innoDB是按照頁為單位讀寫的
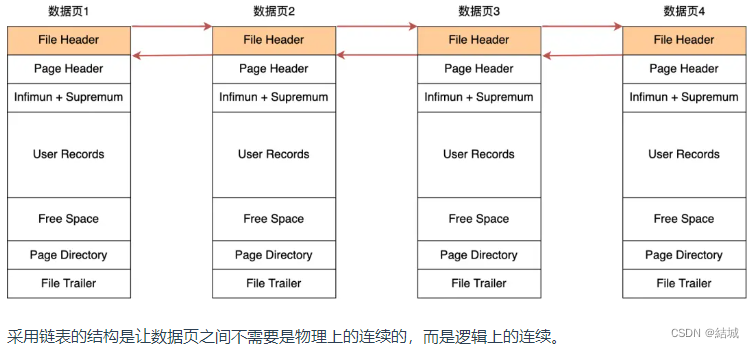
那頁中有很多行數據,是怎么執行查詢的呢,首先我們肯定,是以單向列表形式存儲的,提高了增刪的效率,但是查詢效率低。所以實際上對頁中的行數據進行了優化,能以二分的方式進行查詢,執行這一操作的機制叫做頁目錄,在頁的內部建立分組(包括最大和最小記錄,但不包括被刪除了的記錄)。按照從小到大順序排列,每組的最大的記錄的頭信息(file_header)存儲著本組記錄的數量(見粉紅色字段)。頁目錄存儲的是最后一條記錄的地址偏移量(槽、slot,相當于頁目錄有個指針,指向每個組的最后一條記錄)。所以二分就能根據每個slot的最大值判定當前查詢應該去哪個分組。
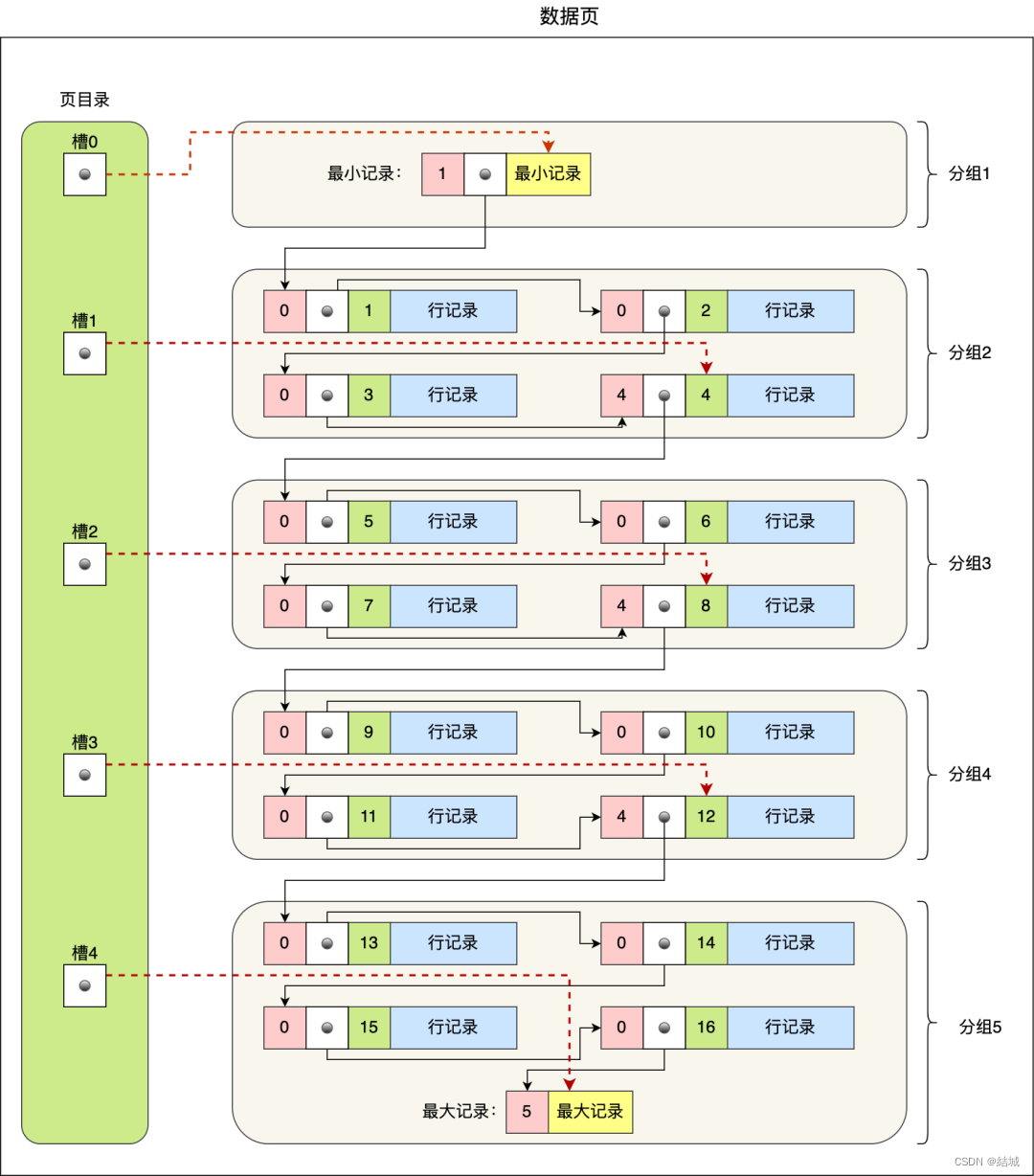
然后我們抽象到更高層次,頁如何被查詢的?其實B+樹的每個節點都是一頁,只不過非葉子節點的數據是指針。葉子節點才是真的數據。
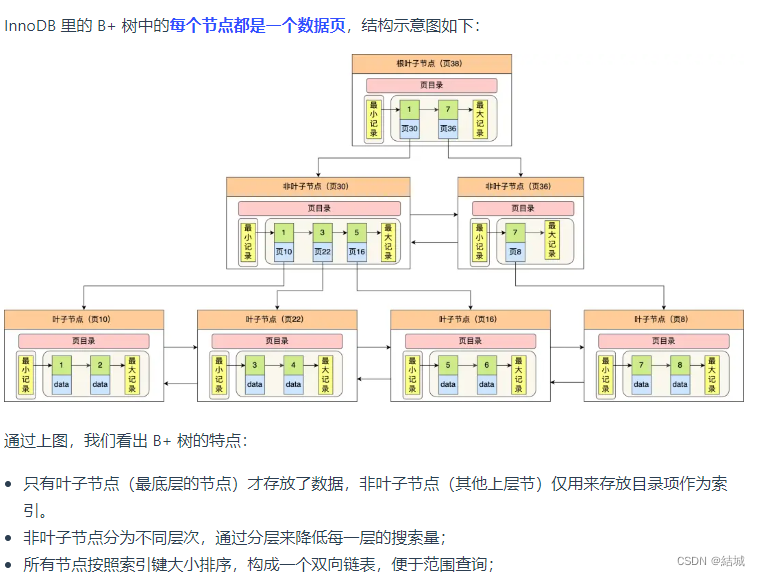
然后索引又分為聚簇索引和二級索引。
聚簇索引一般是主鍵索引,如果沒有主鍵就選不包含NULL值得唯一列,如果還沒有MySQL會創建一個隱藏的自增id列當作聚簇索引。聚簇索引葉子節點存的是真實數據。
二級索引就是建立的索引,葉子節點存放的是主鍵值,也就是說用了二級索引,查到后,還要用查到的主鍵值再查一遍聚簇索引才能獲取數據結果,這個過程叫做回表。但假如你要查的就是主鍵,那就只查一次即可。
mysql中數據是如何被用B+樹查詢到的
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/161736.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/161736.shtml 英文地址,請注明出處:http://en.pswp.cn/news/161736.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

