目錄
一、前言
二、標記階段:引用計數算法
三、標記階段:可達性分析算法
(一)基本思路
(二)GC Roots對象
四、對象的finalization機制
五、MAT與JProfiler的GC Roots溯源
六、清除階段:標記-清除算法Mark-Sweep
七、清除階段:復制算法Copying
八、清除階段:標記-整理算法Mark-Compact
九、對比三種算法
十、分代收集算法
十一、增量收集算法、分區算法
一、前言
對于Java開發人員而言,自動內存管理就像是一個黑匣子,如果過度依賴于“自動”,那么將會是一場災難,最嚴重的莫過于弱化Java人員在程序出現內存溢出時定位問題和解決問題的能力。
所以了解JVM的自動內存分配和內存回收原理顯得非常重要,在遇見OOM的時候才能快速的根據錯誤異常日志定位問題和解決問題。
當需要排查各種內存溢出,內存泄漏問題時,當垃圾收集成為系統達到更高并發量的瓶頸時,我們必須對這些“自動化”的技術實施必要的監控和調節。
垃圾回收器可以對年輕代和老年代進行回收,甚至是全堆和方法區的回收,其中,Java堆時垃圾收集器的工作重點
從次數上講:頻繁手機Young區,較少收集Old區,基本不動方法區
那么什么是垃圾?
垃圾是指運行程序中沒有任何指針指向的對象,這個對象就是需要被回收的垃圾
二、標記階段:引用計數算法
對每個對象保存一個整型的引用計數器屬性,用于記錄被對象引用的情況。被對象引用了就+1,引用失效就-1,0表示不可能再被使用,可進行回收
優點:實現簡單,垃圾便于辨識,判斷效率高,回收沒有延遲性
缺點:
- 需要單獨的字段存儲計數器,增加了存儲空間的開銷
- 每次賦值需要更新計數器,伴隨加減法操作,增加了時間開銷
- 無法處理循環引用的情況,致命缺陷,導致JAVA的垃圾回收器中沒有使用這類算法
引用計數算法,是很多語言的資源回收選擇,例如python,它更是同時支持引用計數和垃圾回收機制,python如何解決循環引用
- 手動解除
- 使用弱引用,weakref,python提供的標準庫,旨在解決循環引用
三、標記階段:可達性分析算法
(一)基本思路
可達性分析算法是以根對象(GCRoots)為起始點,按照從上到下的方式搜索被根對象集合所連接的目標對象是否可達
使用可達性分析算法后,內存中存活的對象都被被根對象集合直接或間接連接著,搜索所走過的路徑稱為引用鏈。如果目標對象沒有任何引用鏈相連,則是不可達的,意味著該對象已經死亡,可以標記為垃圾對象。
在可達性分析算法中,只有能夠被根對象集合直接或者間接連接的對象才是存活的對象
(二)GC Roots對象
根對象(GC Roots)包括以下幾種:
- 虛擬機棧中引用的對象,比如:各個線程被調用的方法中使用到的參數、局部變量
- 本地方法棧內JNI,引用的對象
- 方法區中靜態屬性引用的對象,比如:java類的引用類型靜態變量
- 方法區中常量引用的對象,比如:字符串常量池里的引用
- 所有被同步鎖synchronized持有的對象
- Java虛擬機內部的引用,比如:基本數據類型對應的class對象,一些常駐的異常對象,如nullpointerException,OOMerror,系統類加載器
- 反映java虛擬機內部情況的JMXBean,JVMTI中注冊的回調,本地代碼緩存等
- ?除了固定的GC Roots集合之外,根據用戶選擇的垃圾收集器以及當前回收的內存區域不同,還可以有其他對象臨時性的加入,共同構成完整GCRoots集合,比如分代收集和局部回收(比如專門針對新生代的回收,那么其他非新生代 對象比如老年代也應該考慮作為root對象。因為新生代中的某些對象有可能被老年代的對象引用。)
如果需要使用可達性分析算法來判斷內存是否可回收,那么分析工作必須在一個能保障一致性的快照中進行。這點不滿足的話,分析結果的準確性就無法保證。
這也是GC進行時必須STW的一個重要原因,即使是號稱幾乎不會發生停頓的CMS收集器中,枚舉根節點也是必須要停頓的。
四、對象的finalization機制
Java語言提供了對象終止finaliztion機制來允許開發人員提供對象被銷毀之前的自定義處理邏輯。當垃圾回收器發現沒有引用指向一個對象,即垃圾回收此對象之前,總會先調用這個對象的finalize()方法。
