【論文閱讀筆記】Emu Edit: Precise Image Editing via Recognition and Generation Tasks
- 論文閱讀筆記
- 論文信息
- 摘要
- 背景
- 方法
- 結果
- 額外
- 關鍵發現
- 作者動機
- 相關工作
- 1. 使用輸入和編輯圖像的對齊和詳細描述來執行特定的編輯
- 2. 另一類圖像編輯模型采用輸入掩碼作為附加輸入 。
- 3. 為了提供更直觀和用戶友好的界面,并顯著增強了人類易用性
- 方法/模型
- 任務分類
- 指令生成
- 圖像對生成
- Grounded Precise Editing
- Region-Based Editing Tasks
- Free-Form Editing Tasks
- Vision tasks
- 數據過濾
- Method
- 網絡架構
- 學習任務嵌入
- 任務反轉
- Sequential Edit Thresholding序列修改閾值
- 實驗設計
- 指標
- 評價
- baseline
- 消融研究
- 討論
- 展望
- 啟發
- 訓練代價
- 總結
論文閱讀筆記
- Emu edit是一篇圖像編輯Image Editing的文章,和instruct pix2pix類似,選擇了合成數據作為訓練數據,不是zero-shot任務,并進一步將多種任務都整合為生成任務,從而提高模型的編輯能力。本篇文章的效果應該目前最好的,在local和global編輯甚至其他代理任務(分割、邊緣檢測等)上都取得了比較驚艷的效果。
- 個人比較關注合成數據的制作流程,能夠很好的解決現有真實數據數量和泛化能力受限的問題。
- 文章的很多細節在附錄,值得好好研究。
- 數據集制造的工程量太大了!!!
論文信息
- 論文標題:Emu Edit: Precise Image Editing via Recognition and Generation Tasks
- 作者:GenAI. Meta
- 發表年份:2023
- 期刊/會議:暫無
- 項目主頁(更多可視化結果):https://emu-edit.metademolab.com/
- 數據集(驗證):https://huggingface.co/datasets/facebook/emu_edit_test_set_generations
- code:未發布

摘要
背景
基于指令的圖像編輯需求很大,但是在編輯準確性上還受限。
方法
提出了一種多任務圖像編輯模型Emu Edit,將多種任務(基于區域的編輯、自由形式的編輯和計算機視覺任務)表述為生成任務,并學習任務嵌入(有點類似unicontrolnet指示不同任務的編碼)以指導生成過程走向正確的編輯類型。
結果
我們表明 Emu Edit 可以推廣到新任務,例如圖像修復、超分辨率和編輯任務的組合,并在圖像編輯任務中取得了最先進水平
額外
發布了一個新的具有挑戰性和通用的基準,其中包括7個不同的圖像編輯任務。
關鍵發現
- 多任務學習,為每個任務開發不同的數據處理pipeline,允許搜集更為多樣化和精確的訓練集。
- 在所有任務上訓練單個模型比在每個任務上獨立訓練專家模型產生更好的結果。
- 檢測、分割等計算機視覺任務顯著提高了圖像編輯性能。(ps. 可以在其他任務上進行嘗試)
- 證明了學習到的任務嵌入顯著提高了我們的模型從自由形式指令中準確推斷適當的編輯類型并執行正確的編輯的能力
- 任務嵌入可以在訓練好的模型上面經過few-shot訓練進行更新,如超分,輪廓檢測
作者動機
InstructPix2Pix這樣的基于指令的圖像編輯模型旨在處理任何給定的指令,但它們通常難以準確解釋和執行此類指令。此外,它們的泛化是有限的,往往缺乏對與他們接受過培訓的任務的輕微偏差。
