目錄
一、數據增強
1. 核心概念
2. 核心目的
3. 常用方法
4. 實現示例(基于 PyTorch)
5. 自定義數據集加載
二、保存最優模型
1. 核心概念
2. 實現步驟
(1)定義 CNN 模型
(2)定義訓練與測試函數
(3)啟動訓練
3. 模型加載與使用
三、總結
在卷積神經網絡(CNN)的訓練過程中,數據增強和模型保存是提升性能與實用性的關鍵環節。以下結合理論與實例,詳細解析其原理及實現方式。
一、數據增強
1. 核心概念
數據增強是通過對原始訓練數據進行隨機變換(如旋轉、翻轉、調整亮度等),生成新的訓練樣本的技術。其本質是擴展數據多樣性,讓模型在訓練中接觸更多 “變體”,從而提升泛化能力(減少過擬合)。
2. 核心目的
- 模擬真實場景中的變量(如光照變化、視角差異、遮擋等)。
- 解決訓練數據不足的問題,通過 “人工擴充” 提升模型魯棒性。
3. 常用方法
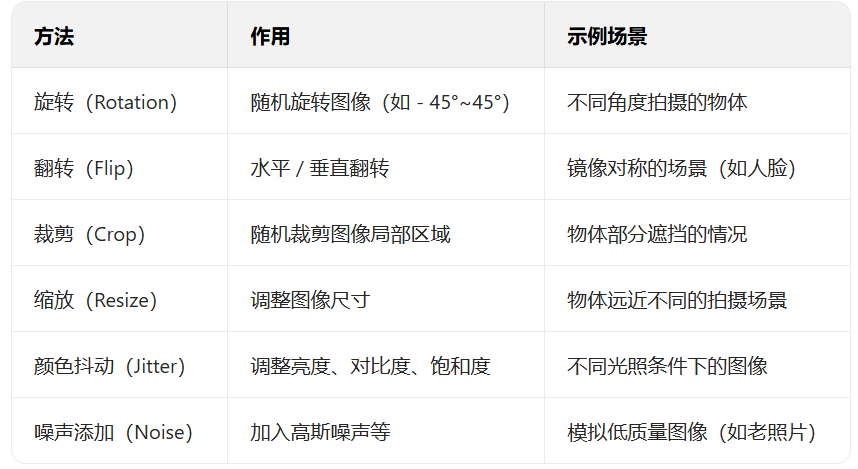

4. 實現示例(基于 PyTorch)
import torch
from torchvision import transforms# 定義訓練集和驗證集的數據增強策略
data_transforms = {'train': transforms.Compose([transforms.Resize([300, 300]), # 縮放圖像transforms.RandomRotation(45), # 隨機旋轉(-45°~45°)transforms.CenterCrop(256), # 中心裁剪至256x256transforms.RandomHorizontalFlip(p=0.5), # 50%概率水平翻轉transforms.ColorJitter(brightness=0.2, contrast=0.1), # 顏色調整transforms.ToTensor(), # 轉換為Tensor(像素值歸一化到[0,1])transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 標準化]),'valid': transforms.Compose([transforms.Resize([256, 256]), # 驗證集僅縮放,不做隨機增強transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
}5. 自定義數據集加載
通過繼承Dataset類,將增強策略應用于實際數據:
from torch.utils.data import Dataset
from PIL import Image
import numpy as npclass FoodDataset(Dataset):def __init__(self, file_path, transform=None):self.transform = transformself.imgs = []self.labels = []# 從txt文件讀取圖像路徑和標簽(格式:圖像路徑 標簽)with open(file_path, 'r') as f:for line in f.readlines():img_path, label = line.strip().split(' ')self.imgs.append(img_path)self.labels.append(int(label))def __len__(self):return len(self.imgs)def __getitem__(self, idx):# 加載圖像并應用增強image = Image.open(self.imgs[idx]).convert('RGB')if self.transform:image = self.transform(image)# 標簽轉換為Tensorlabel = torch.tensor(self.labels[idx], dtype=torch.long)return image, label# 加載訓練集和驗證集
