redis是一個內存數據庫,是把數據存儲在內存中的,而我們知道內存中的數據是不持久的,一旦服務器重啟或者進程重啟,內存的數據就丟失了.為了讓數據達到持久化的效果,就必須把數據寫到硬盤上.
redis相對于mysql這樣的關系型數據庫最明顯的優勢就是快.所以為了保證速度快,數據還得在內存中,但是為了持久,數據還要想辦法存儲在硬盤上.
Redis為了應對這樣的情況,決定把數據在內存中存儲一份,同時在硬盤上也存儲一份.這樣的兩份數據,理論上是完全相同的,實際上可能存在差異,取決于我們具體怎么進行持久化.
當要插入一個新的數據的時候,就需要把這個數據,同時寫入內存和硬盤.但說是同時寫,實際上怎么寫入硬盤是有不同的策略的,應用這些策略,就可以保證redis整體的效率還是足夠高的.
當查詢某個數據的時候,直接從內存讀取.硬盤中的數據只是在redis重啟的時候,用來回復內存中的數據的.
代價就是消耗了更多的空間,同一份數據存儲了兩份,但是硬盤空間畢竟是比較廉價的,這樣的開銷并不會帶來很多的成本.
redis實現持久化的策略
redis實現持久化的整體策略有兩種,RDB和AOF.
RDB:Redis DataBase.AOF:Append Only File.
RDB是定期備份,AOF是實時備份.
RDB持久化
RDB持久化是定期的把當前進程數據生成快照保存到硬盤的過程.
后續redis一旦重啟了,就可以根據硬盤的中快照把內存中的數據給回復回來.
RDB定期備份的兩種方式
1.手動觸發
程序員通過redis客戶端,執行特定的命令,來觸發快照的生成.
save命令,執行save命令的時候,redis服務器會在單線程模型下全力以赴的進行快照生成的操作,此時就會阻塞redis其他客戶端的命令,一般不建議使用save.
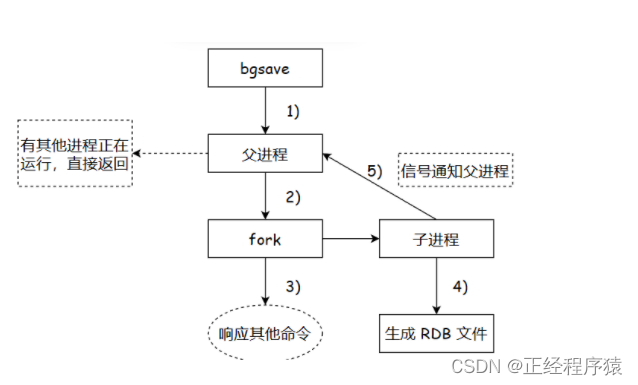
bgsave,bg是background的縮寫,此命令不會影響redis服務器處理其他客戶端的請求和命令.此命令是redis通過多進程的方式來完成并發編程從而實現bgsave.
2.自動觸發
我們可以在redis配置文件中,設置一下,讓redis每隔多長時間以及每產生多少次修改就觸發備份操作.
redis生成rdb文件,是存放在redis的工作目錄中的,redis的工作目錄也是在redis配置文件中進行設置的.
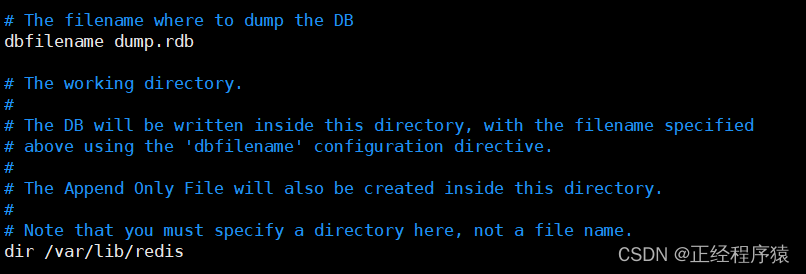
我們不僅可以修改redis的工作目錄,也可以修改生成的rdb文件的名字.
dump.rdb是RDB機制生成的鏡像文件,redis服務器默認是開啟了rdb的.此rdb文件時一個二進制的文件,把內存中的數據,以壓縮的形式,保存到這個二進制文件中.(壓縮會消耗一定的cpu資源,但是能節省存儲空間).

