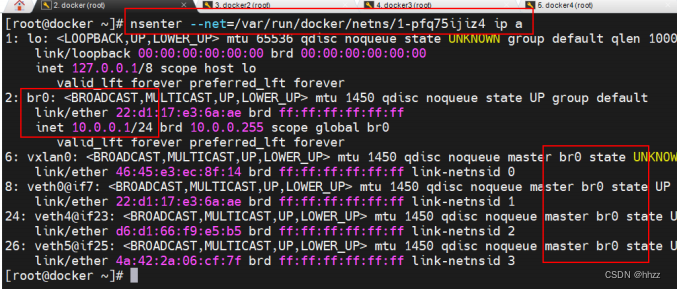
可以看到 2 號接口 br0 的 IP 為 10.0.0.1,即 ingress 網絡的網關為 1-pfq75ijiz4 命名空間
中的 br0。同時還看到,br0 上還連接著 4 個接口,說明 br0 就是一個網關。那么,都是誰
連接在這 4 個接口上呢?
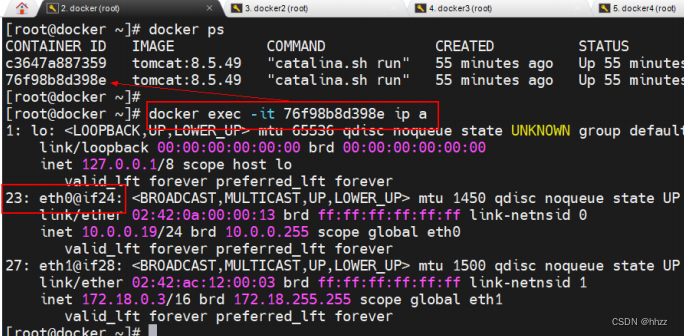
(3) 查看 task 容器的接口
查看 ingress 網絡的 task 容器的接口情況,可以看到這些容器中正好有接口與 br0 網關
中的相應接口構成 veth paire。

(4) 查看 ingress-sbox 容器的接口
查看 ingress-sbox 容器的命名空間 ingress_sbox 的接口情況,可以看到該命名空間中正
好也存在接口與 br0 網關中的相應接口構成 veth paire。

10.5 宿主機的 NAT 過程
(1) 查看宿主機路由
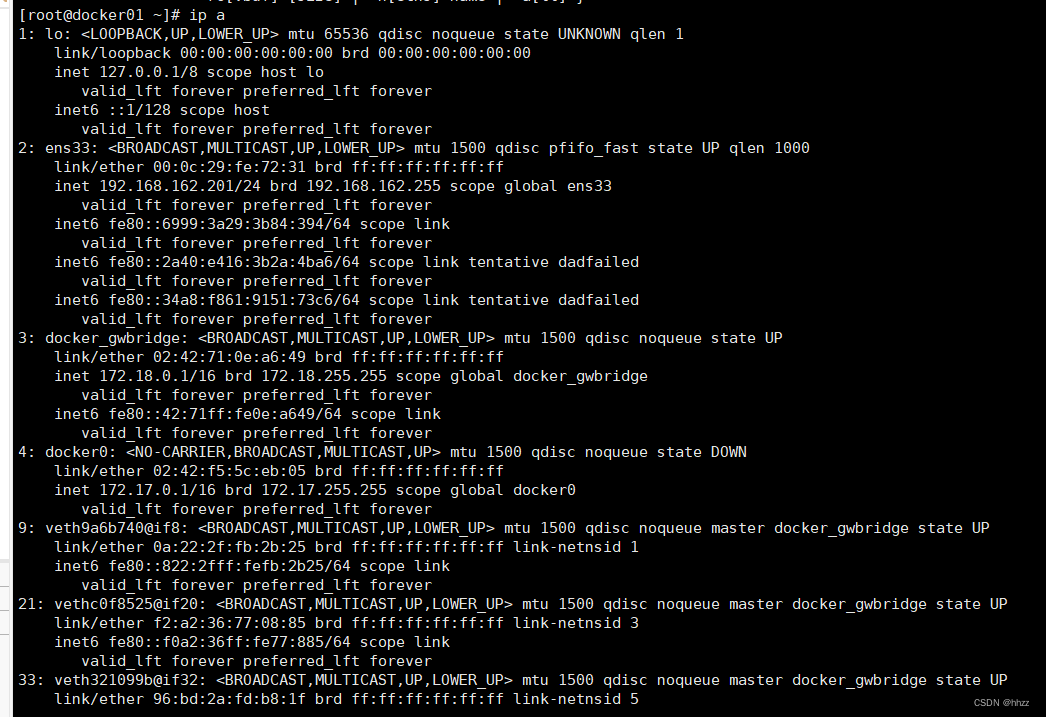
用戶提交的192.168.192.101:9000請求會首先被192.168.192.101主機的哪個接口接收并
