目錄
一.堆的概念與結構
1.1 堆的概念
1.2 堆性質:?
1.3 堆的結構定義
?二.堆的初始化和銷毀
2.1 堆的初始化:
2.2 堆的銷毀:
三.堆的插入數據(含向上調整算法的實現)?
3.1 插入邏輯
3.2?插入函數
3.3?向上調整算法
三. 堆的刪除數據(含向下調整算法)
3.1 刪除邏輯
3.2 向下調整算法
3.3 刪除棧頂
四.堆的取堆頂?
五.堆排序的實現
5.1 借助數據結構實現排序
5.2?真正的堆排序算法
一.堆的概念與結構
堆(Heap)是一種特殊的完全二叉樹,同時也是一種高效的數據結構,主要用于實現優先隊列等場景。其核心特性是節點之間的數值關系滿足嚴格的堆序性,具體可分為大堆(大頂堆)?和小堆(小頂堆)。
1.1 堆的概念
堆的本質
堆是一棵完全二叉樹(結構特性),且每個節點的值必須滿足:
- 若為大堆:每個節點的值大于等于其左右子節點的值(根節點是最大值)。
- 若為小堆:每個節點的值小于等于其左右子節點的值(根節點是最小值)。
1.2 堆性質:?
- 堆中某個結點的值總是不大于或者不小于其父結點的值
- 堆總是一顆完全二叉樹
- 堆頂是最值(最大值或最小值)
1.3 堆的結構定義
// 堆的結構體定義(大堆)
typedef int HPDataType; // 堆中元素的類型
typedef struct Heap {HPDataType* arr; // 存儲堆元素的數組int size; // 當前堆中元素的個數int capacity; // 堆的最大容量
} Heap;?二.堆的初始化和銷毀
2.1 堆的初始化:
// 初始化空堆
void HeapInit(Heap* hp) {if (hp == NULL) {return; // 處理空指針}hp->arr = NULL;hp->size = 0;hp->capacity = 0;
}2.2 堆的銷毀:
銷毀之前先檢查數組為不為空,不為空就釋放掉然后置空,并把size和capacity賦值為0
//銷毀
void HPDestory(HP* php)
{assert(php);if (php->arr)free(php->arr);php->arr = NULL;php->size = php->capacity = 0;
}三.堆的插入數據(含向上調整算法的實現)?
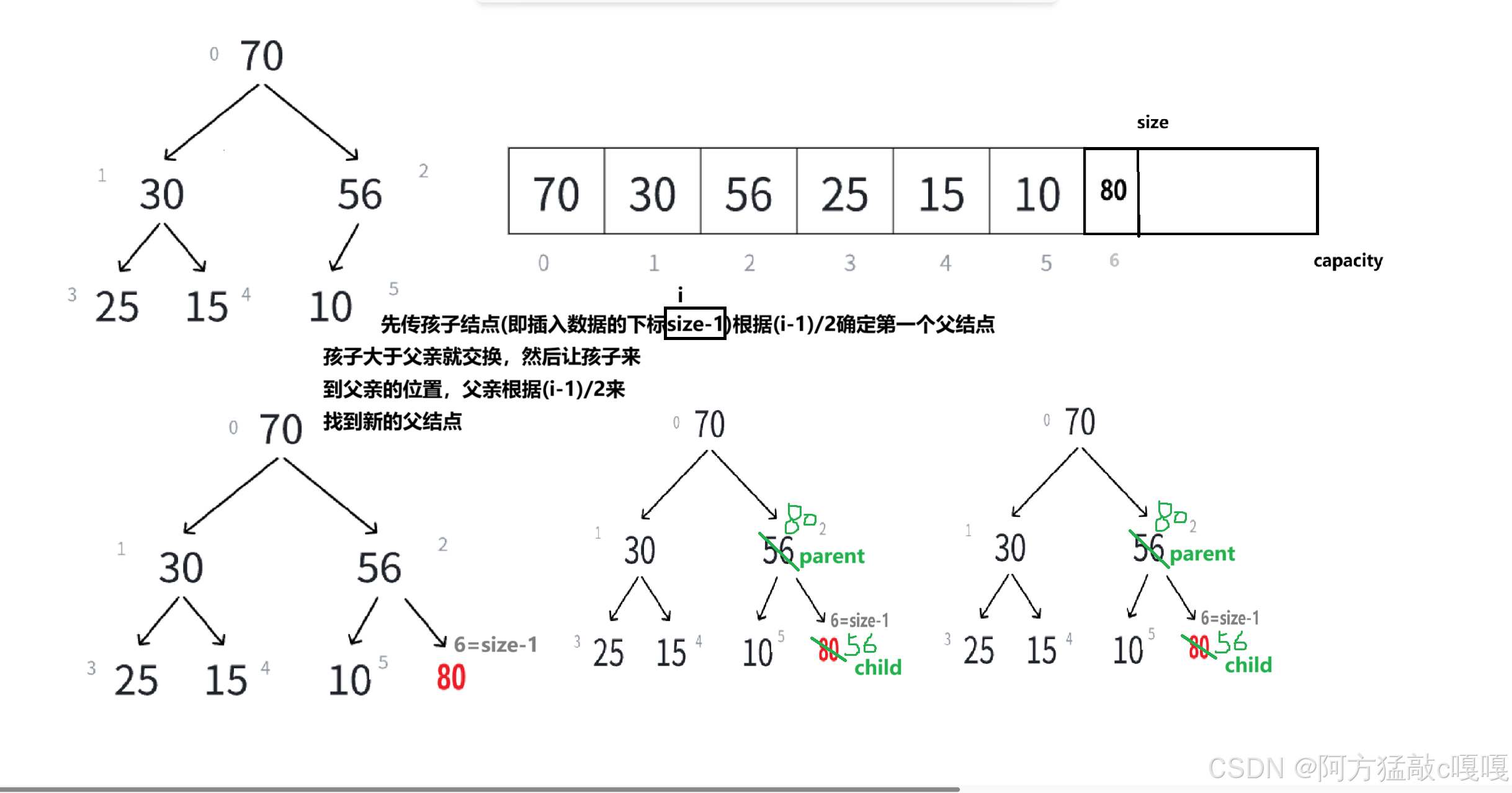
首先我們需要知道插入數據的邏輯 然后通過向上調整的方法來實現
向上調整算法
向上調整(也稱 “上浮”)的核心是:新插入的元素從底部逐步向上移動,與父節點比較,若不滿足堆序則交換,直到找到合適位置或到達根節點。
3.1 插入邏輯
- 空間檢查:若堆已滿,需擴容(類似動態數組擴容)。
- 添加元素:將新元素插入到堆的末尾(數組的最后一個位置)。
- 向上調整:從新元素位置開始,與父節點比較并交換,直至滿足堆序性(大堆:子節點≤父節點;小堆:子節點≥父節點)。
如下圖:
3.2?插入函數
首先插入時 我們需要判斷空間是否足夠 若不夠的話就需要進行增容 代碼如下
//往堆里面插入數據
void HPPush(HP* php, HPDataType x)
