代碼: https://github.com/sczhou/CodeFormer
論文:https://arxiv.org/abs/2206.11253
Towards Robust Blind Face Restoration with Codebook Lookup Transformer
文章目錄
- 論文
- 摘要
- 1 引言
- 2 相關工作
- **4 實驗**
- **4.1 數據集**
- **4.2 實驗設置和指標**
- **4.3 與最先進的方法的比較**
- **4.4 消融研究**
- ****4.5 運行時間**
- **4.6 擴展**
- **4.7 限制**
- **5 結論**
- 論文總結
- 代碼其他介紹
- 推理調用
論文
摘要
Blind face restoration是一個高度 ill-posed 的問題,通常需要輔助引導來 1) 改善從降級輸入到期望輸出的映射,或者 2) 補充在輸入中丟失的高質量細節。在本文中,我們展示了在一個小的代理空間中學到的離散碼本先驗可以通過將盲目的面部恢復建模為 a code prediction task來大大減少恢復映射的不確定性和模糊性,同時為生成高質量面部提供豐富的視覺元素。在這個范式下,我們提出了一個基于 Transformer 的預測網絡,命名為 CodeFormer,用于建模低質量面部的全局構成和上下文,以進行代碼預測,使其能夠在輸入嚴重降級的情況下發現自然面部,從而緊密逼近目標面部。為了增強對不同降級的適應性,我們還提出了一個可控特征轉換模塊,允許在保真度和質量之間進行靈活的權衡。由于表達力豐富的碼本先驗和全局建模,CodeFormer在質量和保真度方面均優于現有技術,展現出對降級的卓越魯棒性。大量的合成和真實數據集上的實驗證明了我們方法的有效性。
1 引言
在野外捕捉的人臉圖像往往受到各種降級的影響,如壓縮、模糊和噪聲。由于降級引起的信息丟失導致在給定低質量(LQ)輸入的情況下存在無窮多合理的高質量(HQ)輸出,因此恢復這樣的圖像是一個高度不適定的問題。在盲目恢復中,由于特定的降級是未知的,這種不適定性進一步增強。盡管隨著深度學習的出現取得了一些進展,但在巨大的圖像空間中學習沒有附加指導的 LQ-HQ 映射仍然是不可行的,導致早期方法的恢復質量不佳。為了提高輸出質量,輔助信息對于 1) 減少 LQ-HQ 映射的不確定性和 2) 補充高質量細節是不可或缺的。
各種先驗已被用于緩解這個問題的不適定性,包括幾何先驗 [5, 6, 31, 45]、參考先驗 [24–26] 和生成先驗 [2, 38, 44]。盡管觀察到了改進的紋理和細節,但這些方法通常對降級的敏感性較高,或者先驗表現受限。這些先驗對于面部恢復提供的指導不足,因此它們的網絡基本上傾向于使用通常受損害的 LQ 輸入圖像的信息。因此,LQ-HQ 映射的不確定性仍然存在,并且輸入圖像的降級使輸出質量惡化。**最近,基于生成先驗,一些方法通過迭代潛在優化 [27] 或直接潛在編碼 [29] 將受損面部投影到一個連續的無限空間。盡管輸出非常逼真,但在嚴重降級的情況下難以找到準確的潛在向量,導致低保真度的結果(圖1(d))。**為了增強保真度,通常需要在這類方法中的編碼器和解碼器之間引入跳躍連接 [38, 44, 2],如圖1(a)(頂部)所示,然而,當輸入嚴重降級時,這樣的設計同時會在結果中引入偽影,如圖1(e)所示。
