論文題目:From Multimodal LLMs to Generalist Embodied Agents: Methods and Lessons(從多模式大型語言模型到多面手具身代理:方法和教訓)
會議:CVPR2025
摘要:我們研究了多模態大型語言模型(Multimodal Large Language Models, mllm)處理不同領域的能力,這些領域超出了這些模型通常訓練的傳統語言和視覺任務。具體來說,我們關注的是嵌入式AI、游戲、UI控制和計劃等領域。為此,我們介紹了一個將mllm應用于通用具身代理(GEA)的過程。GEA是一個單一的統一模型,能夠通過多體現動作標記器在這些不同的領域中扎根。GEA的訓練方法是在大型具體化經驗數據集上進行監督學習,并在交互式模擬器中進行在線強化學習。我們將探索開發這種模型所需的數據和算法選擇。我們的研究結果揭示了使用跨領域數據和在線強化學習進行訓練對于構建多面手智能體的重要性。與其他通用模型和特定于基準的方法相比,最終的GEA模型在不同基準上實現了對未見任務的強大泛化性能。
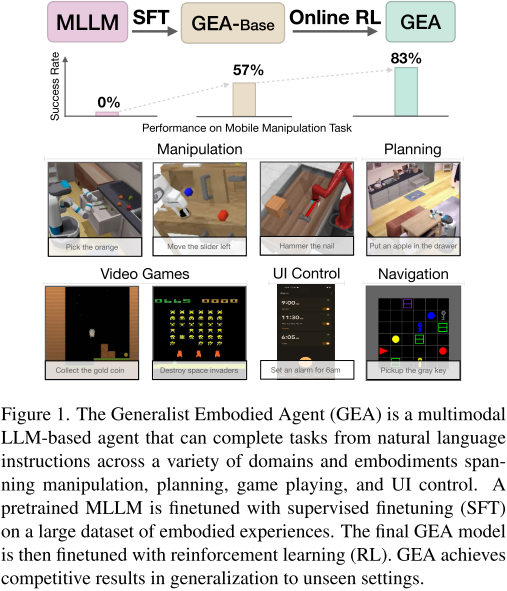
引言:AI智能體的新里程碑
想象一下,一個AI模型能夠同時完成機器人抓取蘋果、玩《太空入侵者》游戲、設置手機鬧鐘,以及規劃復雜的家務任務。這聽起來像科幻小說,但Apple和Georgia Tech的研究團隊通過**Generalist Embodied Agent (GEA)**讓這一愿景成為現實。
這項工作代表了embodied AI領域的重要突破,將多模態大語言模型的能力擴展到了前所未有的應用范圍。
核心挑戰:從語言理解到行動執行
現有方法的局限性
傳統的embodied AI系統通常面臨以下問題:
- 域特化嚴重:大多數系統只能在特定環境中工作,如只做機器人操控或只玩特定游戲
- 動作空間異構:不同任務需要完全不同的控制方式
- 機器人:連續的關節角度控制
- 游戲:離散的按鍵操作
- UI控制:坐標點擊和文本輸入
- 數據稀缺性:專家演示數據有限,且缺乏錯誤恢復示例
GEA的解決方案
研究團隊提出了一個統一的智能體架構,能夠通過單個模型處理多樣化的embodied任務。關鍵創新在于:
- 設計了通用的動作表示方法
- 建立了有效的跨域訓練策略
- 結合了監督學習和強化學習的優勢
技術架構:構建通用智能體的三大支柱
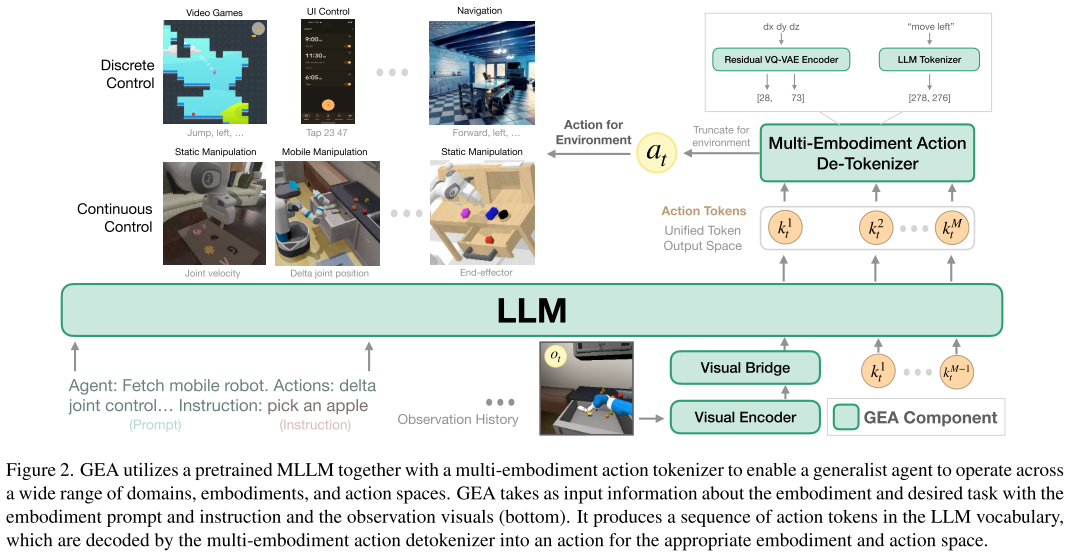
1. 多體驗動作分詞器
核心問題:如何讓一個語言模型理解和輸出各種不同類型的動作?