處理呢?通過命令 ip route 可以查看當前網絡命名空間中的靜態路由信息。

可以看出,所有對 192.168.182.0/24 網絡的請求,都需要經過 ens33 接口,而該接口連
接的 IP 為 192.168.192.101。即 ens33 接口會處理該請求。當然,查看該主機的接口情況也
可以看到,ens33 接口地址為 192.168.192.101。
那么 ens33 接口又會將請求轉發到哪里呢?這就需要查看宿主機的路由轉發表 nat 中的
路由規則了。
(2) 查看 ip 轉換規則
首先通過 iptables –nvL –t nat 命令來查看宿主機中網絡地址轉發表 nat 中的轉發規則。
nat 表的主要功能是根據規則進行地址映射、端口映射,以完成地址轉換。
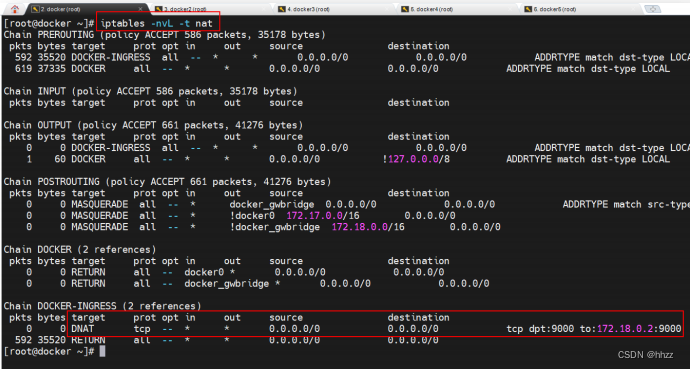
DOCKER-INGRESS 路由鏈路中的 DNAT 映射規則中指出,對于任何源 IP,只要其訪問端
口號為 9000,就會將其轉換為 172.18.0.2:9000 的請求,即將請求轉發到 172.18.0.2。那么請
求是如何到達 172.18.0.2 的呢?