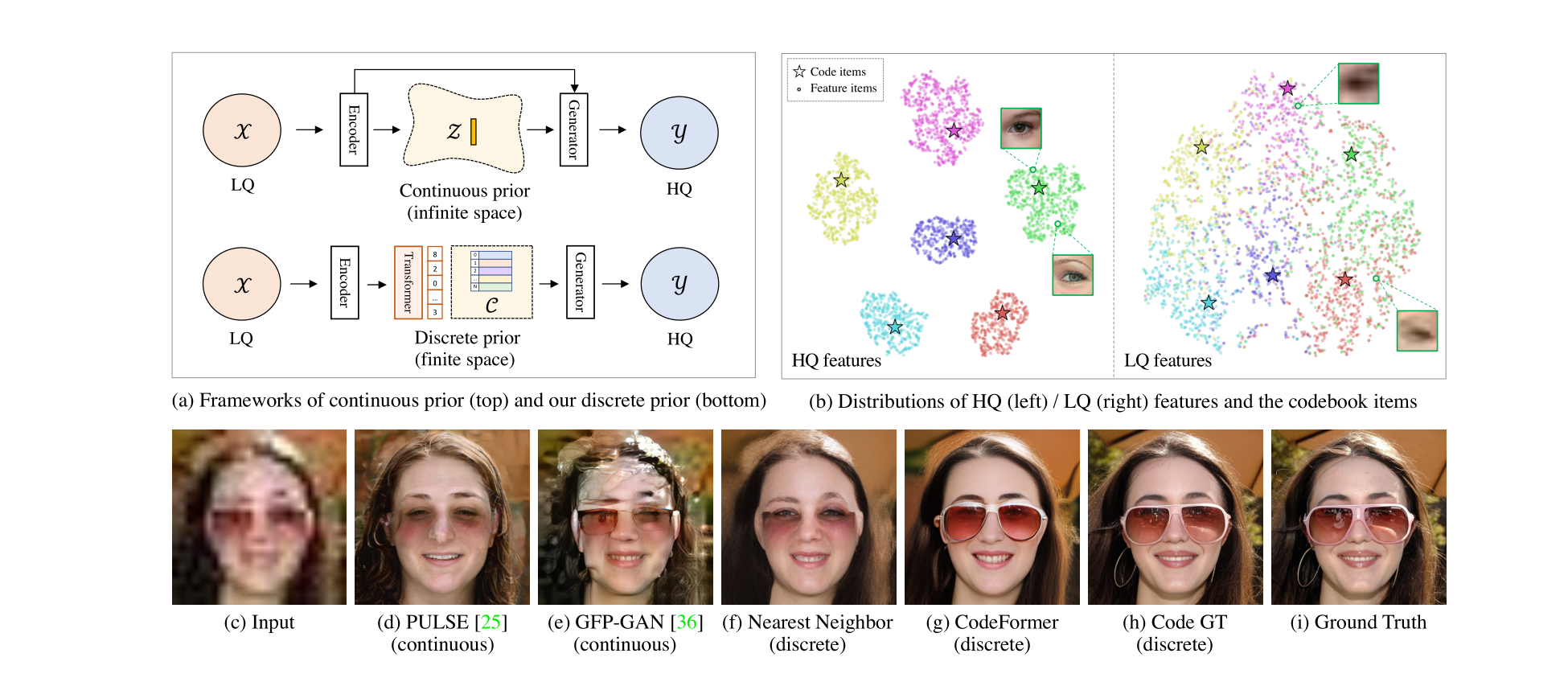
與上述方法不同,本文將盲目的面部恢復視為在學習的離散碼本先驗的一個小有限代理空間中的代碼預測任務,這表現出對降級的卓越魯棒性以及豐富的表達能力。碼本是通過使用矢量量化自重構 HQ 面部來學習的,它與解碼器一起存儲了用于面部恢復的豐富 HQ 細節。與連續生成先驗 [11, 38, 44] 不同,碼本項的組合形成了一個只有有限基數的離散先驗空間。通過將 LQ 圖像映射到一個更小的代理空間(例如,1024個代碼),LQ-HQ 映射的不確定性顯著減小,提高了對多樣降級的魯棒性,如圖1(d-g)中所比較的。此外,碼本空間具有更大的表達能力,感知上近似于圖像空間,如圖1(h)所示。這種性質使得網絡能夠減少對輸入的依賴,甚至可以擺脫跳躍連接的限制。
盡管基于碼本的離散表示已經用于圖像生成 [4, 11, 35],但對于圖像恢復而言,準確的碼組合仍然是一個非常棘手的問題。現有的工作通過最近鄰(NN)特征匹配查找碼本,但這在圖像恢復中較不可行,因為 LQ 輸入的固有紋理通常受到破壞。LQ 圖像中的信息丟失和多樣的降級不可避免地扭曲了特征分布,阻止了準確的特征匹配。如圖1(b)(右側)所示,即使在對 LQ 圖像進行微調后,LQ 特征也不能很好地聚類到確切的代碼,而是擴散到其他附近的代碼簇,因此在這種情況下,最近鄰匹配是不可靠的。
針對恢復,我們提出了一種基于 Transformer 的代碼預測網絡,稱為 CodeFormer,以利用 LQ 面部的全局組成和長距離依賴關系進行更好的代碼預測。具體而言,將 LQ 特征作為輸入,Transformer 模塊預測代碼令牌序列,該序列被視為碼本空間中面部圖像的離散表示。由于全局建模彌補了 LQ 圖像中的局部信息丟失,所提出的 CodeFormer 對嚴重降級表現出魯棒性并保持整體一致性。與圖1(f-g)中呈現的結果相比,所提出的 CodeFormer 能夠恢復更多的細節,如眼鏡,提高了恢復的質量和保真度。
此外,我們提出了一個可控特征轉換模塊,具有可調節系數,用于控制從 LQ 編碼器到解碼器的信息流。這種設計允許在保真度和質量之間進行靈活的權衡,以便可以實現它們之間的連續圖像過渡。這個模塊增強了 CodeFormer 在不同降級下的適應性,例如,在嚴重降級的情況下,可以手動減少攜帶降級的 LQ 特征的信息流以產生高質量的結果。
配備上述組件,所提出的 CodeFormer 在現有數據集和我們新引入的 WIDER-Test 數據集中表現出卓越的性能,該數據集包含從 WIDER-Face 數據集 [43] 中收集的 970 張嚴重受損的面部。除了面部恢復,我們的方法還在其他具有挑戰性的任務上展示了其有效性,例如需要來自其他區域的長距離線索的面部修補。系統性的研究和實驗證明了我們方法相對于先前工作的優點。
2 相關工作
盲目面部恢復。由于人臉具有高度結構化的特點,人臉的幾何先驗被用于盲目的面部恢復。一些方法引入了面部標志點 [6]、面部解析圖 [5, 31, 42]、面部組件熱圖 [45] 或 3D 形狀 [16, 28, 49] 在其設計中。然而,這樣的先驗信息無法從受損的面部準確獲取。而且,幾何先驗無法為高質量的面部恢復提供豐富的細節。
