摘要:通過視覺指令微調訓練的多模態大型語言模型(MLLMs)在各類任務中均取得了優異表現,然而在以視覺為中心的任務(如物體計數或空間推理)中,其性能仍存在局限。我們將這一差距歸因于當前主流的純文本監督范式,該范式僅為視覺通路提供間接指導,常導致多模態大型語言模型在訓練過程中舍棄精細的視覺細節。在本文中,我們提出了視覺表征對齊(VIsual Representation ALignment,VIRAL)方法,這是一種簡單而有效的正則化策略,可使多模態大型語言模型的內部視覺表征與預訓練視覺基礎模型(Vision Foundation Models,VFMs)的表征對齊。通過顯式強制執行這種對齊,VIRAL不僅能讓模型保留來自輸入視覺編碼器的關鍵視覺細節,還能從視覺基礎模型中補充額外的視覺知識,從而增強其處理復雜視覺輸入的推理能力。我們的實驗表明,在廣泛采用的多模態基準測試的所有任務中,該方法均實現了性能的持續提升。此外,我們還進行了全面的消融研究,以驗證我們框架背后的關鍵設計選擇。我們認為,這一簡單發現為在訓練多模態大型語言模型時有效整合視覺信息開辟了重要方向。Huggingface鏈接:Paper page,論文鏈接:2509.07979
研究背景和目的
研究背景:
隨著多模態大型語言模型(MLLMs)的發展,這些模型在處理多樣化任務時展現出強大的能力,尤其是在結合視覺和語言信息的任務中取得了顯著進展。然而,盡管MLLMs在多種任務中表現優異,它們在處理以視覺為中心的任務時仍面臨挑戰,如物體計數和空間推理等任務。這些任務要求模型不僅理解文本信息,還需要精確捕捉和處理視覺細節。
現有的MLLMs主要依賴于文本監督進行訓練,這種訓練方式雖然有效提升了模型的文本理解和生成能力,但往往忽視了視覺信息的精細處理。具體來說,傳統的視覺指令微調方法主要集中于語言建模目標,即通過最大化文本輸出的對數似然來更新模型參數,而視覺表示僅通過文本輸出間接獲得監督。這種間接監督方式導致模型在訓練過程中容易丟失視覺編碼器提供的豐富視覺細節,從而影響其在視覺相關任務中的表現。
為了解決這一問題,研究人員開始探索如何更有效地整合視覺信息到MLLMs中。其中一個關鍵挑戰在于如何確保模型在訓練過程中保留并利用視覺編碼器提供的精細視覺特征。為此,本研究提出了視覺表示對齊(VIRAL)策略,旨在通過顯式對齊MLLMs的內部視覺表示與預訓練視覺基礎模型(VFMs)的表示,來增強模型對復雜視覺輸入的理解能力。
研究目的:
本研究的主要目的是通過引入視覺表示對齊策略,解決MLLMs在處理以視覺為中心的任務時面臨的挑戰。具體來說,研究旨在實現以下幾個目標:
- 提升視覺細節保留能力:通過VIRAL策略,使MLLMs在訓練過程中能夠保留視覺編碼器提供的精細視覺特征,從而增強模型在物體計數、空間推理等視覺相關任務中的表現。
- 增強多模態理解能力:通過顯式對齊MLLMs的內部視覺表示與VFMs的表示,使模型能夠更好地理解和處理多模態輸入,從而提升其在復雜視覺場景下的推理能力。
- 驗證VIRAL策略的有效性:通過廣泛的實驗驗證VIRAL策略在提升MLLMs視覺理解能力方面的有效性,并探索其在不同視覺編碼器和語言模型骨干網絡上的通用性。
研究方法
1. 視覺表示對齊策略(VIRAL):
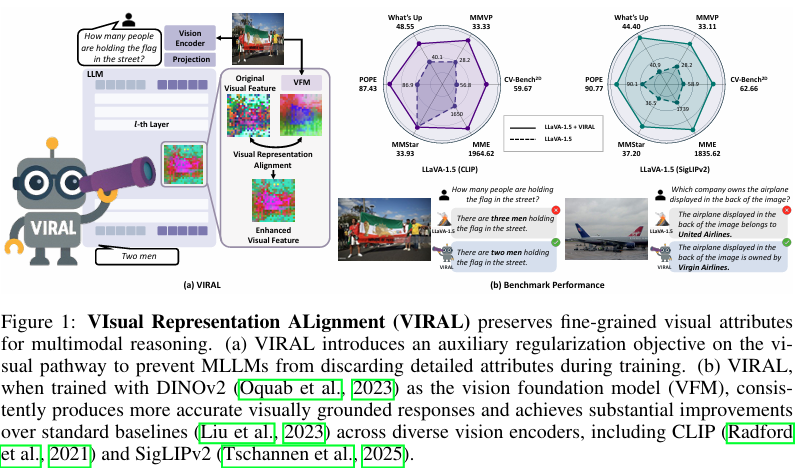
VIRAL策略的核心思想是通過顯式對齊MLLMs的內部視覺表示與預訓練VFMs的表示,來增強模型對視覺細節的處理能力。具體來說,VIRAL在MLLMs的視覺表示層引入了一個輔助的正則化目標,該目標通過最小化MLLMs內部視覺表示與VFMs特征之間的余弦相似度損失來實現對齊。
