
文章目錄
- Java集合之Set:無序不重復的元素容器
- 一、Set接口的核心特性
- 二、常用實現類及底層原理
- 1. HashSet:基于哈希表的高效實現
- 2. LinkedHashSet:保留插入順序的哈希實現
- 3. TreeSet:基于紅黑樹的排序實現
- 三、實現類對比與選擇建議
- 四、使用注意事項
- 總結
Java集合之Set:無序不重復的元素容器
在Java集合框架中,Set是與List并列的重要接口,它以“無序且元素不重復”為核心特性,在數據去重、快速查找等場景中被廣泛應用。本文將深入解析Set接口及其常用實現類,幫助你理解它們的底層原理與適用場景。
一、Set接口的核心特性
Set繼承自Collection接口,但其行為與List有顯著區別:
- 無序性:元素的存儲順序與插入順序無關(特殊實現類如
LinkedHashSet除外),不能通過索引訪問元素。 - 唯一性/不重復:集合中不允許存在重復元素,判斷重復的依據是
equals()方法,若元素重寫了equals(),通常需同時重寫hashCode()以保證一致性。 - 無索引:沒有類似
get(int index)的方法,遍歷需通過迭代器(Iterator)或增強for循環。
Set接口的常用方法與Collection基本一致,如add()、remove()、contains()、size()等,核心差異體現在實現類對“去重”和“查找效率”的不同優化上。
二、常用實現類及底層原理
1. HashSet:基于哈希表的高效實現

1. JDK8以后,當鏈表長度超過8,而且數組長度大于等于64時,自動轉換為紅黑樹
2. 如果集合中存儲的是自定義對象,必須重寫hashCode和equals方法才能用來比較屬性值是否相同
在知道了HashSet的底層原理后,我們就可以回答以下三個問題了:
1. HashSet為什么存和取的順序不一樣?
因為HashSet可能是數組+鏈表+紅黑樹的結合體,而取的時候,是從最小的地址值開始遍歷,而先放進去的元素的地址值不一定就小,以上都造成了HashSet的存取順序不同。
2. HashSet為什么沒有索引?
因為HashSet是數組+鏈表+紅黑樹的結合體,若存在索引,無法分配索引,難道同一個鏈表上和同一個紅黑樹上的元素都用同一個索引碼,因此便取消了HashSet的索引。
3. HashSet是利用什么機制保證數據去重的?
首先利用 HashCode方法來確定元素的位置,再通過equals方法來判斷屬性值是否重復【重寫了HashCode 和 equals 方法】。
HashSet是Set最常用的實現類,底層通過哈希表(HashMap) 實現,其核心特性如下:
- 存儲原理:借助
HashMap的key存儲元素(value為固定常量),利用哈希表的特性保證元素唯一。 - 去重邏輯:添加元素時,先通過
hashCode()計算哈希值,若哈希值不同則直接存儲;若哈希值相同,再通過equals()判斷是否為同一元素,相同則拒絕添加。 - 性能:
- add()、remove()、contains()等操作的平均時間復雜度為O(1),效率極高。
- 無序性:元素存儲位置由哈希值決定,與插入順序無關。
- 注意事項:
- 元素需重寫
hashCode()和equals(),否則可能導致重復元素存入(如自定義對象未重寫方法時,默認使用地址值判斷【重要的事反復強調】)。 - 線程不安全,多線程環境需手動同步(如使用
Collections.synchronizedSet())。
- 元素需重寫
示例代碼:
Set<String> hashSet = new HashSet<>();
hashSet.add("apple");