為了繞過上述限制,提出了一些基于參考的方法 [9, 24–26]。這些方法通常要求參考圖像與輸入受損圖像具有相同的身份。例如,Li等人 [26] 提出了一個引導面部恢復網絡,包括一個變形子網絡和一個重構子網絡,使用與輸入相同身份的高質量引導圖像來更好地恢復面部細節。然而,這樣的參考圖像并不總是可用。DFDNet [24] 預先構建了由高質量面部組件特征組成的字典。然而,特定于組件的字典特征對于高質量面部恢復仍然不足,特別是對于字典范圍之外的區域(例如皮膚、頭發)。為了緩解這個問題,最近的基于 VQGAN 的方法 [40, 47] 探索了一個學到的高質量字典,其中包含更通用和豐富的面部恢復細節。
最近,通過預訓練生成器(例如 StyleGAN2 [21])學到的生成式面部先驗已廣泛用于盲目面部恢復。通過迭代潛在優化進行有效的 GAN 反演 [12, 27] 或對受損面部進行直接潛在編碼 [29] 是利用這種先驗的策略。然而,當將受損面部投影到連續的無限潛在空間時,保持恢復面部的高保真度是具有挑戰性的。為了緩解這個問題,GLEAN [2, 3]、GPEN [44] 和 GFPGAN [38] 將生成先驗嵌入到編碼器-解碼器網絡結構中,同時利用輸入圖像的附加結構信息作為引導。盡管這些方法在保真度方面有所改善,但它們高度依賴輸入通過跳躍連接,這在輸入嚴重損壞時可能引入偽影。
字典學習。在圖像恢復任務中,具有學到字典的稀疏表示已經證明了其優越性,如超分辨率 [13, 33, 34, 41] 和去噪 [10]。然而,這些方法通常需要迭代優化來學習字典和稀疏編碼,具有較高的計算成本。盡管效率低下,對 HQ 字典的高級洞察啟發了基于參考的恢復網絡,例如 LUT [18] 和自引用 [48],以及合成方法 [11, 35]。Jo 和 Kim [18] 通過將網絡輸出值轉移為 LUT 中的值來構建查找表(LUT),因此在推斷過程中只需要進行簡單的值檢索。然而,在圖像域中存儲 HQ 紋理通常需要一個龐大的 LUT,限制了其實用性。VQVAE [35] 首次引入了通過向量量化自編碼器模型學習的高度壓縮的碼本。VQGAN [11] 進一步采用對抗損失和感知損失來增強感知質量,以較高的壓縮率顯著減小碼本大小而不損失其表達能力。與大型手工制作的字典 [18, 24] 不同,可學習的碼本自動學習了用于 HQ 圖像重建的最佳元素,提供了卓越的效率和表達能力,并避免了繁瑣的字典設計。受到碼本學習的啟發,本文研究了盲目面部恢復的離散代理空間。與最近的基于 VQGAN 的方法 [40, 47] 不同,我們通過全局建模預測代碼序列來利用離散碼本先驗,并通過固定編碼器來確保先驗的有效性。這樣的設計使得我們的方法能夠充分利用碼本,使其不依賴于與 LQ 提示的特征融合,顯著增強了面部恢復的魯棒性。
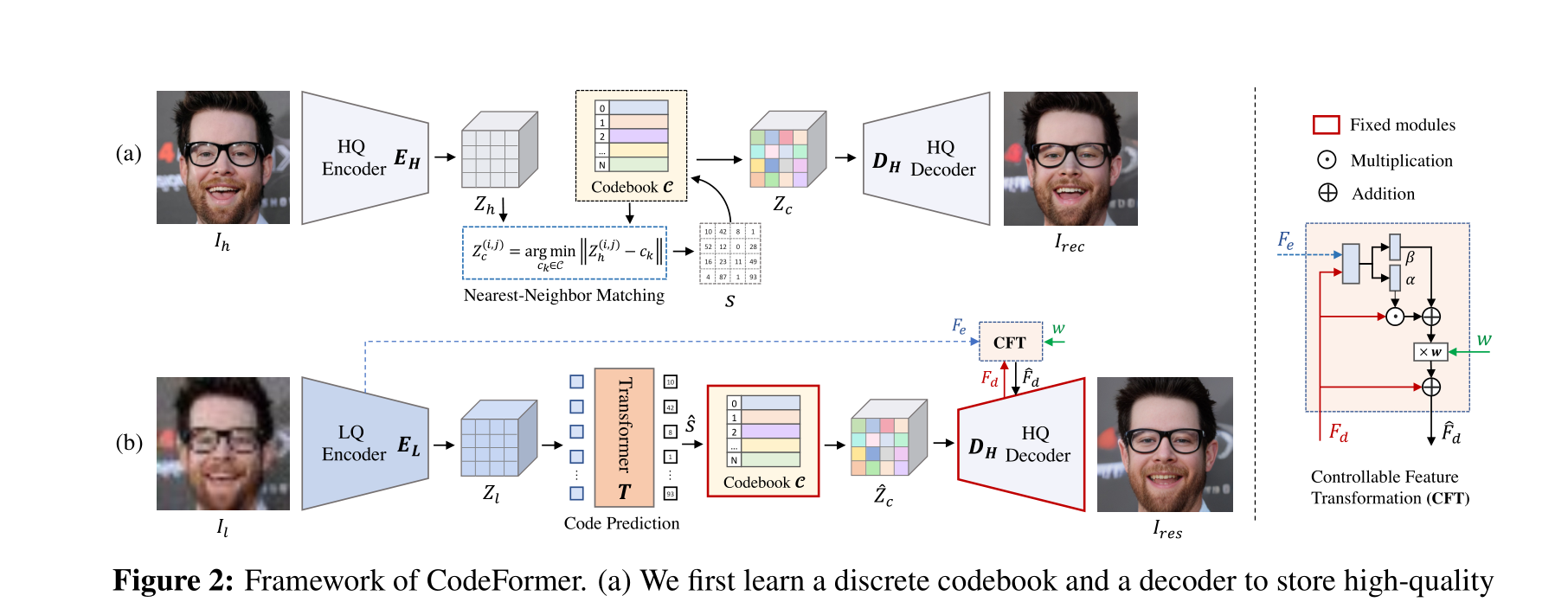
圖2:CodeFormer框架。 (a) 我們首先通過 self-reconstruction learning ** 自重構學習**學習一個離散碼本和一個解碼器,用于存儲面部圖像的高質量視覺部分。(b) 在固定的碼本和解碼器的基礎上,我們引入一個Transformer模塊進行代碼序列預測,對低質量輸入建模全局面部組成。此外,我們使用一個可控特征轉換模塊來控制從LQ編碼器到解碼器的信息流。請注意,這種連接是可選的,可以在輸入嚴重受損時禁用,用戶可以調整標量權重w在質量和保真度之間進行權衡。