解決方案:使用Residual VQ-VAE技術將所有動作統一編碼為token序列
連續動作(機器人關節控制) → RVQ編碼 → [k?, k?, ..., k?] → 語言模型token
離散動作("向左移動") → 文本分詞 → ["move", "left"] → 語言模型token
這種設計讓模型能夠:
- 統一處理機器人的7維關節控制和游戲的簡單按鍵操作
- 在推理時根據具體環境截取相應維度的動作
- 保持動作表示的精度和效率
2. 兩階段訓練策略
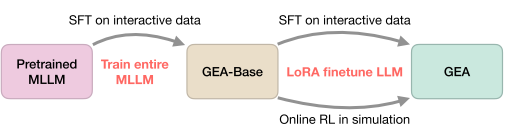
階段一:監督微調(SFT)
- 數據規模:220萬條成功軌跡
- 覆蓋領域:機器人操控、導航、游戲、UI控制、規劃
- 目標:讓模型學會基本的感知-動作映射
階段二:在線強化學習
- 算法:PPO + 持續SFT
- 環境:Habitat Pick、語言重排列、Procgen游戲
- 目標:提升魯棒性和錯誤恢復能力
3. 跨域知識遷移
研究發現,不同域之間存在有益的知識遷移:
- 機器人操控的空間推理能力可以幫助游戲任務
- UI控制的精確定位技能可以提升機器人抓取性能
- 導航任務的路徑規劃思維對復雜操控任務有幫助
實驗結果:全面超越現有方法
操控任務表現
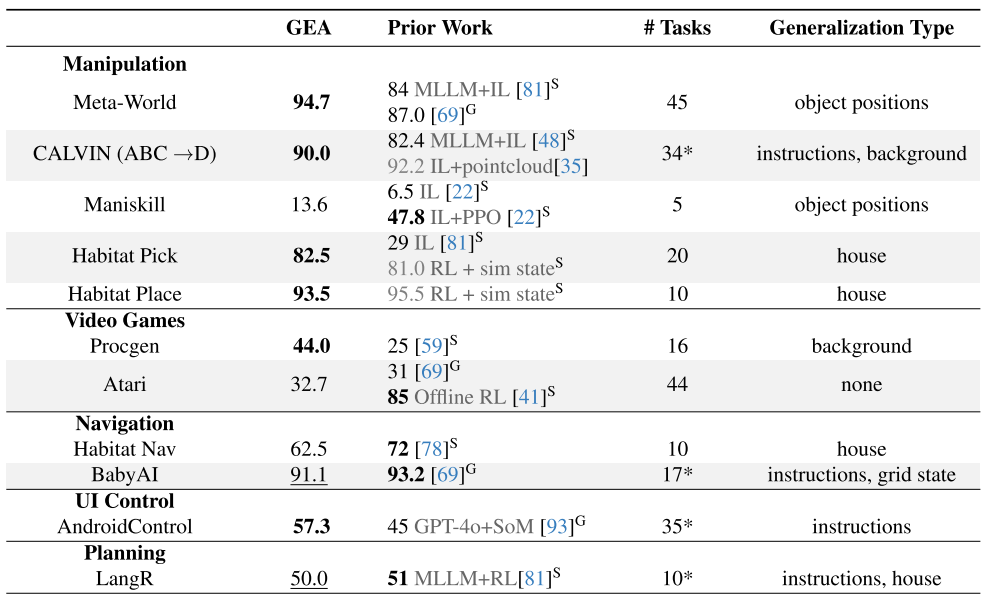
| 基準測試 | GEA性能 | 最佳基線 | 提升幅度 |
|---|---|---|---|
| Meta-World | 94.7% | 87.0% | +7.7% |
| CALVIN | 90.0% | 82.4% | +7.6% |
| Habitat Pick | 82.5% | 81.0% | +1.5% |
視頻游戲表現
- Procgen: 44%專家水平(vs 25%基線)
- Atari: 32.7%專家水平,超越通用基線Gato
其他域表現
- UI控制: 57.3%成功率,超越GPT-4o+專用感知系統
- 導航: 在BabyAI達到91.1%成功率
- 規劃: LangR任務達到50%成功率
關鍵發現:訓練策略的重要啟示
1. 在線RL的決定性作用
實驗對比顯示:
- 僅SFT的GEA-Base:60.5%(Habitat Pick)
- 加入在線RL的GEA:82.5%(+22%提升)
原因分析:
- SFT只學習成功案例,缺乏錯誤恢復能力
- 在線RL能夠探索更多樣的狀態空間
- 交互式學習更符合embodied任務的特性
2. 跨域數據的協同效應
多域聯合訓練 vs 單域訓練的對比:
- 所有測試域都從多域訓練中受益
- 操控任務受益最大(豐富的操控數據相互增強)
- 即使是看似無關的域也存在知識遷移