hashSet.add("banana");
hashSet.add("apple"); // 重復元素,添加失敗
System.out.println(hashSet); // 輸出可能為 [banana, apple](順序不確定)
2. LinkedHashSet:保留插入順序的哈希實現
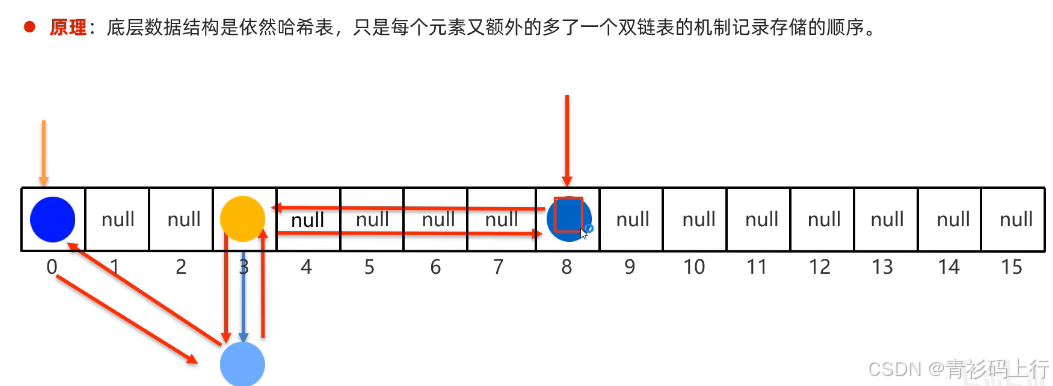
LinkedHashSet繼承自HashSet,底層通過LinkedHashMap實現,在哈希表基礎上增加了雙向鏈表,用于記錄元素的插入順序,因此具備以下特性:
- 有序性:遍歷元素時按插入順序返回,解決了
HashSet的無序問題。 - 性能:
- 插入和刪除效率略低于
HashSet(因需維護鏈表),但遍歷效率更高。 - 時間復雜度仍為O(1)(平均),與
HashSet接近。
- 插入和刪除效率略低于
- 適用場景:需要去重且保留插入順序的場景(如日志記錄、歷史操作跟蹤)。
示例代碼:
Set<String> linkedHashSet = new LinkedHashSet<>();
linkedHashSet.add("first");
linkedHashSet.add("second");
linkedHashSet.add("first"); // 去重
System.out.println(linkedHashSet); // 輸出 [first, second](順序與插入一致)
3. TreeSet:基于紅黑樹的排序實現
TreeSet底層通過紅黑樹(自平衡二叉查找樹) 實現,核心特性是元素可排序:
- 兩種排序方式:
- 自然排序:元素實現
Comparable接口,重寫compareTo()方法(如Integer、String默認支持)。
- 自然排序:元素實現
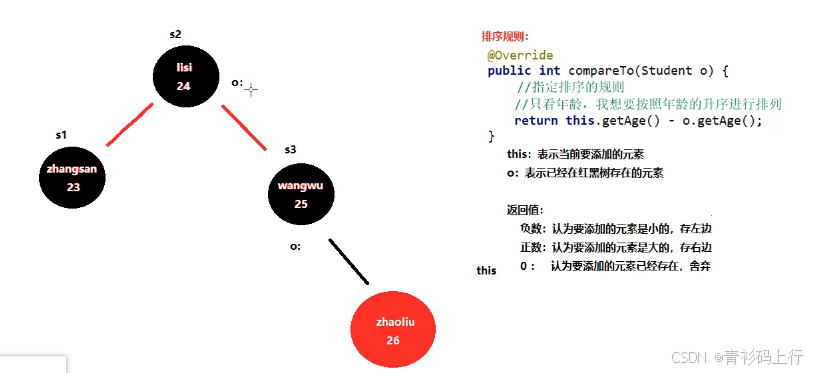
代碼示例:
public class Student implements Comparable<Student> {private String name;private int age;@Overridepublic int compareTo(Student o) {//this:表示當前要添加的元素//o:表示已經在紅黑樹存在的元素return this.age - o.age; // 按年齡升序排列} }排序規則圖示:
適用場景
- 元素類有明確且唯一的默認排序邏輯(如數字按大小、字符串按字典序)。
- 排序規則需要在多處復用,且不會頻繁變更。
- 元素類是自定義類,允許修改其代碼以實現 Comparable 接口。
定制排序 / 比較器排序:創建TreeSet時傳入Comparator對象,自定義排序邏輯。
// 按字符串長度排序
// lambda表達式版:
TreeSet<String> ts= new TreeSet<>((o1, o2) -> o1.length() - o2.length());// 原始版本:
TreeSet<String> ts= new TreeSet<>(new Comparator<String>() {@Override// o1:表示當前要添加的元素// o2:表示已經在紅黑樹存在的元素public int compare(String o1, String o2) {return o1.length() - o2.length();}
});
適用場景
- 元素類無法修改(如 String、Integer 等 JDK 內置類),無法實現 Comparable。
- 需要臨時改變排序規則(同一批元素在不同場景下按不同規則排序)。