為了解決這些差距,引入了 Emu Edit,第一個在大量多樣的任務上訓練的圖像編輯模型,包括圖像編輯和計算機視覺任務。
Emu Edit 在遵守編輯指令和保留原始圖像的視覺保真度方面都提供了實質性的改進。
兩個基準上的自動度量和人類主觀評價表示Emu Edit在基于指令的圖像編輯中取得了最先進的結果。
相關工作
(很好地總結了一些有影響力的工作)
1. 使用輸入和編輯圖像的對齊和詳細描述來執行特定的編輯
- Prompt2prompt(P2P)將輸入標題注意力圖注入目標標題注意力圖。
- Null-Text Inversion 使用零文本嵌入反轉輸入圖像以支持使用p2p進行真實圖像的編輯。
- Plug-and-Play(PNP)除了注意圖外,還注入空間特征,并在全局編輯上獲得了更好的性能。
- Imagic 微調擴散模型以支持復雜的文本指令。
- EDICT提出了一種基于兩個噪聲向量的圖像反演,以實現更好的圖像重建和文本忠實度。
2. 另一類圖像編輯模型采用輸入掩碼作為附加輸入 。
- blended diffusion通過在未屏蔽區域混合輸入圖像來修改擴散步驟。
- Imagen Editor 和 SmartBrush 微調文本到圖像模型以輸入圖像和掩碼為條件。
雖然上面詳述的基于文本的圖像編輯方法使人類能夠編輯圖像,但它們經常表現出不一致的性能,并且需要多個輸入,例如輸入圖像和目標圖像的對齊和詳細描述,或者有時是輸入掩碼。
3. 為了提供更直觀和用戶友好的界面,并顯著增強了人類易用性
- InstructPix2Pix 引入了一個可指示的圖像編輯模型。他們通過利用 GPT-3和 Prompt-to-Prompt開發了這個模型,以生成用于基于指令的圖像編輯的大型合成數據集,并使用數據集來訓練可指示的圖像編輯模型。
- MagicBrush通過要求人類使用在線圖像編輯工具開發了一個手動注釋的指令引導圖像編輯數據集。在這個數據集上微調 InstructPix2Pix 可以提高圖像編輯能力。
最先進的圖像編輯模型仍然難以準確解釋和精確地執行編輯指令。
Emu Edit與僅關注圖像編輯(pix2pix, magicbrush)的先前工作不同,訓練模型執行各種任務并學習非常多樣化能力。訓練過程和數據集的質量和多功能性,以及改進的多任務學習架構,使其能夠在性能上取得很大的飛躍,并區別于該領域的先前工作。
方法/模型
- 訓練一個健壯和準確的圖像編輯模型需要高度多樣化的輸入圖像數據集、編輯指令和輸出編輯的圖像。
- 構建了一個包含 16 個不同的任務和 10 億個示例的新數據集。數據集中的每個示例 (cI , cT , x, i) 都包含一個輸入圖像 cI 、文本指令 cT 、目標圖像 x 和任務索引 i(16個不同任務 )。
任務分類

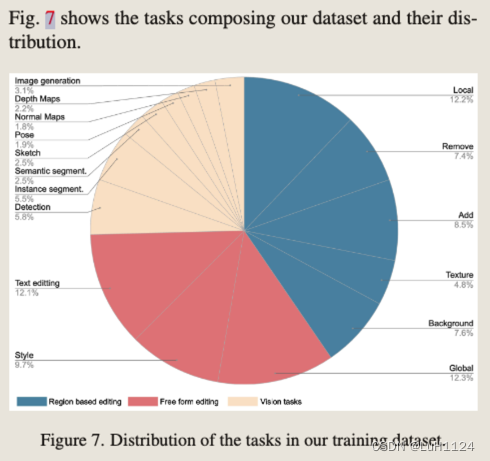
指令生成
- 通過Llama2利用上下文學習為每個任務創建一個特定于任務的代理。具體來說,我們向LLM提供了一個任務描述、一些特定于任務的范例和一個真實的圖像標題。為了增加多樣性,我們對樣本進行采樣并隨機化它們的順序。給定這樣的輸入,我們期望LLM輸出(1)編輯指令,(2)理想輸出圖像的輸出標題,(3)應該更新或添加到原始圖像中
通過以下方式提供 LLM:(1)描述輸入和輸出格式的系統消息,(2)介紹消息,其中我們概述了輸出中每個鍵的問題和目標,以及 (3) 與 LLM 的對話歷史上下文包含可能輸出的示例。然后,我們用一個新的輸入標題提示LLM,并要求它提供一個新的指令。為了鼓勵 LLM 生成的指令中更多的方差和隨機性,我們對歷史上下文執行以下:(1)示例之間的混洗,(2)隨機抽樣 60% 的示例,以及(3)從一組單詞中隨機更改示例中的動詞。
圖像對生成階段使用圖像標題,以及指令生成階段生成的LLM對應的輸出標題“原始對象”和“編輯對象”
圖像對生成