{//檢查空間是否足夠//不夠就擴容if (php->size == php->capacity){int newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity;HPDataType* tmp = (HPDataType*)realloc(php->arr,newcapacity * sizeof(HPDataType));if (tmp == NULL){perror("realloc fail!");exit(1);}php->arr = tmp;php->capacity = newcapacity;}//夠就直接插入php->arr[php->size++] = x;//向上調整AdjustUp(php->arr, php->size - 1);//因為前面size++了,所有傳的是size-1
}3.3?向上調整算法
//交換
void swap(int* a, int* b)
{int temp = *a;*a = *b;*b = temp;
}
//向上調整
void AdjustUp(HPDataType*arr, int child)
{assert(arr);int parent = (child - 1) / 2;while (child > 0){//大堆:>//小堆:<if (arr[child] > arr[parent]){swap(&arr[child], &arr[parent]);child = parent;parent= (child - 1) / 2;}else{break;}}
}以大堆為例,步驟如下:
- 設新元素索引為
child,其父節點索引為parent = (child - 1) / 2(數組從 0 開始)。- 若
a[child] > a[parent](大堆條件),交換兩者,更新child = parent,繼續向上比較。- 重復上述步驟,直到
child = 0(根節點)或a[child] ≤ a[parent]
三. 堆的刪除數據(含向下調整算法)
堆的刪除操作通常指刪除堆頂元素(根節點,即最大值或最小值),并通過向下調整算法重新維護堆的特性。以下是具體實現:
3.1 刪除邏輯
- 替換堆頂:用堆的最后一個元素覆蓋堆頂元素(避免直接刪除堆頂導致結構破壞)。
- 縮減規模:堆的元素數量減 1(邏輯上移除最后一個元素)。
- 向下調整:從新的堆頂開始,與左右子節點中符合堆序的節點交換,直至滿足堆的特性。
如下圖

3.2 向下調整算法
向下調整(也稱 “下沉”)的核心是:將替換后的堆頂元素逐步向下移動,與左右子節點中更符合堆序的節點(大堆選較大者,小堆選較小者)交換,直到找到合適位置或成為葉子節點。
以大堆為例,步驟如下:
- 設當前節點索引為
parent,左子節點索引為child = 2 * parent + 1(數組從 0 開始)。 - 若右子節點存在且大于左子節點,更新
child為右子節點索引。 - 若
a[parent] < a[child](大堆條件),交換兩者,更新parent = child,繼續向下比較。 - 重復上述步驟,直到
child超出堆的范圍或a[parent] ≥ a[child]。
//向下調整
void AdjustDown(HPDataType* arr, int parent, int n)