3. 基礎模型的影響
- 模型規模越大,embodied任務性能越好
- 視覺編碼器的預訓練比語言模型更關鍵
- 不同的基礎MLLM(LLaVA-OneVision vs MM1.5)性能相近
技術細節:實現通用智能體的工程實踐
訓練效率優化
計算資源:
- 階段一:8節點×8 H100 GPU,2天
- 階段二:8節點×8 H100 GPU,1天
- 總計算量:約1億步強化學習
內存優化:
- 使用LoRA微調減少內存占用
- 約束解碼確保動作有效性
- PopArt歸一化處理多環境獎勵差異
數據處理管道
數據收集:多種來源的軌跡數據
- 人類演示:CALVIN、AndroidControl
- RL專家:Habitat、Procgen、Atari
- 運動規劃:Maniskill導航任務
數據格式統一:
- 觀察:RGB圖像序列
- 指令:自然語言描述
- 動作:統一token序列
質量控制:僅使用成功軌跡進行SFT訓練
局限性與未來方向
當前局限
- 性能天花板:某些域(如Maniskill、AndroidControl)仍有較大改進空間
- 零樣本能力有限:無法直接控制完全新的體驗類型
- 計算成本較高:大規模多域訓練需要大量資源
改進方向
- 擴展RL訓練:將在線學習應用到更多域
- 增強泛化能力:研究更好的跨體驗遷移方法
- 提升效率:開發更高效的訓練和推理算法
影響與意義:邁向通用人工智能的重要一步
學術貢獻
- 方法論突破:證明了跨域訓練在embodied AI中的有效性
- 技術創新:多體驗動作分詞器為統一控制提供了新思路
- 實證發現:在線RL對embodied任務的重要性
應用前景
- 家用機器人:一個模型處理清潔、整理、烹飪等多種任務
- 智能助手:同時控制多種設備和應用程序
- 自動化系統:跨平臺的統一控制解決方案
產業影響
- 降低了開發多任務智能體的門檻
- 為robotics即服務(RaaS)提供了技術基礎
- 推動了AI從理解到行動的paradigm shift
結語:通用智能體時代的序幕
GEA的成功表明,通過合適的架構設計和訓練策略,我們可以構建真正的通用智能體。這不僅是技術上的突破,更代表了AI從"專才"向"通才"的重要轉變。
雖然距離真正的通用人工智能還有距離,但GEA為我們展示了一個清晰的發展路徑:
- 統一的表示學習
- 跨域的知識遷移
- 交互式的能力獲取
隨著計算資源的增長和數據的豐富,我們有理由期待更加強大和通用的embodied AI系統。未來的智能體將不再局限于特定任務,而是能夠像人類一樣靈活地適應和學習新的環境與挑戰。




刀具分配問題詳解)


哨兵模式與集群模式有何區別?)






FACE的“段”同Autosar的“層”概念區別探索)