(3) 查看宿主機路由
通過 ip route 命令查看當前宿主機的靜態路由信息。

可以看出,所有對 172.18.0.0/16 網絡的請求,都需要經過 docker_gwbridge 接口,而該
接口連接的 IP 為 172.18.0.1。即 docker_gwbridge 接口會處理該請求。由一個網絡去訪問另
一個網絡必須要經過該目標網絡的網關。經前面的學習知道,docker_gwbridge 正好就是
172.18.0.0/16 網絡的網關。
也就是說,客戶端提交的 192.168.192.101:9000 的請求,經 docker_gwbridge 網關,被
路由到了 IP 為 172.18.0.2 的接口。那么誰的 IP 是 172.18.0.2 呢?經過前面網絡基礎信息查
看可知,docker_gwbridge 網絡中包含 IP 為 172.18.0.2 的 ingress-sbox 容器。
10.6 ingress_sbox 的負載均衡
客戶端請求經宿主機的 NAT 已經成功通過 docker_gwbridge 網關轉發到了 172.18.0.2,
即轉發到了 ingress-sbox 容器,或者更確切地說,是轉發到了 ingress_sbox 命名空間。那么,
ingress_sbox 命名空間又會將請求轉發到哪里呢?這就需要查看 ingress_sbox 命名空間的
iptables 的 mangle 表與 IPVS 功能了。
(1) 查看 ingress_sbox 的 mangle 表
mangle 表的主要功能是根據規則修改數據包的一些標志位,以便其他規則或程序可以
利用這種標志對數據包進行過濾或路由。
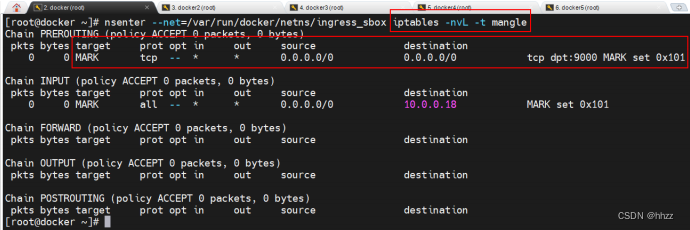
該路由鏈中為任意源地址端口為 9000 的請求打了一個 MARK 標記 0x101,該 MARK 標
記將被 IPVS 用于負載均衡。
(2) 安裝 ipvsadm 命令
后面我們需要使用該命令查看 IPVS 實現的負載均衡規則,但由于 CentOS 系統中默認沒
有安裝 ipvsadm 命令,所以需要先 yum 安裝。
(3) 查看 ingress_sbox 負載均衡規則

端口為 9000 的請求被打上了一個數值為 257 的 MARK 標記,該標記通過 LVS 的 IPVS 的
負載均衡,將該請求轉發到了下面的 10 個 IP 接口,且這 10 個接口的權重 weight 是相同的,
都是 1。這 10 個 IP 接口具有一個共同點,全部來自于 10.0.0.0/24 網絡。那么,如何能到達
10.0.0.0/24 網絡呢?
(4) 查看命名空間路由
通過前面的學習可知,若要由一個網絡轉發到另一個網絡,則必須要先到目標網絡的網