train_dataset = FoodDataset('./train.1txt', transform=data_transforms['train'])
valid_dataset = FoodDataset('./test.1txt', transform=data_transforms['valid'])# 數據加載器(批量處理)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
valid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=64, shuffle=False)其中train.1txt文件內容為:
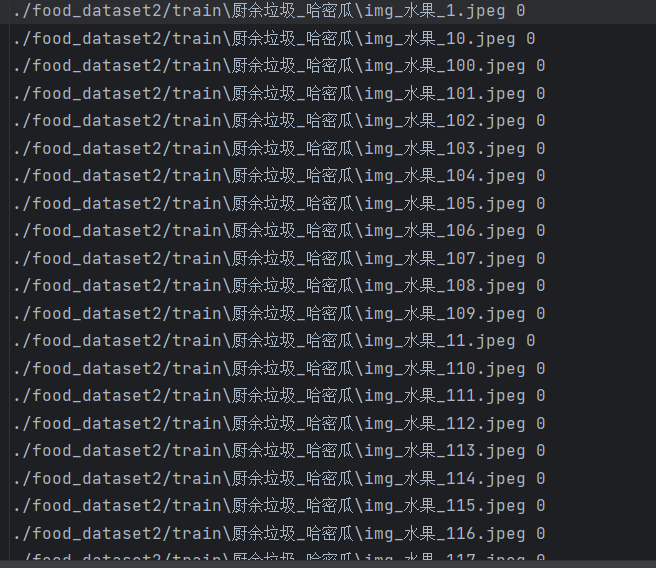
test.1txt文件內容:
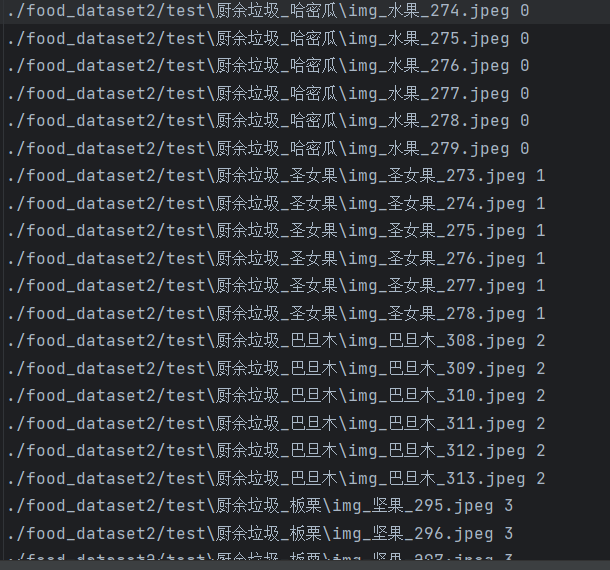
??其中的每個文件地址都有其對應的圖片,數據量較大,訓練時間會較長,如需使用,可私信發送打包文件。
? ? ? ? 整篇文章所有代碼連接為一份完整代碼。
二、保存最優模型
1. 核心概念
訓練過程中,模型性能(如驗證集準確率)會隨迭代波動。保存最優模型指在訓練中跟蹤關鍵指標(如最高準確率),并保存對應狀態,以便后續直接使用最佳模型。
2. 實現步驟
(1)定義 CNN 模型
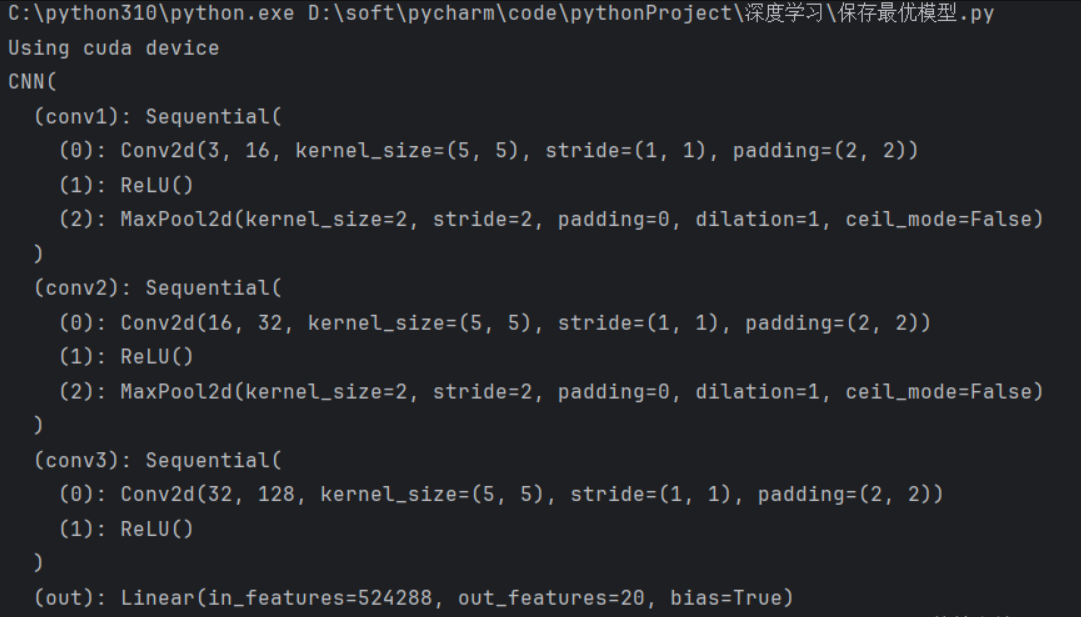
import torch.nn as nnclass SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()# 卷積層1:3通道輸入→16通道輸出,5x5卷積核self.conv1 = nn.Sequential(nn.Conv2d(3, 16, kernel_size=5, stride=1, padding=2),nn.ReLU(),nn.MaxPool2d(kernel_size=2) # 池化后尺寸減半)# 卷積層2:16通道→32通道self.conv2 = nn.Sequential(nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),nn.ReLU(),nn.MaxPool2d(2))# 卷積層3:32通道→128通道(無池化)self.conv3 = nn.Sequential(nn.Conv2d(32, 128, kernel_size=5, stride=1, padding=2),nn.ReLU())# 全連接層:輸入為128×64×64(經3次卷積+池化后的尺寸),輸出20類self.fc = nn.Linear(128 * 64 * 64, 20)def forward(self, x):x = self.conv1(x) # 輸出:16×128×128x = self.conv2(x) # 輸出:32×64×64x = self.conv3(x) # 輸出:128×64×64x = x.view(x.size(0), -1) # 展平為向量x = self.fc(x)return x# 初始化模型并移動到設備(GPU/CPU)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = SimpleCNN().to(device)運行結果:
(2)定義訓練與測試函數
# 損失函數與優化器
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 訓練函數