{assert(arr);int child = 2 * parent + 1;while (child < n){//child+1也小于n//后面的小堆就是取小的,大堆取大的孩子if (child + 1 < n && arr[child] < arr[child + 1]){child++;}//大堆:> 小堆:<if (arr[child] > arr[parent]){swap(&arr[child], &arr[parent]);parent = child;child = 2 * parent + 1;}else{break;}}
}3.3 刪除棧頂
首先我們需要一個判斷是否為空的函數
//判空
bool HPEmpty(HP* php)
{assert(php);return php->size == 0;
}刪除棧頂函數
//刪除(堆頂操作)
void HPPop(HP* php)
{assert(!HPEmpty(php));//首尾交換swap(&php->arr[0], &php->arr[php->size - 1]);php->size--;//向下調整AdjustDown(php->arr, 0, php->size);
}先判斷不為空,然后交換首尾,直接--size刪掉,再通過向下調整算法把刪除一個數據后的堆重新調整成大堆。?
四.堆的取堆頂?
首先判斷是否為空 若不為空則直接返回棧頂元素arr[0]
//取堆頂
HPDataType HPTop(HP* php)
{assert(!HPEmpty(php));return php->arr[0];
}五.堆排序的實現
這里向大家介紹兩種方式 但其實第一種并不是真正意義上的排序 只是達到了排序的目的而已
下面介紹第一種
5.1 借助數據結構實現排序
#include"Heap.h"//堆排序--這不是真正的堆排序,而是利用了堆這個數據結構來實現的排序
void HeapSort1(int* arr, int n)
{HP sp; // 定義一個堆結構體變量HPInit(&sp); // 初始化堆(創建空堆)// 1. 將數組所有元素插入堆中for (int i = 0; i < n; i++){HPPush(&sp, arr[i]); // 插入元素,內部會通過向上調整維護堆序}// 2. 從堆中提取元素,重構數組int i = 0;while (!HPEmpty(&sp)) // 當堆不為空時{HPDataType top = HPTop(&sp); // 獲取堆頂元素(最小值或最大值)arr[i++] = top; // 將堆頂元素存入原數組,依次填充HPPop(&sp); // 刪除堆頂元素,內部通過向下調整維護堆序}
}
int main()
{int arr[6] = { 30,56,25,15,70,10 };printf("排序之前:\n");for (int i = 0; i < 6; i++){printf("%d ", arr[i]);}printf("\n");HeapSort1(arr, 6);printf("排序之后:\n");for (int i = 0; i < 6; i++){printf("%d ", arr[i]);}printf("\n");return 0;
}
核心思路
- 借助堆存儲元素:將待排序數組的所有元素依次插入堆中(構建堆)。
- 提取最值并重構數組:反復從堆頂提取最小值(或最大值),按順序存入原數組,最終得到有序數組。
為什么說 “這不是真正的堆排序”?
