
筆記整理:鄒銘輝,天津大學碩士,研究方向為自然語言處理
鏈接:https://aclanthology.org/2023.acl-long.897
動機
文檔級事件關系抽取(Document-level Event-Event Relation Extraction,簡稱DERE)旨在從文檔中提取事件之間的關系。相較于傳統的句子級任務(SERE),它涉及更加復雜的長文本理解。為了更好地進行文檔級推理,不同于現有方法通過語言工具構建事件圖,本文工作更關注文檔本身的性質,并且不依賴于任何先驗知識。為了做到這一點,作者強調以下關鍵問題:(1)如何捕捉可能相距較遠的事件依賴關系?(2)考慮到SERE和DERE之間的本質差異,是否應該將所有事件對同等對待?為了解決這些問題,作者提出了一種新穎的DERE模型,該模型學習稀疏的事件表示,用于區分句內和句間推理,即SENDIR(Sparse EveNt representations for Discriminating Intra- and inter-sentential Reasoning)。其基本思想是通過假設同一句子中或跨越多個句子的事件對具有不同的信息密度來區分它們:(1)文檔中的低密度暗示著對不相關信息的稀疏注意。本文模型的模塊1設計了各種類型的注意力機制來學習事件表示,以捕捉遠距離依賴關系。(2)句子中的高密度使得SERE相對較容易。本文模型的模塊2使用不同的權重來強調句內和句間推理的作用和貢獻,從而為聯合建模引入了支持性事件對。大量實驗證明了SENDIR的顯著改進以及各種稀疏注意力在文檔級表示上的有效性。
亮點
本文亮點主要包括:
(1)考慮到DERE和SERE任務的本質差異,提出了區分句內推理和句間推理的想法;
(2)本文提出的SENDIR模型關注文檔本身的性質,而無需任何的先驗知識和外部工具。
模型與方法
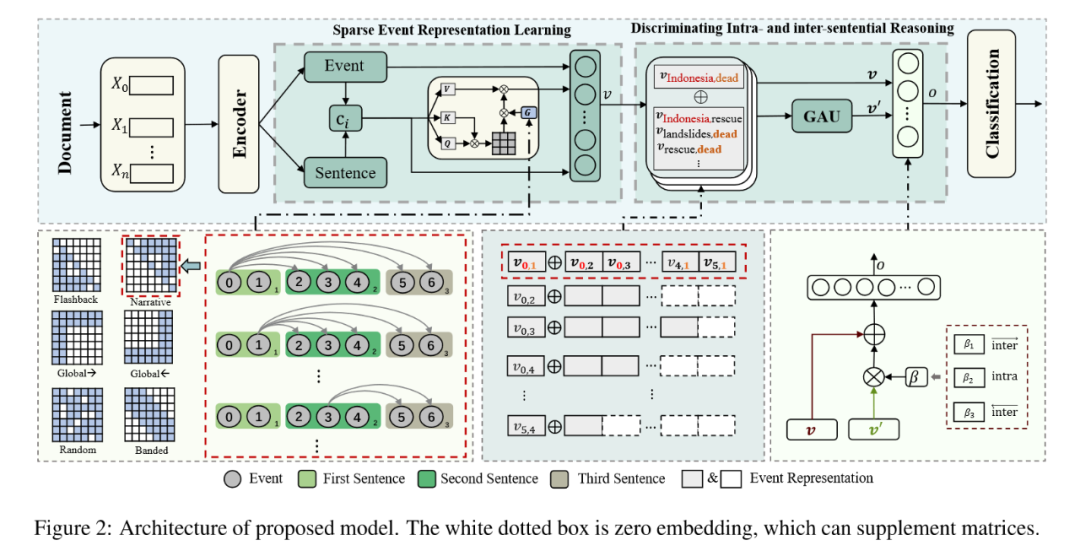