Mac Goland無法調試
去github上下載golang的debug工具delve:
go-delve/delve?github.com/go-delve/delve/blob/master/Documentation/installation/README.md?編輯
或者:
go install github.com/go-delve/delve/cmd/dlvlatest按照他的安裝方式進行安裝,最后會在本地的…

基于北方蒼鷹算法優化概率神經網絡PNN的分類預測 - 附代碼
基于北方蒼鷹算法優化概率神經網絡PNN的分類預測 - 附代碼 文章目錄 基于北方蒼鷹算法優化概率神經網絡PNN的分類預測 - 附代碼1.PNN網絡概述2.變壓器故障診街系統相關背景2.1 模型建立 3.基于北方蒼鷹優化的PNN網絡5.測試結果6.參考文獻7.Matlab代碼 摘要:針對PNN神…

Java面試-框架篇-Mybatis
Java面試-框架篇-Mybatis MyBatis執行流程延遲加載使用及原理一, 二級緩存來源 MyBatis執行流程
讀取MyBatis配置文件: mybatis-config.xml加載運行環境和映射文件構造會話工廠SqlSessionFactory會話工廠創建SqlSession對象(包含了執行SQL語句的所有方法)操作數據庫的接口, Ex…

vue腳手架的基礎搭建過程
MVVM架構
Vue框架底層設計遵循MVVM架構。
Model層(M)模型層(業務邏輯層)
View層(V)視圖層 主管UI
ViewModel層(VM) 將項目代碼劃分清晰的層次結構后,非常有利于后期代…

IP地址定位技術發展與未來趨勢
隨著互聯網的快速發展,人們對網絡的需求和依賴程度越來越高。在海量的網絡數據傳輸中,IP地址定位技術作為網絡安全與信息追蹤的重要手段,其精準度一直備受關注。近年來,隨著技術的不斷進步,IP地址定位的精準度得到了顯…

