JVM篇
一.在JVM中,什么是程序計數器?
在 JVM(Java Virtual Machine) 中,程序計數器(Program Counter Register,簡稱 PC 寄存器) 是一塊較小的內存空間,用于記錄 當前線程所執行的字節碼的行號指示器。
1. 程序計數器的作用
- JVM 的字節碼解釋器在工作時,需要依靠程序計數器來 確定下一條需要執行的字節碼指令。
- 程序計數器存儲的內容可以看作是 當前線程所執行的字節碼的地址(行號)。
- 如果執行的是 本地方法(native 方法),那么程序計數器的值為 未定義(Undefined)。
2. 為什么需要程序計數器
- 多線程環境下,JVM 通過 線程切換 來實現并發執行。
- 每條線程都需要記錄自己執行到哪里了,所以 程序計數器是線程私有的,每個線程都有獨立的 PC 寄存器。
- 當線程切換回來時,程序計數器能幫助 JVM 知道該線程應該 從哪條指令繼續執行。
3. 特點
- 占用內存非常小,幾乎可以忽略。
- 是 JVM 規范中唯一一個沒有規定任何 OOM(OutOfMemoryError)情況的內存區域。
- 屬于線程私有(Thread-Private)內存。
二.你能詳細給我介紹一下Java堆嗎?
1. 什么是 Java 堆(作用)
Java 堆是 JVM 管理的 一塊用于存放 Java 對象實例(以及數組)的運行時內存區域。
它是 所有線程共享 的堆內存區(與線程私有的棧、程序計數器不同)。JVM 的垃圾回收器(GC)主要作用于堆:及時回收不再被引用的對象,防止內存泄漏/耗盡。
2. 堆的邏輯劃分(世代/區域)
傳統的“堆”按代(Generation):
-
Young(新生代)
- Eden(伊甸區)
- Survivor0(S0)/ Survivor1(S1)——兩個幸存者區交換使用
新生代主要承載新創建的對象。大多數對象短命,會在這里被回收(Minor GC)。
-
Old / Tenured(老年代 / 年長代)
存放在多次 GC 后仍然存活、被晉升(promote)的對象。對老年代的回收通常更昂貴(Major/Full GC)。
注意:JDK 8 后的 Metaspace(方法區)已經移出堆(替代 PermGen)。Metaspace 存放類元數據,不屬于堆空間。

三.什么是虛擬機棧? 垃圾回收機制是否涉及棧內存? 棧內存是越大越好嗎 ?方法內的局部變量是否線程安全? 什么情況下會導致棧內存溢出?
1) 什么是虛擬機棧
- 虛擬機棧(JVM Stack)是 JVM 為每個 Java 線程創建的私有內存區域。
- 棧由若干**棧幀(StackFrame)**組成:每個方法調用對應一個棧幀,棧幀里保存方法的局部變量表、操作數棧、常量池引用和返回地址等。
- 線程結束時其虛擬機棧被回收。
- 舉例:線程 A 調用
foo()→bar(),會在棧中先后壓入foo、bar的幀,bar返回后其幀彈出。
2) 垃圾回收機制是否涉及棧內存
- GC 主要回收堆(Heap)上的對象,棧上的局部變量本身不被 GC。
- 但是,棧上的引用(局部變量指向的對象引用)會被當作 GC Roots,GC 會從這些根開始標記可達對象,從而間接影響回收。
- 舉例:方法中
Object o = new Object();,只要o仍在棧上可達,那個對象不會被回收;方法返回后o不再可達,對象就可能被回收。
3) 棧內存是越大越好嗎?
-
不是絕對越大越好,有利有弊:
- 增大
-Xss可以支持更深的調用深度或更大的棧幀(例如深遞歸),減少StackOverflowError風險。 - 但每個線程都占用這個棧空間,棧越大可同時支持的線程數越少,一個棧對應一個線程,棧的內存過大,可能導致系統無法創建更多線程或出現 OOM。
- 增大
-
建議:一般使用默認大小,只有在確切需要(深遞歸或特殊 native 調用)時才調大,或在大量線程場景下調小。
4) 方法內的局部變量是否線程安全
-
局部基本類型變量(如
int)和局部引用變量本身是線程私有的,所以它們的存取不會被多個線程同時修改——局部變量本身是線程安全的。 -
但局部變量引用的對象可能是共享的,如果該對象被多個線程訪問則可能不安全。
-
舉例:
void f() {int a = 0; // 線程安全List<String> list = new ArrayList<>(); // 如果不把 list 發布到其他線程,則安全sharedList.add("x"); // 如果 sharedList 是共享的,可能產生線程安全問題 } -
若需要在不同線程間隔離數據,可使用
ThreadLocal<T>。
5) 什么情況下會導致棧內存溢出(StackOverflow)
-
典型原因:無限/過深遞歸(最常見)、極深的調用鏈、或每幀占用太多棧空間(極少見于 Java,但可發生在 JNI/native 代碼中)。
-
另外,創建大量線程(每個線程都占棧)也會因為總棧消耗過大而引發
OutOfMemoryError或無法創建新線程。 -
錯誤表現:
java.lang.StackOverflowError(單線程棧溢出);大量線程耗盡內存可能出現OutOfMemoryError: unable to create new native thread。 -
舉例(遞歸導致):
void recurse() { recurse(); } // 調用會很快拋出 StackOverflowError
四.能不能解釋一下方法區,介紹一下運行時常量池?