這個二進制文件,我們不能隨意修改.redis服務器重新啟動,會嘗試加載這個rdb文件,如果發現格式錯誤,就可能會加載數據失敗.
需要注意的是,rdb文件,即使我們不去主動修改它,但是也可能會出現一些意外情況,一旦通過一些操作(比如網絡傳輸)引起這個文件被破壞,此時redis服務器也是無法正常啟動的.
rdb的持久化操作可以執行多次,當執行生成rdb鏡像文件操作的時候,此時就會把要生成的快照數據,先保存到一個臨時文件中,當這個快照生成完畢之后,在刪除之前的rdb文件,把新生成的rdb臨時文件名字改為剛才的dump.rdb,所以自始至終,rdb文件是始終只有一個的.
RDB自動觸發的條件
我們可以在redis的配置文件中查看達到自動觸發rdb的條件.?
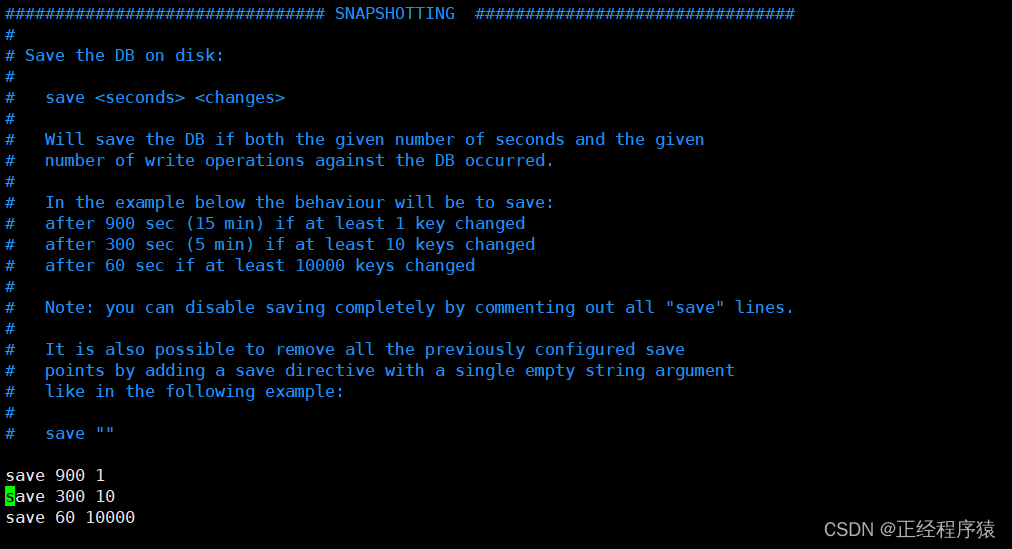
15分鐘之后如果至少修改了一次或者5分鐘之后至少修改了10次或者1分鐘之后至少修改了10000次就會自動觸發rdb機制.
注意:時間要滿足的同時修改次數也要滿足.
此處的數值都可以自行修改.但是修改上述的數據的時候,要有一個基本的原則:生成一個rdb快照,是一個比較高的成本,不能讓這個操作執行的太過頻繁.
也正是因為rdb生成的不能太過頻繁,這就導致,快照里的數據,和當前實際的數據情況可能是存在偏差的.
手動執行bgsave觸發一次生成快照
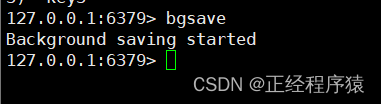
由于這里的數據比較少,執行bgsave瞬間就完成了,立即查看應該是有結果的.如果這里的數據比較多,執行bgsave就可能需要消耗一定的時間,立即查看不一定就是生成完畢了.

在rdb鏡像文件里可以隱約的看到我們的插入的key.
我們重啟redis服務器,再次進入redis客戶端查看數據.

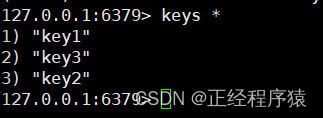
通過上述操作,就可以看到,redis服務器在重啟的時候,加載了rdb文件的內容,恢復了之前內存中的數據狀態.
