點擊 “AladdinEdu,同學們用得起的【H卡】算力平臺”,H卡級別算力,80G大顯存,按量計費,靈活彈性,頂級配置,學生更享專屬優惠。
引言:AI偏見——看不見的技術債務
2018年,亞馬遜不得不廢棄一套用于簡歷篩選的AI系統,因為它系統性歧視女性求職者。該系統通過分析十年間的招聘數據發現,男性求職者更受歡迎,于是學會了自動降低包含"女子俱樂部"、"女子學院"等詞匯的簡歷評分。
這類事件揭示了一個嚴峻現實:AI模型會學習并放大人類社會的偏見。隨著AI系統在招聘、信貸、司法等高風險領域的廣泛應用,模型偏見已從技術問題演變為社會責任和商業風險問題。
本文將深入探討AI偏見的檢測與緩解技術,提供從理論到實踐的完整解決方案,幫助開發者構建更加公平、負責任的AI系統。
一、偏見類型與公平性定義
1.1 偏見的主要類型
AI系統中的偏見主要來源于三個方面:
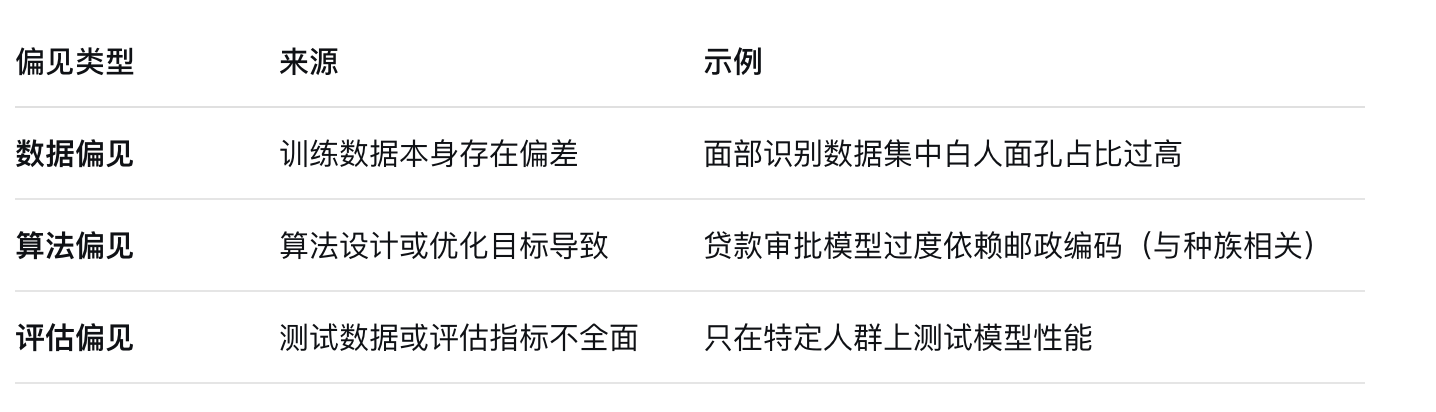
1.2 公平性的數學定義
不同的公平性定義對應不同的技術方案和倫理立場:
# 公平性定義實現示例
import numpy as np
from sklearn.metrics import confusion_matrixdef statistical_parity(y_pred, sensitive_attr):"""統計平價:預測結果在不同群體中分布相似P(?=1|A=0) = P(?=1|A=1)"""group_0 = y_pred[sensitive_attr == 0]group_1 = y_pred[sensitive_attr == 1]return abs(group_0.mean() - group_1.mean())def equal_opportunity(y_true, y_pred, sensitive_attr):"""均等機會:真正例率在不同群體中相等P(?=1|Y=1,A=0) = P(?=1|Y=1,A=1)"""tn_0, fp_0, fn_0, tp_0 = confusion_matrix(y_true[sensitive_attr == 0], y_pred[sensitive_attr == 0]).ravel()tn_1, fp_1, fn_1, tp_1 = confusion_matrix(y_true[sensitive_attr == 1], y_pred[sensitive_attr == 1]).ravel()tpr_0 = tp_0 / (tp_0 + fn_0) if (tp_0 + fn_0) > 0 else 0tpr_1 = tp_1 / (tp_1 + fn_1) if (tp_1 + fn_1) > 0 else 0return abs(tpr_0 - tpr_1)def predictive_equality(y_true, y_pred, sensitive_attr):"""預測平等:假正例率在不同群體中相等P(?=1|Y=0,A=0) = P(?=1|Y=0,A=1)"""tn_0, fp_0, fn_0, tp_0 = confusion_matrix(y_true[sensitive_attr == 0], y_pred[sensitive_attr == 0]).ravel()tn_1, fp_1, fn_1, tp_1 = confusion_matrix(y_true[sensitive_attr == 1], y_pred[sensitive_attr == 1]).ravel()fpr_0 = fp_0 / (fp_0 + tn_0) if (fp_0 + tn_0) > 0 else 0fpr_1 = fp_1 / (fp_1 + tn_1) if (fp_1 + tn_1) > 0 else 0return abs(fpr_0 - fpr_1)
二、偏見檢測與評估框架
2.1 全面評估指標系統
構建完整的偏見評估需要多維度指標:
class BiasAuditFramework:"""AI系統偏見審計框架"""def __init__(self, y_true, y_pred, sensitive_attr):self.y_true = y_trueself.y_pred = y_predself.sensitive_attr = sensitive_attrself.groups = np.unique(sensitive_attr)def calculate_all_metrics(self):"""計算所有偏見評估指標"""metrics = {}# 基礎性能指標metrics['accuracy'] = self._calculate_group_accuracy()metrics['precision'] = self._calculate_group_precision()metrics['recall'] = self._calculate_group_recall()metrics['f1_score'] = self._calculate_group_f1()# 公平性指標metrics['statistical_parity'] = statistical_parity(self.y_pred, self.sensitive_attr)metrics['equal_opportunity'] = equal_opportunity(self.y_true, self.y_pred, self.sensitive_attr)metrics['predictive_equality'] = predictive_equality(self.y_true, self.y_pred, self.sensitive_attr)# 高級指標metrics['disparate_impact'] = self._calculate_disparate_impact()metrics['theil_index'] = self._calculate_theil_index()return metricsdef _calculate_group_accuracy(self):"""計算各群體準確率"""accuracy_dict = {}for group in self.groups:mask = self.sensitive_attr == groupcorrect = (self.y_pred[mask] == self.y_true[mask]).mean()accuracy_dict[f'group_{group}'] = correctreturn accuracy_dictdef _calculate_disparate_impact(self):"""計算差異影響指數4/5規則:小于0.8或大于1.25可能存在偏見"""group_0 = self.y_pred[self.sensitive_attr == 0]group_1 = self.y_pred[self.sensitive_attr == 1]positive_rate_0 = group_0.mean()positive_rate_1 = group_1.mean()# 避免除零錯誤if min(positive_rate_0, positive_rate_1) > 0:return min(positive_rate_0, positive_rate_1) / max(positive_rate_0, positive_rate_1)return 0def _calculate_theil_index(self):"""計算泰爾指數(不平等程度度量)"""# 實現泰爾指數計算passdef generate_audit_report(self):"""生成詳細偏見審計報告"""metrics = self.calculate_all_metrics()report = """AI系統偏見審計報告===================性能差異分析:"""for metric_name, metric_value in metrics.items():if isinstance(metric_value, dict):report += f"\n{metric_name}:\n"for group, value in metric_value.items():report += f" {group}: {value:.4f}\n"else:report += f"\n{metric_name}: {metric_value:.4f}"# 添加偏見檢測結果report += "\n\n偏見檢測結果:\n"if metrics['disparate_impact'] < 0.8:report += "?? 檢測到潛在偏見:差異影響指數 < 0.8\n"if metrics['statistical_parity'] > 0.1:report += "?? 檢測到潛在偏見:統計差異 > 0.1\n"return report# 使用示例
# audit = BiasAuditFramework(y_true, y_pred, sensitive_attributes)
# report = audit.generate_audit_report()
# print(report)
2.2 可視化分析工具
可視化是理解偏見模式的重要手段:
import matplotlib.pyplot as plt
import seaborn as snsdef plot_fairness_metrics(metrics_dict, model_names):"""繪制多個模型的公平性指標對比"""fig, axes = plt.subplots(2, 2, figsize=(15, 12))# 統計差異對比statistical_parities = [m['statistical_parity'] for m in metrics_dict]axes[0, 0].bar(model_names, statistical_parities)axes[0, 0].set_title('Statistical Parity Difference')axes[0, 0].set_ylabel('Difference')# 均等機會對比equal_opportunities = [m['equal_opportunity'] for m in metrics_dict]axes[0, 1].bar(model_names, equal_opportunities)axes[0, 1].set_title('Equal Opportunity Difference')axes[0, 1].set_ylabel('Difference')# 差異影響指數對比disparate_impacts = [m['disparate_impact'] for m in metrics_dict]axes[1, 0].bar(model_names, disparate_impacts)axes[1, 0].set_title('Disparate Impact Ratio')axes[1, 0].set_ylabel('Ratio')axes[1, 0].axhline(y=0.8, color='r', linestyle='--', label='4/5 threshold')# 準確率對比accuracies = [list(m['accuracy'].values()) for m in metrics_dict]x = np.arange(len(model_names))width = 0.35for i, model_acc in enumerate(accuracies):axes[1, 1].bar(x[i] - width/2, model_acc[0], width, label='Group 0')axes[1, 1].bar(x[i] + width/2, model_acc[1], width, label='Group 1')axes[1, 1].set_title('Accuracy by Group')axes[1, 1].set_ylabel('Accuracy')axes[1, 1].set_xticks(x)axes[1, 1].set_xticklabels(model_names)axes[1, 1].legend()plt.tight_layout()plt.show()def plot_confidence_distribution(y_true, y_pred, sensitive_attr, model_name):"""繪制不同群體的置信度分布"""groups = np.unique(sensitive_attr)plt.figure(figsize=(10, 6))for group in groups:mask = sensitive_attr == groupgroup_probs = y_pred[mask] # 假設y_pred是概率值sns.kdeplot(group_probs, label=f'Group {group}', fill=True)plt.title(f'Confidence Distribution - {model_name}')plt.xlabel('Prediction Confidence')plt.ylabel('Density')plt.legend()plt.show()
三、偏見緩解技術實戰
3.1 預處理方法:數據重加權