1.方法區(Method Area)
定義
方法區是Java虛擬機(JVM)規范中定義的運行時數據區的一部分,用于存儲已被虛擬機加載的類信息、常量、靜態變量等數據。它是線程共享的內存區域,所有線程都可以訪問方法區中的數據。
方法區的特點
- 線程共享:方法區是所有線程共享的內存區域。
- 邏輯內存區:方法區是JVM規范中的一個邏輯概念,具體實現依賴于JVM的實現方式。例如:
- JDK 1.7及之前:方法區通過永久代(PermGen)實現,存儲在Java堆的永久代中。
- JDK 1.8及之后:方法區通過元空間(Metaspace)實現,使用本地內存(Native Memory)存儲類的元數據,與Java堆分離。
- 內存回收:方法區的垃圾回收效率較低,主要回收廢棄的類信息和常量池中的無用常量。
- 動態調整:方法區的大小可以動態調整(如元空間的默認大小不受限制,但可以通過參數配置)。
方法區存儲的內容
- 類信息:
- 類的全限定名(如
java.lang.String)。 - 類的父類、接口、修飾符(如
public、abstract)。 - 字段(屬性)的名稱、類型、修飾符。
- 方法的名稱、參數、返回值、修飾符、字節碼(方法體)。
- 類的全限定名(如
- 運行時常量池:存儲編譯期生成的字面量和符號引用(后文詳細說明)。
- 靜態變量:被
static修飾的類變量。
2.運行時常量池(Runtime Constant Pool)
定義
運行時常量池是方法區的一部分,用于存儲類文件中的常量數據(如字面量和符號引用),并在運行時進行動態解析和擴展。它是每個類或接口的運行時數據,由JVM在加載類時從類文件的常量池解析而來。
運行時常量池的作用
- 存儲字面量和符號引用:
- 字面量:如字符串(
"Hello")、整數(123)、浮點數(3.14)等。 - 符號引用:類、字段、方法的符號名稱(如
java/lang/Object.toString:()Ljava/lang/String;)。
- 字面量:如字符串(
- 支持動態鏈接:符號引用在運行時會被解析為直接引用(如內存地址)。
- 節省內存:相同的數據在常量池中只存儲一份,避免重復。
運行時常量池的存儲內容
- 字面量(Literals):
- 字符串常量(如
"Hello")。 - 數值常量(如
int 42、double 3.14)。 final常量(如static final int MAX = 100;)。
- 字符串常量(如
- 符號引用(Symbolic References):
- 類和接口的全限定名:如
java/lang/String。 - 字段的符號引用:包含字段的類名、字段名、字段描述符(如
Ljava/lang/String;)。 - 方法的符號引用:包含方法的類名、方法名、參數類型和返回值類型(如
main([Ljava/lang/String;)V)。
- 類和接口的全限定名:如
- 動態生成的常量:
- 通過
String.intern()方法添加的字符串。 - 動態語言支持(如
invokeDynamic指令生成的調用點)。
- 通過
運行時常量池的版本差異
- JDK 1.6及之前:
- 運行時常量池和字符串常量池都位于永久代(PermGen)。
- 如果常量池過大,可能導致
OutOfMemoryError: PermGen space。
- JDK 1.7及之后:
- 字符串常量池被移到Java堆中。
- 其他常量池數據(如符號引用)仍保留在方法區(元空間)。
- JDK 1.8及之后:
- 方法區通過**元空間(Metaspace)**實現,使用本地內存,不再受Java堆大小的限制。
- 如果元空間內存不足,會拋出
OutOfMemoryError: Metaspace。
示例:運行時常量池的作用
public class Example {public static void main(String[] args) {String str1 = "Hello"; // 字符串字面量,存儲在運行時常量池String str2 = "Hello"; // 直接引用常量池中的"Hello"String str3 = new String("Hello"); // 堆中新建對象System.out.println(str1 == str2); // true(常量池引用)System.out.println(str1 == str3); // false(堆對象 vs 常量池)}
}
str1和str2:都指向運行時常量池中的"Hello"。str3:通過new創建的新對象,存儲在堆中,與常量池無關。
常見問題
- 為什么需要運行時常量池?
- 節省內存:共享相同的數據(如重復的字符串、類名)。
- 支持動態鏈接:符號引用在運行時解析為直接引用,實現類、方法的動態綁定。
- 運行時常量池會導致內存溢出嗎?
- 在 JDK 1.6 及之前,如果常量池過大,可能導致
