概述與設計思路
利用Python的Scrapy框架進行大規模頁面抓取和結構化數據提取,配合aiohttp實現高并發請求,從而高效獲取Amazon平臺上的商品列表、詳情、評論等公開信息。通過對這些數據進行清洗與分析,可以識別出有潛力的商品,評估市場競爭程度,并跟蹤競爭對手的動態,為跨境電商選品提供數據支撐。
核心思路是通過爬蟲程序模擬瀏覽器行為,繞過Amazon的反爬蟲機制,持續抓取商品標題、價格、評分、評論數、類目、上架時間、賣家信息等關鍵字段,進而利用數據分析方法評估商品的市場潛力。
以下是本方案主要組件及其關系的架構圖: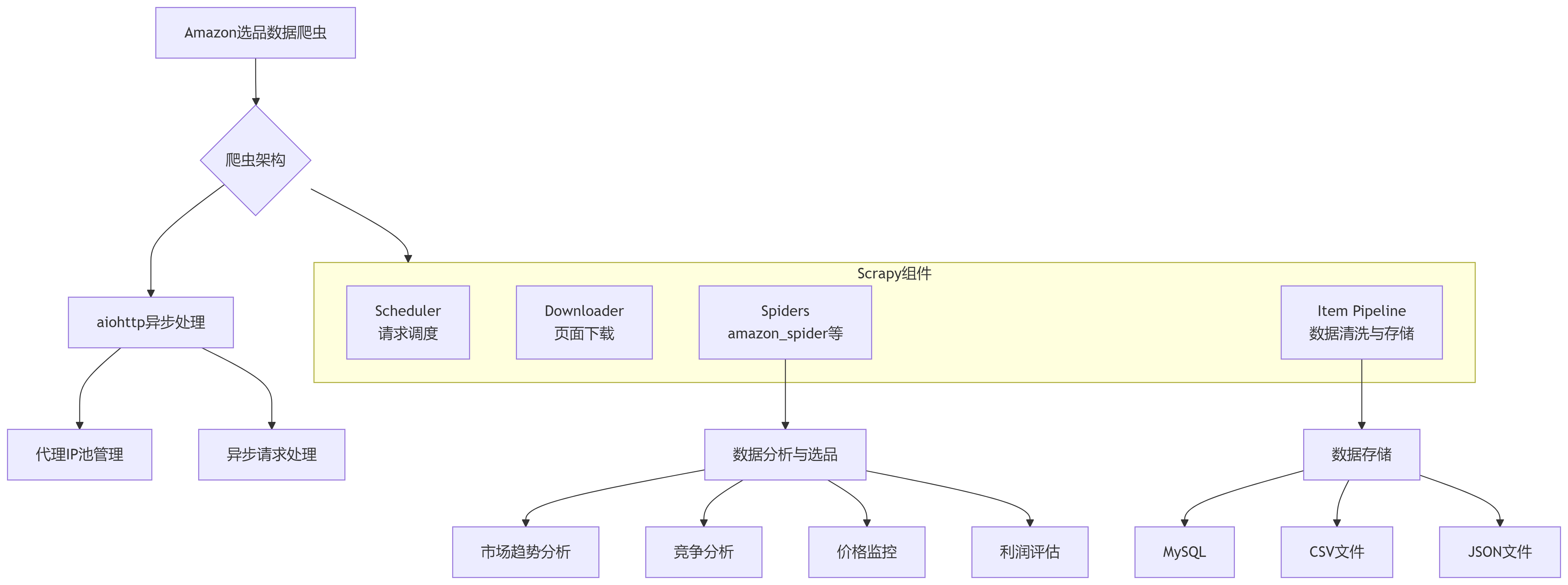
核心代碼實現
1. 環境配置與依賴安裝
首先,確保你的Python環境(建議3.8及以上)已安裝必要的庫:
pip install scrapy aiohttp aiohttp-socks scrapy-user-agents pandas numpy matplotlib2. Scrapy爬蟲項目搭建
使用Scrapy框架創建爬蟲項目,這是爬取Amazon產品數據的主力47。
(1) 創建Scrapy項目
在命令行中執行:


?詳解)
、CD(持續交付/部署)、CT(持續測試)、CICD、CICT)



之一(變更預檢查部分規則))


)

文件管理-基礎命令-pwd命令的使用)
)





)