插入新的key,不手動執行bgsave
我們插入一個新的key之后,重新啟動redis服務器,再次查看內容.
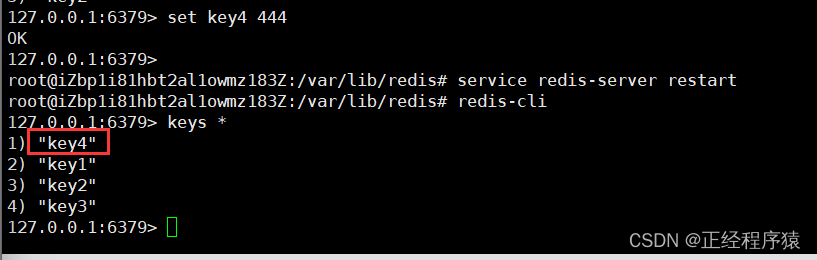
可以看到我們新插入的key4依然存在,但是我們并沒有手動執行bgsave,同時也沒有達到自動觸發的條件,這是什么原因呢?
這是因為如果是通過正常流程重新啟動redis服務器,此時redis服務器會在退出的時候自動觸發生成rdb的操作.但是如果是異常重啟(kill -9或者服務器掉電),此時redis服務器來不及生成rdb,內存中尚未保存的數據就會隨著redis啟動而真的丟失了!!!
所以redis自動觸發rdb會在多個場景中存在:
1.在配置文件中配置save 時間 次數,表示在多長時間之后,執行次數達到多少,才觸發.
2.通過shutdown命令(不帶參數),關閉redis服務器,此處的關閉屬于是正常關閉,也會觸發生成rdb快照的操作.我們上述的service redis-server restart也屬于是正常關閉.
3.redis進行主從復制的時候,主節點也會自動生成rdb快照,然后把rdb快照文件內容傳輸給從節點.
如果正常情況的關閉,我們是不必擔心內存數據丟失的情況,在實際開發中我們更擔心異常情況的出現導致redis服務器異常關閉.比如使用kill命令(kill -9 redis進程id)的方式來直接殺死redis進程,此時就會導致新插入的數據的丟失.

注意在ubuntu系統下,由于我們是通過service的方式來啟動redis,所以會存在一個守護進程來時刻檢測redis的情況,當redis服務器掛掉之后,會迅速在拉起一個redis,所以雖然kill掉了redis進程,但是查看進程信息redis還存在,但是此時的進程id已經不一致了.
bgsave操作流程是創建子進程,由子進程完成持久化操作.
持久化會把數據寫入到一個新的臨時文件中,最后使用新的文件來代替舊的文件.
如果直接使用save命令,此時是不會創建子進程和進行文件替換的.save命令是直接在當前進程中,往同一個文件中寫入數據,不會創建新的文件.

inode相當于是文件的標識,inode不同,說明文件已經不是同一個文件了.
通過配置自動生成rdb快照
我們可以在配置文件中修改save來設置自動生成快照的條件.對于redis來說,修改配置文件之后,一定要重啟服務器,才能生效,如果想要立即生效,也可以通過命令的方式修改.
save " "是用來關閉自動生成快照的.
當我們把rdb的文件改壞了,會發生什么
手動的把rdb的文件改壞,然后一定是通過kill進程方式,重新啟動redis服務器.
如果是通過service redis-server restart重啟,就會在服務器退出的時候,重新生成rdb快照,就把剛才改壞掉的文件替換掉了,所以要使用kill的方式.
由于rdb文件時二進制的,直接把改壞掉的rdb文件交給redis服務器去使用,得到的結果是不可預期的.
如果改的地方正好是文件末尾,對前面的內容沒有影響,可能redis再次啟動還是可以恢復正常的數據的.
對于rdb文件損壞,可能redis服務器啟動得到的數據正確性可能有問題,也可能redis服務器直接就啟動失敗了.