關。由于目前尚在 172.18.0.0/16 網絡,預轉發到 10.0.0.0/24 網絡,所以必須要先到 10.0.0.0/24
網絡的網關 10.0.0.1,即 br0。通過查看 br0 所在命名空間 1-pfq75ijiz4 的靜態路由也可看出:

但存在的問題是,請求目前尚在 ingress_sbox 命名空間中,怎樣才能從 ingress_sbox 命
名空間中出去,然后跳轉到 br0 呢?查看 ingress_sbox 命名空間中的靜態 IP 路由:

可以看出,所有對 10.0.0.0/24 網絡的請求,都需要經過 eth0 接口,而該接口連接的 IP
為 10.0.0.11。在 ingress_sbox 命名空間中 eth0 接口就是 7 號接口,其 veth pair 接口就是 br0
中的 8 號接口。所以,ingress_sbox 命名空間中請求經由 7 號接口跳轉到了 br0 網關。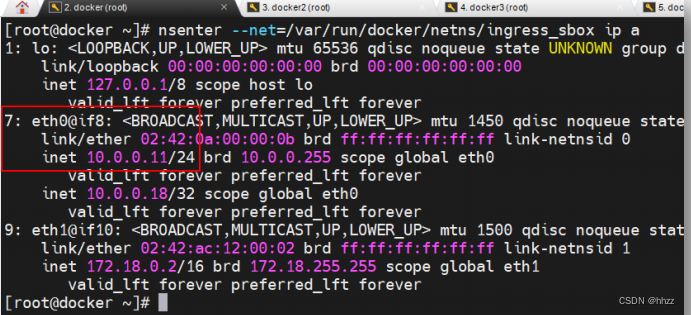
(5) br0 網關的處理
到達 br0 后,再將請求從 br0 的哪個接口轉發出去,是由目標地址決定的,而目標地址
就是 IPVS 負載均衡選擇出的 IP。請求到達 br0 后,首先會將目標地址與本地的 task 容器地
址進行比較,若恰好就是當前宿主機中的 task 容器的 IP,那么直接將請求通過相應的接口
將其轉發;若不是當前宿主機中的 IP,則會將請求轉發到 vxlan0 接口。經過 vxlan0 接口,
可經由 VXLAN 技術將請求通過“網絡隧道”發送到目標地址。
10.7 VXLAN
(1) VXLAN 簡介
VXLAN 是一種隧道技術,可以將不同協議的數據包重新封裝后發送。新的包頭提供了路由信息,從而使被封裝的數據包在隧道的兩個端點間通過公共互聯網絡進行路由。被封裝的
數據包在公共互聯網絡上傳遞時所經過的邏輯路徑稱為隧道。一旦到達網絡終點,數據將被
解包并轉發到最終目的地。
(2) 測試環境 2 搭建
為了能夠看清楚請求在不同主機的容器間所進行了通信,及通信過程中所使用的 VXLAN
技術,這里將原來的服務先刪除,然后再創建一個新的服務。不過,該服務僅有一個副本。
首先刪除原來的 service。
然后在任意主機中創建一個新的 servivce,其僅包含一個副本。這里在 docker3 主機創
建了服務。可以看到,這唯一的副本被分配到了 docker5 主機。

(3) 安裝 tcpdump 命令
這里準備使用 tcpdump 命令對 VXLAN 數據進行監聽,但在 centOS7 系統中默認是沒有
安裝 tcpdump 命令的,所以需要使用 yum 命令先在 docker5 主機安裝。
yum install -y tcpdump
(4) docker5 先監聽
無論對哪個主機的該服務進行訪問,請求最終都會通過 docker5 主機的 ens33 接口進入,