from sklearn.utils import class_weightclass DataReweighting:"""數據重加權偏見緩解"""def __init__(self, sensitive_attr, target_attr):self.sensitive_attr = sensitive_attrself.target_attr = target_attrself.weights = Nonedef calculate_fairness_weights(self):"""計算公平性權重"""# 交叉頻數分析cross_tab = pd.crosstab(self.sensitive_attr, self.target_attr)# 計算理想分布(每個群體-類別組合的期望比例)ideal_distribution = cross_tab.sum(axis=1) / len(self.sensitive_attr)# 計算權重(反比于實際分布)weights = {}for sens_group in cross_tab.index:for target_class in cross_tab.columns:actual_prob = cross_tab.loc[sens_group, target_class] / cross_tab.sum().sum()ideal_prob = ideal_distribution[sens_group] * (cross_tab[target_class].sum() / cross_tab.sum().sum())if actual_prob > 0:weights[(sens_group, target_class)] = ideal_prob / actual_probelse:weights[(sens_group, target_class)] = 0self.weights = weightsreturn weightsdef apply_weights_to_dataset(self, X, sensitive_attr, target_attr):"""應用權重到數據集"""sample_weights = np.ones(len(X))for i, (sens, target) in enumerate(zip(sensitive_attr, target_attr)):sample_weights[i] = self.weights.get((sens, target), 1.0)return sample_weights# 使用示例
# reweighter = DataReweighting(sensitive_attr, y_train)
# weights = reweighter.calculate_fairness_weights()
# sample_weights = reweighter.apply_weights_to_dataset(X_train, sensitive_attr, y_train)
# model.fit(X_train, y_train, sample_weight=sample_weights)
3.2 處理中方法:對抗學習去偏
import torch
import torch.nn as nnclass AdversarialDebiasing(nn.Module):"""對抗學習去偏模型"""def __init__(self, main_model, adversary_model, lambda_val=0.1):super().__init__()self.main_model = main_modelself.adversary_model = adversary_modelself.lambda_val = lambda_valdef forward(self, x, sensitive_attr):# 主任務預測main_output = self.main_model(x)# 對抗預測(嘗試從主任務輸出預測敏感屬性)adversary_output = self.adversary_model(main_output.detach())return main_output, adversary_outputdef compute_loss(self, main_output, adversary_output, y_true, sensitive_attr):# 主任務損失main_loss = nn.CrossEntropyLoss()(main_output, y_true)# 對抗損失(我們希望 adversary 無法預測敏感屬性)adversary_loss = nn.CrossEntropyLoss()(adversary_output, sensitive_attr)# 總損失 = 主任務損失 - λ * 對抗損失total_loss = main_loss - self.lambda_val * adversary_lossreturn total_loss, main_loss, adversary_loss# 對抗訓練循環示例
def adversarial_training(model, dataloader, num_epochs=50):"""對抗訓練循環"""optimizer_main = torch.optim.Adam(model.main_model.parameters())optimizer_adversary = torch.optim.Adam(model.adversary_model.parameters())for epoch in range(num_epochs):for batch_x, batch_y, batch_sensitive in dataloader:# 訓練對抗器model.adversary_model.train()model.main_model.eval()main_output = model.main_model(batch_x)adversary_output = model.adversary_model(main_output.detach())adversary_loss = nn.CrossEntropyLoss()(adversary_output, batch_sensitive)optimizer_adversary.zero_grad()adversary_loss.backward()optimizer_adversary.step()# 訓練主模型(同時優化主任務和欺騙對抗器)model.adversary_model.eval()model.main_model.train()main_output, adversary_output = model(batch_x, batch_sensitive)total_loss, main_loss, adversary_loss = model.compute_loss(main_output, adversary_output, batch_y, batch_sensitive)optimizer_main.zero_grad()total_loss.backward()optimizer_main.step()
3.3 后處理方法:閾值調整