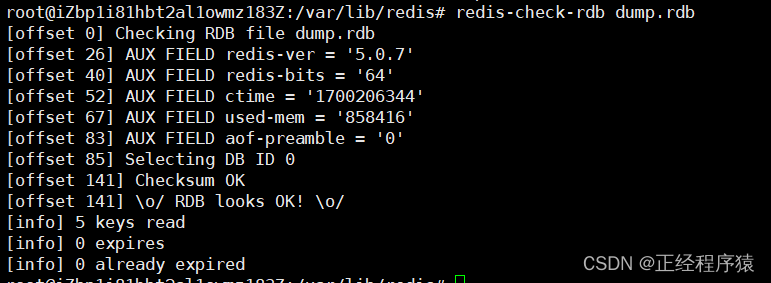
redis也提供了rdb文件的檢查工具,可以先通過檢查工具,檢查一下rdb的文件格式是否是符合要求的.
AOF
當開啟aof的時候,rdb就不生效了,reids服務器啟動的時候就不再讀取rdb文件的內容了.
會把用戶的每個操作都記錄到文件中.當redis重新啟動的時候,就會讀取這個aof文件中的內容,用來恢復數據.
aof默認一般是關閉狀態,修改配置文件,來開啟aof功能.
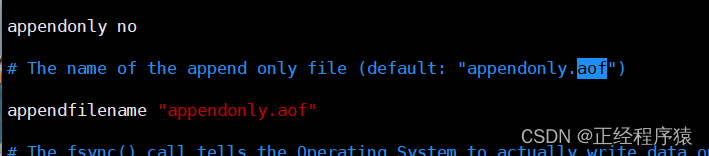
修改為yes開啟.
aof文件所在的位置和rdb文件在同一目錄下.(/var/lib/redis)
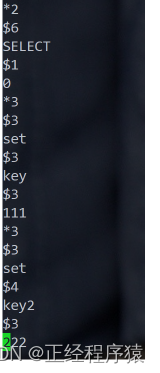
aof是一個文本文件,每次進行的操作都會記錄到文本文件中,通過一些特殊符號作為分隔符,對命令的細節做出區分.
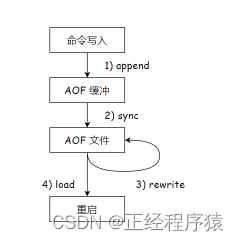
引入aof之后,既要寫內存又要寫硬盤,redis是不是就變慢了?
redis是一個單線程的服務器,速度很快(快就快在直接操作內存).引入aof之后,實際上對于redis來說,是沒有影響的.并沒有影響redis處理請求的速度.原因有兩點:
1.aof機制并非是直接讓工作線程將數據寫入硬盤,而是先寫入一個內存中的緩沖區,當緩沖區的數據積累到一定量之后,在統一寫入內存.引入緩沖區之后,就大大降低了寫硬盤的次數.寫硬盤的時候,寫入硬盤數據的多少,對于性能的影響不是很大,關鍵是寫硬盤的次數多了,影響就比較大了.
2.硬盤上讀寫數據,順序讀寫的速度是比較快的,隨機訪問速度是比較慢的.aof是每次把新的操作寫入到原有的文件的末尾,屬于是順序寫入.
如果把數據寫入到緩沖區里,本質還是在內存中,如果這個時候,進程突然崩潰或者主機掉電,緩沖區中的數據還沒來得及寫入到硬盤中,那么這一部分數據就丟失了.
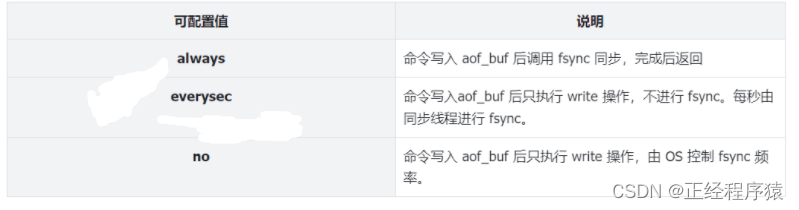
所以,redis給出了一些選項,來取舍刷新頻率和性能.
刷新頻率越高,那么對性能的影響就越大,但是數據的可靠性就越高.
刷新頻率越低,性能影響的越小,但是數據的可靠性就越低.
aof重寫機制
當aof文件持續增長,體積就會越來越大,會影響到redis下次啟動時的啟動時間.
為了解決這個問題,就出現了重寫機制.