SENDIR旨在學習高質量的事件表示,以促進句內和句間推理。如圖2所示,模型框架有四個主要組件:(1)編碼器(Encoder)用于將文檔編碼為向量,(2)稀疏事件表示學習(SER)根據文檔嵌入進一步學習事件表示,(3)區分句內和句間推理(DIR)基于每對事件表示進行聯合推理,以及(4)分類模塊(Classification)用于進行最終預測。
編碼器(Encoder)
使用BERT和Bi-LSTM對長文檔(超過512個token)進行編碼,具體來說,首先使用BERT對單個句子進行編碼得到每個句子中token的表示,然后使用Bi-LSTM對所有句子的所有token進行編碼。公式如下:
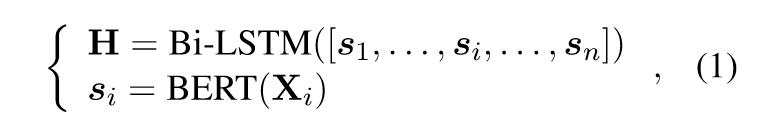
其中Xi=[x1, x2, …, xm]表示第i個包含m個token的句子,H=[?h1, h2, …, hn]表示所有句子的所有n個token的嵌入。
對于事件ei,p,其中i表示第i個事件,p表示句子的索引,定義其嵌入為ei,p = hk,如果事件提及的詞是xk,則該事件在文檔中的位置為k。
稀疏事件表示學習(SER)
SER研究了不同類型的注意力機制,以捕捉句子之間的長距離依賴關系,以獲得高質量的文檔表示,并用于增強事件表示。具體而言,SER首先學習事件特定的句子嵌入ci作為局部上下文(基于事件嵌入與所在句子的句子嵌入計算點積注意力):
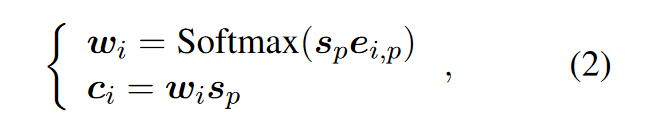
基于這些嵌入,SER再應用稀疏自注意力機制來跳過不相關的信息,以得到全局上下文c'i。特別地,SER引入了六種不同類型的長距離依賴假設。圖2的模型結構圖的左下角可視化展示了不同類型的注意力掩碼。Global→假設前兩個句子中的事件是文檔的核心主題,并且應該看到所有其他事件;Global←假設最后兩個句子中的事件是文檔的結論主題,并且應該看到所有其他事件;Random通常用于增加非局部交互的能力,本文隨機采樣20%的矩陣元素為0,其他為1;Banded假設相關信息僅限于鄰居句子(距離小于3),即每個事件只能看到鄰居句子中的事件;Narrative假設事件大多是按敘述順序描述的,以便前一個事件可以看到后一個事件;Flashback假設事件是按順序寫入的,因此后一個事件應該看到前一個事件。
