這里寫目錄標題
- 一、并行查詢相關自己置參數
- 二、并行掃描
- 2.1、并行順序掃描
- 2.2、并行索引掃描
- 2.3、并行index-only掃描
- 2.4、并行bitmap heap掃描
- 三、并行聚合
- 四、多表關聯
- 4.1、Nested loop多表關聯
- 4.2、Merge join多表關聯
- 4.3、Hash join多表關聯
了解 Oracle 的朋友應該知道 Oracle 支持并行查詢,比如 SELECT 、 UPDATE 、 DELETE大事務開啟并行功能后能利用多核 CPU ,從而充分發揮硬件性能,提升大事務處理效率,PostgreSQL 在 9.6 版本前還不支持并行查詢, SQ L 無法利用多核 CPU 提升性能, 9.6 版本開始支持并行查詢,只是 9.6 版本的并行查詢所支持的范圍非常有限,例如只在順序掃描、多表關聯、聚合查詢中支持并行, 10 版本增強了并行查詢功能,例如增加了并行索引掃描 、并行 index-only 掃描、并行 bitmap heap 掃描等。
一、并行查詢相關自己置參數
max_worker_processes(integer)
設置系統支持的最大后臺進程數,默認值為 8 ,如果有備庫,備庫上此參數必須大于或等于主庫上的 此參數配置值, 此參數調整后需重啟數據庫生效 。max_parallel_workers (integer)
設置系統支持的并行查詢進程數,默認值為 8 ,此參數受 max_worker_processes 參數限制,設置此參數的值比 max_worker processes 值高將無效 。當調整這個參數時建議同時調整 max_parallel workers _per _gather 參數值 。max_parallel_workers_per _gather (integer)
設置允許啟用的并行進程的進程數,默認值為 2 ,設置成 0 表示禁用并行查詢,此參數受 max_worker_processes 參數和 max_parallel_workers 參數限制,因此并行查詢的實際進程數可能比預期的少,并行查詢比非并行查詢消耗更多的 CPU 、 IO 、內存資源,對生產系統有一定影 響 , 使用時需考慮這方面的因素,這三個參數的配置值大小關系通常如下所示:
max_worker_processes > max_parallel_workers > max_parallel_workers p er_gather
parallel_setup_cost(floating point)
設置優化器啟動并行進程的成本 ,默認為 1000 。parallel_tuple_cost(floating point)
設置優化器通過并行進程處理一行數據的成本,默認為 0.1 。mi n_pa ra I lel_ta ble_sca n_size(integer)
設置 開啟并行的 條件之一 , 表 占用 空 間小于此值將不會開啟并行,并行順序掃描場景下掃描的數據大小通常等于表大小 , 默認值為 8MB 。min_parallel_index_scan_size(integer)
設置開啟 并行的 條件之一,實 際上并行索引掃描不會掃描索引所有數據塊,只是掃描索引相關數據塊,默認值為 512kb 。force_parallel_mode (enum)
強制開啟并行, 一般作為測試目的, OLTP 生產環境開啟需慎重,一般不建議開啟 。
postgresql.conf 配置文件設置了以下參數:
max_worker_processes = 16
max_parallel_workers_per_gather = 4 # taken from max_parallel_workers
max_parallel_worders = 8
parallel_tuple_cost = 0.1
parallel_setup+cost = 1000.0
min_parallel_table_scan_size = 8MB
min_parallel_index_scan_size = 612kb
force_parallel_mode = off
行查詢進程 數 預估值由 ~ 4&. max_parallel workers_per_陰陽控制,并行進程數預估值是指優化器解析 SQL 時執行計劃預計會啟用的并行進程數,而實際執行查詢時的并行進程數受參數 max_parallel_ workers 、 max_worker_processes 的限制,也就是說 SQL 實際獲得的并行進程數不會超過這兩個參數設直的值,比如 max worker_processes 參數 設直成 2, max_parallel_workers_per_gather 參數設直成 4 ,不考慮其他因素的情況下,并行查詢實際的并行進程數將會是 2 ,另一方面并行進程數據會受 min_parallel_table _scan_size 參數 的影響, flf 表的大小會影響并行進程數 。 并行查詢執行計劃中的 Workers Planned 表示執行計劃預估的并行進程 數 , Worker Launched 表示并行查詢實際獲得的并行進程數 。
二、并行掃描
2.1、并行順序掃描
介紹并行順序掃描之前先介紹順序掃描(sequential scan),順序掃描通常也稱之為掃描,全表掃描會掃描整張表數據,當表很大時,全表掃描會占用大量CPU、內存、源,對數據庫性能有較大影響,在OLTP事務型數據庫系統中應當盡量避免。
首先創建一張測試表,井插入500萬數據,如下所示:
create table test_big1 (id int4,name character varying(32),create_time timestamp without time zone default clock_timestamp()
);insert into test_big1(id, name)
select n, n || '_test'
from generate_series(1, 50000000) n;
一個順序掃描的示例如下所示:
explain select *
from test_big1
where name = '1_test';

