D-VRNN模型和DD-VRNN模型
總體架構
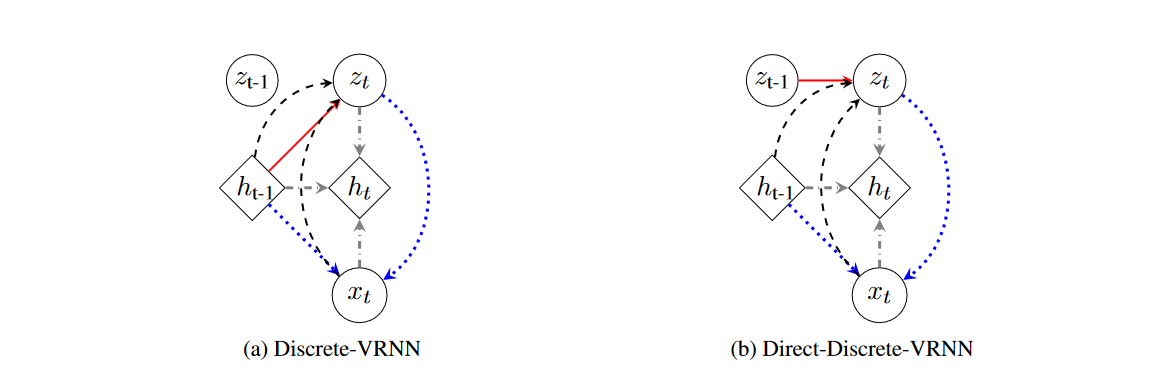
離散-可變循環變分自編碼器(D-VRNN)和直接-離散-可變循環變分自編碼器(DD-VRNN)概述。D-VRNN和DD-VRNN使用不同的先驗分布來建模 z t z_t zt?之間的轉換,如紅色實線所示。 x t x_t xt?的再生成用藍色虛線表示。狀態級別的循環神經網絡的循環關系以灰色虛線點劃線表示。 z t z_t zt?的推斷過程以黑色虛線表示。
方法
原則上,變分遞歸神經網絡(VRNN)在每個時間步都包含一個變分自編碼器(VAE),這些VAE通過一個狀態級的遞歸神經網絡(RNN)相連。在這個RNN中,隱藏狀態變量 h t ? 1 h_{t-1} ht?1? 編碼了直到時間 t t t 的對話上下文。這種連接幫助VRNN模擬對話的時間結構(Chung等人,2015年)。模型的觀測輸入 x t x_t xt? 是構建的話語嵌入。 z t z_t zt? 是時間 t t t 時VRNN中的潛在向量。與Chung等人(2015年)的工作不同,我們模型中的 z t z_t zt? 是一個離散的獨熱向量,其維度為 N N N,其中 N N N 是潛在狀態的總數。
D-VRNN與DD-VRNN之間的主要區別在于 z t z_t zt? 的先驗設定。在D-VRNN中,我們假設 z t z_t zt? 依賴于整個對話上下文 h t ? 1 h_{t-1} ht?1?,如圖(a)中紅色部分所示,這與Chung等人(2015年)的設定相同;而在DD-VRNN中,我們假設在先驗中, z t z_t zt? 直接依賴于 z t ? 1 z_{t-1} zt?1?,以模擬不同潛在狀態之間的直接轉換,如圖(b)中紅色部分所示。我們使用 z t z_t zt? 和 h t ? 1 h_{t-1} ht?1? 來重新生成當前話語 x t x_t xt?,而不是生成下一個話語 x t + 1 x_{t+1} xt+1?,如圖1中藍色虛線所示。重生成的思想有助于恢復對話結構。接下來,遞歸神經網絡利用 h t ? 1 h_{t-1} ht?1?, x t x_t xt? 和 z t z_t zt? 更新自身,并允許上下文隨著對話的進行而傳遞,如圖1中灰色點劃線所示。最后,在推斷中,我們用上下文 h t ? 1 h_{t-1} ht?1? 和 x t x_t xt? 構建 z t z_t zt? 的后驗,并通過從后驗中抽樣來推斷 z t z_t zt?,如圖1中黑色虛線所示。每個操作的數學細節在下文中描述。φ(·)τ 是高度靈活的特征提取函數,如神經網絡。 φ τ x φ_{τ}^x φτx? , φ z τ φzτ φzτ , φ τ p r i o r φ^{prior}_τ φτprior? , φ τ e n c φ^{enc}_τ φτenc? , φ τ d e c φ^{dec}_τ φτdec? 是分別用于輸入 x x x,潛在向量 z z z,先驗,編碼器和解碼器的特征提取網絡。
句子嵌入
用戶話語 u t = [ w 1 , t , w 2 , t , … , w n w , t ] u_t = [w_{1,t}, w_{2,t}, \ldots, w_{n_w,t}] ut?=[w1,t?,w2,t?,…,wnw?,t?] 和系統話語 s t = [ v 1 , t , v 2 , t , … , v n v , t ] s_t = [v_{1,t}, v_{2,t}, \ldots, v_{n_v,t}] st?=[v1,t?,v2,t?,…,vnv?,t?] 是在時間 t t t 的用戶話語和系統話語,其中 w i , j w_{i,j} wi,j? 和 v i , j v_{i,j} vi,j? 是單獨的詞語。兩方話語的連接, x t = [ u t , s t ] x_t = [u_t, s_t] xt?=[ut?,st?],是VAE中的觀測變量。我們使用Mikolov等人(2013年)的方法來進行詞嵌入,并對 u t u_t ut? 和 s t s_t st? 的詞嵌入向量進行平均,得到 u ~ t \tilde{u}_t u~t? 和 s ~ t \tilde{s}_t s~t?。 u ~ t \tilde{u}_t u~t? 和 s ~ t \tilde{s}_t s~t? 的連接被用作 x t x_t xt? 的特征提取,即 ? τ x ( x t ) = [ u ~ t , s ~ t ] \phi^x_\tau (x_t) = [\tilde{u}_t, \tilde{s}_t] ?τx?(xt?)=[u~t?,s~t?]。 ? τ x ( x t ) \phi^x_\tau (x_t) ?τx?(xt?) 是模型的輸入。
