😘個人主頁:@Cx330?
👀個人簡介:一個正在努力奮斗逆天改命的二本覺悟生
📖個人專欄:《C語言》《LeetCode刷題集》《數據結構-初階》《C++知識分享》
🌟人生格言:心向往之行必能至

前言:上篇博客中,我們掌握了引用的小部分,這篇博客會接著把引用剩余的部分講解給大家,然后還會給大家認識內聯函數與nullptr的核心用法,掌握號這些知識,我們就可以進入類和對象的學習中去了
目錄
一.引用(補充)
const引用:
關鍵點:
舉例說明:
圖示如下:
指針和引用的關系:(面試考點)
二.inline內聯函數
關鍵點:
舉例說明:
三.nullptr
關鍵點:
舉例說明:
一.引用(補充)
const引用:
關鍵點:
- 可以引用?個const對象,但是必須用const引用。const引用也可以引用普通對象,因為對象的訪問權限在引用過程中可以縮小,但是不能放大。
- 需要注意的是,在一些場景下,比如類型轉換中會產生臨時對象存儲中間值,也就是說我下面的rb和rp引用的都是臨時對象,而C++規定臨時對象具有常性,所以這里就觸發了權限放大,必須要使用常引用才可以
- 所謂臨時對象就是編譯器需要?個空間暫存表達式的求值結果時臨時創建的?個未命名的對象,C++中把這個未命名對象叫做臨時對象。
舉例說明:
1.引用和指針的權限放大和縮小問題(放大不行,縮小可以):
#include<iostream>
using namespace std;
int main()
{const int a = 0;//權限放大(不能)//int& b = a;int c = 0;//權限縮小(能)const int& d = c;return 0;
}//權限的放大和縮小,只存在于const指針和const引用
//我們再來看看指針#include<iostream>
using namespace std;int main()
{const int a = 0;const int* p1 = &a;//int& p2 = p1;//這個也屬于權限的放大,得寫成下面這樣const int* p2 = p1;//但是權限縮小還是可以的int c = 0;int* p3 = &c;const int* p4 = p3;return 0;
}2.const可以引用常量,作為函數參數時如果不是為了讓形參的改變可以影響實參,是可以const修飾引用的,這樣傳參的時候選擇更多 :
#include<iostream>
using namespace std;int main()
{int i = 0;double d = i;//這個是可以通過編譯的,涉及隱式類型轉換,因為int和double本質上都是關于數據類型大小的。//像整型和指針就只能用強制類型轉換,如下int p = (int)&i;//但是我們再來看看引用里面的使用int j = 1;//double& rd = j;//不行const double& rd = j;//這個就可以了//為什么呢?--我們先不急再看一個例子//int& rp = (int)&j;//不行const int& rp = (int)&j;//可以//-------------------------具體原因分析(配合圖片)------------------------------------//這是因為在引用里面,轉換的過程中會產生一個臨時對象保存中間值。//所以實際上rb,rp引用的都是中間值,在C++里這個臨時對象是具有常性的(即被const修飾)//因此我們這里如果直接轉換的話,就會出現權限放大的錯誤,我們必須使用常引用(即const修飾)return 0;
}圖示如下:

指針和引用的關系:(面試考點)
C++中指針和引用就像兩個性格迥異的親兄弟,指針是哥哥,引用是弟弟,在實踐中他們相輔相成,相得益彰。功能有重疊性,但是也有各自的特點,互相不可替代:
- 語法概念上引用是一個變量的取別名不開空間,指針是存儲?個變量地址,要開空間。(我們一般盡量取談語法層,底層只在一些特殊場景下用來輔助了解)
- 引用在定義時必須初始化,指針建議初始化,但是語法上不是必須的。
- 引用在初始化時引用?個對象后,就不能再引用其他對象;而指針可以在不斷地改變指向對象。
- 指針很容易出現空指針和野指針的問題,引用很少出現,引用使用起來相對更安全?些。