2. 模型架構:
實驗基于LLaVA-1.5架構,該架構結合了預訓練的語言模型(如Vicuna-1.5)和視覺編碼器(如CLIP),并通過一個輕量級的視覺-語言投影器將視覺特征映射到語言模型的嵌入空間。為了驗證VIRAL策略的有效性,研究還探索了不同視覺編碼器(如SigLIPv2)和語言模型骨干網絡(如Qwen2.5-7B)的組合。
3. 實驗設置:
- 數據集:實驗主要在LLaVA-665K數據集上進行,該數據集包含了多樣化的多模態指令數據。
- 訓練參數:使用LoRA進行高效適應,批量大小為64,學習率設置為3e-5。
- 評估指標:評估指標包括CV-Bench2D、What’s Up、MMVP、MME、MMStar和POPE等,以全面評估模型在視覺中心任務和一般多模態理解任務上的表現,并確保模型的整體能力。
研究結果
1. 基準測試結果:
實驗結果顯示,與基線模型相比,使用VIRAL策略在所有測試設置下均顯著提高了模型在所有任務上的性能。特別是在以視覺為中心的任務中,如物體計數和空間推理任務上,VIRAL策略顯著優于僅使用文本監督的基線模型,展示了更優的性能提升。例如,在CV-Bench2D和MMVP任務上,VIRAL策略相比基線模型分別實現了高達33.33%和33.11%的準確率提升。
2. 內部表示分析:
通過層間相似性分析和注意力分析,研究揭示了VIRAL策略如何幫助模型在中間層保留更精細的視覺特征,從而增強了對視覺場景的理解能力。例如,在16層模型中,VIRAL策略相比基線模型在注意力定位任務上表現出更低的空間熵,表明模型能夠更集中地關注與給定文本提示相關的圖像區域。
3. 魯棒性分析:
為了驗證VIRAL策略是否使模型對視覺細節更加敏感,研究設計了視覺標記隨機排列測試。實驗結果顯示,使用VIRAL策略訓練的模型在隨機排列輸入下的性能下降更顯著,表明該策略確實增強了模型對空間關系的捕捉能力。
研究局限
盡管VIRAL策略在提升MLLMs視覺理解能力方面展現出顯著效果,但研究仍存在一些局限性:
1. 數據依賴性問題:
VIRAL策略的性能提升高度依賴于高質量VFMs提供的監督信號,對于缺乏足夠VFM支持的場景,其效果可能受限。
2. 泛化能力:
盡管實驗在多種任務上驗證了VIRAL策略的通用性,但對于更復雜的推理任務,如涉及動態對象跟蹤的任務,VIRAL策略可能需要進一步調整以保持最佳性能。
3. 訓練效率:
VIRAL策略引入了額外的模型參數和計算開銷,可能對訓練效率產生一定影響,特別是在資源有限的情況下。未來研究需要探索更高效的訓練策略以平衡性能提升和計算成本。
未來研究方向
針對VIRAL策略的局限性和潛在改進空間,未來研究可以從以下幾個方面展開:
1.1 探索更精細的對齊機制:
研究可以探索更復雜的對齊目標(如特定中間層的多目標對齊)或引入額外的正則化約束,以進一步提升模型對復雜視覺場景的理解能力。
3.2 結合自監督學習:
將VIRAL策略與自監督學習目標結合,利用未標注的視覺數據增強模型對視覺表示的學習能力,減少對標注數據的依賴。
3.3 跨模態對齊:
探索跨模態表示對齊方法,使模型能夠更好地理解和處理跨模態輸入(如文本-圖像對),從而提升在復雜視覺場景下的推理能力。
3.4 實際應用驗證:
在實際應用場景中驗證VIRAL策略的有效性,如機器人視覺導航、自動駕駛等領域,通過實際應用反饋進一步優化策略設計。
總之,本研究通過引入VIRAL策略顯著提升了MLLMs在處理以視覺為中心任務時的表現。未來研究可以進一步探索更精細的對齊機制、結合自監督學習、跨模態對齊以及實際應用驗證等方向,以推動MLLMs在視覺理解能力上的持續進步。







)




)