finalize()方法允許在子類中被重寫,用于在對象被回收時進行資源釋放,通常在這個方法中進行一些資源釋放和清理的工作,比如關閉文件,套接字和數據庫鏈接等
對象的三種狀態:
- 可觸及的:從根節點開始,可以到達這個對象
- 可復活的:對象的所有引用都被釋放了,但是對象有可能在finalize()中復活
- 不可觸及的:對象的finalize()被調用,并且沒有復活,那么就會進入不可觸及狀態。不可觸及的對象不可能被復活,因為finalize()只會被調用一次
- 只有對象再不可觸及時才可以被回收
判斷一個對象ObjA是否可以被回收,至少需要經歷兩次標記過程
- 1、如果對象到GCRoots沒有引用鏈,則進行第一次標記
- 2、進行篩選,判斷此對象是否有必要執行finalize()方法
- 如果對象A沒有重寫finalize方法,或者finalize方法已經被虛擬機調用過,則虛擬機視為沒有必要執行,對象A被判定為不可觸及的
- 如果對象A重寫finalize()方法,且還未執行過,那么A會被插入到F-queue隊列中,有一個虛擬機自動創建的,低優先級的Finalizer線程觸發其finalize()方法執行
- finalize方法是對象逃脫死亡的最后機會,稍后GC會對F-queue隊列中的對象進行第二次標記,如果A在finalize方法中與引用鏈上的任何一個對象建立了聯系,那么在第二次標記時,A會被移除即將回收集合。之后,對象會再次出現沒有引用存在的情況下,finalize方法不會再被調用,對象直接變為不可觸及狀態
public class CanRelliveObj {public static CanRelliveObj obj;@Overrideprotected void finalize() throws Throwable {super.finalize();System.out.println("調用當前類重寫 finalize 方法");obj = this;}public static void main(String[] args) {try {// 先創建一個對象,分配下內存,不然重來沒出現過何來回收一說obj = new CanRelliveObj();obj = null;System.gc(); // 回收時會調用對象的finalize方法,第一次調用成功拯救自己System.out.println("第一次 gc");// 因為Finalizer線程優先級很低,暫停2s,等待它Thread.sleep(2000);if(obj == null) {System.out.println("obj dead");} else {System.out.println("obj is still alive");}System.out.println("第二次 gc");obj = null;System.gc(); // 此時回收對象發現finalize方法已經被調用,所以直接進行回收if(obj == null) {System.out.println("obj dead");} else {System.out.println("obj is still alive");}} catch (Exception e) {}}
}五、MAT與JProfiler的GC Roots溯源
MAT是Memory Analyzer的簡稱,是一款功能強大的Java堆內存分析器。用于查找內存泄露以及查看內存消耗情況,基于Eclipse開發的一款免費性能分析工具
可以用于分析GC Roots對象
六、清除階段:標記-清除算法Mark-Sweep
標記:從引用根節點開始遍歷,標記所有被引用的對象,一般是在對象Header中記錄為可達對象
注意標記引用對象,不是垃圾對象
清除:對堆內存從頭到尾進行線性的遍歷,如果發現某個對象在其Header中沒有標記為可達對象,則將其回收
缺點
- 效率不算高
- 在GC的時候,需要停止整個應用程序,導致用戶體驗差。
- 這種方式清理出來的空閑內存不連續,產生內存碎片,需要維護一個空閑列表
何為清除?