- 引用可以直接訪問指向對象,指針需要解引用才是訪問指向對象。
- sizeof中含義不同,引用結果為引用類型的大小,但指針始終是地址空間所占字節個數(32位平臺下占4個字節,64位下是8byte)
二.inline內聯函數
關鍵點:
- 用inline修飾的函數叫做內聯函數,編譯時C++編譯器會在調用的地方展開內聯函數,這樣調用內聯函數就不需要建立棧幀了,可以提高效率。
-
inline對于編譯器而言只是一個建議,也就是說,你加了inline編譯器也可以選擇在調用的地方不展開,不同編譯器關于inline什么情況展開各不相同,因為C++標準沒有規定這個。inline適用于頻繁調用的短小函數,對于遞歸函數,代碼相對多?些的函數,加上inline也會被編譯器忽略。
- C語言實現宏函數也會在預處理時替換展開,但是宏函數實現很復雜很容易出錯的,且不方便調試,C++設計了inline目的就是替代C的宏函數。
- vs編譯器 debug版本下面默認是不展開inline的,這樣方便調試,debug版本想展開需要設置?下兩個地方(后面的舉例說明中會有)。
- inline不建議聲明和定義分離到兩個文件,分離會導致鏈接錯誤。因為inline被展開,就沒有函數地址,鏈接時會出現報錯。
舉例說明:
先來看看之前C語言中宏函數里面的一些坑吧,以ADD函數為例:
錯誤一:
#define ADD(int x,int y) return x+y;這個錯誤很離譜,我們要牢記宏是一種替換機制,這里直接寫成了一個函數,很明顯是錯誤的
錯誤二:
//宏是一種替換機制
//#define ADD(int x,int y) return x+y;
//錯誤寫法二:
//#define ADD(a,b) a+b;
//宏定義不要帶分號
//我們把分號去掉,但是還是有問題的
#define ADD(a,b) a+busing namespace std;int main()
{int ret1 = ADD(1, 2);//展開之后:int ret1 = 1 + 2;;,會出現兩個分號,這里還不會報錯,我們再來看看下面的//int ret2 = ADD(1, 2) * 3;//這里就出問題了//我們就算不帶分號,上面這個ret2最后的值也是錯的int ret2 = ADD(1, 2) * 3;//我們想要得到的是9,但是我們打印出來是7cout << ret2 << endl;//因為展開之后:1 + 2 * 3 = 7//這里的優先級被影響了return 0;
}宏定義時,不要加分號,還需要加上()來保持優先級
錯誤三:
#define ADD(a,b) (a+b)
#include<iostream>
using namespace std;int main()
{//這樣寫ret2打印出來的結果是我們想要的9int ret2 = ADD(1, 2) * 3;cout << ret2 << endl;//但是這種寫法還是存在一些問題的int x = 0, y = 1;ADD(x | y, x & y);//展開會變成:(x | y + x & y)//+號的優先級高于 |和& 所以這里相當于(x|(y+x)&y)return 0;
}帶上了外面的括號,ret2的問題解決了。但是在一些場景下還是有問題
正確寫法:
//正確寫法:
#define ADD(a,b) ( (a) + (b) )
#include<iostream>
using namespace std;int main()
{//這樣寫ret2打印出來的結果是我們想要的9int ret2 = ADD(1, 2) * 3;cout << ret2 << '\n';//這種寫法也沒問題了int x = 0, y = 1;ADD(x | y, x & y);//展開會變成:( (x | y) + (x & y) ),符合我們的目的return 0;
}💡Tips:
宏函數這么復雜,容易寫出問題,還不能調試。
那我們為什么還要用它呢,它的優勢在于什么呢?
優點:高頻調用小函數時,寫成宏函數,可以提高效率,預處理階段宏會替換,提高效率,不建立棧幀
我們在C++中使用inline內聯函數代替宏函數該怎么寫:
inline int ADD(int x, int y)
{return x + y;
}和函數的寫法差不多,但是是不一樣的。它編譯是直接展開的跟宏一樣,不會創建棧幀空間?