4 實驗
4.1 數據集
訓練數據集: 我們在FFHQ數據集[21]上訓練模型,該數據集包含70,000張高質量(HQ)圖像,所有圖像都被調整為512×512進行訓練。為了形成訓練對,我們使用以下退化模型[24, 38, 44]從HQ圖像Ih合成LQ圖像Il:
[ Il = {[(Ih \otimes k_{\sigma}) \downarrow r + n_{\delta}] \text{JPEG}_q} \uparrow r, ]
其中HQ圖像Ih首先與高斯核(k_{\sigma})卷積,然后進行尺度為r的降采樣。之后,向圖像添加加性高斯噪聲(n_{\delta}),然后應用JPEG壓縮,質量因子為q。最后,將LQ圖像調整回512×512。我們從區間[1, 15]、[1, 30]、[0, 20]、[30, 90]中隨機采樣σ、r、δ和q。
測試數據集: 我們在一個合成數據集CelebA-Test和三個真實世界數據集上評估我們的方法:LFW-Test,WebPhoto-Test和我們提出的WIDER-Test。CelebA-Test包含從CelebA-HQ數據集[20]中選擇的3,000張圖像,其中LQ圖像在與我們的訓練設置相同的退化范圍內合成。這三個真實世界數據集分別包含三個不同程度的退化,即輕度(LFW-Test),中度(WebPhoto-Test)和重度(WIDER-Test)。LFW-Test包含LFW數據集[17]中每個人的第一張圖像,共包含1,711張圖像。WebPhoto-Test [38]包含從互聯網收集的407張低質量人臉。我們的WIDER-Test包含來自WIDER Face數據集[43]的970張嚴重受損的人臉圖像,為評估盲目人臉修復方法的泛化能力和魯棒性提供了更具挑戰性的數據集。
4.2 實驗設置和指標
設置: 我們將大小為512×512×3的面部圖像表示為16×16的代碼序列。對于所有訓練階段,我們使用批量大小為16的Adam [23]優化器。我們將學習速率設置為8×10-5,用于第I和II階段,并在第III階段采用較小的學習速率2×10-5。三個階段分別進行了150萬、20萬和2萬次迭代的訓練。我們的方法使用PyTorch框架實現,并使用四個NVIDIA Tesla V100 GPU進行訓練。
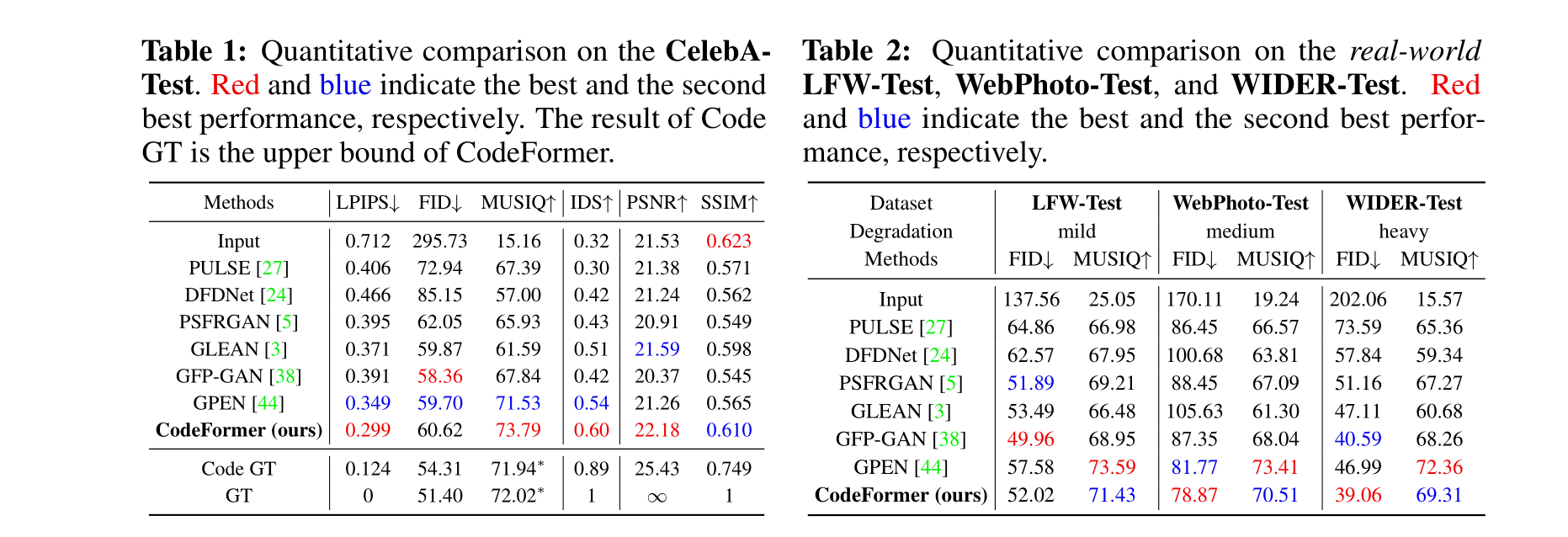
指標: 對于在具有地面真實標簽的CelebA-Test上的評估,我們采用PSNR、SSIM和LPIPS [46]作為指標。我們還使用余弦相似性評估身份保存,其中身份保存得分(IDS)和可視結果指示如Table 1所示。
4.3 與最先進的方法的比較
我們將提出的CodeFormer與最先進的方法進行比較,包括PULSE [27],DFD-Net [24],PSFRGAN [5],GLEAN [3],GFP-GAN [38]和GPEN [44]。我們在合成和真實世界數據集上進行了廣泛的比較。
