近年來,人工智能領域已經取得突破性進展,對經濟社會各個領域都產生了重大影響,結合了統計學、數據科學和計算機科學的機器學習是人工智能的主流方向之一,目前也在飛快的融入計量經濟學研究。表面上機器學習通常使用大數據,而計量經濟學則通常使用較小樣本,但這種區別日漸模糊,機器學習在經濟學領域、特別是經濟學與其它學科的交叉領域表現日益突出。R語言是用于統計建模的主流計算機語言,用于機器學習十分方便,且學習曲線相比于Python更加平滑,因此是進行機器學習的首選之一。在本次培訓中,我們將從論文寫作的實際需求出發,首先簡單的介紹經濟學的基本理論與研究方法,讓您了解論文的選題方法與寫作框架。隨后重點從數據的收集與清洗、綜合建模評價、數據的分析與可視化、數據的空間效應、因果推斷等方面入手,讓您用最快的速度掌握利用R語言進行經濟學研究的技術。同時也會對論文寫作中經常用到的輔助軟件進行介紹,盡量降低論文寫作的難度。
專題一、理論基礎與軟件介紹
1.1 經濟學基礎原理
主要內容:
經濟學思考范式,資源配置,效率與公平(古典經濟學領域)。
格里高利·曼昆,通俗的講述了十大經濟學原理
例如,大衛·李嘉圖的比較優勢的原理。
例如,機會與成本。正U型定價曲線,MC(邊際成本)ACT(平均總成本)
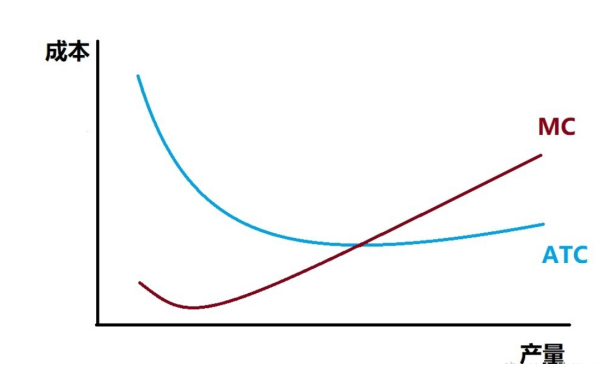
理性人假設,市場調節可能是最優解。
丹·艾瑞里 《怪誕行為學》 錨定效應
1.2 ?概率統計的基本思想
1.2.1 概率統計的常見概念
概率的誕生,奶茶問題。
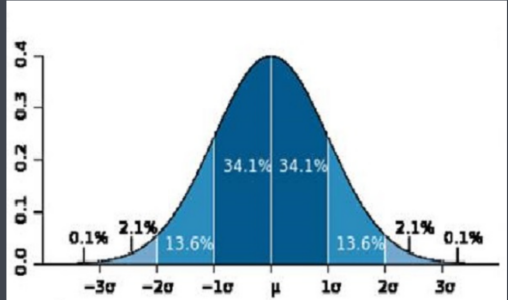
正態分布。

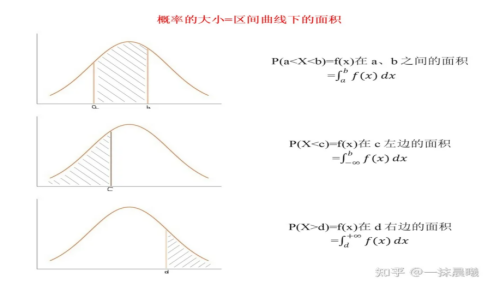
置信區間
P值
1.2.2 ?評價(單指標評價與復合指標評價)
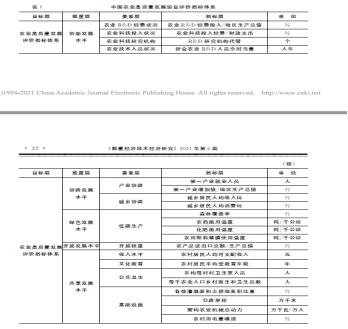
單指標評價:例如GDP
復合指數評價
指標體系評價
1.2.3 ?因果推斷
概念產生:因果推斷(Causal Inference)是根據某一結果發生的條件對因果關系作出刻畫的過程,推斷因果關系的最有效方法是進行隨機對照試驗,但這種方式耗時且昂貴、也無法解釋和刻畫個體差異;因此考慮從觀察數據中進行因果推斷,這類框架包括潛在結果框架和結構因果模型,下文對結構因果模型的因果推理方法進行綜述。