Prior in D-VRNN
在D-VRNN中,先驗是我們在觀察數據之前對 z t z_t zt? 的假設。在D-VRNN中,假設 z t z_t zt? 的先驗依賴于上下文 h t ? 1 h_{t-1} ht?1?,并遵循公式(1)中顯示的分布是合理的,因為對話上下文是影響對話轉換的關鍵因素。由于 z t z_t zt? 是離散的,我們使用softmax函數來獲取分布。
z t ~ softmax ( ? τ prior ( h t ? 1 ) ) (1) z_t \sim \text{softmax}(\phi^{\text{prior}}_\tau (h_{t-1}))\tag{1} zt?~softmax(?τprior?(ht?1?))(1)
Prior in DD-VRNN
DD-VRNN中的先驗。 z t z_t zt? 在公式(1)中對整個上下文 h t ? 1 h_{t-1} ht?1? 的依賴性,使得我們難以解開 z t ? 1 z_{t-1} zt?1? 與 z t z_t zt? 之間的關系。但這種關系對于解碼對話交換如何從一次流向下一次至關重要。因此,在DD-VRNN中,我們直接在先驗中模擬 z t ? 1 z_{t-1} zt?1? 對 z t z_t zt? 的影響,如公式(2)和圖1(b)所示。為了將這個先驗分布適配到變分推斷框架中,我們用公式(3)中的 p ( z t ∣ z t ? 1 ) p(z_t|z_{t-1}) p(zt?∣zt?1?) 來近似 p ( x t ∣ z t , z t ) p(x_t|z_{t}, z_{t}) p(xt?∣zt?,zt?)。稍后,我們將展示設計的新先驗在特定場景下的優勢。
z t ~ softmax ( ? τ prior ( z t ? 1 ) [ ] (2) z_t \sim \text{softmax}(\phi^{\text{prior}}_\tau (z_{t-1})[\tag{2}] zt?~softmax(?τprior?(zt?1?)[](2)
它表示潛在狀態 z t z_t zt? 的先驗分布直接依賴于前一時間步的潛在狀態 z t ? 1 z_{t-1} zt?1?,并通過特征提取函數 ? τ prior \phi^{\text{prior}}_\tau ?τprior? 映射和softmax函數來確定。
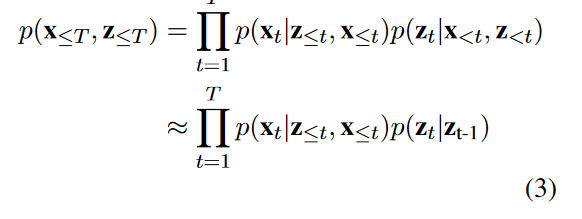
模型整體的概率分布可以近似為:
p ( x ≤ T , z ≤ T ) ≈ ∏ t = 1 T p ( x t ∣ z ≤ t , x < t ) p ( z t ∣ z t ? 1 ) (3) p(x_{\leq T}, z_{\leq T}) \approx \prod_{t=1}^{T} p(x_t|z_{\leq t}, x_{<t})p(z_t|z_{t-1})\tag{3} p(x≤T?,z≤T?)≈t=1∏T?p(xt?∣z≤t?,x<t?)p(zt?∣zt?1?)(3)
生成
z t z_t zt? 是在上下文下當前對話交換的概括。我們使用 z t z_t zt? 和 h t ? 1 h_{t-1} ht?1? 來重構當前的話語 x t x_t xt?。這種 x t x_t xt? 的重生產允許我們恢復對話結構。
我們使用兩個RNN解碼器,dec1和dec2,分別由參數 γ 1 \gamma_1 γ1? 和 γ 2 \gamma_2 γ2? 參數化,以分別生成原始的 u t u_t ut? 和 s t s_t st?。 c t c_t ct? 和 d t d_t dt? 是dec1和dec2的隱藏狀態。上下文 h t ? 1 h_{t-1} ht?1? 和特征提取向量 ? τ z ( z t ) \phi^z_\tau (z_t) ?τz?(zt?) 被連接起來,形成dec1的初始隱藏狀態 h 0 dec1 h^{\text{dec1}}_0 h0dec1?。 c ( n w , t ) c(n_w,t) c(nw?,t) 是dec1的最后一個隱藏狀態。由于 v t v_t vt? 是 u t u_t ut? 的響應,并且會受到 u t u_t ut? 的影響,我們將 c ( n w , t ) c(n_w,t) c(nw?,t) 與 d 0 d_0 d0? 連接起來,將信息從 u t u_t ut? 傳遞給 v t v_t vt?。這個連接向量被用作dec2的 h 0 dec2 h^{\text{dec2}}_0 h0dec2?。這個過程在公式(4)和(5)中顯示。