PermGen space溢出。 - 在 JDK 1.8 及之后,元空間使用本地內存,默認不限制大小,但仍需合理配置(如
-XX:MaxMetaspaceSize)。
- 在 JDK 1.6 及之前,如果常量池過大,可能導致
總結
- 方法區是JVM的邏輯概念,存儲類信息、常量、靜態變量等,JDK 1.8之后通過元空間實現。
- 運行時常量池是方法區的一部分,存儲編譯期生成的字面量和符號引用,并在運行時動態解析。
- 版本差異:JDK 1.7之后字符串常量池移至堆中,JDK 1.8之后元空間取代永久代,解決了固定內存限制的問題。
五.你聽說過直接內存嗎,解釋一下?
什么是直接內存
- 直接內存 指的是 JVM 通過
Unsafe類 或者 NIO 中的ByteBuffer.allocateDirect()方法,直接向操作系統申請的內存。 - 這塊內存不受 JVM 堆大小參數(如
-Xmx)限制,而是受到 本機物理內存 和-XX:MaxDirectMemorySize參數限制。
為什么要有直接內存
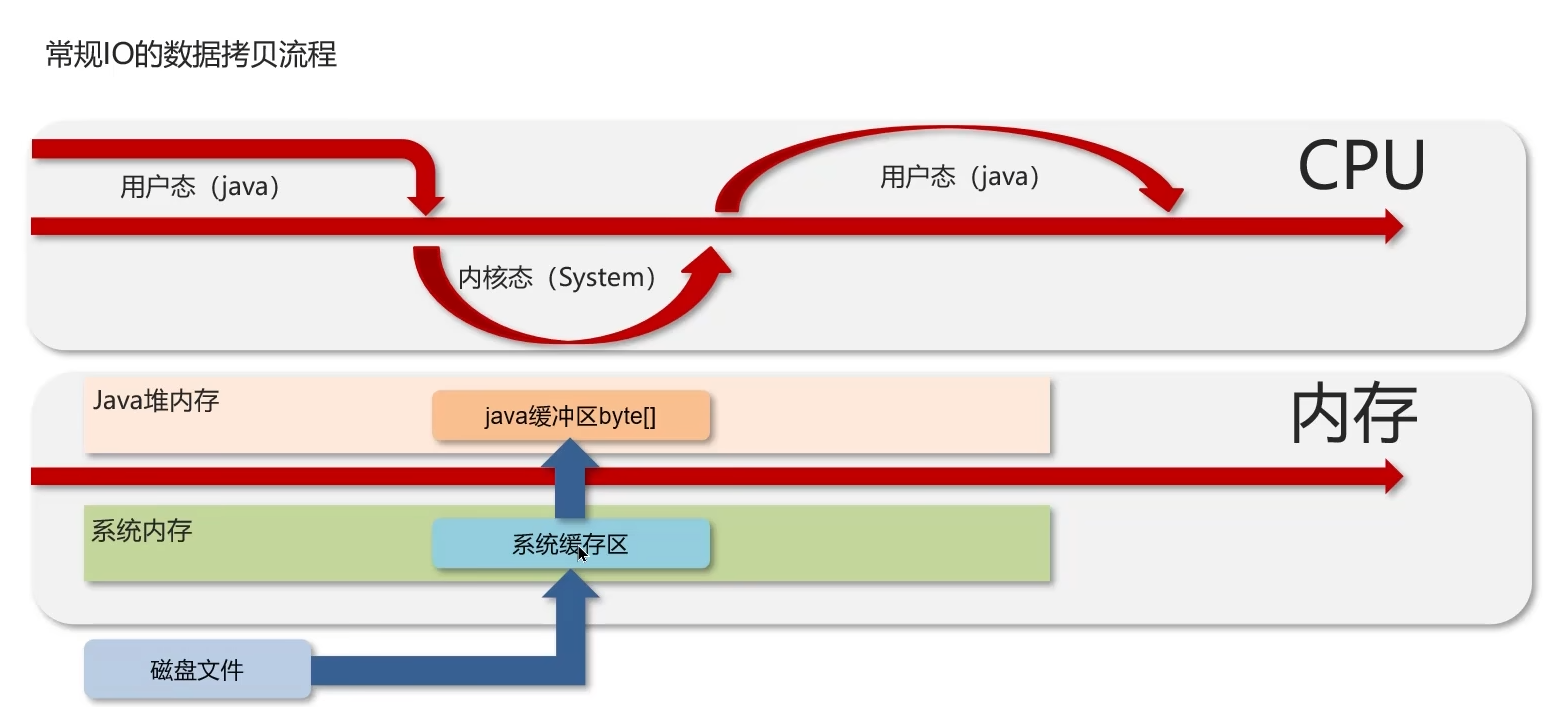
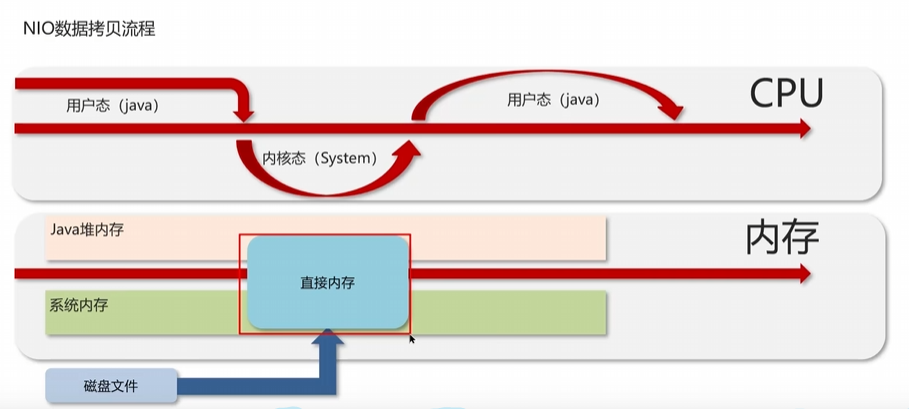
因為傳統 Java 堆內存的讀寫需要 先復制到 JVM 內存,再復制到操作系統內核內存,效率低。
而直接內存避免了這層拷貝:
- I/O 操作(比如網絡傳輸、文件讀寫)可以直接操作這塊內存,減少一次拷貝,提高性能。
典型場景:Java NIO 中的 零拷貝(Zero-Copy)
特點
- 分配和銷毀成本比堆內存高。
- 訪問速度通常比堆內存快,特別是在大數據量 I/O 場景下。
- 可能會導致 內存溢出(OutOfMemoryError: Direct buffer memory),即使堆內存還有空間,因為它不算在
-Xmx里面。
舉例
import java.nio.ByteBuffer;public class DirectMemoryDemo {public static void main(String[] args) {// 分配 100MB 直接內存ByteBuffer buffer = ByteBuffer.allocateDirect(100 * 1024 * 1024);System.out.println("分配了100MB直接內存");}
}
如果運行時不加參數 -XX:MaxDirectMemorySize=200m,但分配超過默認限制,就可能拋出:
Exception in thread "main" java.lang.OutOfMemoryError: Direct buffer memory
六.什么是類加載器,類加載器的種類有哪些?
什么是類加載器(ClassLoader)
- 類加載器的作用:把字節碼文件(.class)加載到 JVM 內存中,并生成對應的 Class 對象。
類加載器的種類
在 JVM 規范里,類加載器分為兩大類:
- 啟動類加載器(Bootstrap ClassLoader)
- 其他類加載器(繼承自 ClassLoader 的加載器)
實際常見的類加載器有:
1. 啟動類加載器(Bootstrap ClassLoader)
- 用 C++ 編寫,屬于 JVM 本地代碼的一部分。
- 主要加載 JDK 核心類庫。
2. 擴展類加載器(Extension ClassLoader)
- 由 Java 實現,父加載器是 Bootstrap。
- 加載 擴展目錄(ext) 下的類(早期 JDK 是
jre/lib/ext,后來 JDK9 之后改為模塊化)。 - 負責加載一些非核心但又是 JDK 提供的擴展類庫。
3. 應用類加載器(Application ClassLoader / System ClassLoader)
- 也叫 系統類加載器。
- 由 Java 實現,父加載器是 擴展類加載器。
- 負責加載 classpath 下的類(我們自己寫的代碼一般都是它加載的)。
4. 自定義類加載器
-
開發者可以繼承
ClassLoader,實現自定義加載邏輯。 -
常見應用場景:
- 熱部署 / 插件機制(如 Tomcat、Spring Boot DevTools)。
- 字節碼加密與解密(防止源碼被反編譯)。
類加載器的層次結構(雙親委派模型)
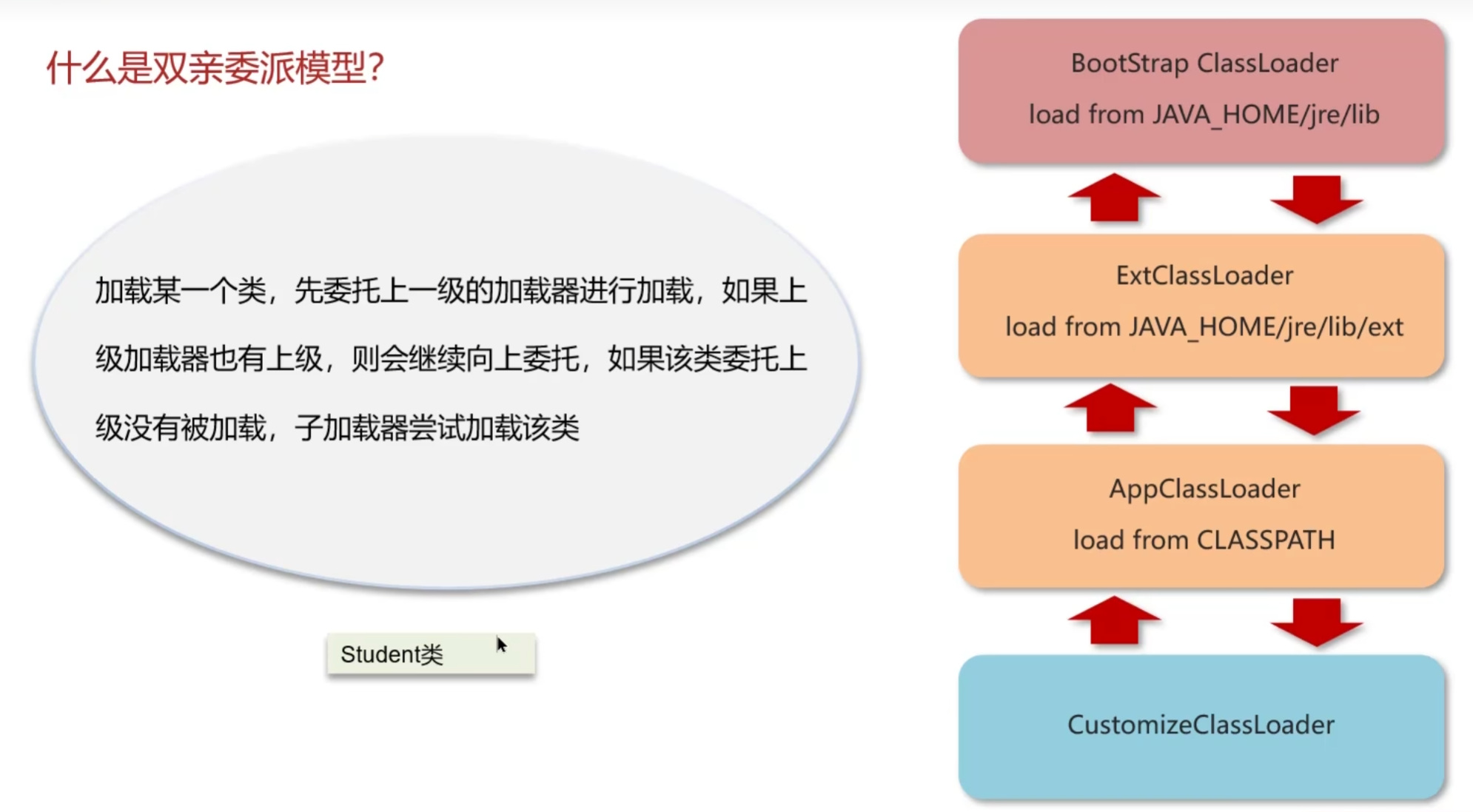
七.什么是雙親委派模型,JVM為什么要采用雙親委派機制?
1.什么是雙親委派模型(Parent Delegation Model)
定義:
在 JVM 中,類加載器在加載類時,并不是自己馬上去嘗試加載,而是把請求交給父類加載器去處理,父類加載器再交給更上層,直到 啟動類加載器。
- 如果父類能完成加載,就直接返回結果。
- 如果父類不能完成加載(即找不到對應的類),再由當前類加載器自己嘗試去加載。
2.雙親委派模型的好處
-
避免類的重復加載