因為默認debug版本下,為了方便調試,inline也不展開。我們需要完成兩設置:
代碼:
#include<iostream>
using namespace std;//轉反匯編看,發現還是有call還是創建了棧幀,這是為什么
inline int ADD(int a, int b)
{return a + b;
}
//因為默認debug版本下,為了方便調試,inline也不展開。
//我們需要設置一下--這里大家可以自己測試看看,最號=好用低版本的vsint main()
{int ret2 = ADD(1, 2) * 3;cout << ret2 << '\n';//打印出來也是9,完全沒有問題return 0;
}設置步驟:
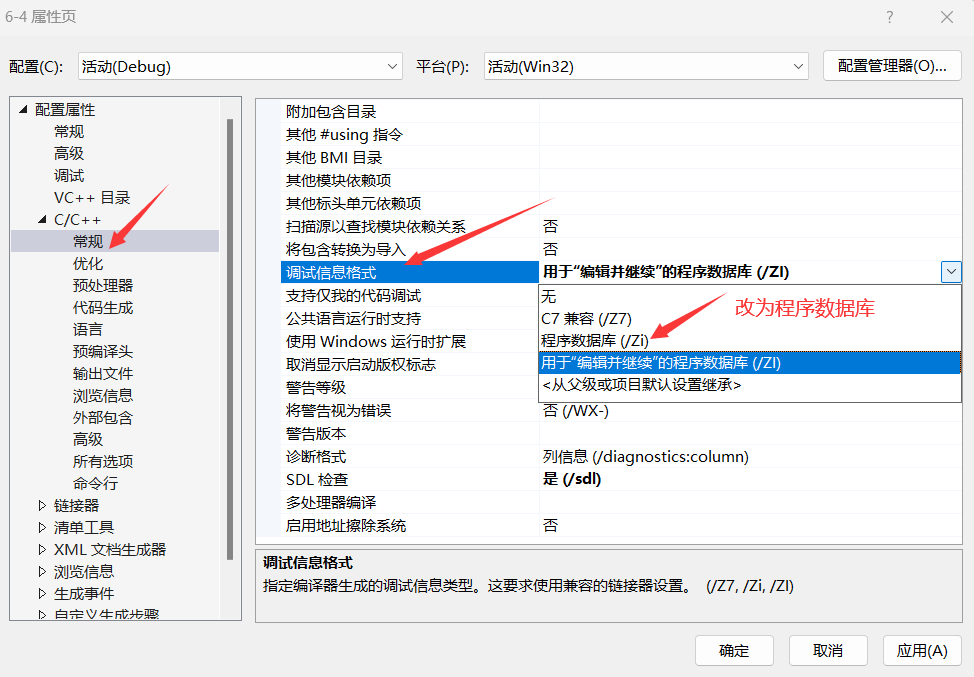
- 右鍵單擊解決方案資源管理器中的項目,選擇“屬性”。
- 在彈出的屬性對話框中,找到“C/C++”選項卡,點擊“常規”。
- 在“調試信息格式”下拉菜單中,選擇“程序數據庫(/Zi)”。