class ThresholdOptimizer:"""通過閾值調整實現公平性"""def __init__(self, y_true, y_score, sensitive_attr):self.y_true = y_trueself.y_score = y_scoreself.sensitive_attr = sensitive_attrself.groups = np.unique(sensitive_attr)def find_fair_thresholds(self, fairness_metric='equal_opportunity', tolerance=0.05):"""為不同群體尋找最優閾值"""best_thresholds = {}fairness_values = {}for group in self.groups:mask = self.sensitive_attr == groupgroup_y_true = self.y_true[mask]group_y_score = self.y_score[mask]# 網格搜索最優閾值thresholds = np.linspace(0, 1, 100)best_fairness = float('inf')best_threshold = 0.5for threshold in thresholds:y_pred = (group_y_score >= threshold).astype(int)current_fairness = self._calculate_fairness(group_y_true, y_pred, fairness_metric)if current_fairness < best_fairness:best_fairness = current_fairnessbest_threshold = thresholdbest_thresholds[group] = best_thresholdfairness_values[group] = best_fairnessreturn best_thresholds, fairness_valuesdef _calculate_fairness(self, y_true, y_pred, metric_name):"""計算指定公平性指標"""if metric_name == 'statistical_parity':return abs(y_pred.mean() - self.y_pred_overall.mean())elif metric_name == 'equal_opportunity':return equal_opportunity(y_true, y_pred, np.ones_like(y_true))else:raise ValueError(f"Unknown metric: {metric_name}")def apply_fair_thresholds(self, y_score, sensitive_attr):"""應用公平閾值進行預測"""y_pred = np.zeros_like(y_score)for group in self.groups:mask = sensitive_attr == groupgroup_scores = y_score[mask]threshold = self.best_thresholds[group]y_pred[mask] = (group_scores >= threshold).astype(int)return y_pred# 使用示例
# optimizer = ThresholdOptimizer(y_val_true, y_val_score, val_sensitive)
# thresholds, fairness = optimizer.find_fair_thresholds(tolerance=0.05)
# fair_predictions = optimizer.apply_fair_thresholds(test_score, test_sensitive)
四、完整偏見審計與緩解流程
4.1 端到端偏見處理流程
class EndToEndBiasMitigation:"""端到端偏見處理流程"""def __init__(self, model, X, y, sensitive_attr):self.model = modelself.X = Xself.y = yself.sensitive_attr = sensitive_attr# 數據分割self.X_train, self.X_test, self.y_train, self.y_test, self.s_train, self.s_test = \self._split_data_with_sensitive(X, y, sensitive_attr)def _split_data_with_sensitive(self, X, y, sensitive_attr, test_size=0.3):"""保持敏感屬性分布的數據分割"""from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test, s_train, s_test = train_test_split(X, y, sensitive_attr, test_size=test_size, stratify=y, random_state=42)return X_train, X_test, y_train, y_test, s_train, s_testdef run_complete_pipeline(self):"""運行完整偏見處理流程"""print("1. 初始偏見檢測...")initial_metrics = self._evaluate_model(self.model, self.X_test, self.y_test, self.s_test)print("2. 應用數據重加權...")reweighted_model = self._apply_reweighting()reweighted_metrics = self._evaluate_model(reweighted_model, self.X_test, self.y_test, self.s_test)print("3. 應用對抗學習...")adversarial_model = self._apply_adversarial_learning()adversarial_metrics = self._evaluate_model(adversarial_model, self.X_test, self.y_test, self.s_test)print("4. 