- 保證同一個類只會由一個類加載器加載,避免不同類加載器重復加載相同類導致沖突。
- 例如:
java.lang.String只能由 啟動類加載器 加載,不會被用戶自己寫的類覆蓋。
-
保證核心類庫的安全性
- 如果用戶自己寫了一個
java.lang.String類,放在classpath下。 - 由于雙親委派,應用類加載器在加載
String時,會先交給父加載器,最終由 啟動類加載器 加載真正的String。 - 避免了用戶惡意替換核心類庫。
- 如果用戶自己寫了一個
-
實現了類加載器的層級結構,模塊化清晰
-
每個加載器只關注自己職責范圍內的類:
- Bootstrap → JDK 核心類庫
- Extension → 擴展類庫
- Application → 應用程序類
-
既有分工,又能保證統一性。
-
八. 說一下類加載的執行過程?
📌 JVM 類加載的執行過程
1. 加載(Loading)
-
作用:將類的字節碼文件(
.class)讀入內存,并創建一個Class對象。 -
加載器:由 類加載器(ClassLoader) 完成,使用 雙親委派模型 來定位和加載類。
2. 鏈接(Linking)
分為三步:
-
驗證(Verification)
- 確保字節碼文件格式正確,不會危害 JVM 安全。
-
準備(Preparation)
-
為類的 靜態變量(static 字段) 分配內存,并賦予默認值。
-
注意:這里只賦默認值 0 / null / false,不會執行任何賦值語句。
-
比如:
public static int a = 10;在 準備階段,
a的值是 0,不是 10。
-
-
解析(Resolution)
- 把常量池里的符號引用(字符串形式的類、方法、字段名)替換為 直接引用(內存地址)。
- 比如:
"java/lang/String"→ 變成真正的String.class對象引用。
3. 初始化(Initialization)
-
真正執行類變量的初始化代碼,以及執行 靜態代碼塊。
-
按照源代碼中定義的順序執行。
-
初始化子類前,必須先初始化父類,但 使用父類時,不會觸發子類初始化。
-
比如:
public class Test {static int a = 10; // ①static { a = 20; } // ② }👉 初始化后
a = 20,因為靜態代碼塊在變量賦值之后執行。
? 總結:
類加載過程 = 加載 → 鏈接(驗證、準備、解析) → 初始化,其中初始化階段才會執行靜態變量賦值和靜態代碼塊。
九.在類加載中,準備階段 和 初始化階段 對不同類型變量(普通、static、final)的處理過程是什么?
1. 普通成員變量(非 static)
- 準備階段:不處理(因為普通成員變量屬于對象實例,不屬于類)。
- 初始化階段:在對象實例化時,隨著構造方法一起執行賦值。
public class Demo {int a = 10; // 普通成員變量
}
👉 a 的賦值要等到 new Demo() 時才發生。
2. 靜態變量(static)
- 準備階段:分配內存并賦默認值(
0、false、null)。 - 初始化階段:執行顯式賦值語句、靜態代碼塊,按代碼順序賦值。
public class Demo {static int a = 10; // ① 顯式賦值static { a = 20; } // ② 靜態代碼塊
}
👉 準備階段:a = 0
👉 初始化階段:先執行 ① → a = 10,再執行 ② → a = 20
3. final static 變量
-
情況 1:編譯期常量(基本類型或
String,值在編譯期已確定)- 準備階段:直接賦初始值(不會等到初始化階段)。
- 因為編譯器在編譯時就把值放進了 常量池。
public class Demo {public static final int A = 100;public static final String B = "Hello"; }👉 在 準備階段,
A = 100,B = "Hello" -
情況 2:運行期才能確定的值(如
new對象,方法返回值)- 準備階段:賦默認值(
0/null)。 - 初始化階段:執行賦值操作。
public class Demo {public static final Integer C = Integer.valueOf(10); // 運行時決定 }👉 準備階段:
C = null
👉 初始化階段:C = Integer.valueOf(10) - 準備階段:賦默認值(
4. 普通 final 變量(非靜態)
- 屬于對象實例變量,不在類加載階段處理。
- 必須在構造方法或聲明時賦值。
public class Demo {final int x = 5; // 聲明時賦值final int y; Demo(int y) { // 或者構造方法里賦值this.y = y;}
}
十.對象什么時候能被垃圾器回收?