以上執行計劃Seq Scan on test_bigl說明表test_bigl典型的順序掃描執行計劃,PostgreSQL中的順序掃描在9.6
上進行了順序掃描,這是版本開始支持并行處理,一個典
并行順序掃描會產生多個子進程,井利用多個邏輯CPU
并行全表掃描,一個并行順序掃描的執行計劃如下所示:
explain analyze select *
from test_big1
where name = '1_test';
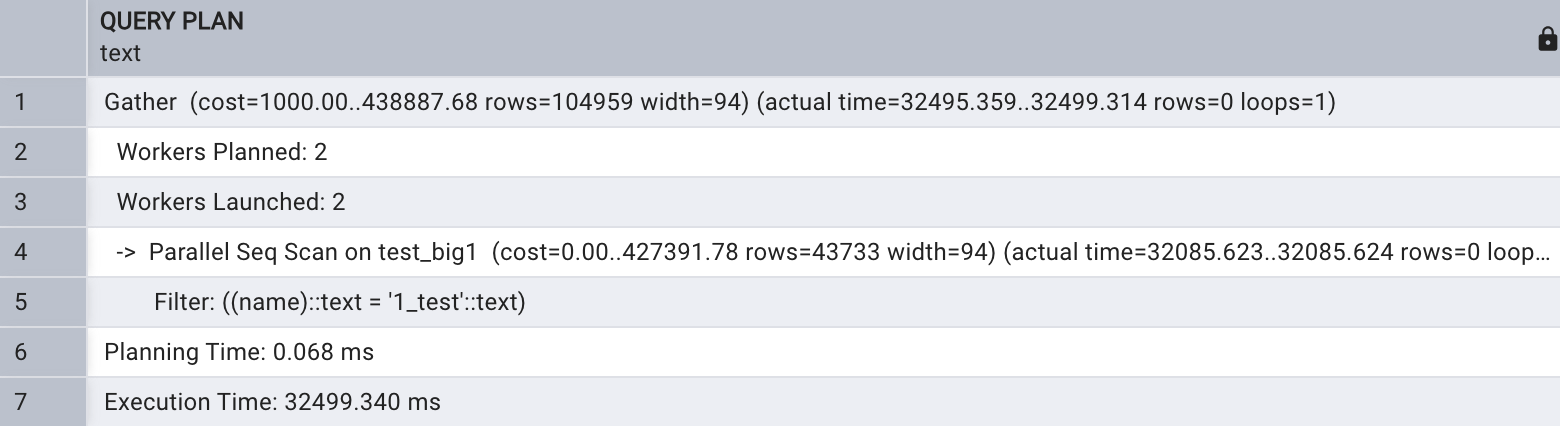
Workers Planned 表示執行計劃預估的并行進程數,
Worker Launched 表示查詢實際獲得的并行進程數,這里 Workers Planned 和 Worker Launched值都為 4 , Parallel Seq Scan on test_ big 1 表示進行了并行順序掃描, Planning time 表示生成執行計劃的時間, Execution time 表示 SQL 實際執行時間,從以 上可 以 看出, 開啟 4 個并行時 SQL 實際執行時間為 1367 毫秒。
接下來測試不開啟并行的 SQL 性能,由于 max_parallel_workers_per_gather 參數設置成了 4 , 設置成 0 表示關閉并行,在會話級別設置此參數值為 0 ,如下所示 :
set max_parallel_workers_per_gather = 0;
不開啟并行,執行計劃如下所示 :
explain analyze select *
from test_big1
where name = '1_test';