然后,根據局部和全局上下文定義事件表示e'i為:
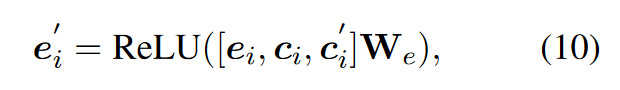
最后,給定一個事件對(ei, ej),定義其表示vi,j為:
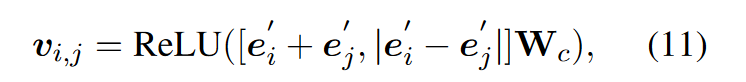
區分句內和句間推理(DIR)
上一節定義了基于局部和全局上下文的事件對表示vi,j。在本節中,DIR將它們作為句內特征進行處理,表明尚未考慮從其他句子中獲取事件對以形成推理鏈。為了進一步獲得每對事件的句間特征,DIR首先為每對事件選擇支持事件對,并使用GAU進行信息融合。然后,以不同的權重將兩種類型的特征組合在一起,以區分兩種類型的推理。
首先,假設只有共享至少一個公共事件的事件對才能對推理鏈做出貢獻,而不是使用所有事件對作為支持。基于這一假設,可以為給定的一個事件對(ei, ej)構建一個支持事件對集合T1=[vi,j, vi,1, …, vN,j],然后使用GAU進行推理得到增強后的事件對表示T2=[v'i,j, v'i,1, …, v'N,j]。公式如下:
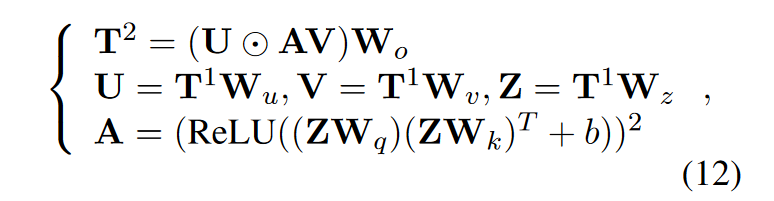
然后,需要將兩種不同權重的特征組合起來。基本思想是,同一句子內的事件對相對容易預測,并且有很高的置信度。因此,DIR利用句內特征來促進跨不同句子的事件對。為了避免更容易的預測帶來的問題,如果事件對在同一句子內,則給予句內特征更高的權重。相反,對于來自不同句子的事件,則給予句間特征更高的權重,以突出句間推理。最后,對于關系(ei, ej)之間的查詢事件對表示定義如下:
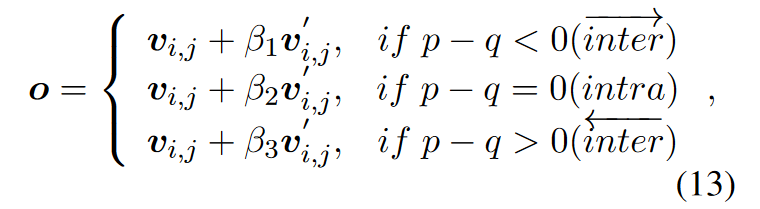
其中β1, β2和β3是超參數(本文中分別設置為0.8,?0.2和0),p和q表示事件所在句子的索引。