然后再找到該 task 容器。所以這里要先監聽 docker5 的 ens33 接口。

(5) docker3 訪問
在瀏覽器可以對任意主機提交訪問請求。這里是向 docker3 主機發出的訪問請求。

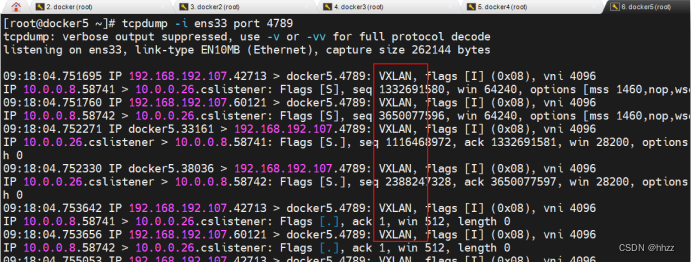
(6) docker5 查看抓包數據
當向 docker3 主機發送了訪問請求后,docker5 上就會看到抓取的 VXLAN 數據包。
11 Raft 算法
11.1 基礎
Raft 算法是一種通過對日志復制管理來達到集群節點一致性的算法。這個日志復制管理
發生在集群節點中的 Leader 與 Followers 之間。Raft 通過選舉出的 Leader 節點負責管理日志
復制過程,以實現各個節點間數據的一致性。
11.2 角色、任期及角色轉變
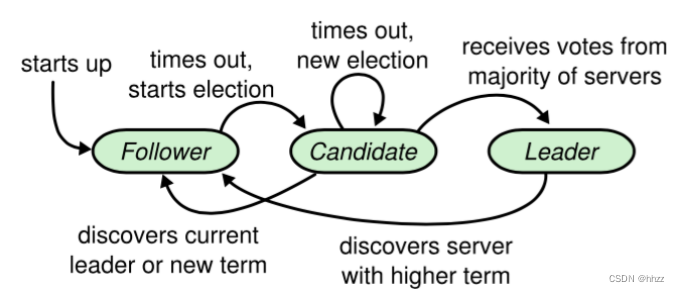
在 Raft 中,節點有三種角色:
- Leader:唯一負責處理客戶端寫請求的節點;也可以處理客戶端讀請求;同時負責日志復制工作
- Candidate:Leader 選舉的候選人,其可能會成為 Leader。是一個選舉中的過程角
- Follower:可以處理客戶端讀請求;負責同步來自于 Leader 的日志;當接收到其它Cadidate 的投票請求后可以進行投票;當發現 Leader 掛了,其會轉變為 Candidate 發起Leader 選舉
11.3 leader 選舉
通過 Raft 算法首先要實現集群中 Leader 的選舉。
(1) 我要選舉
若 follower 在心跳超時范圍內沒有接收到來自于 leader 的心跳,則認為 leader 掛了。此
時其首先會使其本地 term 增一。然后 follower 會完成以下步驟:
- 此時若接收到了其它 candidate 的投票請求,則會將選票投給這個 candidate
- 由 follower 轉變為 candidate
- 若之前尚未投票,則向自己投一票
- 向其它節點發出投票請求,然后等待響應
(2) 我要投票
follower 在接收到投票請求后,其會根據以下情況來判斷是否投票:
- 發來投票請求的 candidate 的 term 不能小于我的 term
- 在我當前 term 內,我的選票還沒有投出去
- 若接收到多個 candidate 的請求,我將采取 first-come-first-served 方式投票
(3) 等待響應
當一個 Candidate 發出投票請求后會等待其它節點的響應結果。這個響應結果可能有三
種情況:
- 收到過半選票,成為新的 leader。然后會將消息廣播給所有其它節點,以告訴大家我是新的 Leader 了