所謂的清除并不是真的置空,而是把需要清除的對象地址保存在空閑的地址列表里,下次有新對象需要加載時,判斷垃圾的位置空間是否夠,如果夠就存放。
總結:第一次遍歷標記可達對象,第二次遍歷清除未標記對象。清除實際上是將未標記對象加入空閑列表,下次有新對象產生,判斷空閑列表中垃圾的位置放不放的下,放得下就覆蓋。
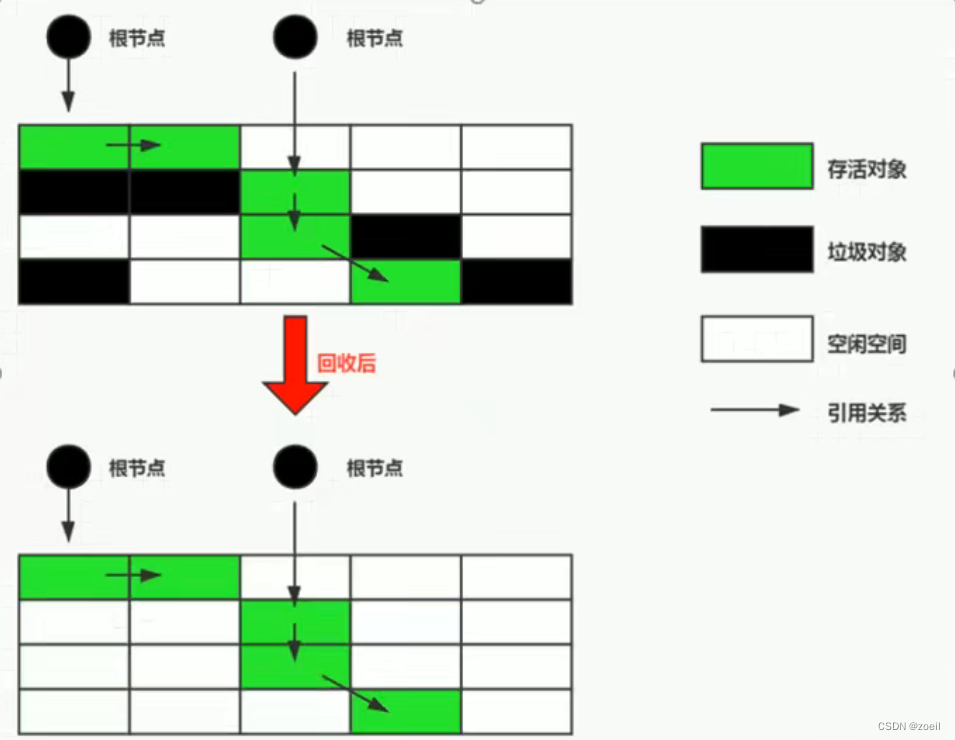
七、清除階段:復制算法Copying
為了解決標記-清除算法在垃圾收集效率方面的缺陷——產生內存碎片。1963年出現了復制(Copying)算法
原理:將或者的內存空間分為兩塊,每次使用其中一塊。在垃圾回收時,將正在使用的內存中的存活的對象復制到未被使用的內存塊中,之后清除正在使用的內存塊中的所有的對象,交換兩個內存的角色,最后完成垃圾回收
優點
- 沒有標記和清除的過程,實現簡單高效
- 復制過去以后的保證空間的連續性,不會出現碎片的問題
缺點
- 需要兩倍的內存空間
- 對于G1這種拆分為大量region的GC,復制而不是移動,意味著GC需要維護region之間的引用關系(就像對象的兩種),不管是內存占用或者時間開銷也不小。
注意:如果系統中的垃圾對象很多,需要復制的存活對象數量并不會太大,或者非常低使用復制算法效率才會高。想一想,如果每次復制都發現垃圾對象很少,基本每次復制都是全部移動,那效率肯定很低。
應用場景:
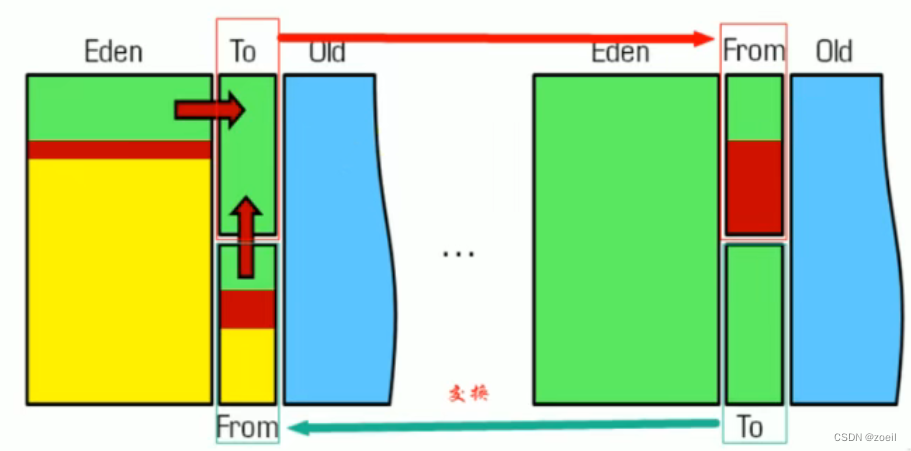
在新生代,對常規應用的垃圾回收,一次通常可以回收70%-90%的內存空間。回收性價比很高,所以現在的商業虛擬機都是用這種手機算法回收新生代。?(記得from區和to區嗎,為什么總有一個區是空的,現在聯系起來了。使用的就是是復制算法)
八、清除階段:標記-整理算法Mark-Compact
標記-整理又叫標記-壓縮算法。
背景:復制算法的高效性是建議在存活對象少,垃圾對象多的前提下的。適用于新生代,而老年代大部分對象都是存活對象,所以并不適用,否則復制成本較高。因此,基于老年代垃圾回收的特性,需要使用其他算法。
標記-清除算法可以應用在老年代中,但是該算法不僅執行效率低下,而且執行完內存回收后還會產生內存碎片。所以JVM的設計者在此基礎之上進行改進,標記-整理垃圾收集算法誕生了。
執行過程
- 第一個階段和標記清除算法一樣,從根節點開始標記所有被引用的對象
- 第二階段將所有的存貨對象壓縮在內存的一端,按照順序排放,之后清理邊界外所有的空間
- 最終效果等同于標記清除算法執行完成后,再進行一次內存碎片整理。
與標記清除算法本質區別,標記清除算法是非移動式的算法,標記壓縮是移動式的
優點
- 消除了標記-清除算法內存區域分散的缺點,