1. 引用計數法(Reference Counting)
原理
-
給每個對象維護一個 引用計數器:
- 每當有一個地方引用它,計數器 +1。
- 引用失效時,計數器 -1。
-
當計數器 = 0 時,說明對象不可用,可以被回收。
優點
- 實現簡單,效率高。
- 一旦計數為 0 就可以立即回收對象(不用等 GC 掃描)。
缺點
- 無法解決循環引用問題:
兩個對象互相引用,即使外部沒有引用,它們的計數器也不是 0,無法被回收。
舉例
class Node {Node next;
}
public class Test {public static void main(String[] args) {Node a = new Node();Node b = new Node();a.next = b;b.next = a;a = null;b = null; // 外部都斷開了引用// 但 a 和 b 互相引用,計數不為 0 → 無法回收}
}
👉 因為這個問題,Java 沒有采用引用計數法。
2. 可達性分析法(Reachability Analysis)
原理
- JVM 從一組稱為 GC Roots 的對象出發,沿著引用鏈向下搜索。
- 如果一個對象與 GC Roots 沒有任何引用鏈相連,就判定為不可達對象 → 可以被回收。
GC Roots 包括:
- 虛擬機棧中引用的對象(方法參數、局部變量等)
- 方法區中靜態變量引用的對象
- 方法區中常量引用的對象
- 本地方法棧(JNI)引用的對象
GC Roots = JVM 里一切“根源性引用”的集合,比如線程、棧變量、靜態變量、常量、JNI 引用等。
優點
- 可以有效避免循環引用問題。
- 更符合現代編程語言的需求,因此 Java 采用可達性分析來判斷對象是否存活。
示例
class Parent {static Parent p; // 靜態變量(GC Root)int[] arr = new int[1024];
}public class Test {public static void main(String[] args) {Parent obj = new Parent(); // 局部變量 objobj = null; // 斷開 obj// obj 沒有任何 GC Roots 引用 → 可被回收// 但如果 Parent.p = obj; 那么對象就存活}
}
十一.JVM垃圾回收算法有哪些?
JVM 的垃圾回收算法主要有以下幾類,每一種算法在不同的場景下各有優缺點:
1. 標記-清除(Mark-Sweep)
-
過程:
- 從 GC Roots 開始標記所有可達對象。
- 清除未被標記的對象,回收內存。
-
優點:實現簡單。
-
缺點:
- 會產生 內存碎片,不連續的內存影響大對象分配。
-
示例:假設堆內存像一張紙,標記可用的格子后,擦掉不用的內容,但留下了空洞。
2. 復制算法(Copying)
-
過程:
- 把內存分為兩塊(例如 Eden + Survivor0 / Survivor1)。
- 每次只用其中一塊,當垃圾回收時,把存活對象復制到另一塊,清空原來的區域。
-
優點:
- 沒有碎片問題。
- 分配速度快(指針碰撞分配)。
-
缺點:
- 需要 雙倍內存 空間。
-
示例:就像有兩張紙,只寫一張,用完后把重要的內容抄到另一張,再把舊紙扔掉。
3. 標記-整理(Mark-Compact)
-
過程:
- 標記存活對象。
- 將存活對象移動到內存的一端。
- 清理掉邊界外的垃圾對象。
-
優點:解決了內存碎片問題。
-
缺點:移動對象需要額外開銷,效率比復制算法低。
-
示例:像書架整理,把要保留的書一本本挪到左邊,右邊空出來。
? 總結
- 標記-清除:簡單,但有碎片。
- 復制算法:無碎片,速度快,但浪費內存。
- 標記-整理:無碎片,但速度慢。
十二.說一下JVM中的分代回收?
一、JVM 堆的分代結構
JVM 堆通常分為:
-
新生代(Young Generation)
- 包含 Eden 區、Survivor0 (S0)、Survivor1 (S1)。
- 特點:對象朝生夕死,存活率低。
- 默認比例:
Eden : S0 : S1 = 8 : 1 : 1。
-
老年代(Old Generation)
- 存放經過多次 GC 仍存活的對象。
- 特點:對象存活率高,內存大。
-
永久代(PermGen)/ 元空間(Metaspace,Java 8+)
- 存放類元數據(類結構、方法元信息等)。
- JDK8 之后用本地內存實現 Metaspace,不再在堆里。
二、回收過程
1. 新生代回收(Minor GC / Young GC)
-
觸發條件:Eden 區滿。
-
算法:復制算法(Copying)。
-
過程:
- 存活對象從 Eden + 一個 Survivor 區,復制到另一個 Survivor 區。
- 清空 Eden 和用過的 Survivor 區。
- 如果 Survivor 放不下,部分對象會晉升到老年代(稱為 晉升/提升)。
2. 老年代回收(Major GC / Old GC)
- 觸發條件:老年代空間不足。
- 算法:標記-清除(Mark-Sweep)或 標記-整理(Mark-Compact)。
- 特點:回收速度慢,可能會導致應用停頓時間長。
3. 整堆回收(Full GC)
-
觸發條件:
- 老年代空間不足;
- 元空間不足;
- System.gc() 調用;
- 其他 GC 策略觸發。
-
過程:回收新生代 + 老年代 + 元空間。
-
代價:非常昂貴,應盡量避免頻繁 Full GC。
十三.說一下JVM有哪些垃圾和回收器?