在合成數據集上的評估: 我們首先在CelebA-Test上展示了定量比較,如Table 1所示。在LPIPS、FID和MUSIQ等圖像質量指標方面,我們的CodeFormer相較于現有方法取得了最佳分數。此外,它還在IDS和PSNR方面保持了最高的身份保存。此外,我們在Fig. 3中展示了定性比較。相比之下,其他方法未能產生令人愉悅的恢復結果,例如DFDNet [24],PSFRGAN [5],GFP-GAN [38]和GPEN [44]引入了明顯的偽影,而GLEAN [3]產生了過度平滑的結果,缺乏面部細節。此外,所有對比方法都無法保持身份。由于表達豐富的碼本先驗和全局建模,CodeFormer不僅產生了高質量的面部,而且在輸入受到嚴重損害時也能很好地保持身份。
在真實世界數據集上的評估: 如Table 2所示,我們的CodeFormer在具有輕度和中度退化的真實世界測試數據集上取得了可比較的FID分數的感知質量,并在具有重度退化的測試數據集上取得了最佳分數。雖然PULSE [27]在感知MUSIQ分數上也表現不錯,但它無法保持輸入圖像的身份,如Table 1和Fig. 4所示。從Fig. 4中的視覺比較中可以觀察到,我們的方法對真實的重度退化表現出卓越的魯棒性,并產生大多數視覺上令人滿意的結果。值得注意的是,CodeFormer成功保持了身份,并產生了具有豐富細節的自然結果。
4.4 消融研究
碼本空間的有效性: 我們首先研究碼本空間
的有效性。如Table 3中的Exp。 (a)所示,去除碼本(即直接將編碼器特征Zl饋送到解碼器)導致更差的LPIPS和IDS分數。結果表明,碼本的離散空間是確保我們模型的魯棒性和有效性的關鍵。
基于Transformer的碼本查找預測的優越性: 為驗證我們基于Transformer的碼本查找預測的優越性,我們將其與兩種不同的解決方案進行比較,即最近鄰(NN)匹配,即Exp。 (b),以及基于CNN的碼本預測模塊,即Exp。 ?,該模塊使用Linear層進行預測,按照編碼器EL的順序。如Table 3所示,Exps。 (b)和?的比較表明,采用碼本查找的碼本預測比NN特征匹配更為有效。然而,CNN的卷積操作的局部性質限制了其對長代碼序列預測的建模能力。與純CNN-based方法(即Exp。 ?)相比,我們基于Transformer的解決方案在LPIPS和IDS分數方面產生更高保真度的結果,以及在所有退化程度下更高的代碼預測準確度,如Fig. 6所示。此外,CodeFormer的優越性也在Fig. 5和Fig. 9中的視覺比較中得到證明。
固定解碼器的重要性: 與DFDNet [24]中的大型字典(~3.2G)旨在存儲大量面部細節的目標不同,我們故意采用了一個緊湊的碼本C ∈ RN×d,其中N = 1024和d = 256,僅保留用于面部恢復的基本代碼,然后激活預訓練解碼器中存儲的詳細線索。因此,碼本必須與解碼器一起使用,以充分發揮其潛力。為了證明我們的設計,我們進行了兩項研究:1)同時固定碼本和解碼器,即Exp。 (g),和2)固定碼本但微調解碼器,即Exp。 (e)。Table 3顯示,微調解碼器會導致性能下降,驗證了我們的說法。這是因為微調解碼器破壞了由預訓練碼本和解碼器持有的學到的先驗,導致次優性能。因此,我們在我們的方法中保持解碼器固定。
**4.5 運行時間
我們比較了最先進的方法[27, 24, 5, 2, 38, 44]和提出的CodeFormer的運行時間。所有現有方法都在512^2張面部圖像上使用其公開可用的代碼進行評估。如Table 5所示,提出的CodeFormer的運行時間與PSFRGAN [5]和GPEN [44]相似,可以在0.1秒內推斷一張圖像。與此同時,我們的方法在Celeb-Test數據集上在LPIPS方面取得了最佳性能。