- 目標是生成符合編輯指令的輸入和編輯圖像對,并保留應該保持完整的圖像元素
- 為應對不同任務所需的數據集,為每個任務開發了一種新的生成技術
Grounded Precise Editing
P2P 依賴于輸入圖像標題和編輯圖像標題中的詞對詞對齊來構建掩碼修改注意力圖,但詞對詞的約束并不強,無法保留結構和身份。Emu edit提出了一種掩碼提取方法,該方法應用于編輯過程之前。
(i)通過 LLM 從編輯指令中識別編輯區域并在圖像生成之前創建相應的掩碼
基于區域的編輯包括所有在有限區域內對圖像進行更改的編輯指令,其余圖像保持不變。為了在保留其余細節的同時調整特定對象或位置,我們在編輯過程中利用了局部區域的掩碼。我們利用DINO來檢測需要屏蔽的區域,使用LLM中提取出的Object字段對應的“原始對象”和“編輯對象”字段。
使用基于掩碼的注意力控制來生成編輯圖像時,它通常用相似的對象類型替換對象,而不是刪除它。例如,當屏蔽狗周圍的區域時,我們將編輯限制在該特定區域,從而產生狗的新變體。我們通過創建三種不同類型的掩碼來解決這個問題。第一個采用由DINO和SAM創建的原始精確掩碼。第二個涉及通過膨脹將掩碼擴展到添加的對象之外,然后使用高斯模糊對其進行細化。最后,第三種方法使用對象周圍的邊界框(由 DINO 創建),從而消除了特定形狀的約束。我們生成多個圖像,每個圖像都有不同的掩碼,然后過濾。
在某些情況下,LLM 生成的“原始對象”和“編輯對象”包含所有格詞(例如,“狗的尾巴”)。我們觀察到,在許多情況下,DINO 在這些情況下很難檢測到對象。為此,我們對LLM使用額外的提示來識別沒有擁有的對象。
(ii)在編輯過程中集成這些掩碼,以確保編輯區域與原始圖像無縫融合。
基于掩碼的注意力控制:保持非編輯區域的噪聲來自原圖,編輯區域的噪聲圖像注意力影響之后的。遵循 P2P 并在所有標記上注入自注意力層。交叉注意力層注入輸入和輸出字幕之間的公共標記
此外:面對不同的編輯挑戰,例如添加或刪除對象,需要量身定制的解決方案。(見附錄的7.2.3-5)
Region-Based Editing Tasks
1.Local/Texture
給定輸入標題,我們首先生成輸入圖像。然后,我們利用“原始對象”(如第 7.2 節所述)來提取局部掩碼(使用第 7.2.2 節)。最后,我們使用獲得的掩碼應用基于掩碼的注意力控制來生成編輯的圖像。我們重復這個過程 10 次迭代,在每次迭代中,我們從 [4, 8] 中采樣引導尺度,從 [0.3, 0.9] 中采樣 Nc 和 Ns(執行交叉注意力和自注意力的步驟N),并從 [0.02, 0.2] (在這個階段執行混合操作)混合。
2.添加
提取“編輯對象”(在這種情況下添加的對象)的掩碼是不可能的,因為輸入圖像中不存在對象。
為了克服這一挑戰,我們解決這個問題如下: 1. 我們使用輸出標題生成輸出圖像 y。請注意,圖像 y 包含“編輯對象”。2.提取y中“編輯對象”的掩碼m。3.我們應用基于掩碼的注意力控制使用輸入標題、圖像 y 和掩碼 m 生成輸入圖像 x 這種方法的主要問題是,在某些情況下,我們生成對象的不同版本,而不是消除它
3.刪除
生成數據的過程類似于 Add 任務的過程。唯一的區別是我們首先生成圖像 x(使用輸入標題),然后提取對象的掩碼 m 以去除,最后使用輸出標題、圖像 x 和掩碼 m 生成圖像 y。
4.背景
給定一個輸入圖像、輸入標題和編輯的對象(在這種情況下,替代背景),我們首先提取背景掩碼。為了消除輪廓中的偽影,我們應用了擴展背景掩碼的最小濾波器,然后使用高斯濾波對其進行平滑處理。接下來,我們將圖像和生成的掩碼作為輸入提供給修復模型,該模型創建一個新的背景。最后,我們將輸入圖像和編輯后的圖像混合在掩碼區域。我們生成了 10 張編輯圖像,具有不同的噪聲和引導尺度,并根據 CLIP 指標選擇最佳圖像。