分類模塊(Classification)
給定事件對的最終表示o,使用線性函數來預測關系,公式如下:
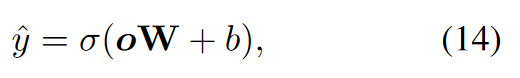
實驗
本文在兩個領域的三個數據集上對模型進行評估。EventStoryLine和Causal-TimeBank是事件因果關系抽取(RE)數據集,而MATRES是事件時間關系抽取數據集。其中,EventStoryLine標注了258份文檔,包含22個主題,共有4,316個句子,5,334個事件提及,7,805個句內事件對,以及46,521個句間事件對。Causal-TimeBank (Causal-TB)標注了184份文檔,包含6,813個事件,和7,608個事件對。MATRES標注了275份文檔,涵蓋了四種時間關系,即BEFORE,AFTER,EQUAL和VAGUE。
本文使用精確率(P)、召回率(R)和F1分數(F1)作為評估指標。
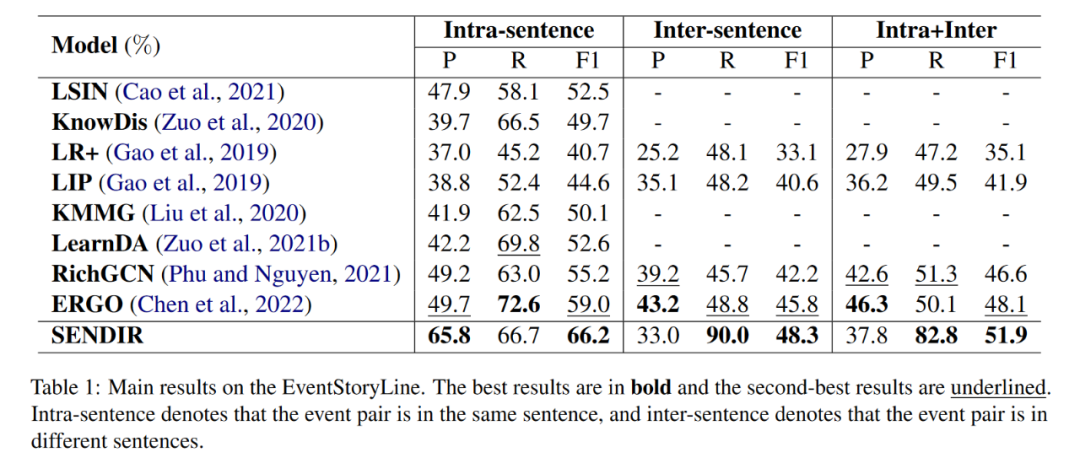
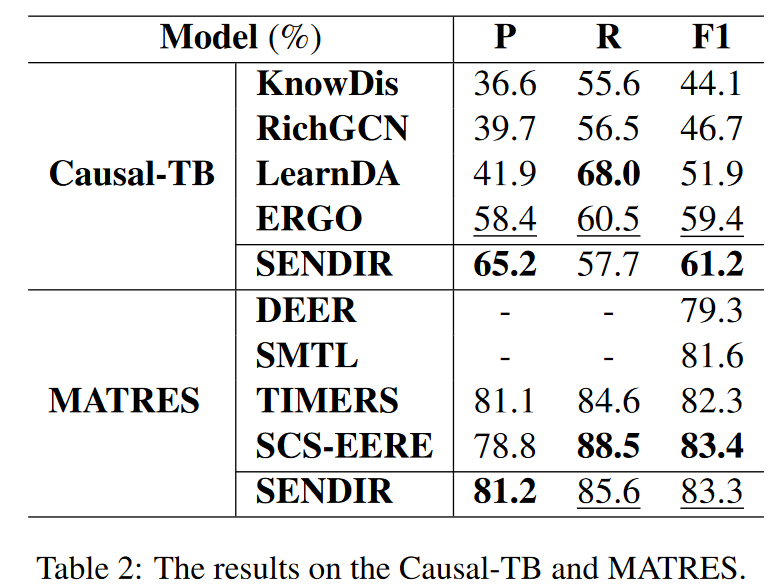
表1和表2分別展示了在EventStoryLine、Causal-TB和MATRES上的整體性能。我們可以看到:(1)SENDIR在EventStoryLine和Causal-TB上取得了更好的F1得分,并且在MATRES上也有競爭力的結果,這證明了模型的有效性和泛化能力。(2)在MATRES上,SENDIR略低于SCS-EERE。因為事件時間關系抽取對事件之間的方向尤為敏感。(3)在表1中,所有模型在句內表現比句間更好。這與本文的論斷一致,即句內關系抽取更容易。(4)特別地,SENDIR在句內具有更高的精確度。因為區分性推理方案減輕了更困難的跨句子推理的負面影響。(5)在句間設置中,改進主要來自更高的召回率。作者將這歸因于增強的遠距離建模能力和支持性的查詢集——它傾向于從更廣泛的上下文和其他事件對中找到關系線索。