重寫機制是因為在zof文件中,有一些內容是冗余的,比如對一個key修改了多次,但是我們在下次啟動的時候,只是關注這個key的最終結果的,至于它是修改了幾次我們是不關注的,比如刪除一個key,或者set了多個key我們可以用mset命令.
重寫其實就是對aof文件進行整理操作,這個整理能夠提出其中的冗余操作,并且合并一些操作,達到給aof文件瘦身的效果.
AOF?重寫過程可以?動觸發和?動觸發:
???動觸發:調??bgrewriteaof?命令。
???動觸發:根據?auto-aof-rewrite-min-size?和?auto-aof-rewrite-percentage?參數確定?動觸發時
機。
auto-aof-rewrite-min-size:表?觸發重寫時?AOF?的最??件??,默認為?64MB。
auto-aof-rewrite-percentage:代表當前?AOF?占???相?較上次重寫時增加的?例.
aof重寫流程

父進程通過fork操作創建出子進程.
父進程仍然負責接收請求,子進程負責針對aof文件重寫.在重寫的時候,不關心aof文件中原來的內容,只是關心內存中最終的數據狀態.
子進程只需要把內存中當前的數據,獲取出來,以aof的格式,寫入到一個新的aof文件中.(內存中的數據狀態,就已經相當于是aof文件結果整理后的模樣了).
子進程寫新的aof文件的同時,父進程仍然在不停的接收客戶端的請求,父進程還是會把這些請求產生的aof數據先寫入到緩沖區,在刷新到原有的aof文件中.
在創建子進程的瞬間,子進程就繼承了當前父進程的內存狀態.因此,子進程里的內存數據是父進程fork之前的狀態,fork之后,新來的請求對內存造成的影響,是子進程感知不到的.
所以,此時父進程又準備了一個aof_rewrite_buf緩沖區,專門用來存放fork之后收到的數據.當子進程把aof數據寫完之后,會通過信號通知父進程,父進程在把aof_rewrite_buf中的內容也寫入到新的aof文件里.
此時就可以用新的aof文件代替舊的文件了.
如果在執行bgrewriteaof的時候,當前reids已經在進行aof重寫了,此時就不會再次執行aof重寫了,會直接返回.
如果,在執行bgrewriteaof的時候,當前redis正在生成rdb文件的快照,那么aof操作就會等待,等到rdb快照生成完畢之后,在進行執行aof操作.
rdb對于fork之后的數據,就直接置之不理了.aof則對于fork之后的數據,采取了aof_rewrite_buf緩沖區的方式來處理.這也很符合它們的設計理念.rdb只是用來定期備份(定期備份就難以和最新的數據保持一致),aof則是實時備份.
父進程fork完畢之后,就已經讓子進程寫新的aof文件了,并且一段時間過后,子進程很快的完成了工作,新的文件代替舊的文件.那么,父進程還有必要繼續寫這個即將被替換的舊的文件嗎?
是有必要的.考慮到極端情況,假設在重寫過程中,重寫到一半,服務器崩潰了,子進程內存的數據就丟失了,而新的aof文件內容還不完整,所以如果父進程不堅持寫舊的aof文件,在這種情況下,reids重啟就無法保證數據的完整性了.
混合持久化
aof本來是按照文本的方式來寫入文件的,但是文本的方式寫文件,后續加載的成本是比較高的.
此時redis就引入了混合持久化的方式,結合rdb和aof的特點.
按照aof的方式,每一個請求或者操作都會記錄到文件中.
在觸發aof重寫之后,就會把當前的內存狀態按照rdb的二進制格式寫入到新的aof文件,后續再進行的操作,仍然是按照aof文本的方式追加到aof文件后面.
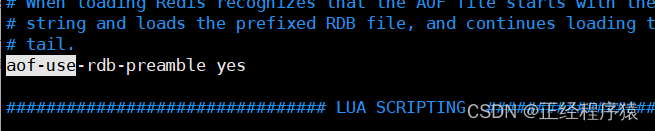
yes表示開啟混合持久化.





)



![【Mysql】[Err] 1293 - Incorrect table definition;](http://pic.xiahunao.cn/【Mysql】[Err] 1293 - Incorrect table definition;)