Free-Form Editing Tasks
4.全局
全局任務包括不限于特定區域的編輯指令。因此,我們使用帶有空白掩碼的基于掩碼的注意力控制生成圖像對。混合是從 [0.1, 0.2] 中采樣的,以鼓勵更好的圖像忠實度。我們從 [0.4, 0.9] 中采樣 Nc 和 Ns。
5.風格
我們使用即插即用(PNP)來生成風格化的編輯圖像。該任務的目標是在保留圖像結構的同時,根據編輯指令改變圖像樣式。我們使用DDIM反演將PNP應用于真實的輸入圖像。對于每個樣本,我們生成 10 個編輯圖像,每個圖像都具有以下采樣參數:從 [6.5, 110] 中采樣的引導尺度,Ns 從 [0.5, 1.0] 中采樣,并且要共享的空間特征部分設置為 0.8。
6.文本編輯
文本編輯任務包括向圖像添加文本,從圖像中刪除文本,并用另一個文本替換一個文本。此外,我們允許用戶選擇添加文本的字體和顏色。我們使用 OCR [7] 生成輸入圖像 x 中找到的文本的掩碼 m。我們利用掩碼 m 來修復圖像,表示新圖像 y。為了添加文本,我們使用 y 作為輸入圖像,x 作為編輯圖像。為了刪除文本和替換文本,我們使用反向。在替換文本時,我們將圖像 y 中的內嵌區域與特定字體和顏色的文本疊加。
Vision tasks
7.檢測/分割
給定一個輸入圖像,我們使用DINO檢測“編輯對象”。為了將檢測形式化為生成任務,我們通過繪制檢測到的邊界框來創建一個新的圖像 y。對于分割,我們繪制檢測到的對象像素。
8.顏色
我們將顏色任務定義為對圖像整體顏色的修改。我們通過應用以下過濾器生成樣本:(1)顏色過濾器——隨機改變圖像的亮度、對比度、飽和度和色調,(2)模糊——應用隨機大小的高斯核,以及(3)銳化和散焦。
9.Image Translation
涉及從條件圖像到目標圖像的雙向映射。例如,草圖到圖像和圖像到草圖。我們遵循ControlNet來生成深度圖、分割圖、人體姿勢、法線圖和草圖。
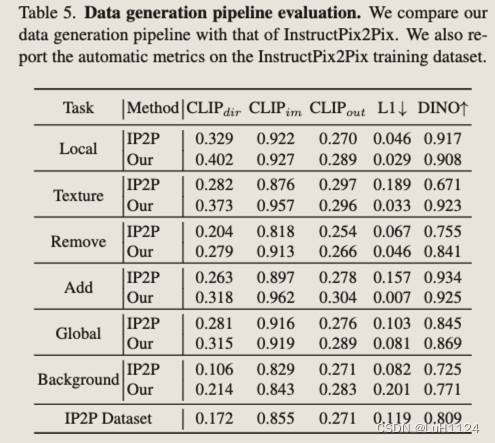
數據過濾
(i)使用任務預測器用應該屬于另一個任務的指令重新分配樣本,(ii)應用 CLIP 過濾指標
(iii)采用基于輸入圖像深度圖和編輯圖像之間的 L1 距離的結構保留過濾
(iv)應用圖像檢測器來驗證元素的存在(在 Add 任務中),根據指令中指定的對象,元素的缺失(在 Remove 任務中)或替換(在 Local 任務中)。
此過程過濾掉 70% 的數據,從而產生 1000 萬個樣本的最終數據集。
Method
- 為了為模型提供將生成過程引導到正確任務的強條件,建議為每個任務學習一個唯一的任務嵌入,我們將其集成到模型中。
- 在訓練期間,任務嵌入與模型權重一起學習。訓練后,Emu Edit 能夠通過小樣本學習新任務嵌入來適應新任務,其余模型被凍結。
- 最后,介紹了一種在多輪編輯場景中保持生成圖像質量的方法。
網絡架構
- 基于Emu擴散模型
- 為了將Emu轉換為基于指令的圖像編輯模型,我們將其限制在待修改的cI和指令cT上(類似pix2pix,調整輸入Uner的輸入通道數,新的權重被初始化為0,使用a zero signalto-noise ratio (SNR)技術) min ? θ E y , ? , t [ ∥ ? ? ? θ ( z t , t , E ( c I ) , c T ) ∥ 2 2 ] \min _\theta \mathbb{E}_{y, \epsilon, t}\left[\left\|\epsilon-\epsilon_\theta\left(z_t, t, E\left(c_I\right), c_T\right)\right\|_2^2\right] θmin?Ey,?,t?[∥???θ?(zt?,t,E(cI?),cT?)∥22?]
