
【導讀】
單目 3D 目標檢測是計算機視覺領域的熱門研究方向,但如何在真實復雜場景中識別“未見過”的物體,一直是個難題。本文介紹的 3D-MOOD 框架,首次提出端到端的開集單目 3D 檢測方案,并在多個數據集上刷新了 SOTA。
目錄
一、研究背景
二、3D-MOOD 方法
規范圖像空間 (Canonical Image Space)
幾何感知的3D查詢生成?(Geometry-Aware 3D Query Generation)
三、實驗與結果
開集實驗
跨領域實驗
消融實驗
總結
近年來,三維目標檢測在自動駕駛、機器人和 AR/VR 等應用中扮演著越來越重要的角色。相比多攝像頭或激光雷達,單目方案更具成本優勢和部署靈活性,因此備受關注。然而,現有方法普遍基于“閉集設定”——訓練和測試數據共享相同的類別與場景。這一假設在現實中顯然過于理想化。試想,一個自動駕駛系統若只能識別訓練中見過的車輛和行人,而無法應對新環境中的未知物體,那它的實用性必然大打折扣。
這正是 3D-MOOD 想要解決的問題。研究者提出了一種全新的端到端框架,能夠在保持單目檢測優勢的同時,突破閉集限制,將 二維檢測結果提升至三維空間,并通過幾何先驗與規范化設計,使模型能夠在完全陌生的場景和類別中依然穩健工作。
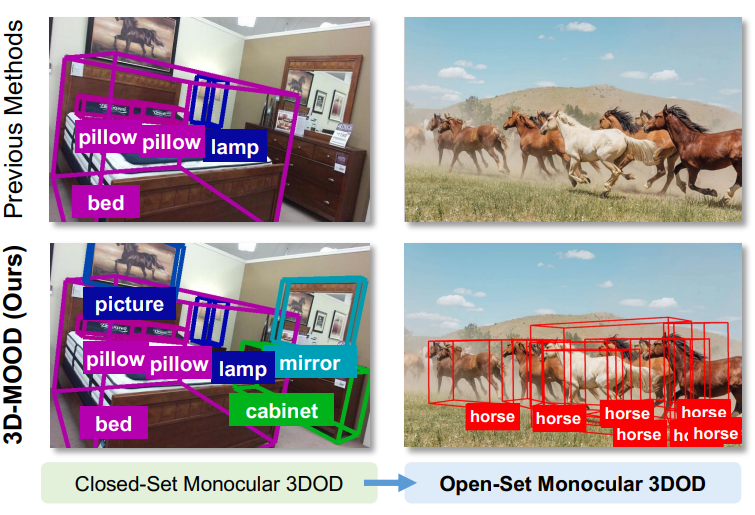
一、研究背景
傳統單目 3D 檢測方法雖然在 Omni3D 等大規模基準上取得了不錯的成績,但仍停留在特定類別和特定場景的優化,缺乏對未知類別的適應性。
為了打破這一局限,研究者們提出了 開放集3D檢測 的概念,要求模型不僅能檢測已知類別,還要能泛化到任意未知類別。這對于構建更智能、更通用的3D感知系統至關重要。然而,這一任務極具挑戰性,因為它要求模型:
-
開放詞匯識別:能夠理解自然語言描述,識別任意對象。
-
精確3D定位:在缺乏直接深度信息的情況下,從單張2D圖像中準確推斷出物體的3D邊界框(包括位置、尺寸和方向)。
-
跨場景泛化:在多樣的室內外場景中保持穩健性能。
為此,一些工作嘗試借助大規模視覺語言模型生成偽標注來拓展類別空間,但受限于不能端到端訓練,性能依舊有限。3D-MOOD 的出現為這一難題提供了新思路:它不再依賴繁瑣的偽標注流程,而是直接設計出一個可以 端到端訓練的開集單目 3D 檢測器,真正意義上推動了單目檢測向開放世界應用邁進。
在Coovally平臺上包括多模態3D檢測、目標追蹤、目標檢測、文字識別、實例分割、關鍵點檢測等全新任務類型。

!!點擊下方鏈接,立即體驗Coovally!!
平臺鏈接:https://www.coovally.com
平臺匯聚國內外開源社區超1000+熱門模型,覆蓋YOLO系列、Transformer、ResNet等主流視覺算法。同時集成300+公開數據集,一鍵下載即可投入訓練,徹底告別“找模型、配環境、改代碼”的繁瑣流程!