一、JVM 垃圾回收的基本原理
- 垃圾回收器是負責回收不再使用的對象的組件。
- JVM 的垃圾回收主要關注 堆內存(Heap) 和 方法區(MetaSpace) 的回收。
- 回收策略基于 分代回收(Generational GC) 和 垃圾收集算法,而不同的垃圾回收器實現了不同的回收策略和算法。
二、JVM 常見的垃圾回收器
1. Serial GC(串行回收器)
-
特點:使用單線程進行垃圾回收,適用于單核 CPU 系統。
-
使用場景:低內存和小型應用。
-
回收過程:
- 新生代使用 復制算法(Copying)。
- 老年代使用 標記-清除 或 標記-整理(Mark-Compact)。
-
啟動方式:
-XX:+UseSerialGC
2. Parallel GC(并行回收器)
-
特點:多線程進行垃圾回收,通過并行回收提高吞吐量,適用于多核 CPU 系統。
-
使用場景:需要高吞吐量的應用。
-
回收過程:
- 新生代使用 復制算法(Copying)。
- 老年代使用 標記-整理(Mark-Compact)。
-
啟動方式:
-XX:+UseParallelGC
3. CMS GC(Concurrent Mark-Sweep, 并發標記-清除回收器)
-
特點:通過并發回收減少停頓時間,適用于低停頓應用。
-
使用場景:要求低延遲的應用。
-
回收過程:
- 新生代使用 復制算法(Copying)。
- 老年代使用 標記-清除(Mark-Sweep)+ 并發清除。
-
啟動方式:
-XX:+UseConcMarkSweepGC
4. G1 GC(Garbage-First Garbage Collector)
-
特點:適合多核 CPU 和大堆內存的環境,目標是實現高效的垃圾回收,同時降低停頓時間。
-
使用場景:適合大內存、高并發、要求低延遲的應用。
-
回收過程:
- G1 會將堆分成多個 Region,每個 Region 由 G1 回收器動態選擇回收。
- 新生代和老年代采用不同的回收策略,G1 會通過預測停頓時間來選擇回收哪些區域。
-
啟動方式:
-XX:+UseG1GC
三、總結
- Serial GC:適用于小型應用,單線程,回收效率較低。
- Parallel GC:適用于多核 CPU,大型應用,追求高吞吐量。
- CMS GC:適用于低停頓、高并發應用,減少停頓時間。
- G1 GC:適合大內存、高并發應用,平衡吞吐量和停頓時間。
十四.請詳細聊一下Java中的G1垃圾分類回收器?
1. G1的核心設計理念
G1的設計目標是通過靈活的分區管理和優先級回收策略,解決傳統垃圾回收器(如CMS)的痛點,例如:
- 內存碎片化:CMS的標記-清除算法可能導致碎片,無法分配大對象。
- 不可預測的停頓時間:CMS和Parallel Scavenge的停頓時間難以控制。
- 全堆回收的開銷:傳統回收器需要對整個堆進行回收,效率低下。
G1的核心思想:
- 分區(Region)管理:將堆劃分為多個大小相等的獨立區域(Region),每個區域可以動態分配給新生代或老年代。
- 增量式回收:每次只回收部分區域(Collection Set),避免全堆回收。
- 可預測的停頓時間:通過啟發式算法和用戶設定的停頓目標(如
-XX:MaxGCPauseMillis),控制GC停頓時間。 - 并發與并行結合:在標記和清理階段充分利用多核CPU資源。
2. G1的內存模型
G1將堆劃分為多個Region(默認大小1MB~32MB,可通過-XX:G1HeapRegionSize調整),每個Region可以屬于以下類型之一:
- Eden Region:存放新創建的對象(屬于新生代)。
- Survivor Region:存放年輕代GC后存活的對象。
- Old Region:存放存活時間較長的對象(屬于老年代)。
- Humongous Region:專門存儲巨型對象(大小超過Region的一半)。
邏輯分代 vs 物理分代
- 傳統分代(如CMS):新生代和老年代是物理上連續的內存區域。
- G1邏輯分代:新生代和老年代是邏輯上的概念,Region可以動態分配到任意分代中。
3. G1的工作原理
G1的回收過程分為四個主要階段,通過增量式回收和優先級列表實現高效垃圾回收:
1. 年輕代回收(Young GC)
- 觸發條件:Eden區填滿時觸發。
- 過程:
- 復制算法:將Eden和Survivor中的存活對象復制到新的Survivor區域。
- 對象晉升:如果Survivor區域不足,部分存活對象晉升到老年代。
- 清理空Region:回收不再使用的Eden和Survivor Region。
2. 并發標記(Concurrent Marking)
- 目標:標記老年代中的垃圾對象。
- 步驟:
- 初始標記(STW):標記從根節點直接引用的對象。
- 并發標記:與用戶線程并發執行,遍歷老年代對象圖。
- 最終標記(STW):處理并發標記期間的剩余任務。
- 篩選回收(Mixed GC):選擇垃圾最多的Region進行回收(混合回收新生代和部分老年代)。
3. 混合回收(Mixed GC)
- 特點:在年輕代回收的基礎上,回收部分老年代Region。
- 優先級策略:基于Region的垃圾比例和回收成本,優先回收垃圾最多的Region(Garbage-First名稱的由來)。
4. 完全GC(Full GC)
- 觸發條件:堆內存不足或G1無法回收足夠空間時觸發。
- 實現方式:使用單線程的標記-整理算法,停頓時間較長,需盡量避免。
4. G1的關鍵特性
| 特性 | 描述 |
|---|---|
| 分區管理 | 堆被劃分為多個Region,靈活分配到不同代,減少內存碎片。 |
| 可預測的停頓時間 | 用戶通過-XX:MaxGCPauseMillis設置目標停頓時間(默認200ms),G1會盡力滿足。 |
| 并發與并行 | 并發標記階段與用戶線程并行運行;并行階段(如Young GC)利用多核CPU加速。 |
| 空間整合 | 使用復制算法回收Region,避免內存碎片(對比CMS的標記-清除)。 |
| 動態調整 | Region的分配和回收策略動態調整,適應不同負載場景。 |
十五.強引用,軟引用,弱引用,虛引用的區別是什么?