不開啟并行時此 SQL 執行時間為50463毫秒,開啟井行查詢為32499毫秒。
2.2、并行索引掃描
Index Scan using 表示 執行計劃預計進行索引掃描, 索 引掃描也支持并行,稱為并行索引掃描 ( Parallel index scan ), 首 先在表 test_bigl 上創建索引, 如下所示 :
create index idx_test_big1_id
on test_big1 using btree (id);
執行以下SQL,統計ID小于1千萬的記錄數,如下所示:
explain analyze select count(name)
from test_big1
where id < 10000000;
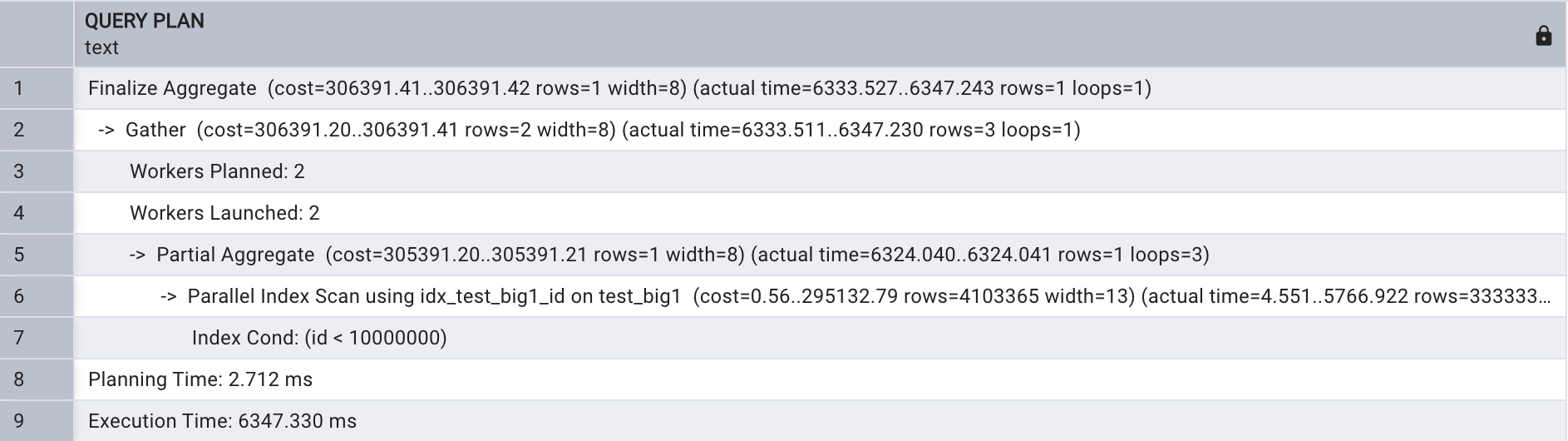
根據以上執行計劃可以看出,進行了并行索引掃描,開啟了2個并行進程,在會話級別關閉并行查詢,如下所示:
SET max_parallel_workers_per_gather = 0;explain analyze select count(name)
from test_big1
where id < 10000000;

執行計劃看出進行了索引掃描,沒有開啟并行。
2.3、并行index-only掃描
了解并行 index-only 掃描之前首先介紹下index-only掃描,顧名思義,index-only掃描是指只需掃描索引,也就是說SQL 僅根據索引就能獲得所需檢索 的 數據,而不需要通過索引回表查詢數據 。 例如 ,使用SQL統計ID小于100萬的記錄數,在開始測試之前,先在會話級別關閉 并行, 如下所示:
SET max_parallel_workers_per_gather = 0;explain select count(*)
from test_big1
where id < 10000000;

上執行計劃主要看Index Only Scan這一 行 ,由于ID宇段上建 立了索引,統計記錄數不需要再回表查詢其他信息,因此進行了index-only掃描,接下來使用EXPLAIN ANALYZE執行此SQL,如下所示:
explain analyze select count(*)
from test_big1
where id < 10000000;

