Spark的通用運行流程與Spark YARN Cluster 模式的運行流程
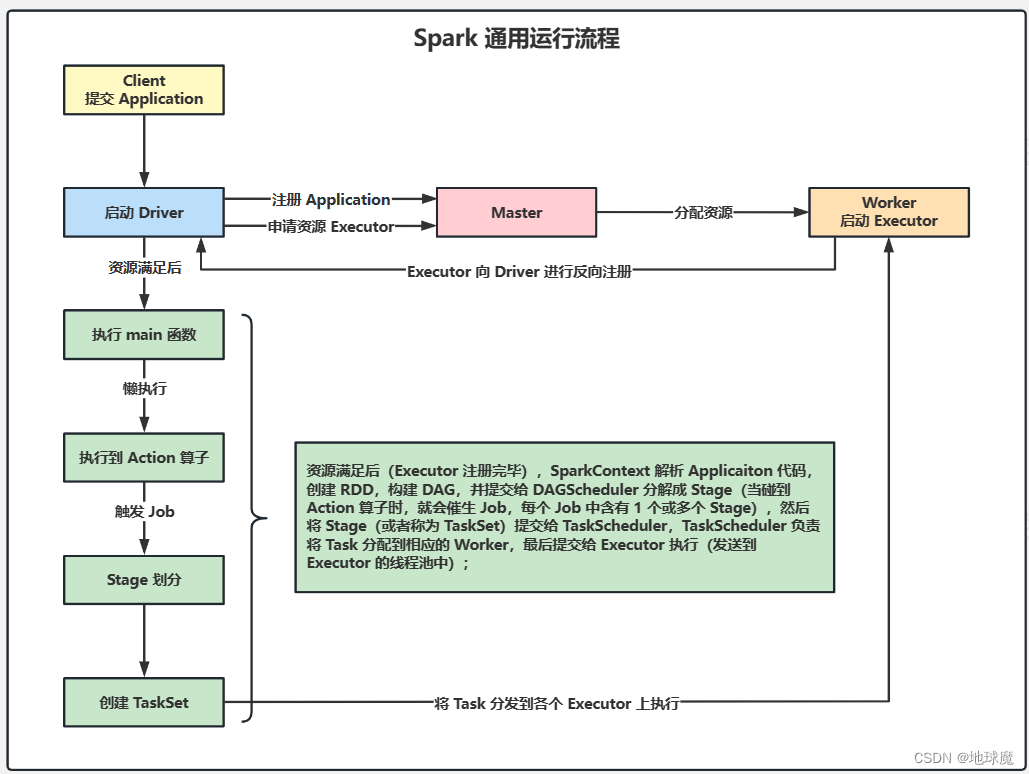
集群啟動后Worker節點會向Master節點心跳匯報資源 Client向Driver提交APP,根據不同的運行模式在不同的地方創建Driver。 Driver以粗粒度的方式向Master注冊應用并申請資源(在Application執行之前,將所有的資源申請完畢,當資源申請成功后,才會進行任務的調度,當所有的Task執行完成后,才會釋放這部分資源。)(資源有Executer的CPU Core和Mem) Master根據SparkContext的資源申請情況以及Worker心跳周期內報告的信息決定在哪個Worker上分配資源,也就是Executer。 Worker節點創建Executer進程,Executer向Driver反向注冊。 資源滿足后(Executer注冊完畢)SparkContext解析代碼,創建RDD,構建DAG,并提交給DAGScheduler分解成Stage(當碰到行動算子時,會催生job,每一個job有一個或多個Stage),然后Stage提交給TaskScheduler,TaskScheduler負責將Task分配給相應的Worker,最后提交Executer執行。 每個Executer會有一個線程池,Executer通過啟動多個線程(Task)來對RDD的Partition進行并行計算,并向SparkContext報告,直到Task完成。 所有Task完成后,SparkContext向Master注銷,釋放資源。
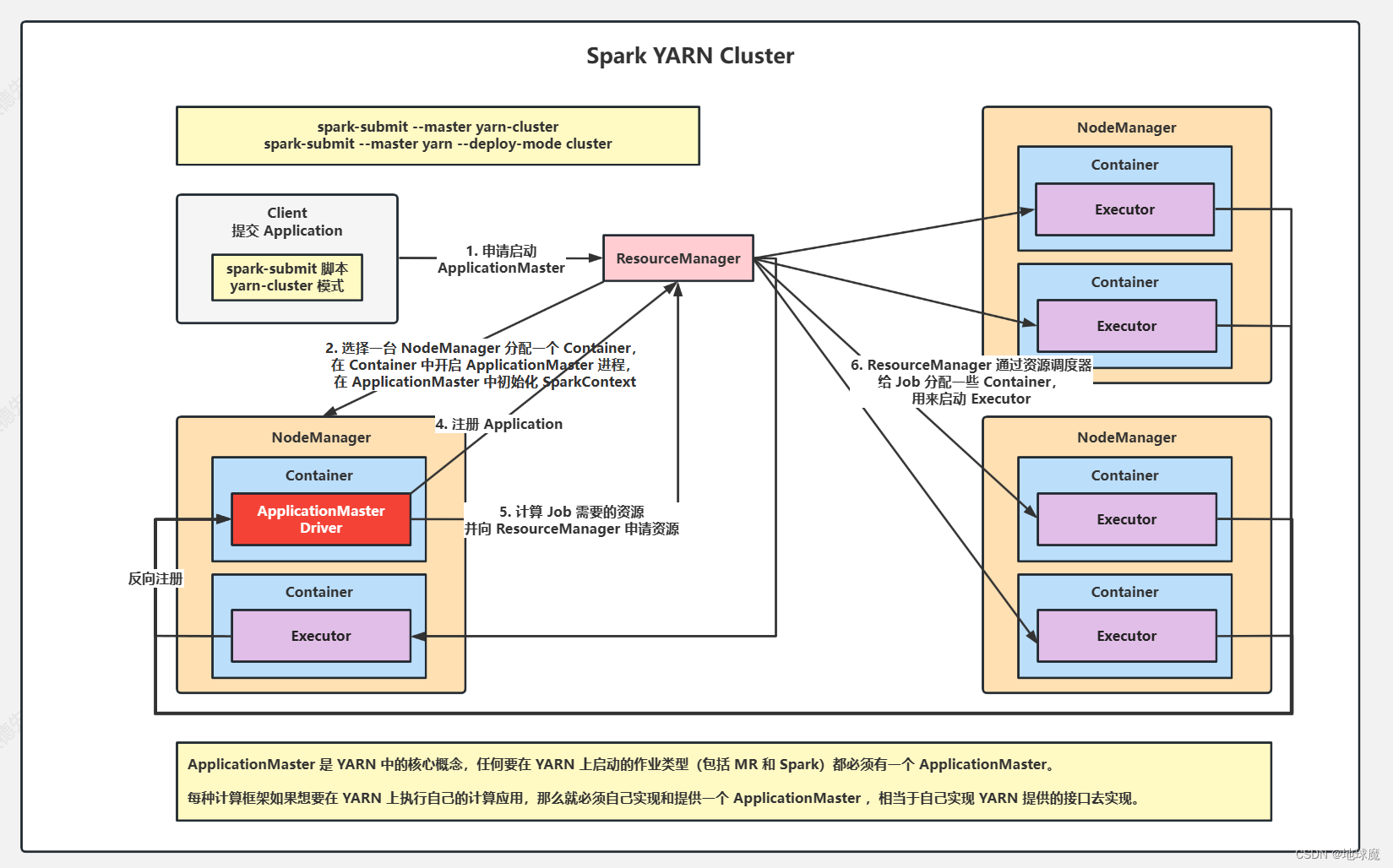
第一個階段是把Spark的Driver作為一個ApplicationMaster在YARN集群中啟動 第二個階段是由ApplicationMaster創建應用程序,然后為他向ResourceManager申請資源,并啟動Executer來運行Task,同時監控他的整個過程,直到運行完成。 在YARN Cluster模式下,Driver運行在ApplicationMaster中。程序啟動后會和ResourceManager通訊申請啟動ApplicationMaster; ResourceManager收到請求后,通過ResourceScheduler選擇一臺NodeManager分配一個Container,在Container中開啟ApplicationMaster進程;同時在ApplicationMaster中初始化Driver; ApplicationMaster向ResourceManager注冊,這樣用戶可以直接通過ResourceManager查看應用程序的運行狀態,然后他將采用輪詢的方式通過RPC協議為各個任務申請資源,并監控他們運行狀態直到運行結束; 一旦ApplicationMaster申請到資源(也就是Container)后,便與對應的NodeManager通信,在NodeManager的Container中啟動CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend啟動后會向Driver中的SparkContext反向注冊并申請Task。 