1. 強引用(Strong Reference)
- 定義:最常見的引用類型,通過直接賦值(如
Object obj = new Object())創建。 - 回收時機:只要存在強引用指向對象(GC Roots 能到達的對象),垃圾回收器永遠不會回收該對象,即使內存不足。
- 使用場景:
- 普通的業務對象(如業務實體、數據模型等)。
- 需要長期存活的對象(如緩存中的關鍵數據)。
- 示例:
Object strongRef = new Object(); // 強引用 strongRef = null; // 顯式置為null后,對象可被回收 System.gc(); // 建議JVM回收
2. 軟引用(Soft Reference)
- 定義:通過
SoftReference<T>類創建,表示“有用但非必需”的對象。 - 回收時機:
- 在內存充足時,不會被回收。
- 一旦內存不足(OOM)時,會被回收以釋放內存。
- 使用場景:
- 內存敏感的緩存(如圖片緩存、緩存池),在內存不足時自動清理。
- 避免因緩存占用過多內存導致OOM。
- 示例:
Object obj = new Object(); SoftReference<Object> softRef = new SoftReference<>(obj); obj = null; // 移除強引用 // 當內存不足時,softRef.get() 可能返回 null
3. 弱引用(Weak Reference)
- 定義:通過
WeakReference<T>類創建,表示“非必需”的對象。 - 回收時機:
- 下一次垃圾回收時,只要沒有強引用,就會被回收。
- 與內存是否充足無關。
- 使用場景:
- 監聽對象的回收(如監聽某個對象是否被銷毀)。
- 避免內存泄漏(如緩存中臨時對象)。
- 示例:
Object obj = new Object(); WeakReference<Object> weakRef = new WeakReference<>(obj); obj = null; // 移除強引用 // 下一次GC后,weakRef.get() 會返回 null
4. 虛引用(Phantom Reference)
- 定義:通過
PhantomReference<T>類創建,不能通過get()方法獲取對象。 - 回收時機:
- 對象被回收后,虛引用才會被加入引用隊列,由Reference Handler線程執行相關內存的清理操作。
- 使用場景:
- 資源清理(如關閉文件句柄、釋放本地資源)。
- 監控對象何時被回收(需配合
ReferenceQueue使用)。
Reference Handler線程的作用
- Reference Handler線程 是JVM啟動時創建的一個守護線程,其核心職責是:
- 監控對象的回收狀態:當JVM的垃圾回收器(如CMS、G1等)回收對象時,會將對應的引用(軟引用、弱引用、虛引用)加入一個全局的
pending隊列。 - 將引用加入對應的引用隊列:Reference Handler線程會從
pending隊列中取出引用,并根據其注冊的ReferenceQueue將其加入到程序可見的隊列中。 - 觸發后續處理邏輯:程序可以通過輪詢或阻塞方式從引用隊列中取出引用,進而執行資源清理操作(例如關閉文件句柄、釋放本地資源等)。
- 監控對象的回收狀態:當JVM的垃圾回收器(如CMS、G1等)回收對象時,會將對應的引用(軟引用、弱引用、虛引用)加入一個全局的
- 示例:
Object obj = new Object(); ReferenceQueue<Object> queue = new ReferenceQueue<>(); PhantomReference<Object> phantomRef = new PhantomReference<>(obj, queue); obj = null; // 移除強引用 // 調用 System.gc() 后,phantomRef 會被加入 queue
對比總結
| 特性 | 強引用 | 軟引用 | 弱引用 | 虛引用 |
|---|---|---|---|---|
| 回收時機 | 永遠不回收(除非顯式置為 null) | 內存不足時回收 | 下一次GC時回收 | 對象被回收后加入引用隊列 |
| 是否可獲取對象 | ? 通過 get() 獲取 | ? 通過 get() 獲取 | ? 通過 get() 獲取 | ? 無法通過 get() 獲取 |
| 是否需要引用隊列 | ? 不需要 | ? 不需要 | ? 不需要 | ? 必須配合 ReferenceQueue |
| 典型用途 | 普通對象、關鍵數據 | 緩存(內存敏感) | 臨時對象、監聽回收 | 資源清理、對象回收監控 |
十六.JVM調優參數可以在哪設置參數值?
1. 命令行啟動參數
- 適用場景:直接通過命令行啟動Java應用(如
java -jar app.jar)。 - 設置方法:
在啟動命令中添加JVM參數,例如:java -Xms256m -Xmx256m -XX:+UseG1GC -jar app.jar - 參數類型:
- 標準參數(
-X):如-Xms(初始堆大小)、-Xmx(最大堆大小)。 - 非標準參數(
-XX):如-XX:+UseG1GC(啟用G1垃圾回收器)。
- 標準參數(
2. IDE配置(如 IntelliJ IDEA)
- 適用場景:在開發環境中運行或調試Java應用。
- 設置方法:
- 通過運行/調試配置:
- 打開
Run/Debug Configurations(快捷鍵Alt + Shift + F10或菜單Run > Edit Configurations)。 - 在
VM options字段中輸入參數,例如:-Xms256m -Xmx256m -XX:+PrintGCDetails
- 打開
- 全局配置:
- 在
File > Settings > Build, Execution, Deployment > Build Tools > [所選配置]中設置全局的VM options。
- 在
- 通過運行/調試配置:
3. 中間件配置(如 Tomcat)
- 適用場景:部署在 Tomcat、WebLogic、WebSphere 等應用服務器中。
- 設置方法:
- Tomcat:
- 編輯
setenv.sh(Linux/Mac)或setenv.bat(Windows)文件,添加參數到JAVA_OPTS,例如:JAVA_OPTS="-Xms256m -Xmx256m -XX:+UseG1GC" - 如果沒有
setenv.sh,可以手動創建或修改catalina.sh中的JAVA_OPTS。
- 編輯
- Tomcat:
4. 容器環境(如 Docker/Kubernetes)
- 適用場景:在容器化部署中(如 Docker、Kubernetes)。
- 設置方法:
- Docker:
- 在
docker run命令中通過-e設置環境變量JAVA_OPTS,例如:docker run -e JAVA_OPTS="-Xms256m -Xmx256m" my-java-app - 或在 Dockerfile 中指定
ENV JAVA_OPTS。
- 在
- Kubernetes:
- 在 Deployment 或 Pod 的 YAML 文件中通過環境變量設置
JAVA_OPTS,例如:env:- name: JAVA_OPTSvalue: "-Xms256m -Xmx256m -XX:+UseG1GC"
- 在 Deployment 或 Pod 的 YAML 文件中通過環境變量設置
- Docker:
總結對比
| 場景 | 設置位置 | 典型參數示例 |
|---|---|---|
| 命令行啟動 | 啟動命令 | -Xms256m -Xmx256m -XX:+UseG1GC |
| IDE(如 IntelliJ) | 運行/調試配置 | -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError |
| Tomcat | setenv.sh 或 setenv.bat | JAVA_OPTS="-Xms256m -Xmx256m" |
| Docker/Kubernetes | 環境變量 JAVA_OPTS | -Xms256m -XX:+UseContainerSupport |
十七.常見的JVM調優的參數有哪些?