c 0 = [ h t ? 1 , ? τ z ( z t ) ] c_0 = [h_{t-1}, \phi^z_\tau (z_t)] c0?=[ht?1?,?τz?(zt?)]
w ( i , t ) , c ( i , t ) = f γ 1 ( w ( i ? 1 , t ) , c ( i ? 1 , t ) ) (4) w(i,t), c(i,t) = f_{\gamma_1}(w(i-1,t), c(i-1,t))\tag{4} w(i,t),c(i,t)=fγ1??(w(i?1,t),c(i?1,t))(4)
d 0 = [ h t ? 1 , ? τ z ( z t ) , c ( n w , t ) ] d_0 = [h_{t-1}, \phi^z_\tau (z_t), c(n_{w},t)] d0?=[ht?1?,?τz?(zt?),c(nw?,t)]
v ( i , t ) , d ( i , t ) = f γ 2 ( v ( i ? 1 , t ) , d ( i ? 1 , t ) ) (5) v(i,t), d(i,t) = f_{\gamma_2}(v(i-1,t), d(i-1,t))\tag{5} v(i,t),d(i,t)=fγ2??(v(i?1,t),d(i?1,t))(5)
遞歸過程
狀態級RNN根據以下等式(6)更新其隱藏狀態 h t h_t ht? 與 h t ? 1 h_{t-1} ht?1?。 f θ f_\theta fθ? 是由參數 θ \theta θ 參數化的RNN。
h t = f θ ( ? τ z ( z t ) , ? τ x ( x t ) , h t ? 1 ) (6) h_t = f_\theta (\phi^z_\tau (z_t), \phi^x_\tau (x_t), h_{t-1}) \tag{6} ht?=fθ?(?τz?(zt?),?τx?(xt?),ht?1?)(6)
推斷
我們根據上下文 h t ? 1 h_{t-1} ht?1? 和當前話語 x t x_t xt? 來推斷 z t z_t zt?,并構建 z t z_t zt? 的后驗分布,通過另一個softmax函數,如等式(7)所示。一旦我們得到了后驗分布,我們應用Gumbel-Softmax來取 z t z_t zt? 的樣本。D-VRNN和DD-VRNN在它們的先驗上有所不同,但在推斷上沒有不同,因為我們假設在先驗中 z t z_t zt? 之間的直接轉換而不是在推斷中。
z t ∣ x t ~ softmax ( ? τ e n c ( h t ? 1 ) , ? τ x ( x t ) ) (7) z_t|x_t \sim \text{softmax}(\phi^{enc}_\tau (h_{t-1}), \phi^x_\tau (x_t)) \tag{7} zt?∣xt?~softmax(?τenc?(ht?1?),?τx?(xt?))(7)
這段文字描述了變分遞歸神經網絡(VRNN)的損失函數,以及為了解決變分自編碼器(VAE)中潛在變量消失的問題,如何結合了兩種損失函數:bow-loss和Batch Prior Regularization (BPR)。以下是對該段落的翻譯以及相關公式的解釋:
損失函數
VRNN的目標函數是其在每個時間步的變分下界,如等式(8)所示(Chung等人,2015)。為了緩解VAE中潛在變量消失的問題,我們結合了bow-loss和Batch Prior Regularization (BPR)(Zhao等人,2017,2018)到最終的損失函數中,并引入了可調整的權重 λ \lambda λ,如等式(9)所示。
L VRNN = E q ( z ≤ T ∣ x ≤ T ) [ log ? p ( x t ∣ z ≤ t , x < t ) ] + \mathcal{L}_{\text{VRNN}} = \mathbb{E}_{q(z_{\leq T}|x_{\leq T})}[\log p(x_t | z_{\leq t},x_{<t})]+ LVRNN?=Eq(z≤T?∣x≤T?)?[logp(xt?∣z≤t?,x<t?)]+
