
在當前多模態 AI 和大模型技術風頭正勁的背景下,Jina AI 始終領跑于創新前沿,技術領先。2023 年 10 月 30 日,Jina AI 隆重推出 jina-embeddings-v2,這是全球首款支持 8192 輸入長度的開源向量大模型,其性能媲美 OpenAI 的閉源 text-embedding-ada002。如今,jina-embeddings-v2 正式登陸 AWS Marketplace,為中大型企業提供了私有化部署向量模型的理想解決方案。
作為亞馬遜云科技創業加速器的一員,Jina AI 與 AWS 的密切合作體現了雙方在推動 AI 技術發展上的共同承諾。這次合作不僅在技術層面上實現了聯合,更是對未來大模型應用落地的深入探索。
Jina AI 的創始人兼 CEO 肖涵博士,對此表示:“jina-embeddings-v2 上線 AWS Marketplace,是對私有化 AI 解決方案行業標準的一次重大推進。”
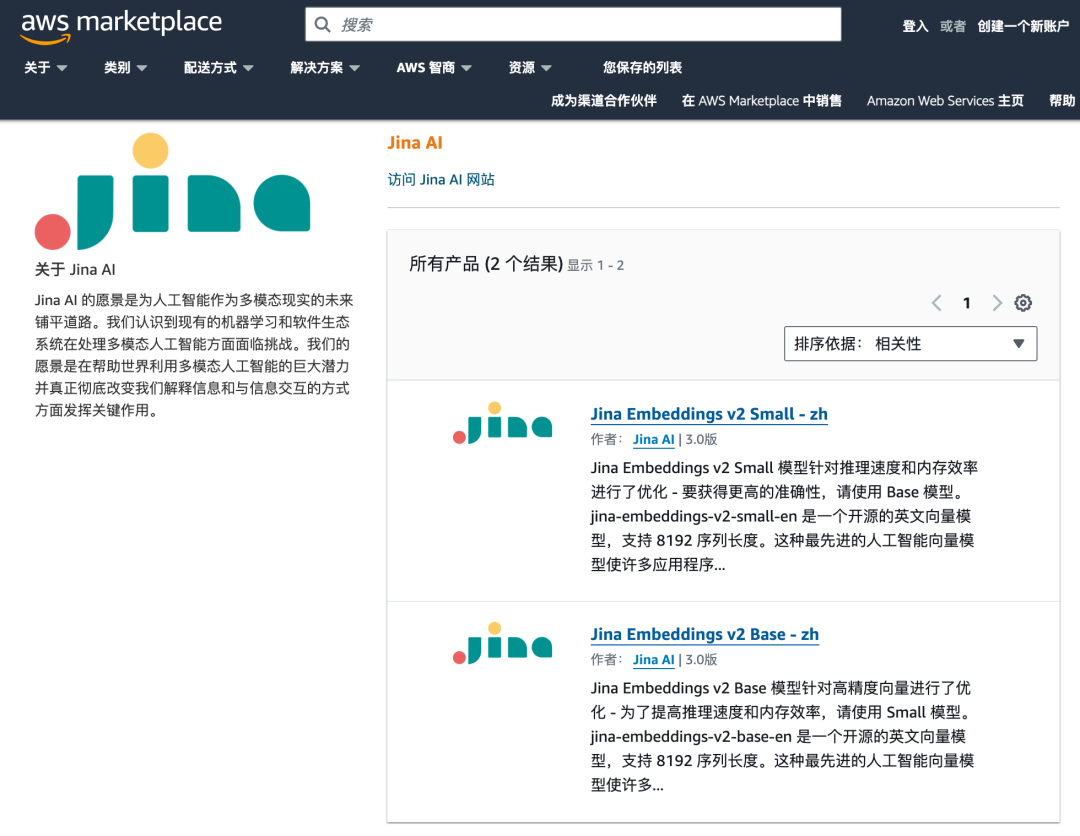 現在,企業用戶可以在 AWS Marketplace 上搜索 jina-embeddings-v2-base/small,并將它們直接部署到自己的 AWS 賬戶中。
現在,企業用戶可以在 AWS Marketplace 上搜索 jina-embeddings-v2-base/small,并將它們直接部署到自己的 AWS 賬戶中。 AWS SageMaker 的無縫集成
在 Jina AI,我們不僅追求技術創新,更重視其在 實際應用中的高效實施。因此我們將 jina-embeddings-v2 與 AWS SageMaker 進行了無縫集成,為企業用戶提供了一種高效便捷的解決方案。企業用戶現在可以輕松地將 jina-embeddings-v2 模型直接部署為 SageMaker 終端節點,迅速應用到實際業務中,無需擔憂技術復雜性和部署挑戰。
在商業應用方面,我們特別注重?經濟性和隱私保護。我們的英語 Base 模型和 Small 模型無需額外許可費,客戶僅需承擔 AWS 實例相關費用。這不僅確保了在 Virtual Private Cloud(VPC)內的數據隱私和安全,同時也提供了成本效益極高的解決方案。
此外,我們為不同業務場景提供多元化的選擇。0.27 GB 的 Base 模型和 0.07 GB 的 Small 模型,能夠服務從深度數據分析到輕量級應用的多樣化需求。其中,Base 模型以其全面的語義表示能力,非常適合企業級搜索和內容推薦。而專門針對移動和邊緣設備優化的 Small 模型,則突出了在速度和效率上的優勢。
jina-embeddings-v2 的獨特優勢
RAG 應用的理想選擇:我們深知長文本處理的復雜性,特別是在需要廣泛信息搜集和深度理解的場景中。jina-embeddings-v2 支持不同語義粒度的完整文本表示,使其成為優化 RAG 應用中處理長篇文本的理想選擇。它不僅增強了文本的語義理解能力,還提供了更大的靈活性和準確性。
全球首個支持 8k 輸入長度的開源模型:jina-embeddings-v2 作為全球首個支持高達 8k 輸入長度的開源模型,它在多方面比肩 OpenAI 的閉源模型 text-embedding-ada-002。我們的開源模型不僅具有強大的性能,更重要的是,它為用戶提供了根據自己的業務需求進行個性化調整的自由度。
更小的維度實現高效的表征:在保持與 OpenAI 的 text-embedding-ada-002 模型相當的性能表現的同時,jina-embeddings-v2 的向量維度僅為其一半,大幅降低了存儲需求并提高了檢索速度。
開始使用 AWS 上的 jina-embeddings-v2
要開始使用 jina-embeddings-v2,請訪問 AWS Marketplace 列表并選擇最適合您需求的模型。
🔗:https://aws.amazon.com/marketplace/seller-profile?id=seller-stch2ludm6vgy
以下示例可幫助您開始使用 jina-embeddings-v2 模型:
Sagemaker 的實時推理:https://github.com/jina-ai/jina-sagemaker/blob/main/notebooks/Real-time%20inference.ipynb
使用 SageMaker 批量向量化:https://github.com/jina-ai/jina-sagemaker/blob/main/notebooks/Batch%20transform.ipynb
即將推出多語言向量模型
Jina AI 正在積極開發多語言向量模型,包括中英雙語、德英雙語的向量模型。供企業客戶在各種云服務提供商(CSP)上進行私有化部署,為全球客戶提供更加全面和靈活的 AI 解決方案。隨著這些模型的推出,不僅將跨越語言障礙,更將為企業解鎖全球機遇。

)


真題解析#中國電子學會#全國青少年軟件編程等級考試)

】)
![[論文筆記] Scaling Laws for Neural Language Models](http://pic.xiahunao.cn/[論文筆記] Scaling Laws for Neural Language Models)


)


)



)
)
)