- 接收到別的 candidate 發來的新 leader 通知,比較了新 leader 的 term 并不比自己的 term小,則自己轉變為 follower
- 經過一段時間后,沒有收到過半選票,也沒有收到新 leader 通知,則重新發出選舉
(4) 選舉時機
在很多時候,當 Leader 真的掛了,Follower 幾乎同時會感知到,所以它們幾乎同時會變為 candidate 發起新的選舉。此時就可能會出現較多 candidate 票數相同的情況,即無法選舉出 Leader。
為了防止這種情況的發生,Raft 算法其采用了 randomized election timeouts 策略來解決這個問題。其會為這些 Follower 隨機分配一個選舉發起時間 election timeout,這個 timeout在 150-300ms 范圍內。只有到達了 election timeout 時間的 Follower 才能轉變為 candidate,否則等待。那么 election timeout 較小的 Follower 則會轉變為 candidate 然后先發起選舉,一般情況下其會優先獲取到過半選票成為新的 leader。
11.4 數據同步
在 Leader 選舉出來的情況下,通過日志復制管理實現集群中各節點數據的同步。
(1) 狀態機
Raft 算法一致性的實現,是基于日志復制狀態機的。狀態機的最大特征是,不同 Server
中的狀態機若當前狀態相同,然后接受了相同的輸入,則一定會得到相同的輸出。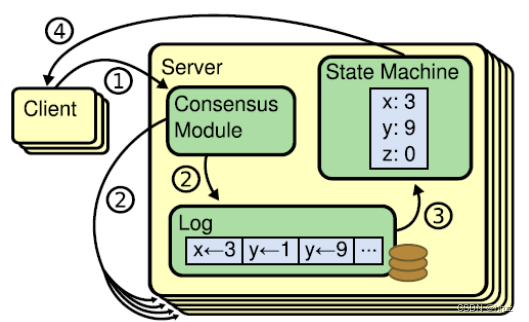
(2) 處理流程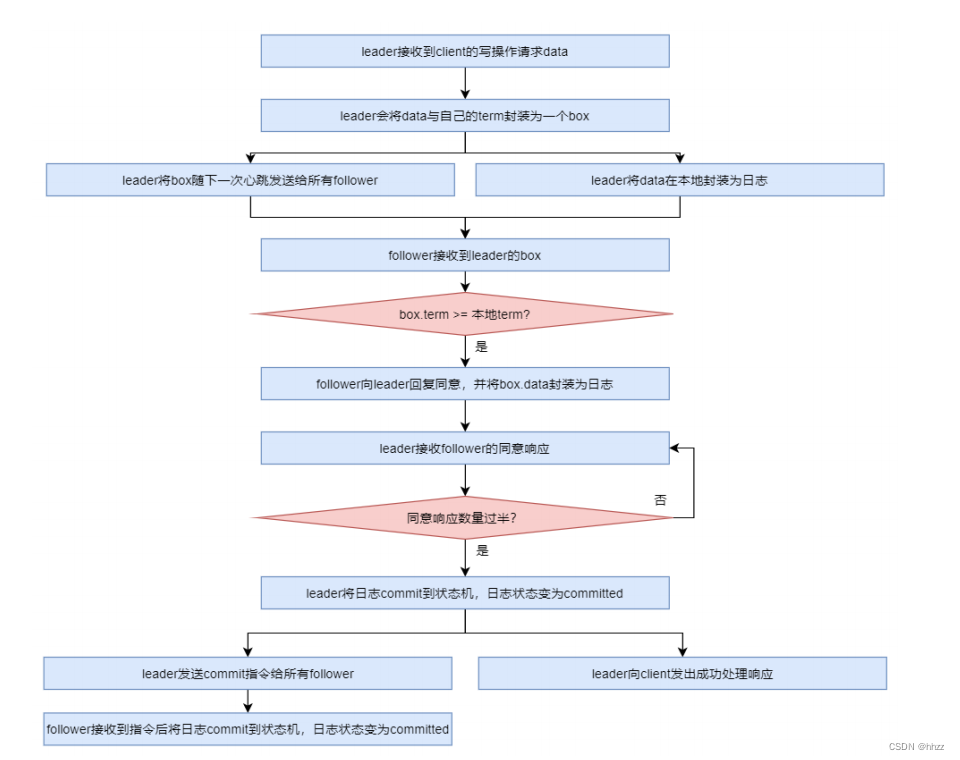
當 leader 接收到 client 的寫操作請求后,大體會經歷以下流程:
- leader 在接收到 client 的寫操作請求后,leader 會將數據與 term 封裝為一個 box,并隨
著下一次心跳發送給所有 followers,以征求大家對該 box 的意見。同時在本地將數據封
裝為日志
- ?follower 在接收到來自 leader 的 box 后首先會比較該 box 的 term 與本地記錄的曾接受過
的 box 的最大 term,只要不比自己的小就接受該 box,并向 leader 回復同意。同時會將
該 box 中的數據封裝為日志。
- 當 leader 接收到過半同意響應后,會將日志 commit 到自己的狀態機,狀態機會輸出一
個結果,同時日志狀態變為了 committed
- 同時 leader 還會通知所有 follower 將日志 commit 到它們本地的狀態機,日志狀態變為
了 committed
- 在 commit 通知發出的同時,leader 也會向 client 發出成功處理的響應。
(3) AP 支持
