爬取步驟:
1.先找到網頁源代碼
2.從網頁源代碼中拿到m3u8
3.下載m3u8
4.讀取m3u8文件,下載視頻
5.合并視頻
首先我們來爬取一個星辰影院的電影:
下面我以這個為例:
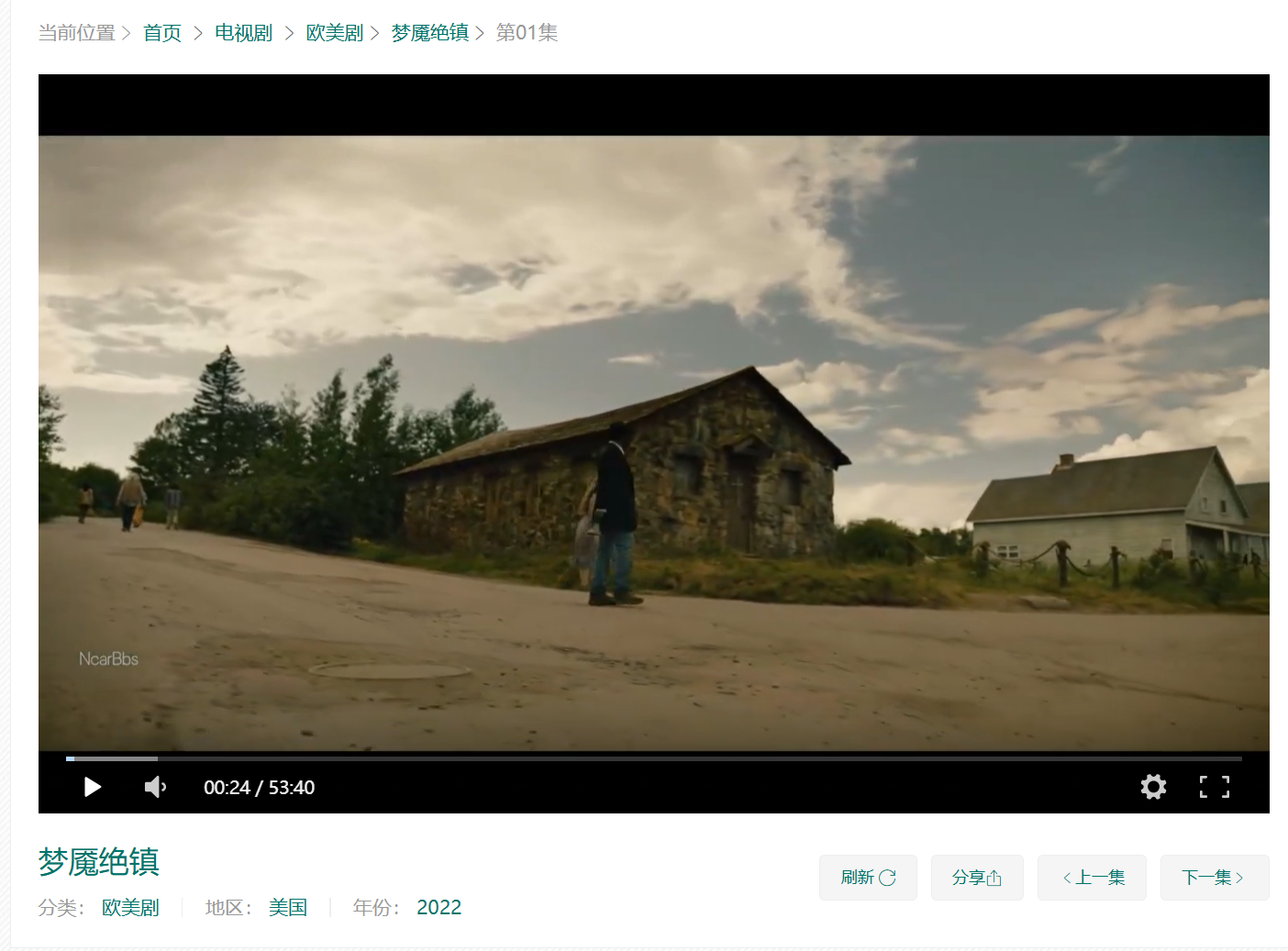
我們需要在源代碼中找到m3u8這個url:
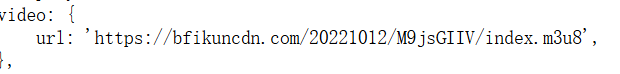
緊接著我們利用下面的方法來進行視頻的爬取:
輸入網站的url:
url="https://www.xcyy44.com/play/16166_1.html"打印一下看一下是否有我們要的數據:
resp=requests.get(url)
print(resp.text)在搜索框中搜索一下發現正是我們要的url:
再利用正則表達式提取一下m3u8的地址:
obj=re.compile(r"url: '(?P<url>.*?)',",re.S) 得到m3u8的地址并打印:
m3u8_url=obj.search(resp.text).group("url")
print(m3u8_url) 
接下來把m3u8文件下載下來:
用resp2來接受一下m3u8的地址,并把resp2寫入到test文件中:
resp2=requests.get(m3u8_url)with open("test.m3u8","wb") as f:f.write(resp2.content)resp2.close()
print('下載完畢')然后將得到的這些m3u8進行解析:
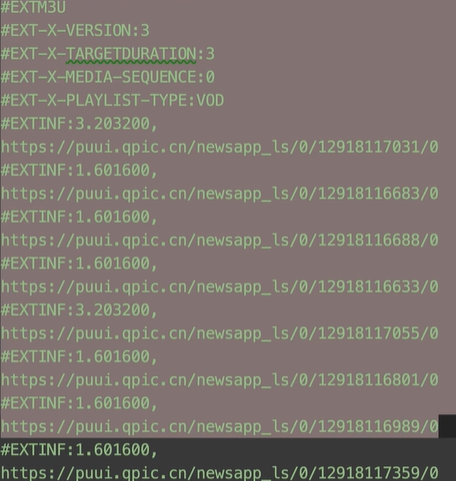
先將test文件打開讀取里面的內容,在利用循環便利一下里面的內容,在利用strip()去除空白,判斷是否有#,如果有就繼續遍歷,找到沒有的寫入到video中完成一個打印一個:
n=1
with open('test.m3u8','r',encoding='utf-8') as f:for line in f:line = line.strip() if line.startswith('#'): continueresp3=requests.get(line)f=open(f'video/{n}.ts','wb')f.write(resp3.content)f.close()resp3.close()n+=1print('完成一個')最后在把視頻片段合并在一起就ok了
完整代碼:
import requests
import reobj=re.compile(r"url: '(?P<url>.*?)',",re.S) #用來提取m3u8的地址url="https://www.xcyy44.com/play/16166_1.html"resp=requests.get(url)
m3u8_url=obj.search(resp.text).group("url") #拿到m3u8的地址
# print(resp.text)
# print(m3u8_url)
resp.close()#下載m3u8文件
resp2=requests.get(m3u8_url)with open("test.m3u8","wb") as f:f.write(resp2.content)resp2.close()
print('下載完畢')
#
# #解析m3u8文件
n=1
with open('test.m3u8','r',encoding='utf-8') as f:for line in f:line = line.strip() #去掉空白if line.startswith('#'): #如果以#開頭則會繼續循環continue#下載視頻片段resp3=requests.get(line)f=open(f'video/{n}.ts','wb')f.write(resp3.content)f.close()resp3.close()n+=1print('完成一個')


?詳解)
、CD(持續交付/部署)、CT(持續測試)、CICD、CICT)



之一(變更預檢查部分規則))


)

文件管理-基礎命令-pwd命令的使用)
)