index-only 掃描支持并行,稱為并行 index-only 掃描,接著測試并行 index-only掃描,在會話級別開啟并行功能,如下所示 :
SET max_parallel_workers_per_gather to default;explain analyze select count(*)
from test_big1
where id < 10000000;
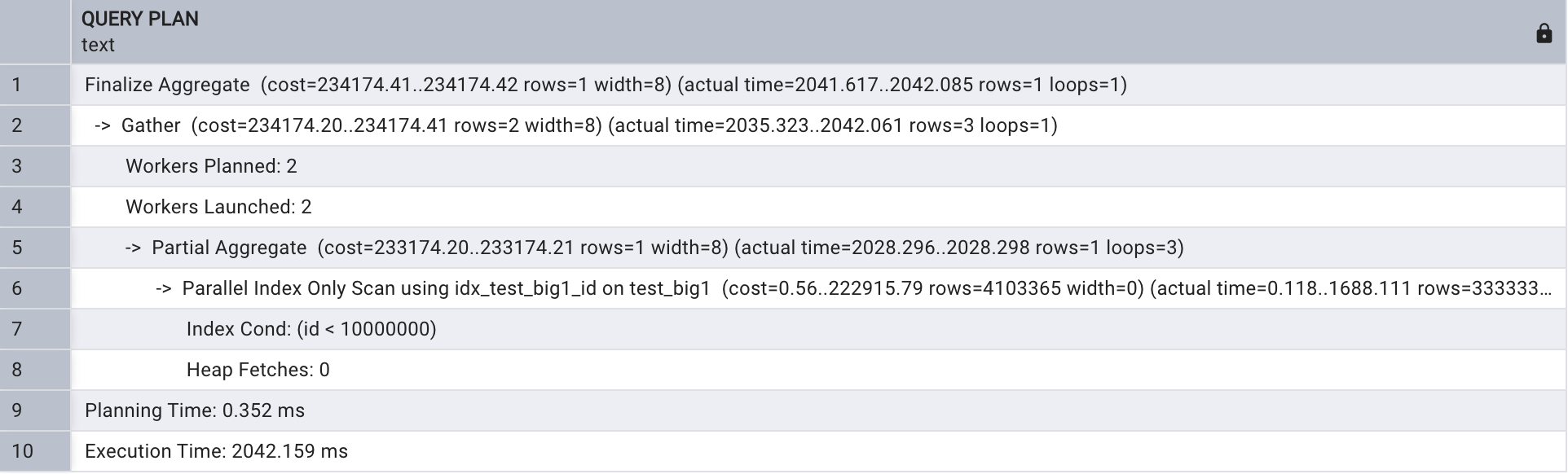
上執行計劃主要看 Parallel Index Only Scan 這段 ,進行了并行 index-only 掃描。
2.4、并行bitmap heap掃描
紹并行 bitmap heap 掃描之前先了解下 Bi tmap Index 掃描和 Bitmap Heap 掃描, 當 SQL的where 條件中出現or時很有可能出現 Bitmap Index 掃描 , 如下所示 :
explain select *
from test_big1
where id = 1 or id = 2;