二、3D-MOOD 方法
3D-MOOD 的核心思想是 “從 2D 到 3D 的提升”。研究者在強大的開集 2D 檢測模型 G-DINO 的基礎上,設計了一個 3D Bounding Box Head,用來預測物體的三維中心、深度、尺寸和旋轉,將二維檢測框自然地擴展為三維框。
與此同時,論文還提出了兩個關鍵模塊來增強泛化能力。其一是 Canonical Image Space,通過對圖像分辨率和相機內參的規范化,使訓練和測試在不同數據集間保持一致,避免了常見的跨域退化。其二是 Geometry-aware 3D Query Generation,利用相機參數和深度特征生成幾何感知的查詢,顯著提升了在陌生場景下的表現。此外,模型還配備了 輔助深度估計頭,進一步增強了對三維幾何的理解。
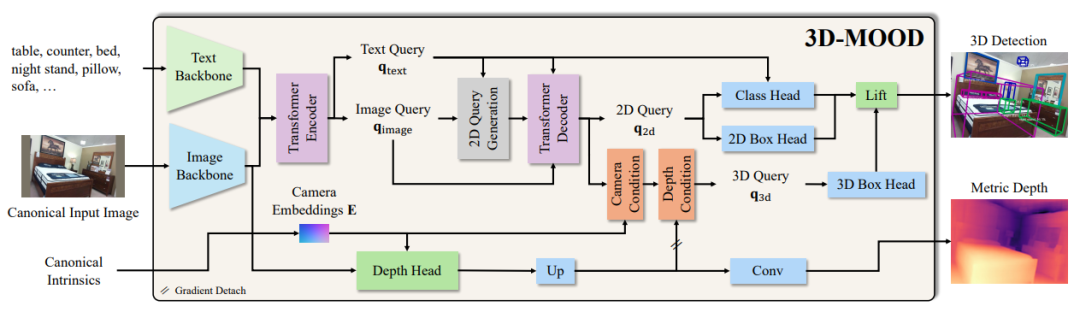
-
規范圖像空間 (Canonical Image Space)
范圖像空間 (Canonical Image Space)在單目3D檢測中,相機內參(如焦距)對于從2D像素坐標推斷3D空間位置至關重要。然而,在訓練和推理過程中,輸入圖像通常會經過縮放和填充(resizing and padding)以適應網絡輸入尺寸,這會隱式地改變相機內參,導致3D定位不準確。
為解決此問題,3D-MOOD引入了 規范圖像空間(Canonical Image Space, CI)。其思想是在預處理圖像的同時,對相機內參進行相應的、顯式的變換,從而將不同分辨率、不同焦距的圖像統一到一個標準化的坐標空間中。這使得模型能夠學習到一種與原始圖像尺寸和相機參數無關的、更具泛化性的幾何表示。

如上圖所示,傳統方法(左側)在圖像縮放后并未調整相機內參,導致幾何信息不一致。而3D-MOOD提出的CI(右側)通過同步調整內參,確保了3D幾何投影的一致性。實驗證明,這種方法不僅提升了精度,還因其高效的批處理能力降低了訓練時的GPU內存消耗。

-
幾何感知的3D查詢生成?(Geometry-Aware 3D Query Generation)
現代檢測器(如DETR系列)通常使用一組可學習的“查詢”(queries)來代表潛在的物體。如何初始化這些查詢對于模型的性能至關重要。在3D檢測中,理想的查詢應包含場景的幾何先驗信息。
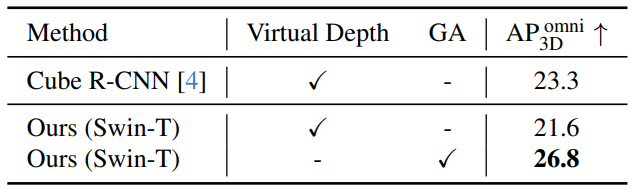
3D-MOOD提出了一種幾何感知的3D查詢生成(Geometry-Aware 3D Query Generation, GA)機制。它首先利用一個輕量級的深度估計頭(auxiliary depth estimation head)預測出粗略的深度圖,然后將圖像特征與這個深度圖結合,生成一組與場景幾何結構緊密相關的3D查詢。這些查詢能夠更有效地聚焦于場景中可能存在物體的區域,從而加速模型收斂并提升檢測精度。與之前方法(如Cube R-CNN中的虛擬深度)相比,GA機制被證明能取得更好的收斂效果。
三、實驗與結果
-
開集實驗
為了驗證方法的有效性,作者在 Omni3D 上進行了訓練,并在 Argoverse 2(室外自動駕駛場景) 和 ScanNet(室內場景) 上開展了開集測試。


結果顯示,3D-MOOD 在新類別和新環境中均大幅超越了 Cube R-CNN 和 OVM3D-Det 等基線方法,證明其在開集檢測中的顯著優勢。
-
跨領域實驗
在跨域實驗中,3D-MOOD 在不同數據集間實現了更強的遷移能力,優于 Uni-MODE 等統一模型;在閉集設定下,它同樣在 Omni3D 上刷新了 SOTA,說明方法不僅適用于開放場景,在標準評測中也具備領先性能。


-
消融實驗
進一步的消融實驗則表明,Canonical Image Space、輔助深度估計與幾何感知查詢生成模塊均對性能提升有所貢獻,尤其是幾何感知查詢,在開集場景中的作用尤為明顯。

總結
3D-MOOD 的提出,首次將 單目 3D 檢測從閉集擴展到開集,并通過端到端設計解決了跨場景與新類別檢測的難題。它不僅在多個數據集上刷新了 SOTA,還為未來的三維感知研究打開了新的方向。隨著更多跨模態學習和大規模數據的加入,類似 3D-MOOD 的方法有望進一步提升開放世界下的三維理解能力,推動其在自動駕駛、機器人等領域的實際落地。










切換工作界面為淺灰色的方法)


:秒級擴容)

)

)
)