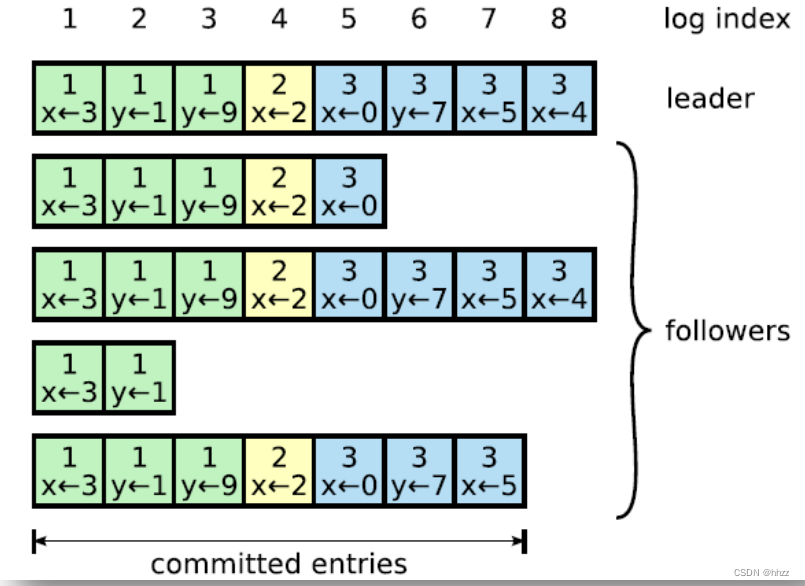
Log 由 term index、log index 及 command 構成。為了保證可用性,各個節點中的日志可
以不完全相同,但 leader 會不斷給 follower 發送 box,以使各個節點的 log 最終達到相同。
即 raft 算法不是強一致性的,而是最終一致的。
11.5 腦裂
Raft 集群存在腦裂問題。在多機房部署中,由于網絡連接問題,很容易形成多個分區。
而多分區的形成,很容易產生腦裂,從而導致數據不一致。
由于三機房部署的容災能力最強,所以生產環境下,三機房部署是最為常見的。下面以
三機房部署為例進行分析,根據機房斷網情況,可以分為五種情況:
(1) 情況一--不確定
這種情況下,B 機房中的主機是感知不到 Leader 的存在的,所以 B 機房中的主機會發
起新一輪的 Leader 選舉。由于 B 機房與 C 機房是相連的,雖然 C 機房中的 Follower 能夠感
知到 A 機房中的 Leader,但由于其接收到了更大 term 的投票請求,所以 C 機房的 Follower
也就放棄了 A 機房中的 Leader,參與了新 Leader 的選舉。
若新 Leader 出現在 B 機房,A 機房是感知不到新 Leader 的誕生的,其不會自動下課,
所以會形成腦裂。但由于 A 機房 Leader 處理的寫操作請求無法獲取到過半響應,所以無法
完成寫操作。但 B 機房 Leader 的寫操作處理是可以獲取到過半響應的,所以可以完成寫操
作。故,A 機房與 B、C 機房中出現腦裂,且形成了數據的不一致。
若新 Leader 出現在 C 機房,A 機房中的 Leader 則會自動下課,所以不會形成腦裂。
(2) 情況二--形成腦裂
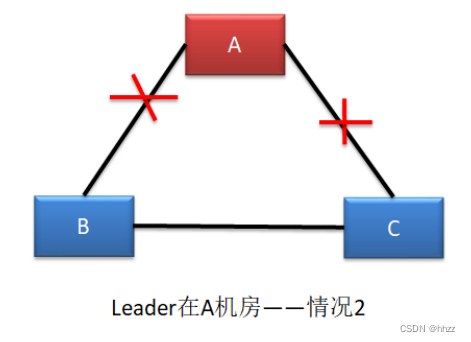
這種情況與情況一基本是一樣的。不同的是,一定會形成腦裂,無論新 Leader 在 B 還
是 C 機房。
(3) 情況三--無腦裂
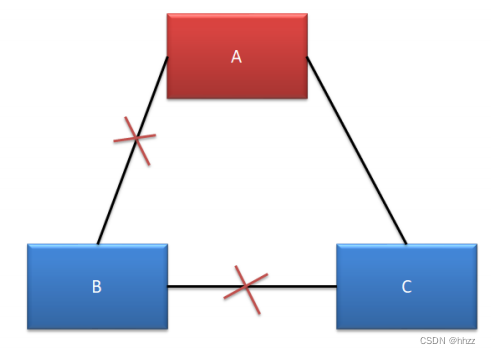
A、C 可以正常對外提供服務,但 B 無法選舉出新的 Leader。由于 B 中的主機全部變為
了選舉狀態,所以無法提供任何服務,沒有形成腦裂。
(4) 情況四--無腦裂
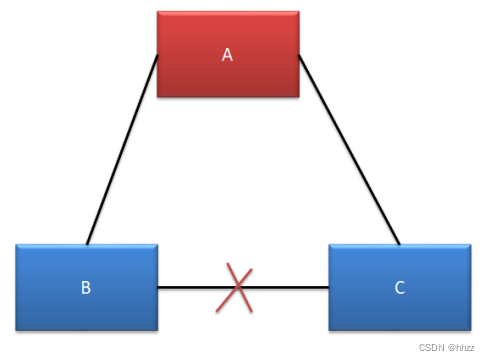
A、B、C 均可以對外提供服務,不受影響。
(5) 情況五--無腦裂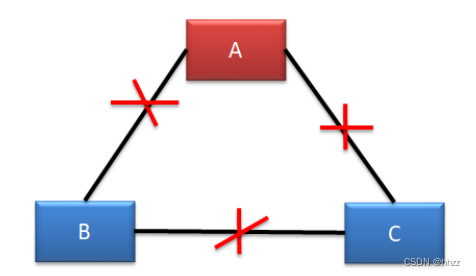
A 機房無法處理寫操作請求,但可以對外提供讀服務。
B、C 機房由于失去了 Leader,均會發起選舉,但由于均無法獲取過半支持,所以均無
法選舉出新的 Leader。
11.6 Leader 宕機處理