-
-Xms:設置JVM初始堆內存大小(如-Xms2g表示2GB)。 -
-Xmx:設置JVM最大堆內存大小(如-Xmx4g表示4GB)。- 推薦設置:
-Xms和-Xmx設置為相同值,避免堆動態擴容導致的性能抖動。
- 推薦設置:
-
-XX:SurvivorRatio:設置Eden區與Survivor區的比例(如-XX:SurvivorRatio=8表示Eden占年輕代的80%)。 -
G1回收器(Garbage First):
- 啟用參數:
-XX:+UseG1GC - 關鍵參數:
-XX:MaxGCPauseMillis=200:目標最大停頓時間。
- 啟用參數:
-
-XX:MaxTenuringThreshold=N:設置對象晉升到老年代的最大年齡(默認15)。
十八.說一下JVM的調優工具?
一、命令行工具(輕量級,適合線上快速排查)
-
jps(Java Virtual Machine Process Status Tool)
- 查看當前系統上運行的所有 Java 進程及其
pid。
- 查看當前系統上運行的所有 Java 進程及其
-
jstat(JVM Statistics Monitoring Tool)
-
監控 類加載、垃圾回收、內存、JIT 編譯 等信息。
-
示例:
jstat -gc <pid> 1000每 1s 打印一次 GC 情況。
-
-
jmap(Memory Map Tool)
-
查看堆內存使用情況,導出堆轉儲(heap dump)。
-
示例:
jmap -heap <pid> jmap -dump:live,format=b,file=heap.hprof <pid>
-
-
jhat(JVM Heap Analysis Tool)
- 分析
jmap生成的 heap dump 文件。
- 分析
-
jstack(Stack Trace Tool)
-
打印指定進程的線程快照,定位 死鎖、死循環、線程阻塞 問題。
-
示例:
jstack <pid> > threadDump.txt
-
二、圖形化工具(直觀,適合長期監控和分析)
-
JConsole
- JDK 自帶,基于 JMX,實時監控內存、線程、類加載、MBean 等。
- 缺點:性能一般,功能偏簡單。
-
VisualVM
- 功能強大的分析工具,可以監控 CPU、內存、線程、GC,還能分析 heap dump。
- 可安裝插件(如 BTrace)增強功能。
- 推薦作為調優首選工具。
十九.JVM內存泄漏的排查思路有哪些?
1?? 導出內存快照(Heap Dump)
當懷疑內存泄漏(Heap 使用持續上漲,Full GC 頻繁且效果不明顯)時,可以先用 jmap 導出內存快照:
# 導出堆快照文件(hprof 格式)
jmap -dump:live,format=b,file=heap.hprof <pid>
live:只導出存活對象(減少無效數據)file=heap.hprof:生成的快照文件<pid>:Java 進程號,可以通過jps查看
?? 注意:jmap dump 會造成 Stop The World,生產環境需要謹慎操作,最好在壓力低時執行。
2?? 使用 VisualVM 加載快照
打開 VisualVM → File → Load → 選擇剛剛生成的 heap.hprof 文件,進入內存分析界面。
VisualVM 提供幾個關鍵視角:
(1)Classes 視角
-
按類展示實例數量和占用內存大小。
-
排查思路:
- 看哪些類的實例數量異常大(比如
HashMap$Node、byte[]、String等)。 - 判斷是否符合業務預期(例如緩存對象是否被回收)。
- 看哪些類的實例數量異常大(比如
(2)Instances 視角
-
可以點進某個類,查看對象實例。
-
排查思路:
- 查看對象的生命周期是否合理。
- 比如某個 Session 對象明明用戶退出后應該被銷毀,但還存活在內存中。
(3)References 視角(引用鏈分析)
-
查看某個對象的 引用路徑(Reference Chain)。
-
排查思路:
- 找出 GC Roots → 對象的保留鏈。
- 如果對象本應釋放,卻因為被某個 靜態集合、緩存、ThreadLocal 引用而無法回收,就說明有內存泄漏。
3?? 常見內存泄漏場景(結合 VisualVM 分析)
-
靜態集合持有對象
- 例:
static List或Map沒有清理,導致對象一直被引用。 - 在 VisualVM 的 Reference Chain 中,可以看到對象被某個
static字段強引用。
- 例:
-
緩存未設置過期策略
- 使用
HashMap或ConcurrentHashMap緩存,但沒清理過期數據。 - 在 VisualVM 中看到大量緩存對象,引用路徑來自緩存類。
- 使用
-
Listener / Callback 未釋放
- 注冊的監聽器沒 remove,導致被引用。
- 在 VisualVM 中,實例的引用路徑顯示來源是某個 listener 列表。
-
ThreadLocal 泄漏
- ThreadLocal 使用不當(沒有調用
remove()),導致 value 不能被回收。 - 在快照中可看到
ThreadLocalMap.Entry引用了大量對象。
- ThreadLocal 使用不當(沒有調用
-
數據庫連接 / IO 資源未關閉
- 在快照中可能會看到大量的
Socket、FileInputStream對象。
- 在快照中可能會看到大量的
二十.CPU飆高的排查方案和思路是什么?
假設你發現某個 Java 進程 CPU 很高,你想找出是哪個線程導致的:
? 步驟 1:用 top -Hp <pid> 找出高 CPU 的線程 ID(十進制)
top -Hp 12345
輸出中看到某個線程 PID 是 12346,占用 98% CPU。
? 步驟 2:將線程 ID 轉為 16 進制
printf "%x\n" 12346
# 輸出:303a
? 步驟 3:用 jstack + grep 查找該線程的堆棧
jstack 12345 | grep -A 30 303a # 查看該線程的調用棧
注意:我們搜索的是
303a(16進制),因為jstack中的nid是 16進制格式。
? 輸出示例:
"main" #1 prio=5 os_prio=0 tid=0x00007f8c8000a000 nid=0x303a runnable [0x00007f8c8556d000]java.lang.Thread.State: RUNNABLEat com.example.Calculator.compute(Calculator.java:45)at com.example.Service.handleRequest(Service.java:30)at com.example.ApiController.process(ApiController.java:20)at com.example.Main.main(Main.java:10)
這就定位到了:是 main 線程在執行 compute() 方法,可能是一個死循環或密集計算,導致 CPU 占用過高。
🔍 關鍵概念解釋
| 名稱 | 說明 |
|---|---|
pid | Java 進程的進程 ID(Process ID) |
tid | Java 線程對象 ID(java.lang.Thread 的 ID,jstack 中 tid=...) |
nid | Native Thread ID,操作系統線程 ID,16進制,jstack 中 nid=0xabc |
os_prio | 操作系統線程優先級 |
runnable / TIMED_WAITING / BLOCKED | 線程狀態,反映當前線程在做什么 |
采用量子相位估計(QPE)方法,增強量子神經網絡訓練)




-緩存菜品和緩存套餐功能-記錄實戰教程、問題的解決方法以及完整代碼)







)