Applicat給ionMaster中的SparkContext分配Task給CoarseGrainedExecutorBackend執行,CoarseGrainedExecutorBackend運行Task并向ApplicationMaster匯報運行的狀態和進度,方便ApplicationMaster隨時掌握各個任務的運行狀態,從而可以在任務失敗時重新啟動任務。 應用程序運行完成后,ApplicationMaster向ResourceManager申請注銷并關閉自己。該模式下只能通過YARN查看日志。 Client模式: 在Client模式下,驅動程序(Spark應用的主程序)運行在提交作業的客戶端機器上,而不是集群中。 驅動程序與集群中的資源不直接交互,而是依賴于客戶機的機器資源,包括CPU,內存和網絡帶寬等。 客戶端負責與ResourceManager通信以請求容器來運行ApplicationMaster和Executor,并且客戶端還會負責監控Spark應用發運行狀態。 由于驅動程序運行在客戶端機器上,因此跟容易地監控和調試作業,開發人員可以直接查看驅動程序的日志和輸出。 Cluster模式: 在Cluster模式下,驅動程序運行在集群中,由ResourceManager分配資源,作業提交后,ResourceManager會啟動一個ApplicationManager來管理作業的執行,并分配資源給各個Executor 客戶機僅用于提交作業,一旦作業提交成功后,客戶機的角色就結束了。整個作業運行過程由集群負責,包括資源分配和任務的調度。 由于作業的執行不依賴于客戶端機器的資源,而是利用整個集群的資源,因此Cluster模式適合用于生產環境中的大規模數據處理。
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。
如若轉載,請注明出處:http://www.pswp.cn/news/161443.shtml
繁體地址,請注明出處:http://hk.pswp.cn/news/161443.shtml
英文地址,請注明出處:http://en.pswp.cn/news/161443.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!







RKNPU詳解)




)


真題解析#中國電子學會#全國青少年軟件編程等級考試)

】)
![[論文筆記] Scaling Laws for Neural Language Models](http://pic.xiahunao.cn/[論文筆記] Scaling Laws for Neural Language Models)