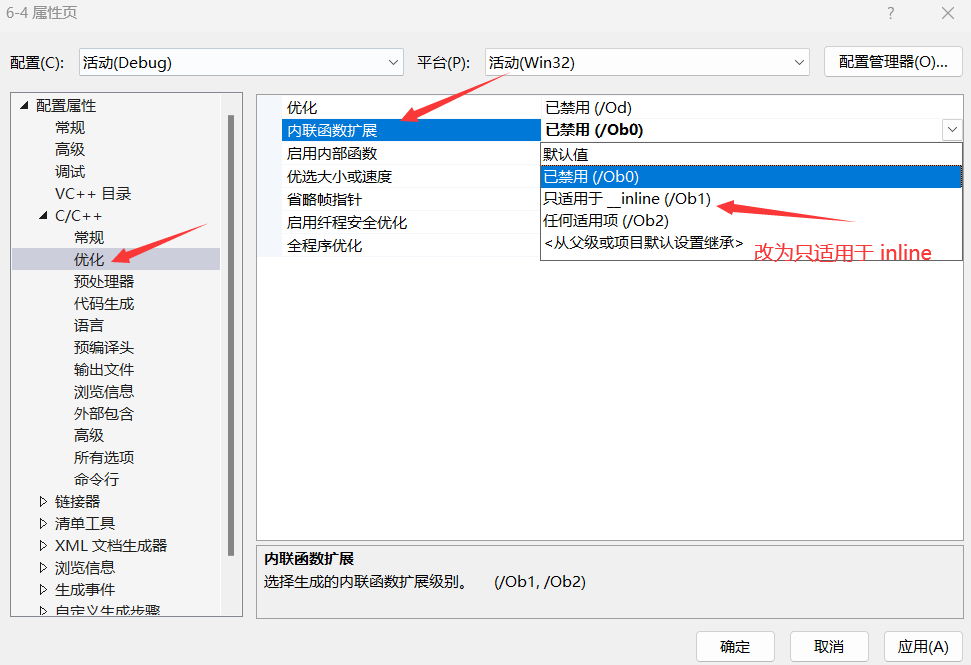
- 接著點擊“C/C++”下的“優化”選項。
- 在“內聯函數的擴展”下拉菜單中,選擇“只適用于_inline(/Ob1)”。

inline只是一個建議,展開還是創建空間由編譯器說的算,遞歸和代碼多的函數可能就不會展開:
#include<iostream>
using namespace std;inline int ADD(int a, int b)
{a *= 2;a *= 2;a *= 2;a *= 2;a *= 2;a *= 2;a *= 2;a *= 2;a *= 2;a *= 2;//5個的時候還是可以展開的,10個就不行了return a + b;
}int main()
{int ret2 = ADD(1, 2) * 3;cout << ret2 << '\n';return 0;
}圖示如下:
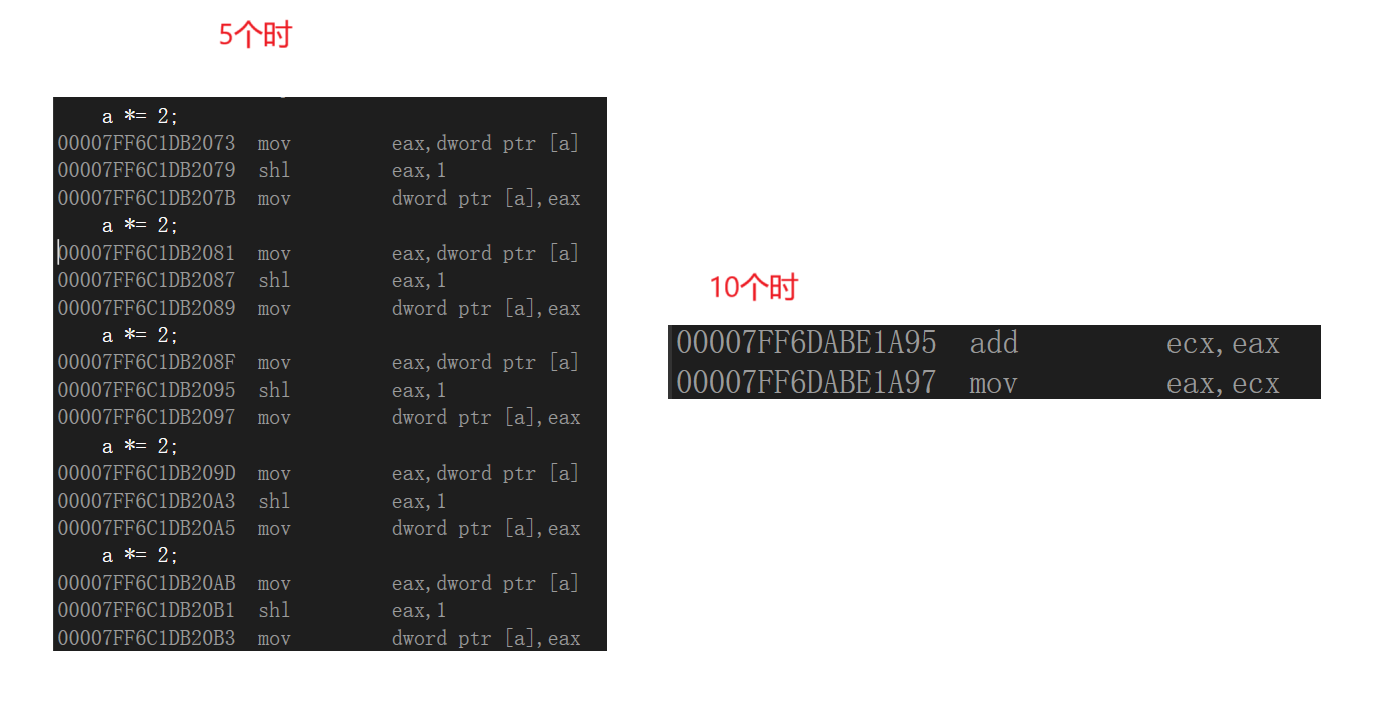
思考:為什么只是建議呢?