學習任務嵌入
在訓練期間,給定我們數據集中的樣本,我們使用任務索引 i 從嵌入表中獲取任務的嵌入向量 vi,并將其與模型權重聯合優化。我們通過將任務嵌入通過 U-Net、εθ 的附加條件引入來做到這一點。具體來說,我們通過交叉注意交互將任務嵌入集成到 U-Net 中,并將其添加到時間步嵌入中。優化問題更新為
min ? θ E y , ? , t [ ∥ ? ? ? θ ( z t , t , E ( c I ) , c T , v i ) ∥ 2 2 ] \min _\theta \mathbb{E}_{y, \epsilon, t}\left[\left\|\epsilon-\epsilon_\theta\left(z_t, t, E\left(c_I\right), c_T, v_i\right)\right\|_2^2\right] θmin?Ey,?,t?[∥???θ?(zt?,t,E(cI?),cT?,vi?)∥22?]
(1)當需要紋理編輯時,沒有任務條件的模型可能會執行全局編輯
(2)當需要全局編輯時,它可能會選擇分割
(3)在本地編輯更適合的情況下實現樣式編輯。

任務反轉
給定新任務的幾個示例,我們學習了一個新的任務嵌入 vnew。凍結模型權重,并且僅通過任務嵌入將其適應任務。(實驗證明不學習也能泛化新任務)
min ? θ E y , ? , t [ ∥ ? ? ? θ ( z t , t , E ( c I ) , c T , v n e w ) ∥ 2 2 ] \min _\theta \mathbb{E}_{y, \epsilon, t}\left[\left\|\epsilon-\epsilon_\theta\left(z_t, t, E\left(c_I\right), c_T, v_{new}\right)\right\|_2^2\right] θmin?Ey,?,t?[∥???θ?(zt?,t,E(cI?),cT?,vnew?)∥22?]
Sequential Edit Thresholding序列修改閾值
多次對同一圖像進行序列化編輯會由于累計error產生偽影,Emu Edit設置了一個像素編輯閾值,超過一定程度才使用上次編輯結果,否則還使用上次的輸入圖像。文章中的fig12展示了該項更詳細的消融實驗。


實驗設計
- 評估方法在基于指令的圖像編輯任務上的性能
- 一項全面的消融研究,以評估不同貢獻的有效性(消除了計算機視覺任務對圖像編輯任務模型性能的貢獻、學習任務嵌入的重要性以及多任務學習對基于指令的圖像編輯的影響)
- 數據生成管道消融實驗
- 學習新任務的能力
指標
(i) CLIP文本圖像方向相似度(CLIPdir) -測量字幕變化與圖像變化之間的一致性
(ii) CLIP圖像相似度(CLIPimg) -測量編輯圖像和輸入圖像之間的變化
(iii) CLIP輸出相似度(CLIPout) -測量編輯后的圖像與輸出標題的相似度
(iv)輸入圖像和編輯圖像之間的L1像素距離
(v) DINO輸入和編輯圖像的DINO嵌入之間的相似性。
(vi)人類評估者評估文本對齊和圖像忠實度