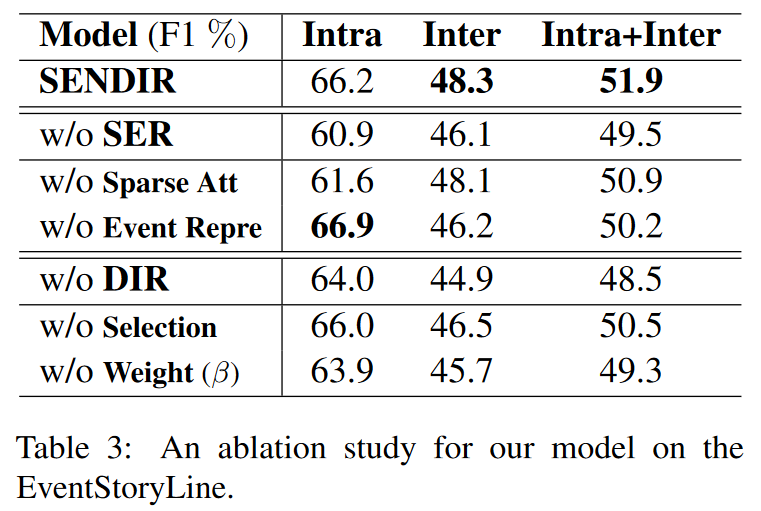
為了進一步分析SENDIR,本文還進行了消融分析,以說明主要模塊的有效性。表3展示了消融實驗的結果。
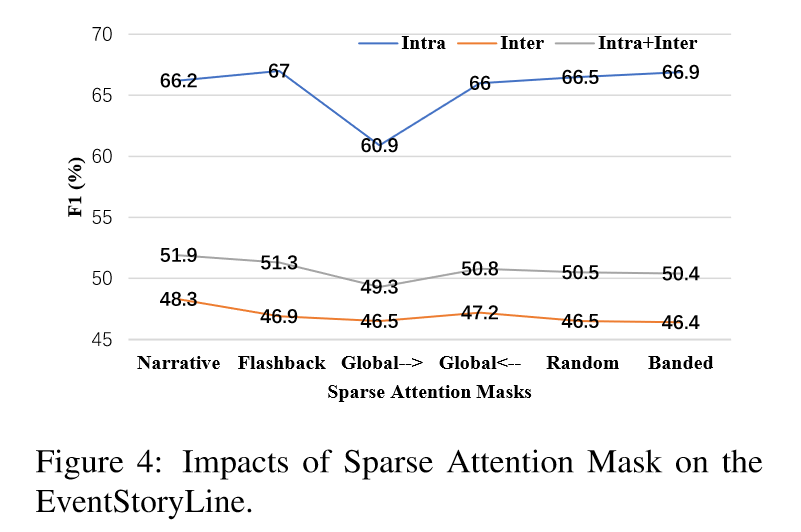
為了研究不同的稀疏注意力掩碼對SER(某個特定任務或模型的準確率)的影響,本文使用了以下不同的稀疏注意力掩碼:Narrative、Flashback、Global→、Global←、Random和Banded。從圖4中可以得到以下結論:(1)在句內,這些稀疏注意力掩碼除了Global→外,其他的結果都相似。這與之前的結果一致,即事件對更多地依賴于局部語境而不是遠距離的全局語境。(2)Random意外地表現良好,表明文檔中存在大量冗余信息,而稀疏掩碼矩陣可以減輕噪聲的影響。(3)Narrative取得了最佳性能,這反映了人類寫作習慣中的語言偏好——總是首先談論主題。
總結
本文將一種新穎的具有稀疏事件表示的判別推理方法SENDIR用于DERE。該方法可以學習高質量的事件表示,并促進文檔級理解中的跨句推理。實驗結果表明了方法的有效性,改善了句間情況,而不損害句內事件對。廣泛的分析還為稀疏長文本表示學習中的各種語言偏差提供了有趣的見解。SENDIR的局限性包括以下兩個方面:(1)它尚未擴展到文檔級別的以實體為中心的關系任務。本文工作是以事件為中心的,未來的工作將在實體為中心的情況下進行擴展。文檔級別的以實體為中心的關系抽取需要考慮實體的多次提及以及同一實體對的不同方向上的不同關系。(2)它沒有引入外部常識知識。知識可以用于豐富事件并提高準確的事件關系抽取。
OpenKG
OpenKG(中文開放知識圖譜)旨在推動以中文為核心的知識圖譜數據的開放、互聯及眾包,并促進知識圖譜算法、工具及平臺的開源開放。

點擊閱讀原文,進入 OpenKG 網站。



)










Java+ssm+MYSQL酒店大數據資源管理系統的設計與實現02029)