4.6 擴展
面部顏色增強: 我們在面部顏色增強上微調我們的模型,使用與GFP-GAN(v1)[38]相同的顏色增強(隨機顏色抖動和灰度轉換)。我們在具有顏色丟失的真實世界老照片(來自CelebChild-Test數據集[38])上將我們的方法與GFP-GAN(v1)[38]進行比較。提出的CodeFormer生成具有更自然顏色和細節的高質量人臉圖像。
面部修復: 提出的Codeformer可以很容易地擴展到面部修復,即使在大面具比例下也表現出色。為了構建訓練對,我們使用一個公開可用的腳本[44]隨機繪制不規則折線掩碼以生成有掩碼的面部。我們將我們的方法與兩種最先進的面部修復方法CTSDG [14]和GPEN [44]以及用于碼本查找的最近鄰匹配進行比較。如Fig. 9所示,CTSDG和GPEN在大面具情況下表現困難。在我們的框架中使用最近鄰匹配粗略地重建面部結構,但在恢復眼鏡和眼睛等完整視覺部分時也失敗了。相反,我們的CodeFormer生成了高質量的自然面部,沒有筆畫和偽影。
4.7 限制
我們的方法建立在一個帶有碼本的預訓練自編碼器上。因此,自編碼器的能力和表達性可能影響我們方法的性能。1) 盡管通過Transformer的全局建模顯著緩解了身份不一致問題,但在一些罕見的視覺部分(例如配飾)中仍存在不一致,其中當前的碼本空間無法無縫地表示圖像空間。使用碼本空間中的多個尺度來探索更精細的視覺量化可能是一個解決方案。2) 盡管CodeFormer在大多數情況下表現出色,但在側臉情況下,CodeFormer對其他方法的優勢有限,也無法產生良好的結果,如Fig. 10中所示的失敗案例。這是預期的,因為在FFHQ訓練數據集中只有很少的側臉,因此,碼本無法學到足夠的代碼以處理這種情況,導致在重建和修復方面的效果較差。
5 結論
本文旨在解決盲目面部修復中的基本挑戰。通過學習一個小的離散但表達豐富的碼本空間,我們將面部修復轉變為代碼標記預測,顯著降低了修復映射的不確定性,并簡化了修復網絡的學習。為了彌補局部信息損失,我們通過一個富有表現力的Transformer模塊,探索了從受損面部獲取全局構圖和依賴的可能性,以更好地預測代碼。由于這些設計的好處,我們的方法顯示出很強的表達性和對嚴重退化的強大魯棒性。為了增強我們的方法對不同退化的適應性,我們還提出了一個可控的特征轉換模塊,允許在保真度和質量之間進行靈活的權衡。實驗結果表明了我們方法的卓越性和有效性。



論文總結
能和codeformer打的就只有gfpgan,但似乎感覺上codeformer還是更勝一籌。
臉部修復,既要考慮到不要太依賴于原來的降級圖,如果太依賴很容易導致生成的臉非常丑。也要考慮到需要和原來的降級圖要相似。如何在這二者之中平衡,就是codeformer所做的事情——codebook。
人臉修復所面臨的問題:
在人臉修復領域,由于圖像質量降低或損壞,傳統的修復方法往往難以有效地還原高質量的人臉圖像。特別是在缺乏高質量參考圖像的情況下,傳統方法無法提供令人滿意的結果。本文提到的問題包括局部紋理和細節的丟失、面部結構的損壞以及對于重建的不確定性。
論文中提到的方法的新點:
論文提出了一種名為CodeFormer的新方法,該方法通過學習一個小而表達豐富的離散碼本空間,將面部修復問題轉化為代碼標記的預測問題。與傳統的方法相比,這種方法減少了修復映射的不確定性,并通過引入Transformer模塊來全局建模受損面部的整體構圖和依賴關系,從而更好地預測代碼。