真正的堆排序(如之前實現的HeapSort)是原地排序,直接在原數組上通過構建堆和調整堆實現排序,不需要額外的堆結構,空間復雜度為O(1)。
而這段代碼的本質是:
- 額外創建了一個堆(
HP sp),需要O(n)的額外空間存儲元素; - 排序過程依賴于堆的插入和刪除操作,本質是 “利用堆的特性進行排序”,而非嚴格意義上的原地堆排序。
5.2?真正的堆排序算法
通過構建大堆并反復提取最大值來實現數組的升序排序。其核心特點是原地排序(無需額外空間存儲堆),充分利用堆的特性高效完成排序。以下是詳細解釋:
一、核心思路
構建大堆:將待排序數組轉換為大堆(每個父節點的值 ≥ 子節點的值),此時堆頂(數組首位)是最大值。
排序過程:
交換堆頂(最大值)與當前堆的最后一個元素,將最大值放到數組末尾(最終位置)。
縮小堆的范圍(排除已排好的末尾元素),對新堆頂執行向下調整,重新維護大堆特性。
重復上述步驟,直到所有元素排序完成。
二、代碼逐段解析
1.?HeapSort 函數(排序核心)
void HeapSort(int* arr, int n)
{// 1. 構建大堆for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(arr, i, n); // 從最后一個非葉子節點開始向下調整}// 2. 執行排序int end = n - 1; // 標記當前堆的最后一個元素索引while (end > 0){// 交換堆頂(最大值)與當前堆的最后一個元素swap(&arr[0], &arr[end]);// 縮小堆范圍(end減1),對新堆頂執行向下調整,重建大堆AdjustDown(arr, 0, end);end--; // 下一次排序的堆范圍更小}
}
(1)構建大堆
關鍵代碼:
for (int i = (n - 1 - 1) / 2; i >= 0; i--)計算最后一個非葉子節點的索引:
(n-1-1)/2(等價于?(n-2)/2)。- 數組從 0 開始,最后一個元素索引為?
n-1,其父親節點索引為?(n-1-1)/2。- 從下往上調整:從最后一個非葉子節點開始,依次向上對每個節點執行?
AdjustDown(向下調整),最終將整個數組轉換為大堆。
為什么從非葉子節點開始?
葉子節點沒有子節點,無需調整;非葉子節點可能破壞堆序,需通過向下調整使其子樹滿足大堆特性。
(2)排序過程
-
交換堆頂與末尾元素:
swap(&arr[0], &arr[end])
大堆的堆頂(arr[0])是當前堆中的最大值,交換后最大值被放到數組末尾(arr[end]),即它的最終位置。 -
向下調整重建大堆:
AdjustDown(arr, 0, end)
交換后堆頂元素可能破壞堆序,需從堆頂開始向下調整,但此時堆的范圍已縮小為?[0, end-1](end?位置已排好序)。 -
循環縮小范圍:
end--
每次循環后,已排序的元素增加一個,堆的范圍持續縮小,直到?end=0(所有元素排序完成)。
2.?main 函數(測試邏輯)
int main()
{int arr[6] = { 30,56,25,15,70,10 }; // 待排序數組printf("排序之前:\n");for (int i = 0; i < 6; i++){printf("%d ", arr[i]); // 輸出:30 56 25 15 70 10}printf("\n");HeapSort(arr, 6); // 調用堆排序函數printf("排序之后:\n");for (int i = 0; i < 6; i++){printf("%d ", arr[i]); // 輸出:10 15 25 30 56 70(升序)}printf("\n");return 0;
}
-
測試數組初始為?
[30,56,25,15,70,10],經過堆排序后變為升序數組?[10,15,25,30,56,70]。
三、關鍵輔助函數說明
AdjustDown(向下調整算法)
作用:當某個節點破壞大堆特性時,通過與左右子節點中較大的一個交換,逐步向下移動,直至子樹重新滿足大堆特性。
(代碼中未顯示實現,但核心邏輯是:選擇左右子節點的最大值,與父節點比較,不滿足大堆則交換并繼續調整。)swap(交換函數)
作用:交換兩個元素的值,用于將堆頂最大值移動到數組末尾。
四、為什么大堆能實現升序排序?
大堆的堆頂始終是當前堆中的最大值,每次將最大值放到數組末尾,相當于 “從后往前” 依次確定最大元素的位置。
經過?
n-1?次交換和調整后,數組從前往后依次遞增,最終實現升序。
五、算法特性
-
時間復雜度:
O(n+logn)(構建堆?O(n)?+ 排序階段?O(nlog+n))。 -
空間復雜度:
O(1)(原地排序,僅需常數級額外空間)。 -
不穩定性:交換過程可能改變相等元素的相對順序(例如?
[2, 2, 1]?排序后可能變為?[1, 2, 2],但兩個?2?的原始順序可能改變)。
總結
這段代碼是標準的堆排序實現,通過 “構建大堆→交換堆頂與末尾→調整堆” 的循環,高效完成升序排序。其原地排序的特性和?O(n+log n)?的時間復雜度,使其在大規模數據排序中表現優異。



:容器運行時工具實踐及 OpenStack 部署基礎)









)


)
)