【wireshark】基礎學習
TOC
查詢tcp tcp 查詢tcp握手請求的代碼 tcp.flags.ack 0 確定tcp握手成功的代碼 tcp.flags.ack 1 確定tcp連接請求的代碼 tcp.flags.ack 0 and tcp.flags.syn 1 3次握手后確定發送成功的查詢 tcp.flags.fin 1 查詢某IP對外發送的數據 ip.src_host 192.168.73.134 查詢某…

)
python趣味編程-5分鐘實現一個太空大戰游戲(含源碼、步驟講解)
飛機戰爭游戲系統項目是使用Python編程語言開發的,是一個簡單的桌面應用程序。
Python 中的飛機戰爭游戲使用pygame導入和隨機導入。
Pygame 是一組跨平臺的 Python 模塊,專為編寫視頻游戲而設計。它包括設計用于 Python 編程語言的計算機圖形和聲音庫。

以jar包形式 部署Spring Boot項目
后端部署
當你將Spring Boot項目打包成JAR文件并上傳到服務器時,可以考慮在服務器上創建一些目錄來存放這個JAR文件以及相關的配置文件。以下是一些常見的目錄結構建議: /opt/your-project-name/: 在/opt目錄下創建一個與你的項目名稱相關的…

【word技巧】Word制作試卷,ABCD選項如何對齊?
使用word文件制作試卷,如何將ABCD選項全部設置對齊?除了一直按空格或者Tab鍵以外,還有其他方法嗎?今天分享如何將ABCD選項對齊。
首先,我們打開【替換和查找】,在查找內容輸入空格,然后點擊全部…


20個CSS函數-釋放設計創造力和響應能力
20個CSS函數-釋放設計創造力和響應能力
CSS是網頁設計的核心,使開發者和設計者能夠制作出令人嘆為觀止和反應迅速的網頁布局。CSS函數通過引入動態性和多功能性提升了我們的設計能力。在本文中,我們將開始講解20個CSS函數。
1.rgba():定義顏…


【應用前沿】索托斯平臺:個性化推薦變身SaaS 服務
隨著互聯網技術和人工智能的迅速發展,面對海量的數據和資源,如何快速準確地為每個用戶提供其感興趣的內容,成為我們亟待解決的問題。個性化推薦系統正是為了解決這一問題而誕生的,它能夠通過對用戶行為的分析和挖掘,為…
![[Ubuntu]RT810xE--網線已拔出--問題解決](http://pic.xiahunao.cn/[Ubuntu]RT810xE--網線已拔出--問題解決)
[Ubuntu]RT810xE--網線已拔出--問題解決
0 環境
ubuntu 22.04.3 LTSDell Inspiron 15 5547windows/ubuntu 雙系統
1 問題說明
Dell 筆記本安裝的 Ubutun 系統,有線網絡無法使用,一直顯示 “網線已拔出”。
網上一查,才了解到主要原因:網卡驅動安裝錯誤。系統默認安裝…

5-6求1-20的階乘和
#include<stdio.h>
//求階乘
int main(){int n;double sum0;//求和:一點一點加int t1;for (n1;n<15;n){tt*n;sumsumt;}printf("結果是:%22.15e \n",sum);return 0;
}為啥最后是%22.15e呢? 因為這個求和的結果太大了 所以轉…
![轉移表達式:<![CDATA[ ]]>](http://pic.xiahunao.cn/轉移表達式:<![CDATA[ ]]>)
轉移表達式:<![CDATA[ ]]>
你是否遇到過:在mybatis 時我們sql是寫在xml 映射文件中,如果寫的sql中有一些特殊的字符的話,在解析xml文件的時候會被轉義,但我們不希望他被轉義,所以我們要使用<![CDATA[ ]]>來解決。
<![CDATA[ ]]> …

【譯】什么時候使用 Spring 6 JdbcClient
原文地址:Spring 6 JdbcClient: When and How to Use it?
一、前言
自 Spring 6.1 起,JdbcClient 為 JDBC 查詢和更新操作提供了統一的客戶端 API,從而提供了更流暢、更簡化的交互模型。本教程演示了如何在各種場景中使用 JdbcClient。
二…

【VScode】安裝配置、插件及遠程SSH連接
一、VSCode安裝 二、配置安裝插件 三、配置遠程連接SSH 四、MinGW
一、VSCode安裝
VS官網 Visual Studio Code - Code Editing. Redefined下載安裝包: 二、配置安裝插件
安裝中文插件 配置字體為20
配置文件–>首選項->設置->Font Size為20
設置 VSC…

【libGDX】使用Mesh繪制圓形
1 前言 使用Mesh繪制三角形 中介紹了繪制三角形的方法,使用Mesh繪制矩形 中介紹了繪制矩形的方法,本文將介紹繪制圓形的方法。 libGDX 以點、線段、三角形為圖元,沒有提供繪制圓形的接口。要繪制圓形邊框,必須通過割圓法逼近圓形&…