保真度
保真度權重w位于[0, 1]之間。通常,較小的w傾向于產生更高質量的結果,而較大的w則產生更高保真度的結果。
Codebook是什么:
Codebook是指學到的小而表達豐富的離散碼本空間。在這個空間中,高質量的面部圖像被編碼為一系列離散的代碼標記,這些標記在訓練過程中學到,以便在修復階段使用。Codebook的使用使得修復網絡能夠更有效地還原受損面部的高質量細節。
CodeFormer模型架構和其他模型的比較:
CodeFormer模型采用了一個兩階段的訓練方法。第一階段通過自重構學習預訓練了一個量化自編碼器,學到了碼本和相應的解碼器。第二階段引入了Transformer模塊,通過學習全局面部構圖,更準確地預測了從低質量輸入到高質量輸出的代碼標記。論文還介紹了一個可控的特征轉換模塊,允許在還原質量和還原保真度之間進行靈活的權衡。
與其他方法(如PULSE、DFD-Net、PSFRGAN、GLEAN等)相比,CodeFormer在合成和真實世界的測試數據集上表現出更好的質量、保真度和身份保持性。CodeFormer通過引入學得的碼本和全局建模的Transformer模塊,相對于傳統的基于先驗信息的方法和其他基于生成模型的方法,顯著提高了面部修復的效果。
代碼其他介紹
功能:
🖼? Whole Image Enhancement
# 對于整個圖像 **Whole Image Enhancement**
# 添加'--bg_upsampler realesrgan'以使用Real-ESRGAN增強背景區域
# 添加'--face_upsample'以使用Real-ESRGAN進一步提高修復后的人臉
python inference_codeformer.py -w 0.7 --input_path [圖像文件夾]|[圖像路徑]🌈 Face Colorization (cropped and aligned face)
# For cropped and aligned faces (512x512)
# Colorize black and white or faded photo
python inference_colorization.py --input_path [image folder]|[image path]🎨 Face Inpainting (cropped and aligned face)
# For cropped and aligned faces (512x512)
# Inputs could be masked by white brush using an image editing app (e.g., Photoshop)
# (check out the examples in inputs/masked_faces)
python inference_inpainting.py --input_path [image folder]|[image path]
如果想自己訓練,下面是訓練過程,看一下有助于理解論文:
# :milky_way: 訓練文檔
[English](train.md) **|** [簡體中文](train_CN.md)## 準備數據集
