一、概述
? ? ? ? 相較于基于強化學習的NAS,可微NAS能直接使用梯度下降更新模型結構超參數,其中較為有名的算法就是DARTS,其具體做法如下。
? ? ? ? 首先,用戶需要定義一些候選模塊,這些模塊內部結構可以互不相同(如設置不同種類和數量的卷積,使用不同種類的連接結構等);其次,用戶也需要指定神經網絡的層數,每一層由候選模塊的其中之一構成。
? ? ? ? 由于搜索空間=(其中
為候選模塊種類,
為預先指定的神經網絡層數)巨大,為了從龐大的搜索空間中找到合適的結構,需要引入superNet。
二、SuperNet
? ? ? ? 以下內容均基于論文:FBNet![]() https://openaccess.thecvf.com/content_CVPR_2019/papers/Wu_FBNet_Hardware-Aware_Efficient_ConvNet_Design_via_Differentiable_Neural_Architecture_Search_CVPR_2019_paper.pdf
https://openaccess.thecvf.com/content_CVPR_2019/papers/Wu_FBNet_Hardware-Aware_Efficient_ConvNet_Design_via_Differentiable_Neural_Architecture_Search_CVPR_2019_paper.pdf
? ? ? ? 2.1模型結構
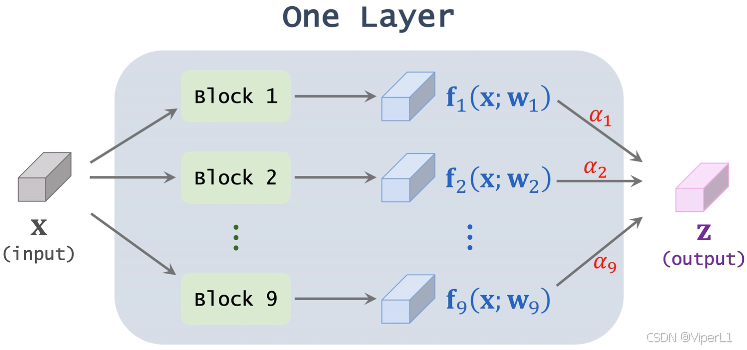
? ? ? ? 這里以SuperNet中的某一層為例,設置候選模塊一共9種,這層superNet由9種不同的模塊并聯而成。輸入向量在候選模塊處理后分別得到9個向量
,這個處理過程記作:
,其中
為模塊中的權重。將這些向量
進行加權求和,這些權重記作
,所有
之和為1(由softmax計算得到),權重
就是模型要學習的神經網絡結構超參數。
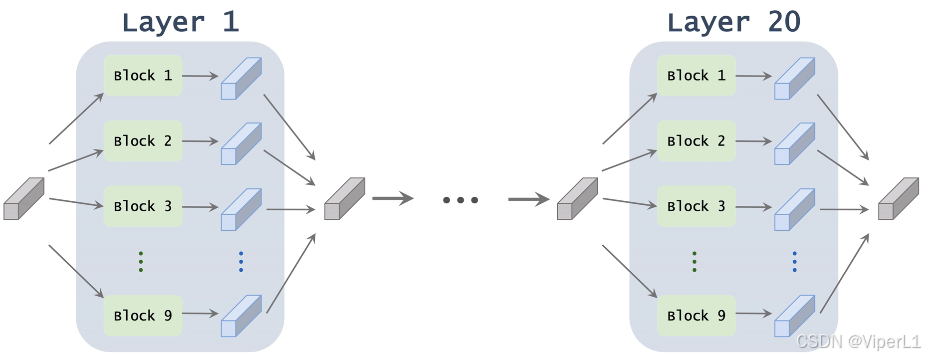
? ? ? ? 通過堆疊上述模塊,組成一個完整的superNet,經過訓練,每一層最終會保留一個模塊。
? ? ? ? 2.2訓練
? ? ? ? 將superNet的候選模塊一共9個,記作;設superNet一共20層,記作
;得第
層中第
個模塊的參數記作
和
,故
,
,這兩個即為需要訓練并學習的參數。superNet做出的預測記作
。
? ? ? ? 交叉熵損失函數可以寫作,在這個損失函數中,由于
是關于
的函數,且兩者可微,故損失函數
能通過
傳遞給
,所以可以直接使用反向梯度傳播更新模型。
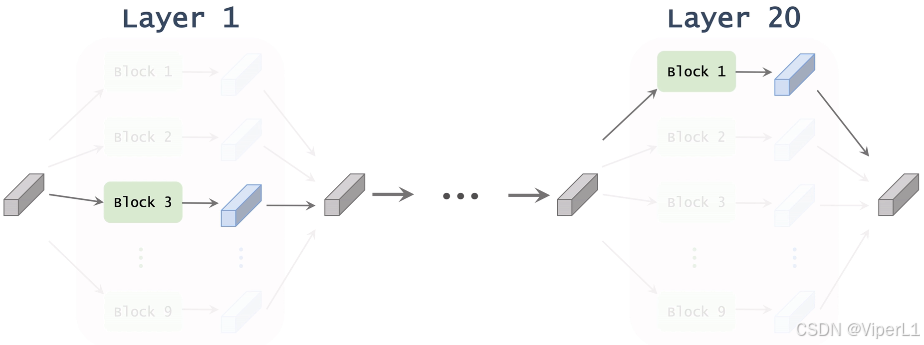
? ? ? ? 基于學習到的,我們可以計算出superNet中沒一層中每個模塊的權重
,對于每層而言,選取其中權重最大的模塊作為該層的結構,這些模塊串聯即可得到整個模型的結構,如下圖所示。
三、使用額外的性能指標優化superNet
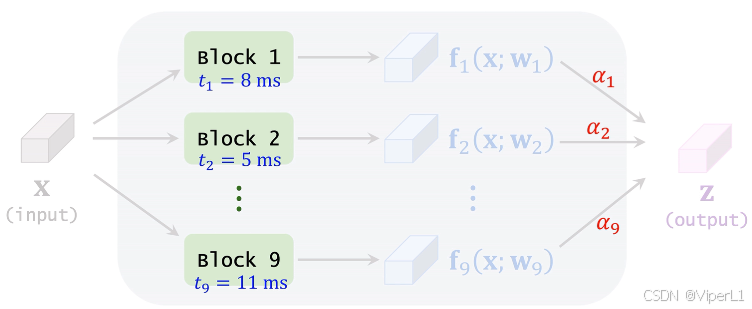
? ? ? ? 以應用于移動設備的輕量化神經網絡舉例,這類神經網絡由于需要考慮移動設備的算力限制,往往需要延遲(latency,推理時間)越小越好。
? ? ? ? 可以事先測量每個候選模塊的平均延遲,計算這一層中每個模塊的延遲加權平均,如下圖所示。
? ? ? ? 將20層網絡中的延遲求和,得到:,其中
的定義在2.2節中已經給出,可以進一步記作
,其中的
為計算得到的常數。
????????損失函數為:,其中
可以決定犧牲多少準確率來換取計算速度。
? ? ? ? 另外也可以使用,作為損失函數,效果和上式相同。


——內部類、匿名對象、對象拷貝時的編譯器優化和內存管理)

![[數據結構——lesson10.堆及堆的調整算法]](http://pic.xiahunao.cn/[數據結構——lesson10.堆及堆的調整算法])


算法在民航LPV-200進近中的具體實現流程)







 進程基礎)



