從 PDF 中提取文本一直是很多人的需求。市面上的工具雖然能處理大部分數字 PDF,但遇到掃描件 PDF 時往往無能為力,想要直接復制或獲取其中的文字并不容易。其實這個問題并不是沒有解法 —— 本文將帶你了解如何借助 Python + OCR 技術,從掃描 PDF 中提取可編輯文本。
為什么提取掃描件 PDF 需要用到 OCR 技術
在探討如何從掃描件 PDF 中提取文本之前,我們先來了解一下 OCR 技術 及其重要性。
OCR(Optical Character Recognition,光學字符識別),是一種將圖像或視頻中的文字內容轉化為可編輯文本的技術。它不僅能識別字符,還能保留一定的排版信息,因此被廣泛應用在文檔數字化、檔案管理以及數據提取等場景中。
為什么提取掃描件 PDF 的文本離不開 OCR?原因在于 PDF 文件主要分為兩類:
- 標準 PDF(數字 PDF):文檔中的文字是以字符形式存儲的,可以直接復制、搜索和提取。
- 掃描件 PDF:內容本質上是圖片,不包含可識別的文本信息,傳統的提取方法無法處理。
因此,當面對掃描件 PDF 時,OCR 技術就顯得尤為必要,它能幫助我們將圖片中的文字識別出來,轉換為真正可操作的文本。
安裝必要的 Python 庫
在了解了基礎知識之后,我們進入到 工具準備環節。本文將主要使用兩款庫:Spire.PDF for Python 和 Spire.OCR for Python。有了它們,處理掃描件 PDF 并提取文本會變得高效而簡單。
- Spire.PDF:負責將掃描件 PDF 轉換為適合 OCR 處理的圖片。
- Spire.OCR:對這些圖片進行文字識別,并輸出可編輯的文本內容。
它們的安裝方式十分便捷,只需在命令行中運行以下命令:
pip install spire.pdf
pip install spire.ocr
除了使用 pip 安裝外,你也可以前往 E-iceblue 官網 下載相應的安裝包并手動安裝。
通過 Python 將 PDF 轉換為圖像
正如前面提到的,OCR 無法直接處理 PDF 文件,尤其是掃描件 PDF。因此,第一步我們需要先將其轉換為圖片。借助 Spire.PDF,這個過程十分簡便:只需加載 PDF 文檔,遍歷頁面,然后調用 PdfDocument.SaveAsImage() 方法,就能將每一頁保存為圖像文件。
在保存時,你還可以根據需求選擇 PNG、JPG 或 BMP 等常見格式。下面的示例代碼演示了如何使用 Python 將掃描件 PDF 轉換為 PNG 圖片:
from spire.pdf import *# 加載 PDF 文件
pdf = PdfDocument()
pdf.LoadFromFile("E:/Administrator/Python1/input/AI繪畫的利與弊.pdf")# 遍歷 PDF 頁面
for i in range(pdf.Pages.Count):# 將每一頁轉換為圖像with pdf.SaveAsImage(i) as image:# 保存圖像image.Save(f"E:/Administrator/Python1/output/pdftoimage/ToImage_{i}.png")# image.Save(f"Output/ToImage_{i}.jpg")# image.Save(f"Output/ToImage_{i}.bmp")pdf.Close()
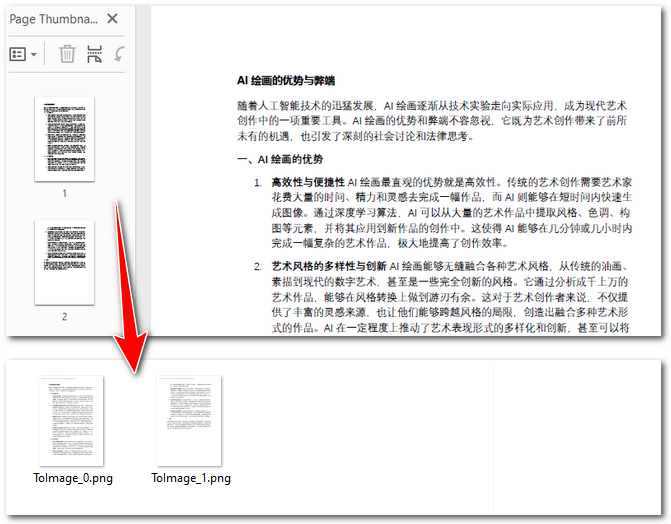
OCR 識別并提取掃描件 PDF 中的文本
完成 PDF 轉圖片 的步驟后,我們就可以進入核心環節——使用 OCR 掃描圖片并提取文字。借助 OcrScanner.Scan() 方法,這個過程非常簡單。它不僅能夠從圖片中獲取文本,還支持包括 中文、英文、法語 在內的多種語言識別,可以做到“一字不落”。
下面的示例演示了如何在 Python 中調用 OCR,對前一步生成的 PDF 圖片進行文字識別,并將結果保存為 .txt 文檔:
from spire.ocr import *# 創建 OCR 掃描器實例
scanner = OcrScanner()# 配置 OCR 模型路徑和語言
configureOptions = ConfigureOptions()
configureOptions.ModelPath = r'E:/DownloadsNew/win-x64/'
configureOptions.Language = 'Chinese'
scanner.ConfigureDependencies(configureOptions)# 使用 OCR 掃描圖片
scanner.Scan(r'E:/Administrator/Python1/output/pdftoimage/ToImage_0.png')# 將提取的文本保存為文本文件
text = scanner.Text.ToString()
with open('E:/Administrator/Python1/output/掃描件PDF文本提取.txt', 'a', encoding='utf-8') as file:file.write(text + '\n')

結論
通過本文的示例,我們完成了從掃描件 PDF 轉換為圖片,再利用 OCR 技術識別并提取文本的全過程。借助 Spire.PDF for Python 和 Spire.OCR for Python,這一流程不僅簡單高效,而且對多語言的支持也非常友好。如果你也在尋找快速處理掃描件 PDF 的方法,不妨嘗試一下這兩個庫。









)
完全指南及電商銷售數據TreeMap繪制實戰)