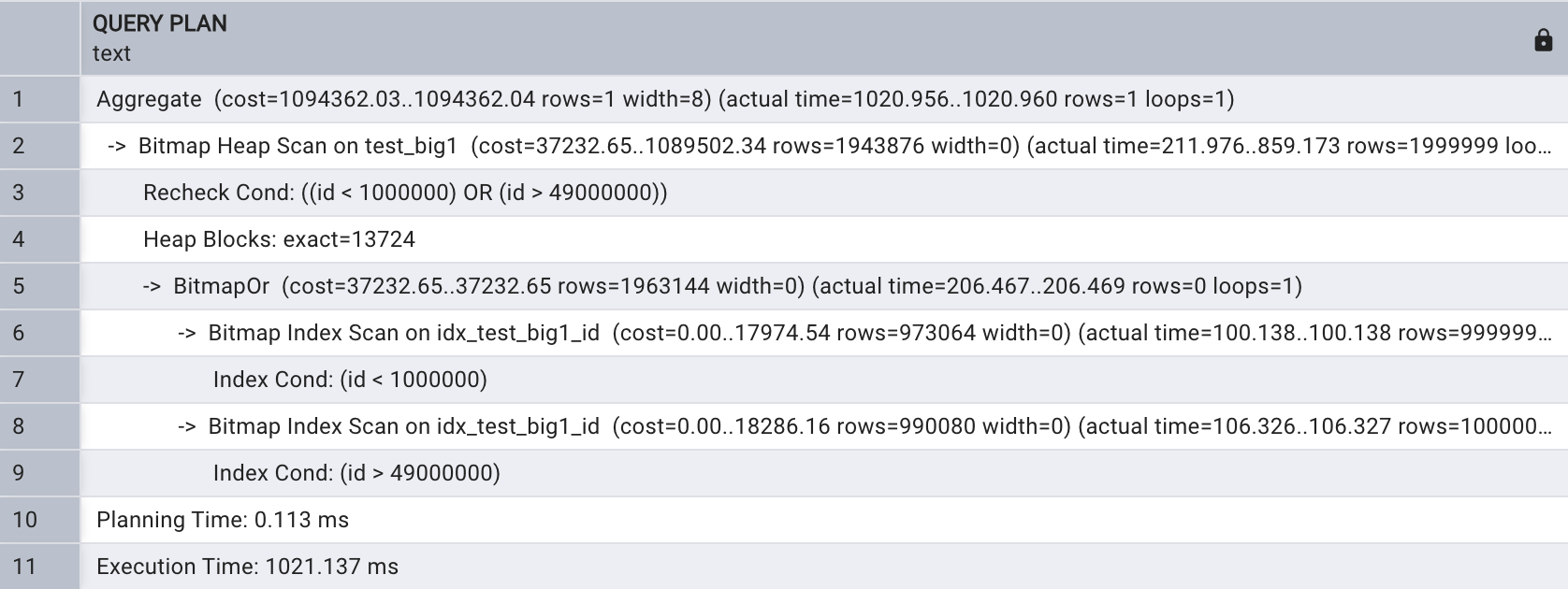
從以上執行計劃看出,首先執行兩次 Bitmap Index 掃描 獲取索 引項,之后將 Bitmap Index掃描獲取的結果合起來回表查 詢 ,這時在表test_bigl 上進行了Bitmap Heap 掃描 。
Bitmap Heap 掃描也支持并行,執行以下 SQL ,在查詢條件中將 ID 的選擇范圍擴大。
explain analyze select count(*)
from test_big1
where id < 1000000 or id > 49000000;
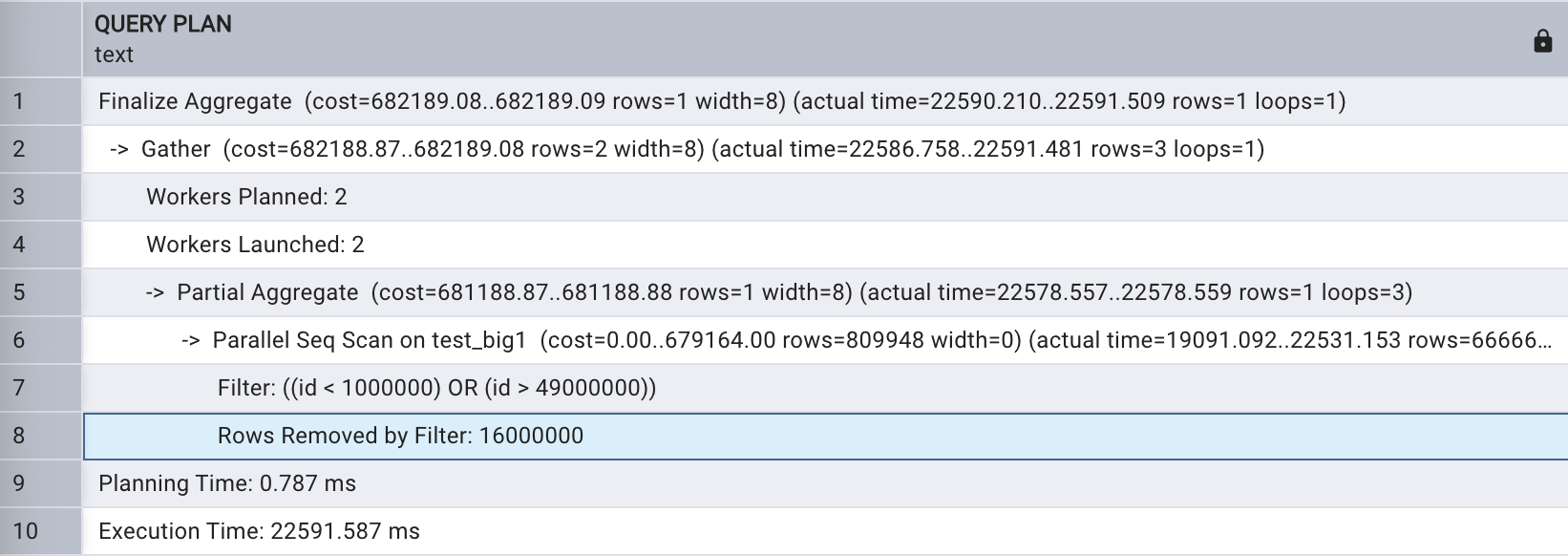
會話級關閉并行查詢,如下所示:
set max_parallel_workers_per_gather = 0;explain analyze select count(*)
from test_big1
where id < 1000000 or id > 49000000;
三、并行聚合
合操作是指使用 count() 、 sum() 等聚合函數 的 SQL ,以下執行 count ()函數統計表記錄總數,執行計劃如下所示 :
explain analyze select count(*)
from test_big1;