證據等級,單個案例,多個案例,隨機對照實驗,循證,機理機制分析
1.3 ?機器學習用于評價和因果推斷(算法介紹)
1.3.1KNN和Kmeans
KNN(K- Nearest Neighbor)法即K最鄰近法,最初由 Cover和Hart于1968年提出,是一個理論上比較成熟的方法,也是最簡單的機器學習算法之一。該方法的思路非常簡單直觀:如果一個樣本在特征空間中的K個最相似(即特征空間中最鄰近)的樣本中的大多數屬于某一個類別,則該樣本也屬于這個類別。該方法在定類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。
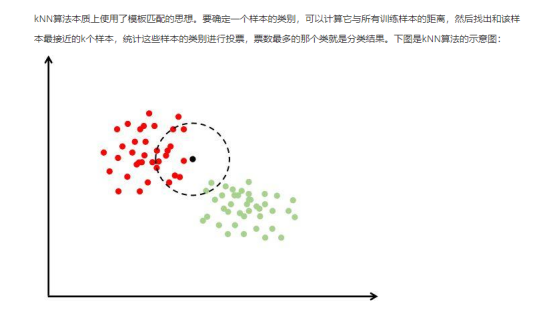
Kmeans
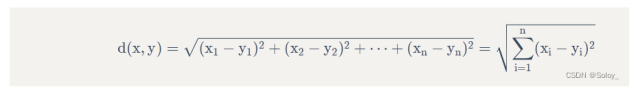

1.3.2德爾菲和AHP
德爾菲是Delphi的中文譯名。美國蘭德公司在20世紀50年代與道格拉斯公司合作研究出有效、可靠地收集專家意見的方法,以“Delphi”命名,之后,該方法廣泛地應用于商業、軍事、教育、衛生保健等領域。德爾菲法在醫學中的應用,最早開始于對護理工作的研究,并且在使用過程中顯示了它的優越性和適用性,受到了越來越多研究者的青睞。
AHP(Analytic Hierarchy Process)層次分析法是美國運籌學家T. L. Saaty教授于二十世紀70年代提出的一種實用的多方案或多目標的決策方法,是一種定性與定量相結合的決策分析方法。常被運用于多目標、多準則、多要素、多層次的非結構化的復雜決策問題,特別是戰略決策問題,具有十分廣泛的實用性。

1.3.3熵權法
TOPSIS-熵權法
熵權法是一種基于數據信息熵大小計算各個指標權重的方法,能很好的對多指標目標進行綜合評價。TOPSIS法能進一步優化熵權法的結果,使評價結果更加客觀合理[23~25]。
第一步,對數據進行標準化處理:
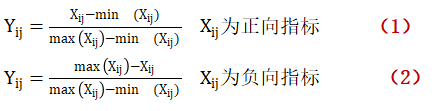
? ? ? ? ? ? ? ? ? ? ? ? ? ??
第二步,計算發展水平測度體系中的信息熵:
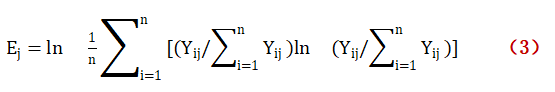
? ? ? ? ?
第三步,計算權重
? ? ??
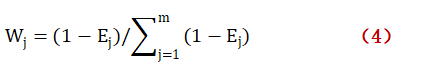
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
第四步,構建測度指標的加權矩陣R:
? ? ? ? ??
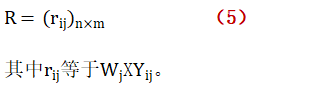
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
第五步用加權矩陣R確定最優方案,最劣方案:
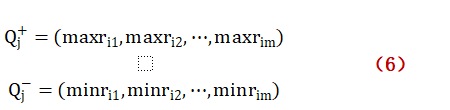
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
第六步,計算和最優最劣方案的距離和:
? ? ?
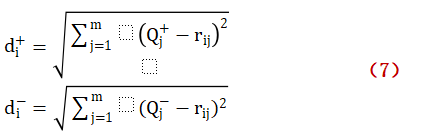
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
第七步,計算和理想方案的相對接近度:
? ? ? ? ? ? ?

? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
理想接近度的值在[0-1]之間,其值越大,就代表該區域的畜牧業發展水平越高,反之則是該區域的畜牧業發展水平越低。
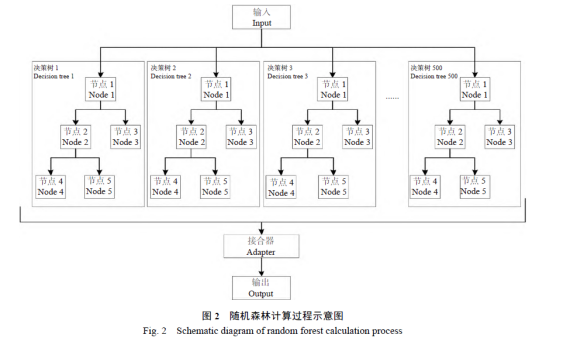
1.3.4隨機森林算法
機器學習中有一種大類叫集成學習(Ensemble Learning),集成學習的基本思想就是將多個分類器組合,從而實現一個預測效果更好的集成分類器。集成算法可以說從一方面驗證了中國的一句老話:三個臭皮匠,賽過諸葛亮。
1.3.5神經網絡
神經網絡學習分為兩個階段:一是多層前饋階段,從輸入層一次計算各層節點的實際輸入、輸出;二是反向修正階段,即根據輸出誤差,沿路反向修正各連接權重,降低誤差[27]。
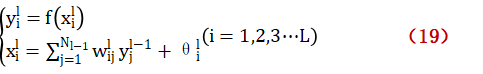
? ? ? ? ? ? ? ? ? ? ? ? ??

? ? ? ? ? ? ? ? ? ? ? ?
1.4 常用軟件介紹
Excel,R,Stata,Photoshop,Arcgis,SPSS,Geoda,Python,Notexpress,Endnote
專題二、數據的獲取與整理
2.1數據類型的介紹
定量數據,定類數據,
截面數據,時間序列數據,面板數據
2.2數據的獲取
論文,統計局,年鑒,相關網站,購買
https://www.ceads.net.cn/
統計年鑒
論文標注
2.3數據的整理
常見的格式轉換,缺失值的填補
專題三、常用評價方法與相關軟件詳細介紹(案例詳解)
3.1農業碳排放計算
3.2能源消費碳排放計算
3.3綜合評價方法
公式的輸入以及熵權法的實際操作
https://gongshi.wang/
3.4數據分析與數據可視化
常用數據可視化方法介紹
箱線圖,柱狀圖,折線圖,地理圖形等
地理學三大定律與空間自相關分析
3.5隨機森林回歸建模
3.5.1模型構建與相關參數的優化
3.5.2模型的效果評估
3.5.3模型的結果分析
3.5.4驅動因素與機制機理分析(歸因分析,驅動機制)
3.6神經網絡回歸建模
內容同上。
與其它模型效果對比
專題四、寫作要點與案例的介紹
4.1整體寫作要點
4.1.1好的開始是成功的一半(引言)
文章的選題來源
4.1.2文獻綜述的寫法
4.1.3研究方法的選擇與公式的編輯
4.1.4數據分析與可視化(分析)
4.1.5兩種討論方式的寫法(討論)
4.1.6結論與摘要的寫法
4.1.7心態建設以及期刊選擇與投稿
4.2案例介紹
4.2.1兩種常見類型論文的介紹
實驗類型的文章介紹
模型計算類文章介紹
4.2.2案例
2000—2020年山西省農業碳排放時空特征及趨勢預測
基于機器學習算法的新疆農業碳排放評估及驅動因素分析
西北地區碳排放的驅動因素與脫鉤效應研究
中國農業高質量發展的地區差異及分布動態演進








)

)

:構建ReAct模式的網頁內容摘要與分析Agent)




與LSTM(長短期記憶網絡)的組合預測方法)

