隨著互聯網技術和人工智能的迅速發展,面對海量的數據和資源,如何快速準確地為每個用戶提供其感興趣的內容,成為我們亟待解決的問題。個性化推薦系統正是為了解決這一問題而誕生的,它能夠通過對用戶行為的分析和挖掘,為用戶提供精準、個性化的推薦服務,極大地提高了信息獲取的效率和用戶體驗,在電商、新聞資訊、視頻、音樂、閱讀等領域被廣泛應用。
然而,一套完整的個性化推薦系統建設,除了需要巨大的人力物力投入,還需要長時間的數據積累和算法調優,具有較高的使用成本,讓很多團隊望而卻步。
如何讓個性化推薦系統像 SaaS 服務一樣被低成本使用呢?360內容平臺部依托于深厚的推薦算法能力和強大的內容創作平臺,通過對推薦系統的算法和引擎平臺化,經過多個業務場景的打磨,推出了索托斯推薦平臺,為客戶提供低成本的一體化推薦服務。

索托斯,以行業標準化協議,接入各個應用場景的待推薦資源和用戶的行為日志,通過自動化的數據流生產系統完成識別、標注、向量化等內容理解,通過平臺化的一系列算法模型訓練實現資源和用戶的畫像特征等數據挖掘,基于 A/B 實驗平臺和 Debug 系統,對算法模型進行自動調參,按照預定目標自我優化,給接入方提供該場景個性化推薦的最優解。
整體架構如下:

首先是系統的標準化接入。
對于推薦系統來說,通俗地理解就是根據用戶的各種行為推測其興趣喜好,然后給用戶推薦其感興趣的資源,比如給經常看娛樂資訊的用戶推一條明星八卦。因而,用戶的行為和要推薦的資源就是推薦系統最基礎的要素,那么該如何把這兩類數據高效地接入到推薦系統呢?
對于SaaS化推薦系統,接入的推薦場景可能包括資訊、視頻、壁紙、商品、短劇等多種屬性各異的資源,不同資源的用戶行為也千差萬別。索托斯對數據接入分資源和行為做了一層標準化抽象:對于資源,定義通用屬性,數據可以通過消息隊列或文件的方式同步到推薦系統生產平臺,然后以統一的生產加工流程完成資源的審核、標注、內容理解、正排提取、倒排構建,對于不同資源類別的個性化屬性,索托斯的生產平臺以流程分支的方式支持屬性定義和處理,底層自動擴展相應的語義體系;對于用戶行為,采用日志打點上報的方式,定義通用的打點規范,指定核心提升指標,行為日志自動經過實時計算產生算法模型的輸入語料。
其次是通用算法服務。
推薦系統中,算法服務主要包括召回、排序、策略幾大類。其中召回服務通過算法模型獲取初始的數據集,然后由排序服務通過特征進行打分排序,最后由策略服務做裝屏:按資源類別和用戶畫像進行數據打散、過濾、強插等操作。具體圖示如下:

在復雜的實際生產環境中,不同的算法服務依賴各自不同的語料,經過模型訓練,產生不同的結果文件,比如用戶畫像、倒排隊列、特征、向量、tag等,然后供在線服務使用,或者作為二級語料進行下一步的模型訓練。這些差異一方面會降低系統的可擴展性和復用性,另一方會增加系統的維護成本。
為了便于算法服務平臺化,我們對算法服務進行了標準化架構優化。首先是定義統一的算法模型的各種輸入語料格式和接入標準。推薦系統原始語料主要是用戶的曝光、點擊、點贊、收藏、關注等用戶行為日志和資源數據,通過Flink實時計算框架,對日志進行標準化的語料預處理生成以下幾種初始語料:按請求 id 合并的單位時間窗口內每個用戶的行為序列,資源的單位時間行為統計,用戶的點擊序列。然后,把算法服務拆分成離線和在線,在線服務提供統一協議的PB 格式數據,由推薦引擎調度;離線服務,統一數據解析規范,基于上述的初始語料,通過核心算法模型進行數據訓練,產生畫像、倒排等結果集。整體如下圖:

通過上述標準化處理,目前索托斯平臺集成了推薦系統核心的算法服務,其中召回服務涵蓋高熱、畫像、icf、vicf、validFilter、dssm、tagicf、berttagemblarge、tagemb、rankshare、lda 等超過20算法。這些通用算法服務在內容平臺的視頻、cube 等核心推薦場景經過充分驗證,在各類適用的場景中有顯著的效果提升,如下圖:

推薦系統中各個環節的實時日志處理、算法模型訓練、離線任務等,都離不開穩定的大數據計算平臺。索托斯依賴的是技術中臺提供的強大的奇麟大數據平臺,針對業務敏感的Flink實時任務,一方面虛擬化團隊從底層計算資源做隔離,通過對磁盤LVM條帶化和網絡加速等方面的優化,使得計算集群機器有極致的性能保障;另一方面系統部團隊對這種實時大規模數據處理的任務,對 Flink 進行深讀定制優化,在集群資源調度方面實現了更智能、高效的動態策略,在高可用方面提供了更加柔性、穩定的災備預案。因而,在多個團隊的鼎力支持下,索托斯的大數據底座堅如磐石。
然后是持續增長。
幾乎所有場景接入推薦服務之后,都會面臨如何持續提升數據指標的問題。索托斯從兩個方面著手,其一,提供一站式用戶分析與運營平臺,為接入方提供多維度效果分析指標數據,通過歸因分析模型挖掘用戶側、資源側潛在的優化和改進點,輔助發現業務的關鍵增長方向,科學地進行產品優化;另一方面各個算法模型向上層暴露超參,每個算法通過多個參數枚舉組合的方式,自動進行多組 A/B 實驗,根據實驗結果自動選擇最優參數放量,實現系統的自我迭代優化。

最后是系統自動化運維。
從安全和穩定的角度,各個接入場景的資源、服務、數據都是完全相互隔離的。每個接入場景的各類算法服務至少有20多個,眾多的接入場景的數百上千的服務,運維成了棘手的問題,因此,索托斯平臺實現了一套自動化運維系統。
對于眾多的服務,我們通過 ops 的 wonder 系統采集的基礎硬件指標數據和通用算法服務采集的業務指標數據分別進行分鐘級的分時對比、單位時間累計對比,同時參考日環比、周同比,以準確發現異常并歸因出問題,然后根據問題類型分別采取不同的自動化處理預案。比如,某個服務監測到耗時 P99上升,同時集群所有機器的 cpu利用率都同比升高,且到某個設定的閾值(比如50%),則判定集群負載高,此時自動進行彈性擴容,如果只是某臺機器異常,那則可根據這臺機器的綜合指標判斷是進程問題還是機器問題,以進行服務重啟或機器彈性替代等自動化運維動作。具體詳見下圖:
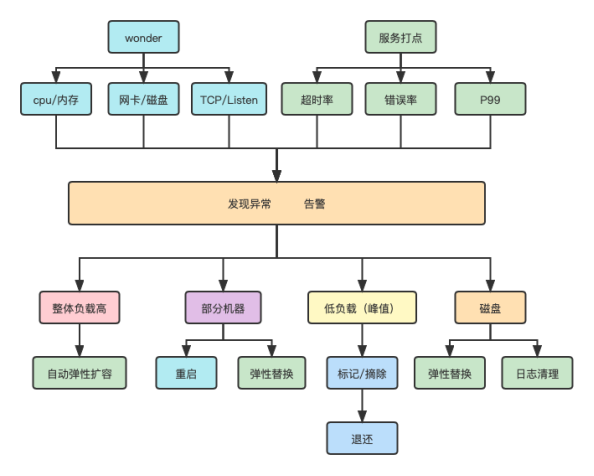
經過全方面的系統基礎能力建設,加上內容平臺核心推薦場景的不斷打磨優化,以及持續的功能迭代,目前索托斯已經具備優越的 toB 能力,并在瀏覽器畫報、鎖屏壁紙、開機小助手、衛士資訊彈窗、導航 cube、商業化小說、付費短劇、小游戲等場景接入,為各個業務帶來100%甚至更高的核心指標提升。
![[Ubuntu]RT810xE--網線已拔出--問題解決](http://pic.xiahunao.cn/[Ubuntu]RT810xE--網線已拔出--問題解決)

![轉移表達式:<![CDATA[ ]]>](http://pic.xiahunao.cn/轉移表達式:<![CDATA[ ]]>)






![[遞歸]有理數樹](http://pic.xiahunao.cn/[遞歸]有理數樹)





)
安裝Powershell)