應用閾值調整...")final_metrics = self._apply_threshold_adjustment(adversarial_model)# 生成對比報告comparison = {'initial': initial_metrics,'reweighted': reweighted_metrics,'adversarial': adversarial_metrics,'final': final_metrics}return comparisondef generate_comprehensive_report(self, comparison_results):"""生成綜合報告"""report = """偏見緩解效果綜合報告===================各階段公平性指標對比:"""metrics_to_display = ['statistical_parity', 'equal_opportunity', 'disparate_impact']for metric in metrics_to_display:report += f"\n{metric}:\n"for stage, results in comparison_results.items():value = results[metric]if isinstance(value, dict):value = sum(value.values()) / len(value) # 簡化顯示report += f" {stage}: {value:.4f}\n"# 計算改善程度initial_fairness = comparison_results['initial']['statistical_parity']final_fairness = comparison_results['final']['statistical_parity']improvement = (initial_fairness - final_fairness) / initial_fairness * 100report += f"\n總體改善: {improvement:.1f}% 的偏見減少\n"return report# 使用示例
# pipeline = EndToEndBiasMitigation(model, X, y, sensitive_attr)
# results = pipeline.run_complete_pipeline()
# report = pipeline.generate_comprehensive_report(results)
# print(report)
五、實踐建議與最佳實踐
5.1 構建負責任AI系統的原則
- 多元化數據收集:確保訓練數據覆蓋所有相關群體
- 透明化文檔:記錄數據來源、標注過程和模型限制
- 持續監控:在生產環境中持續監控模型公平性
- 多方參與:包括領域專家、受影響群體代表在開發過程中
5.2 組織層面的實施框架
class OrganizationalBiasFramework:"""組織級偏見治理框架"""def __init__(self):self.policies = {}self.audit_logs = []self.mitigation_strategies = {}def define_fairness_policy(self, policy_name, metrics, thresholds):"""定義公平性政策"""self.policies[policy_name] = {'metrics': metrics,'thresholds': thresholds,'created_at': datetime.now()}def conduct_audit(self, model, dataset, policy_name):"""執行偏見審計"""policy = self.policies[policy_name]audit_result = {'timestamp': datetime.now(),'policy': policy_name,'results': {},'compliance': True}# 計算所有指標for metric in policy['metrics']:value = calculate_metric(metric, model, dataset)audit_result['results'][metric] = value# 檢查是否符合閾值要求threshold = policy['thresholds'][metric]if value > threshold:audit_result['compliance'] = Falseself.audit_logs.append(audit_result)return audit_resultdef implement_mitigation(self, strategy_name, technique, parameters):"""實施偏見緩解策略"""self.mitigation_strategies[strategy_name] = {'technique': technique,'parameters': parameters,'implemented_at': datetime.now(),'effectiveness': None}def generate_compliance_report(self):"""生成合規性報告"""compliant_audits = [a for a in self.audit_logs if a['compliance']]compliance_rate = len(compliant_audits) / len(self.audit_logs) if self.audit_logs else 0report = f"""組織AI公平性合規報告生成時間: {datetime.now()}==============================總審計次數: {len(self.audit_logs)}合規次數: {len(compliant_audits)}合規率: {compliance_rate:.1%}最近審計結果:"""for audit in self.audit_logs[-5:]: # 顯示最近5次審計report += f"\n{audit['timestamp']}: {audit['policy']} - {'合規' if audit['compliance'] else '不合規'}"return report
結論:邁向公平可靠的AI未來
AI偏見問題不能僅靠技術解決,但技術是解決方案的重要組成部分。通過系統性的偏見檢測和緩解策略,我們可以顯著提高AI系統的公平性和可靠性。
關鍵要點總結:
- 檢測先行:在使用任何緩解技術前,必須全面評估模型偏見
- 多層次策略:結合預處理、處理中和后處理方法
- 持續監控:公平性不是一次性的目標,而是持續的過程
- 組織承諾:需要技術、流程和文化的共同支持
未來發展方向:
- 自動化偏見檢測:開發更智能的自動偏見檢測工具
- 可解釋性增強:更好地理解偏見產生的原因和機制
- 標準化評估:建立行業統一的偏見評估標準和基準
- 跨文化公平性:解決全球化AI系統中的跨文化偏見問題
通過采用本文介紹的技術和方法,開發者和組織可以構建更加公平、可靠的AI系統,為推動負責任AI發展做出貢獻。



)













切換工作界面為淺灰色的方法)