- 下載訓練數據集: [FFHQ](https://github.com/NVlabs/ffhq-dataset)---## 訓練### 👾 階段 I - VQGAN
- 訓練VQGAN:> python -m torch.distributed.launch --nproc_per_node=8 --master_port=4321 basicsr/train.py -opt options/VQGAN_512_ds32_nearest_stage1.yml --launcher pytorch- 訓練完VQGAN后,可以通過下面代碼預先獲得訓練數據集的密碼本序列,從而加速后面階段的訓練過程:> python scripts/generate_latent_gt.py- 如果你不需要訓練自己的VQGAN,可以在Release v0.1.0文檔中找到預訓練的VQGAN (`vqgan_code1024.pth`)和對應的密碼本序列 (`latent_gt_code1024.pth`): https://github.com/sczhou/CodeFormer/releases/tag/v0.1.0### 🚀 階段 II - CodeFormer (w=0)
- 訓練密碼本訓練預測模塊:> python -m torch.distributed.launch --nproc_per_node=8 --master_port=4322 basicsr/train.py -opt options/CodeFormer_stage2.yml --launcher pytorch- 預訓練CodeFormer第二階段模型 (`codeformer_stage2.pth`)可以在Releases v0.1.0文檔里下載: https://github.com/sczhou/CodeFormer/releases/tag/v0.1.0### 🛸 階段 III - CodeFormer (w=1)
- 訓練可調模塊:> python -m torch.distributed.launch --nproc_per_node=8 --master_port=4323 basicsr/train.py -opt options/CodeFormer_stage3.yml --launcher pytorch- 預訓練CodeFormer模型 (`codeformer.pth`)可以在Releases v0.1.0文檔里下載: https://github.com/sczhou/CodeFormer/releases/tag/v0.1.0---:whale: 該項目是基于[BasicSR](https://github.com/XPixelGroup/BasicSR)框架搭建,有關訓練、Resume等詳細介紹可以查看文檔: https://github.com/XPixelGroup/BasicSR/blob/master/docs/TrainTest_CN.md】)
![[論文筆記] Scaling Laws for Neural Language Models](http://pic.xiahunao.cn/[論文筆記] Scaling Laws for Neural Language Models)


)


)



)
)
)





)