從以上執行計劃 看 出, 首先進行 Part i al Aggregate , 開 啟了 四個 并 行進程, 最后進行Finalize Aggregate。
這個例子充分驗證 了聚合查詢 count ()能 夠支持并行 , 為 了 初 步測試并行性能,在會話級別關閉并行查詢,如下所示 :
set max_parallel_workers_per_gather = 0;explain analyze select count(*)
from test_big1;

不同并行進程數下的全表掃描執行時間:

四、多表關聯
4.1、Nested loop多表關聯
多表關聯 Nested loop 實際上是一個嵌套循環, 偽代碼如下所示 :
for (i = 0; i < length(outer); i++)for (j = 0; j < length(inner); j++)if (outer[i] == inner[j])output(outer[i], inner[j]);
接著 測試 Nested loop 多表關聯場景 下使用到并行掃描 的情況,創建一張 test_small 小表,如下所示 :
create table test_small(id int4,name character varying(32)
);insert into test_small(id, name)
select n, n || '_small'
from generate_series(1, 800000) n;
ANALYZE 命令用于收集表上的統計信息,使優化器能夠獲得更準確的執行計劃,兩表關聯執行計劃如下所示 :
explain analyze select test_small.name
from test_big1, test_small
where test_big1.id = test_small.id and test_small.id < 10000;
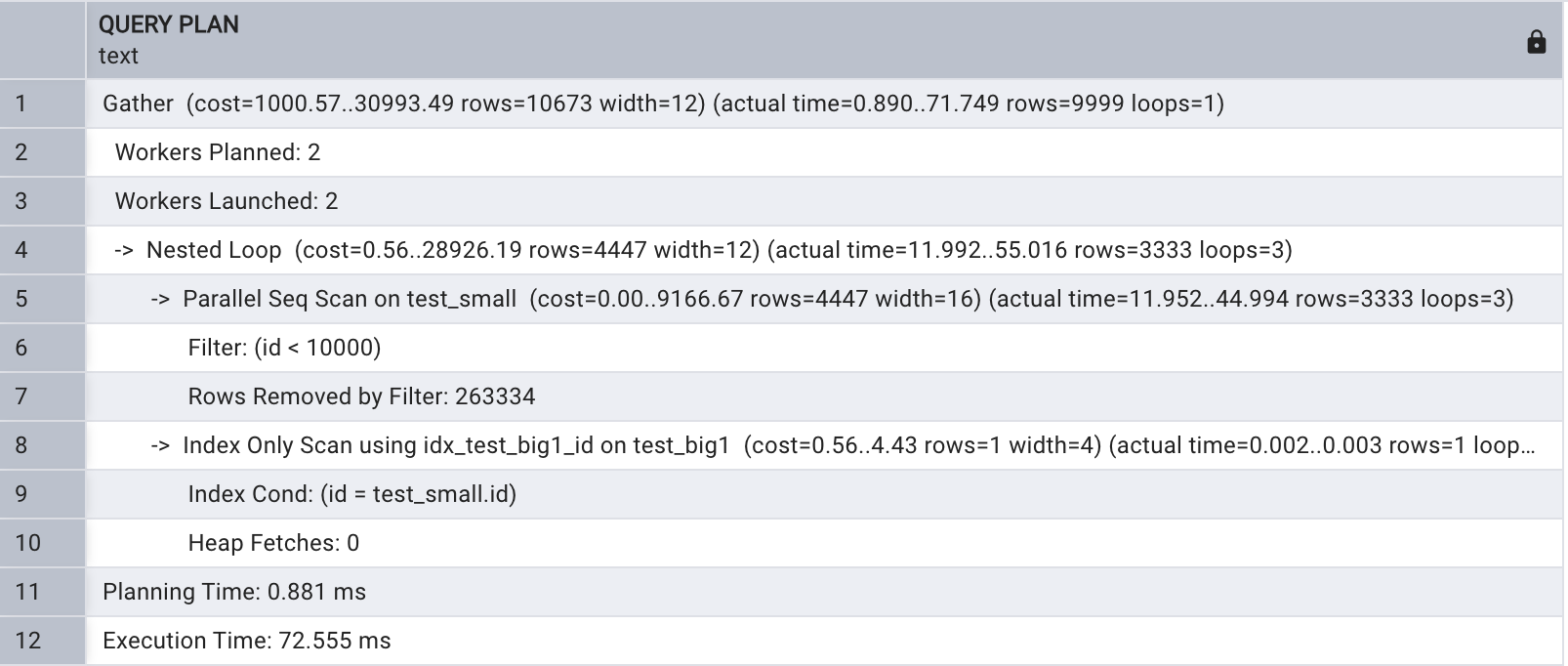
從以上執行計劃可以 看出,首先在表 test_bigl 上進行 了 Index Only 掃描,用于檢索 id 小于 10000 的記錄,之后兩表進行 Nested loop 關聯同時在表 test_small I 上進行了并行 Bitmap Heap 掃描,用于檢索 id 小于 10000 的記 錄。
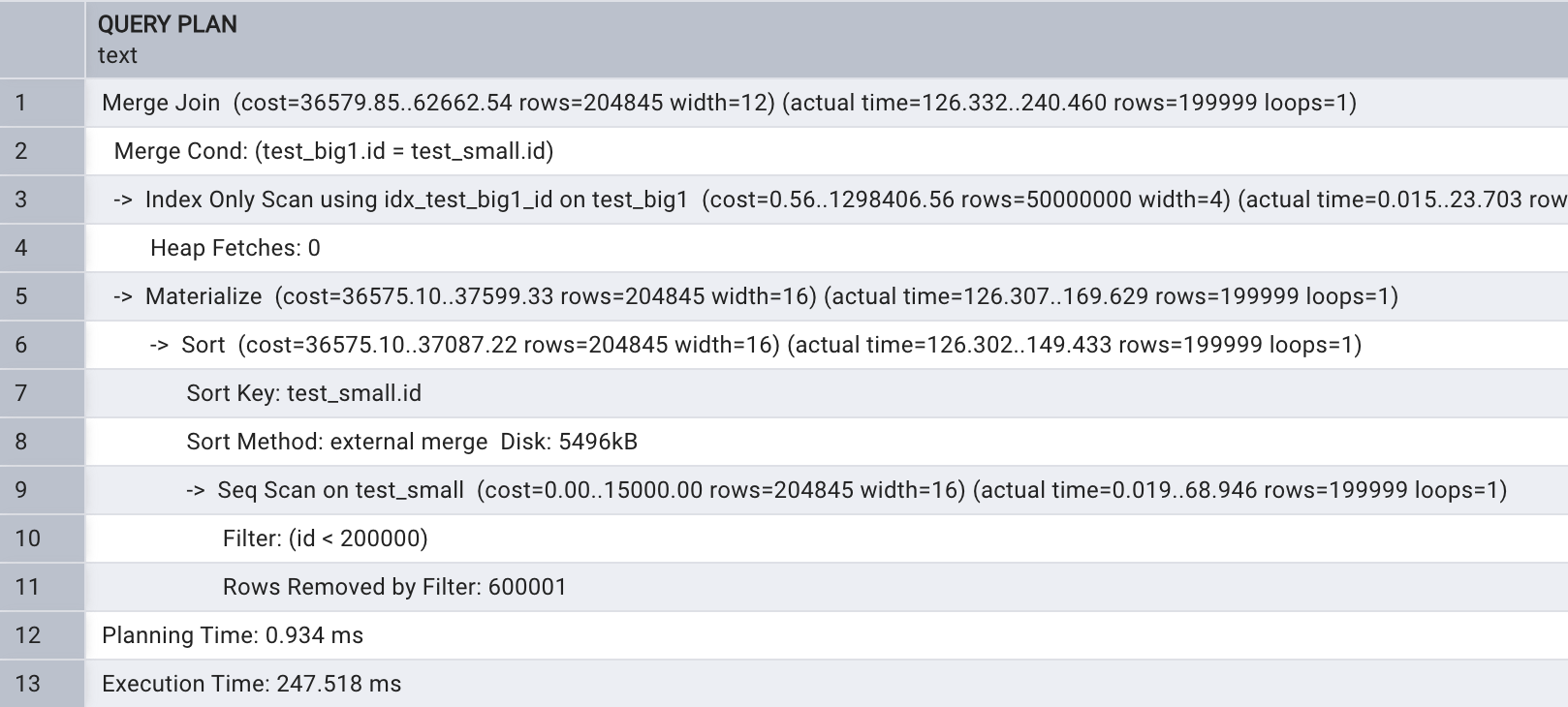
4.2、Merge join多表關聯
Merge join 多表關聯首先將兩個表進行排序,之后進行關聯宇段匹配 , Merge join 示例如下所示:
explain analyze select test_small.name
from test_big1, test_small
where test_big1.id = test_small.id
and test_small.id < 200000;