- 元素類已有默認排序,但需要覆蓋默認規則(如數字默認升序,需臨時按降序排列)。
- 去重邏輯:通過排序規則判斷元素是否重復(
compareTo()返回0則視為重復,而非 equals() 方法,因為其底層為紅黑樹,非哈希表)。 - 性能:
- add()、remove()、contains()操作的時間復雜度為O(log n),適合需要頻繁排序和查找的場景。
- 遍歷元素時按排序順序返回,無需額外排序操作。
- 注意事項:
- 元素必須可比較(否則會拋出
ClassCastException)。 - 線程不安全,多線程環境需同步處理。
- 元素必須可比較(否則會拋出
示例代碼:
// 自然排序(String默認按字典序)
Set<String> treeSet = new TreeSet<>();
treeSet.add("orange");
treeSet.add("apple");
treeSet.add("banana");
System.out.println(treeSet); // 輸出 [apple, banana, orange](按字典序排序)// 定制排序(整數降序)
Set<Integer> customTreeSet = new TreeSet<>((a, b) -> b - a);
customTreeSet.add(3);
customTreeSet.add(1);
customTreeSet.add(2);
System.out.println(customTreeSet); // 輸出 [3, 2, 1]
使用原則:默認使用第一種,如果第一種不能滿足當前需求,就使用第二種
三、實現類對比與選擇建議
三者均不重復,且無索引 ? 哈希表 => 數組+單向鏈表+紅黑樹
| 實現類 | 底層結構 | 有序性 | 去重依據 | 平均時間復雜度 | 適用場景 |
|---|---|---|---|---|---|
| HashSet | 哈希表 | 無序 | hashCode() + equals() | O(1) | 高效去重,不關心順序 |
| LinkedHashSet | 哈希表+雙向鏈表 | 有序,插入順序 | hashCode() + equals() | O(1) | 去重且需保留插入順序 |
| TreeSet | 紅黑樹 | 可排序 | compareTo()/Comparator | O(log n) | 去重且需排序或頻繁范圍查詢 |
四、使用注意事項
-
元素的不可變性:若元素是可變對象,修改其屬性可能導致哈希值或排序位置變化,引發
Set內部狀態混亂(如HashSet中元素修改后可能無法被正確查找)。建議使用不可變對象(如String、Integer)作為Set元素。 -
hashCode()與equals()的一致性:
- 若
a.equals(b) == true,則a.hashCode()必須等于b.hashCode()。 - 重寫時盡量保證哈希值分布均勻(減少哈希沖突),避免影響
HashSet性能。
- 若
-
線程安全:所有
Set實現類均線程不安全,多線程并發修改時需使用Collections.synchronizedSet()包裝,或直接使用ConcurrentHashMap(JDK 1.8+)的newKeySet()方法創建線程安全的Set。
總結
HashSet追求高效,LinkedHashSet兼顧順序,TreeSet專注排序。理解它們的底層原理(哈希表、紅黑樹)和特性差異,能幫助你在實際開發中選擇最合適的容器,提升代碼效率與可讀性。
如果我的內容對你有幫助,請 點贊 , 評論 , 收藏 。創作不易,大家的支持就是我堅持下去的動力!








)