def train(dataloader, model, loss_fn, optimizer):model.train() # 開啟訓練模式(啟用 dropout/batchnorm)for batch, (X, y) in enumerate(dataloader):X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)# 反向傳播optimizer.zero_grad() # 清空梯度loss.backward() # 計算梯度optimizer.step() # 更新參數if batch % 100 == 0:print(f"Batch {batch}, Loss: {loss.item():.4f}")# 測試函數(含最優模型保存)
best_acc = 0.0 # 記錄最佳準確率def test(dataloader, model, loss_fn):global best_accmodel.eval() # 開啟評估模式(固定 dropout/batchnorm)size = len(dataloader.dataset)num_batches = len(dataloader)test_loss, correct = 0, 0with torch.no_grad(): # 關閉梯度計算,節省內存for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchescorrect /= sizeprint(f"Test: Accuracy: {(100*correct):.1f}%, Avg loss: {test_loss:.4f}")# 保存最優模型(準確率提升時)if correct > best_acc:best_acc = correct# 保存完整模型(含結構和參數)torch.save(model, "best_model.pt")# 或僅保存參數(更輕量):torch.save(model.state_dict(), "best_model.pth")(3)啟動訓練
epochs = 150 # 訓練輪數
for t in range(epochs):print(f"\nEpoch {t+1}/{epochs}")train(train_loader, model, loss_fn, optimizer)test(valid_loader, model, loss_fn)
print("訓練完成!最優模型已保存為 best_model.pt")3. 模型加載與使用
訓練結束后,可直接加載最優模型進行預測:
# 加載保存的模型
loaded_model = torch.load("best_model.pt").to(device)
loaded_model.eval() # 切換至評估模式# 示例:對單張圖像預測
def predict(image_path):image = Image.open(image_path).convert('RGB')# 應用驗證集的預處理transform = data_transforms['valid']image = transform(image).unsqueeze(0).to(device) # 增加批次維度with torch.no_grad():pred = loaded_model(image)return pred.argmax(1).item() # 返回預測類別# 測試預測
print("預測類別:", predict("test_image.jpg"))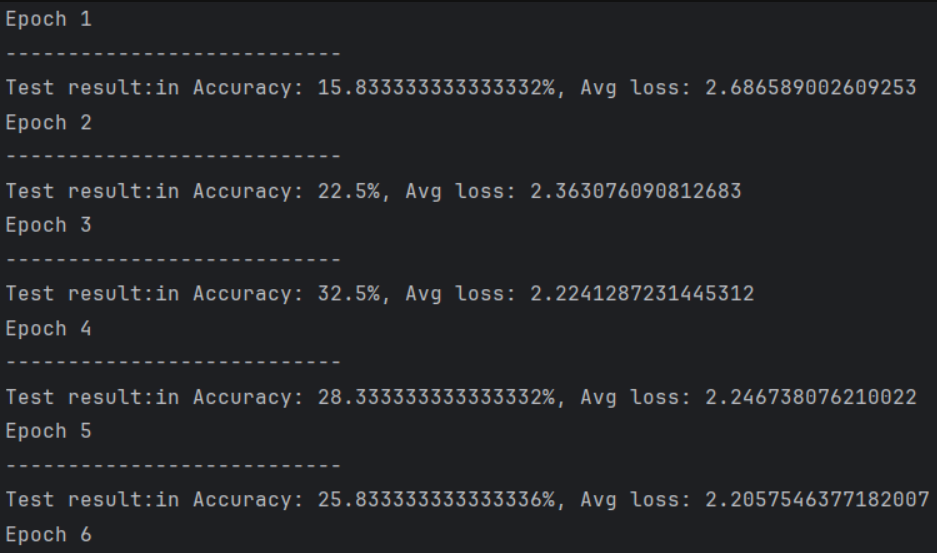
?訓練結束得到當前訓練的最優模型,其為pt\pth\t7文件,此時該文件即為當前模型,可直接調用該文件使用。
![]()
三、總結
- 數據增強通過模擬真實場景變化,提升模型泛化能力,需注意訓練集用隨機增強、驗證集僅做標準化。
- 保存最優模型通過跟蹤驗證集指標(如準確率),保留性能最佳的模型狀態,避免訓練后期過擬合導致的性能下降。
以上方法可直接應用于圖像分類、目標檢測等 CNN 任務,實際使用時需根據數據集特點調整增強策略和模型結構。













?詳解)
、CD(持續交付/部署)、CT(持續測試)、CICD、CICT)



之一(變更預檢查部分規則))