∑ t = 1 T ? KL ( q ( z t ∣ x ≤ t , z < t ) ∥ p ( z t ∣ x < t , z < t ) ) (8) \sum_{t=1}^{T} -\text{KL}(q(z_t | x_{\leq t},z_{<t}) \| p(z_t | x_{<t},z_{<t}))\tag{8} t=1∑T??KL(q(zt?∣x≤t?,z<t?)∥p(zt?∣x<t?,z<t?))(8)
L D-VRNN = L VRNN-BPR + λ ? L bow (9) \mathcal{L}_{\text{D-VRNN}} = \mathcal{L}_{\text{VRNN-BPR}} + \lambda * \mathcal{L}_{\text{bow}} \tag{9} LD-VRNN?=LVRNN-BPR?+λ?Lbow?(9)
狀態轉移概率計算
一種既能數值表示又能視覺表示對話結構的好方法是構建一個潛在狀態之間的轉移概率表。這樣的轉移概率也可以用來設計在強化學習(RL)訓練過程中的獎勵函數。我們因為D-VRNN和DD-VRNN的先驗不同,所以分別計算它們的轉移表。
D-VRNN
從等式(6)我們知道 h t h_t ht? 是 x ≤ t x_{\leq t} x≤t? 和 z < t z_{<t} z<t? 的函數。結合等式(1)和(6),我們發現 z t z_t zt? 是 x ≤ t x_{\leq t} x≤t? 和 z < t z_{<t} z<t? 的函數。因此, z < t z_{<t} z<t? 對 z t z_t zt? 有一個間接的影響通過 h t ? 1 h_{t-1} ht?1?。這個間接影響加強了我們的假設,即前面的狀態 z < t z_{<t} z<t? 影響未來的狀態 z t z_t zt?,但也使得恢復一個清晰的結構和解開 z t ? 1 z_{t-1} zt?1? 對 z t z_t zt? 直接影響變得困難。
為了更好地可視化對話結構并與基于HMM的模型進行比較,我們通過估算二元轉移概率表來量化 z t ? 1 z_{t-1} zt?1? 對 z t z_t zt? 的影響,其中 p i , j = # ( s t a t e i , s t a t e j ) # ( s t a t e i ) p_{i,j} = \frac{\#(state_i,state_j)}{\#(state_i)} pi,j?=#(statei?)#(statei?,statej?)?。分子是有序對( s t a t e i , t ? 1 state_i, t-1 statei?,t?1, s t a t e j , t state_j, t statej?,t)的總數,分母是數據集中 s t a t e i state_i statei? 的總數。我們選擇一個二元轉移表而不是一個更大 n n n 的 n n n-gram轉移表,因為最近的上下文通常是最相關的,但應該注意的是,與HMM模型不同,我們模型中的轉移程度既不是有限的也不是預先確定的,因為 z t z_t zt? 捕獲了所有上下文。根據不同的應用,可能會選擇不同的 n n n。
命名實體離散變分遞歸神經網絡(NE-D-VRNN)
在任務導向對話系統中,某些命名實體的存在,如食物偏好,對于確定對話的階段起著關鍵作用。為了確保潛在狀態捕獲此類有用信息,我們在計算等式(9)中的損失函數時,對命名實體賦予更大的權重。這些權重鼓勵重構的話語含有更多正確的命名實體,因此影響潛在狀態有更好的表示。我們將這個模型稱為NED-VRNN(命名實體離散變分遞歸神經網絡)。



)
![[Android]使用Retrofit進行網絡請求](http://pic.xiahunao.cn/[Android]使用Retrofit進行網絡請求)






,bisect_right(nums,target))


SQL)
![TC397 EB MCAL開發從0開始系列 之 [15.1] Fee配置 - 雙扇區demo](http://pic.xiahunao.cn/TC397 EB MCAL開發從0開始系列 之 [15.1] Fee配置 - 雙扇區demo)