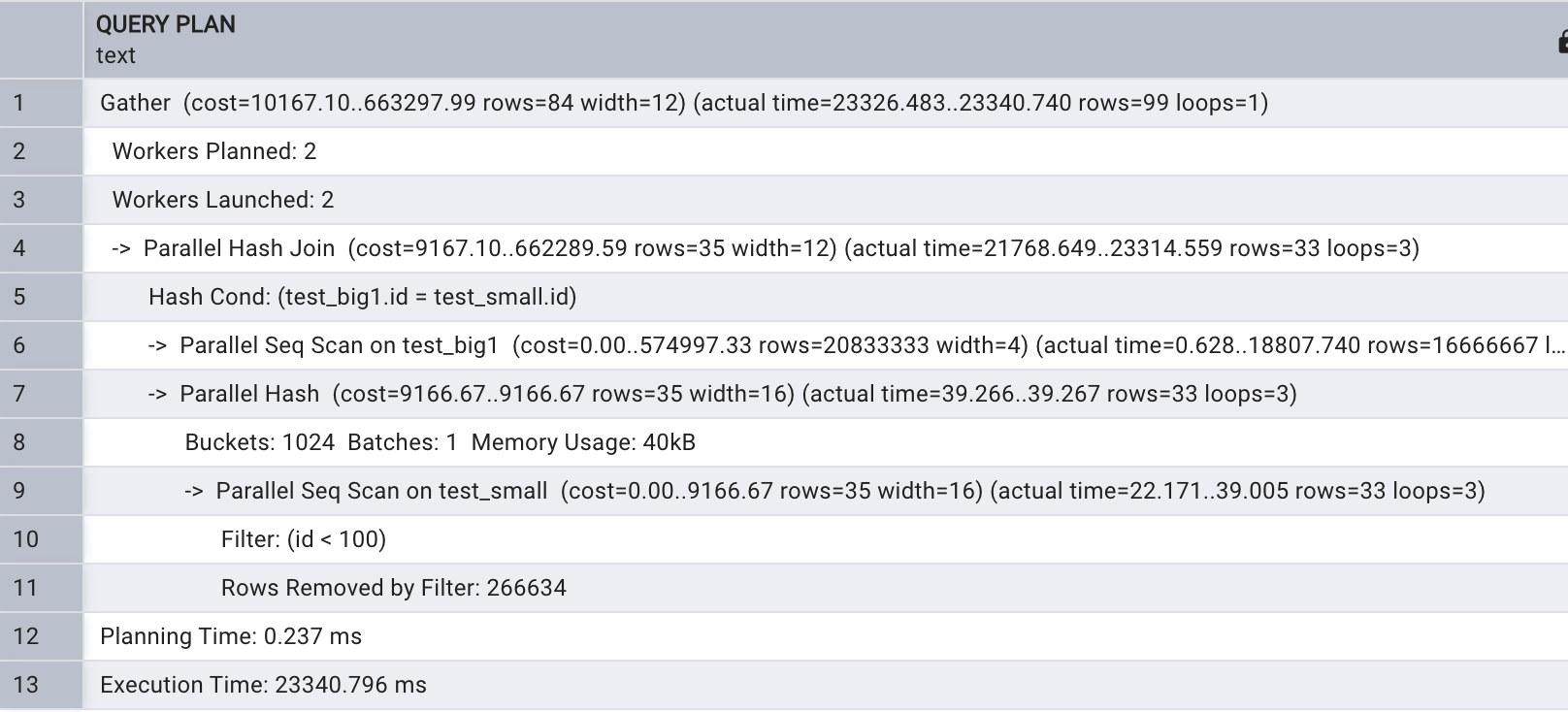
4.3、Hash join多表關聯
ostgreSQL 多表關聯也支持 Hash join , 當關聯宇段沒有索引情況下兩表關聯通常會進行 Hash join ,接 下 來查看 Hash join 的執行計劃 ,先將兩張表上 的索引刪除,同時關閉并行,如下所示:
drop index idx_test_big1_id;drop index idx_test_small_id;explain analyze select test_small.name
from test_big1 join test_small
on test_big1.id = test_small.id and test_small.id < 100;

)



![SQLI-labs[Part 2]](http://pic.xiahunao.cn/SQLI-labs[Part 2])

![[硬件電路-194]:NPN三極管、MOS-N, IGBT比較](http://pic.xiahunao.cn/[硬件電路-194]:NPN三極管、MOS-N, IGBT比較)

后半)
 用戶手冊)

![Vue模板中傳遞對象或數組時,避免直接使用字面量[]和{}](http://pic.xiahunao.cn/Vue模板中傳遞對象或數組時,避免直接使用字面量[]和{})




)
)