如果完全交給程序員,可能會出現代碼指令惡性膨脹的問題,導致可執行程序(安裝包)過大,這是特別不好的。所以編譯器會自己把握這個展開還是不展開,有其自己的邏輯和判斷。

inline不建議聲明和定義放離到兩個文件,分離會導致鏈接錯誤。因為inline被展開,就沒有函數地址,鏈接時會出錯:(注意看注釋)
拿順序表為例,我直接給正確改法了,然后它的.cpp文件和.h文件這里是截圖的
SeqList.h:(內聯函數直接在.h文件中實現就可以了)
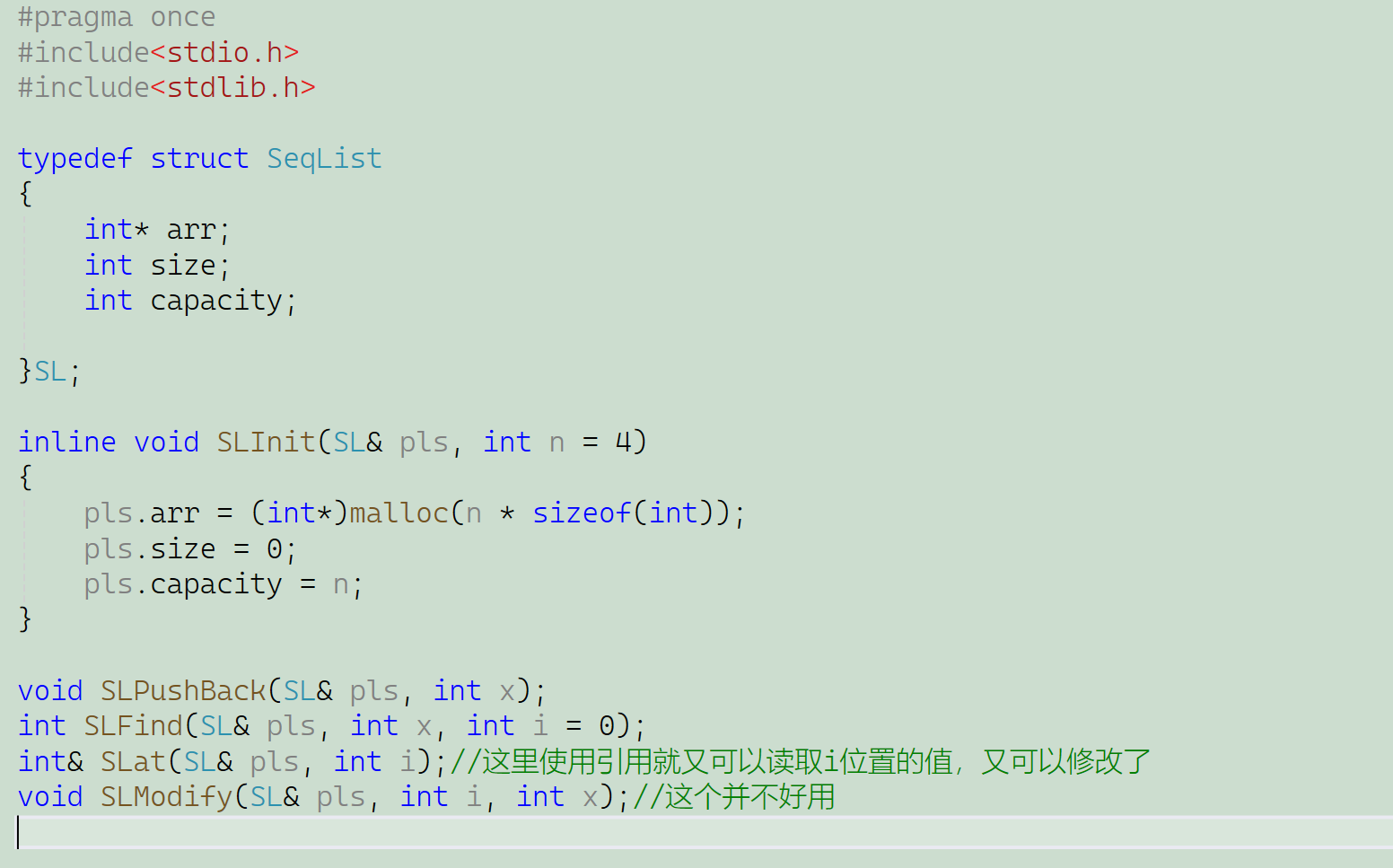
SeqList.cpp:(在.cpp文件中不需要再實現內聯函數了,可以看出我這里注釋掉了)
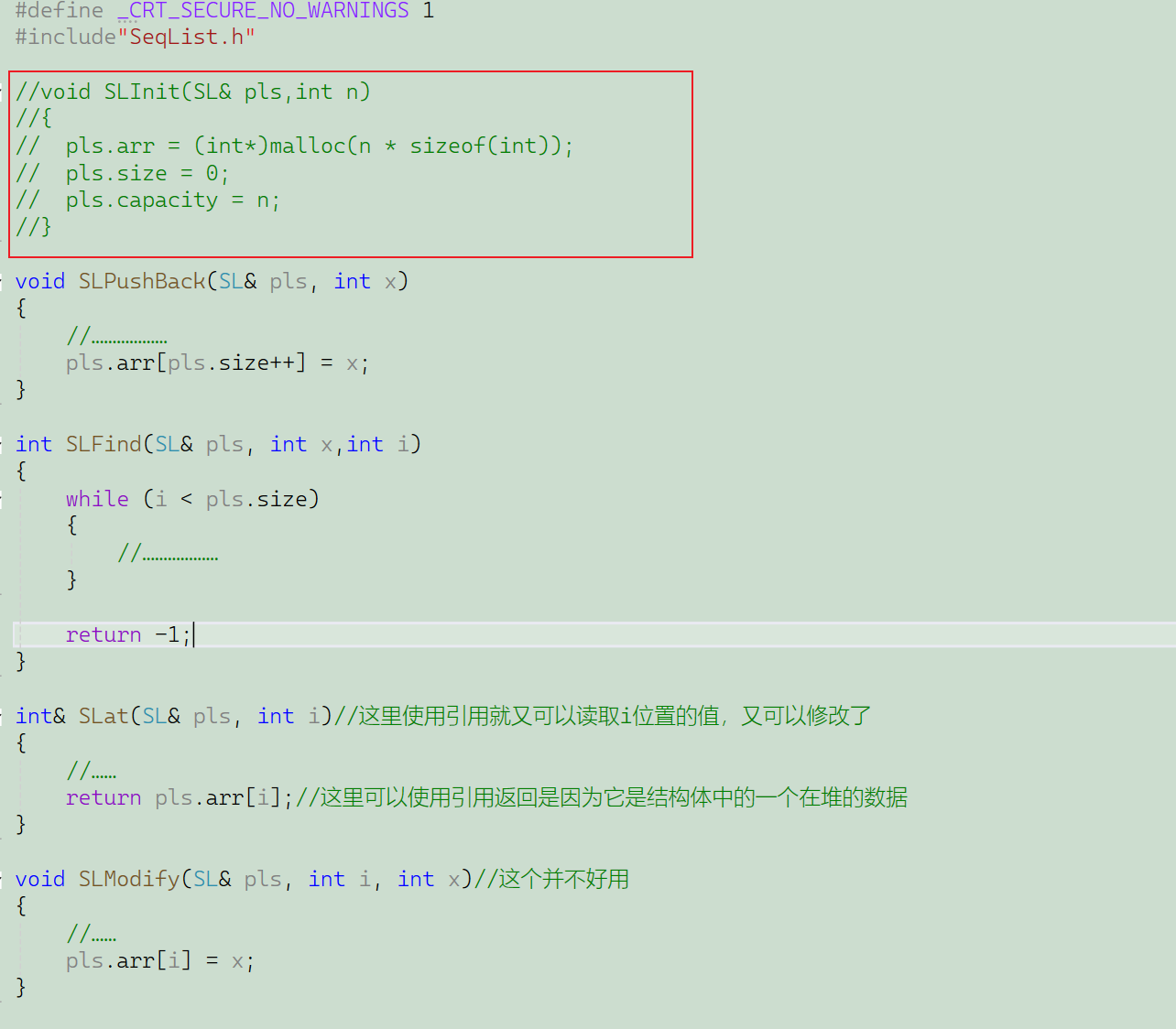
test.cpp:
#include"SeqList.h"int main()
{SL s;//我實現用的引用所以不用傳地址SLInit(s); // call 地址return 0;
}三.nullptr
NULL實際是?個宏,在傳統的C頭文件(stddef.h)中,可以看到如下代碼:

關鍵點:
- C++中NULL可能被定義為字面常量0,或者C中被定義為無類型指針(void*)的常量。不論采取何種定義,在使用空值的指針時,都不可避免的會遇到?些麻煩,本想通過f(NULL)調?指針版本的f(int*)函數,但是由于NULL被定義成0,調用了f(int x),因此與程序的初衷相悖。f((void*)NULL);調用會報錯。
- C++11中引入nullptr,nullptr是?個特殊的關鍵字,nullptr是?種特殊類型的字面量,它可以轉換成任意其他類型的指針類型。使用nullptr定義空指針可以避免類型轉換的問題,因為nullptr只能被隱式地轉換為指針類型,而不能被轉換為整數類型。
舉例說明:
#include<iostream>
using namespace std;void f(int x)
{cout << "f(int x)" << endl;
}void f(int* ptr)
{cout << "f(int* ptr)" << endl;
}int main()
{f(0);f(NULL);//f((void*)0);--有個圖片//用上面的都會執行出來函數1,而不會是函數2f(nullptr);//但是用nullptr就很清晰了,可以很好處理這個問題int* p1 = NULL;char* p2 = NULL;//以后我們在C++里面置為空都這樣寫int* p3 = nullptr;char* p4 = nullptr;return 0;
}
這里可以看出用NULL時并沒有達到我想要的效果,但是用nullptr可以?
完整源代碼:
CPP專屬倉庫: 【CPP知識學習倉庫】 - Gitee.com
往期回顧:
《C++起源與核心:版本演進+命名空間法》
《C++基礎:輸入輸出、缺省參數,函數重載與引用的巧妙》
總結:這篇博客到這里就結束了,我們C++人們知識也就告一段落,接下來就會進入我們類和對象的學習中去,如果文章對你有幫助的話,歡迎評論,點贊,收藏加關注,感謝大家的支持。


)










:化繁為簡,Spring Boot自動配置的實現之秘)


)
![[Vid-LLM] docs | 視頻理解任務](http://pic.xiahunao.cn/[Vid-LLM] docs | 視頻理解任務)

![[Java惡補day51] 46. 全排列](http://pic.xiahunao.cn/[Java惡補day51] 46. 全排列)