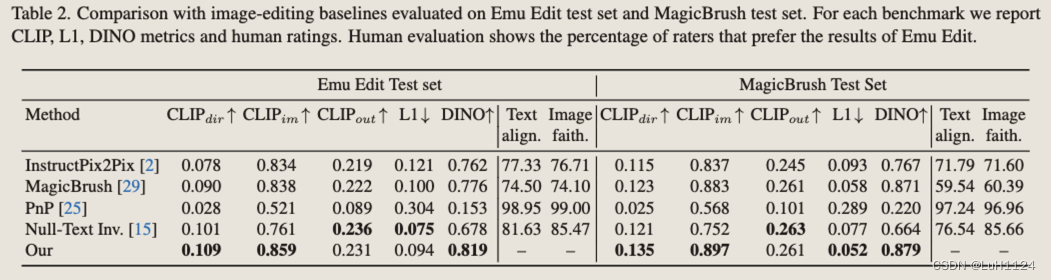
評價
MagicBrush 測試集和Emu Edit 基準測試的結果,認為pix2pix的評價基準并不友好
- MagicBrush使用來自MS-COCO基準和注釋器定義的指令的不同真實輸入圖像集。在數據收集期間,注釋者旨在使用DALLE-2 圖像編輯平臺來生成編輯的圖像,基準偏向于 DALLE-2 編輯器可以成功遵循的編輯指令,這可能會損害其多樣性和復雜性。
- Emu 編輯基準。收集偏差降低且多樣性較高的數據集,首先定義了七種不同類別的潛在圖像編輯操作:背景更改(背景)、全面的圖像更改(全局)、樣式更改(樣式)、對象刪除(Remove)、對象添加(Add)、本地化修改(Local)和顏色/紋理更改(Texture)。利用MagicBrush基準的不同輸入圖像集,對于每個編輯操作,人工設計相關、創造性和具有挑戰性的指令。人工過濾具有不相關指令的示例。最后,為了支持對需要輸入和輸出標題的方法的評估,我們還收集了輸入標題和輸出標題。這樣做時,我們要求注釋者確保字幕捕獲圖像中的兩個重要元素,以及應該根據指令更改的元素。已公開發布以支持更好地評估基于指令的圖像編輯模型。
baseline
InstructPix2Pix
MagicBrush
PNP
P2P 的 Null-Text 反演修改

消融研究
-
視覺任務的重要性
(i)檢測和分割任務可以增強局部編輯能力(ii)圖像到圖像翻譯任務可以增強自由模式下的編輯 -
任務嵌入的重要性,任務嵌入有助于明確編輯目標

-
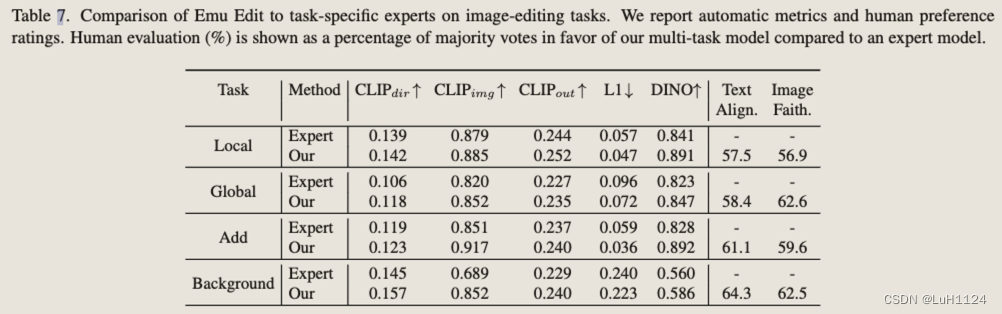
多任務與專家模型比較,幾乎全面超越
-
消融了參與多任務訓練方案的任務數量,任務數越多,效果提升越好
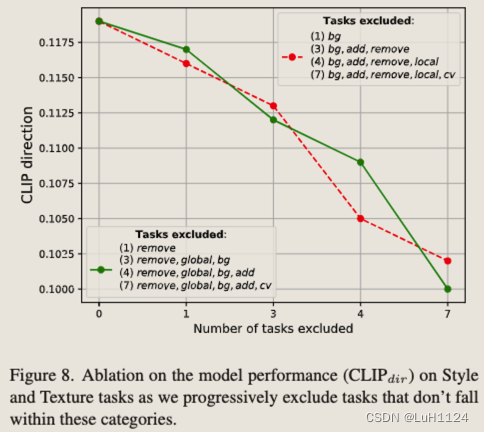
-
新任務的few-shot fintune,100個樣本下的finetune足以比肩專家模型
討論
展望
更好地和LLM相結合,這種增強對于編輯任務特別有用,這些任務需要從輸入圖像中進行更復雜的推理,例如計數對象或執行復雜的、高度詳細的任務。
啟發
- 多任務學習有助于模型更好地理解自然語言指令以執行更精準的編輯
- 它能夠以最小的示例推廣到圖像修復和超分辨率等新任務,進一步證明了其多功能性和高級理解。
訓練代價
使用Emu的縮小版本,該版本以 CLIP ViT-L [18] 和 T5-XL [19] 為條件,并以 512 × 512 的分辨率生成圖像。通過連接到pix2pix之后的輸入通道來調整它以獲得圖像輸入。通過交叉注意和時間步嵌入來調節文本和任務嵌入。對于訓練,使用批量大小為 512 的 Adam 優化器。我們使用 2e-5 的學習率為,余弦衰減時間表和 2,000 次迭代的線性預熱。訓練跨越 48,000 步。
總結
總的來說,證明了多任務學習對于圖像編輯有著正向的提升,能夠更好的理解文本指令。同時更類似于一個backbone,few-shot的finetuning就可以遷移到其他新任務。
)

)




)











)