(1) 請求到達前 Leader 掛了
client 發送寫操作請求到達 Leader 之前 Leader 就掛了,因為請求還沒有到達集群,所以
這個請求對于集群來說就沒有存在過,對集群數據的一致性沒有任何影響。Leader 掛了之
后,會選舉產生新的 Leader。
由于 Stale Leader 并未向 client 發送成功處理響應,所以 client 會重新發送該寫操作請求。
(2) 未開始同步數據前 Leader 掛了
client 發送寫操作請求給 Leader,請求到達 Leader 后,Leader 還沒有開始向 Followers
發出數據 Leader 就掛了。這時集群會選舉產生新的 Leader。Stale Leader 重啟后會作為
Follower 重新加入集群,并同步新 Leader 中的數據以保證數據一致性。之前接收到 client 的
數據被丟棄。
由于 Stale Leader 并未向 client 發送成功處理響應,所以 client 會重新發送該寫操作請求。
(3) 同步完部分后 Leader 掛了
client 發送寫操作請求給 Leader,Leader 接收完數據后向所有 Follower 發送數據。在部
分 Follower 接收到數據后 Leader 掛了。由于 Leader 掛了,就會發起新的 Leader 選舉。
- 若 Leader 產生于已完成數據接收的 Follower,其會繼續將前面接收到的寫操作請求轉換為日志,并寫入到本地狀態機,并向所有 Flollower 發出詢問。在獲取過半同意響應后會向所有 Followers 發送 commit 指令,同時向 client 進行響應。
- 若 Leader 產生于尚未完成數據接收的 Follower,那么原來已完成接收的 Follower 則會放
棄曾接收到的數據。由于 client 沒有接收到響應,所以 client 會重新發送該寫操作請求。
(4) commit 通知發出后 Leader 掛了
client 發送寫操作請求給 Leader,Leader 也成功向所有 Followers 發出的 commit 指令,
并向 client 發出響應后,Leader 掛了。
由于 Stale Leader 已經向 client 發送成功接收響應,且 commit 通知已經發出,說明這個
寫操作請求已經被 server 成功處理。
11.7 Raft 算法動畫演示
在網絡上有一個關于 Raft 算法的動畫,其非常清晰全面地演示了 Raft 算法的工作原理。
該動畫的地址為:http://thesecretlivesofdata.com/raft/???????


:構建簡單頁面)
)








)


——4.6.存儲過程和函數(Procedure和Function))



)