- 消除了復制算法中,內存減半的高額代價
缺點
- 從效率上來講,標記整理算法要低于復制算法
- 移動對象的同時,如果對象被其他對象引用,則還需要調整引用的地址
- 移動的過程中,需要全程暫停用戶應用程序,即STW

九、對比三種算法

效率上來說,復制算法是最快的(因為不像標記-清除和標記整理那樣需要標記,還有整理),但是浪費了太多的內存。?
而標記-整理算法相對來說更加平滑一些,但是效率上不太行,比復制算法多了一個標記的階段,比標記-清除多了一個整理內存的階段。
想到了一個問題:復制算法不標記怎么知道一個對象是否存活,是否需要進行復制?
即:復制算法不用進行標記嗎?
查閱相關資料后,明白了。復制算法沒有像標記-清除和標記-整理兩個方法一樣有單獨的標記過程。因為復制gc只需要把“活”的對象拷貝到survivor,還要mark什么呢?至于怎么判斷是“活”的,gc roots以下的不都是“活”的?復制算法是從gc roots開始,遇到活對象就復制走了。gc roots找可達對象的過程結束就復制完了。不像標記算法那樣,對于一個對象是否需要回收要滿足兩個條件:① 對象不可達;②沒必要執行finalize方法。
java gc中為什么復制算法比標記整理算法快? - 簡書
十、分代收集算法
不同生命周期的對象可以采取不同額收集方式,以便提高回收效率
幾乎所有的GC都采用分代收集算法執行垃圾回收的
HotSpot中
- 年輕代:生命周期短,存活率低,回收頻繁
- 老年代:區域較大,生命周期長,存活率高,回收不及年輕代頻繁
十一、增量收集算法、分區算法
(一)增量收集算法思想
每次垃圾收集線程只收集一小片區域的內存空間,接著切換到應用程序線程,依次反復,直到垃圾收集完成
通過對線程間沖突的妥善管理,允許垃圾收集線程以分階段的方式完成標記、清理或復制工作
缺點:線程和上下文切換導致系統吞吐量的下降
(二)分區算法
為了控制GC產生的停頓時間,將一塊大的內存區域分割成多個小塊,根據目標的停頓時間,每次合理的回收若干個小區間,而不是整個堆空間,從而減少一次GC所產生的時間
分代算法是將對象按照生命周期長短劃分為兩個部分,分區算法是將整個堆劃分為連續的不同的小區間
每一個小區間都獨立使用,獨立回收,這種算法的好處是可以控制一次回收多少個小區間



,bisect_right(nums,target))


SQL)
![TC397 EB MCAL開發從0開始系列 之 [15.1] Fee配置 - 雙扇區demo](http://pic.xiahunao.cn/TC397 EB MCAL開發從0開始系列 之 [15.1] Fee配置 - 雙扇區demo)










 操作符的妙用)
