目錄
一、功能介紹
二、具體的程序示例
三、實際應用建議
一、功能介紹
本方案的核心功能是持續監聽一個數據源(如傳感器、API接口、消息隊列、其他應用程序等),將獲取到的實時數據流以追加的方式寫入到Excel文件中。同時,方案會處理文件創建、表頭初始化、數據分批寫入等細節,確保程序的效率和數據的完整性。
二、具體的程序示例
示例功能
模擬數據源: 創建一個函數來模擬實時監測數據(例如:時間戳、溫度、濕度、壓力)。
初始化Excel文件: 程序啟動時,檢查目標Excel文件是否存在。如果不存在,則創建它并寫入表頭。
定時任務: 每5秒采集一次模擬數據,并將其追加到Excel文件的指定工作表中。
優雅退出: 通過鍵盤中斷(Ctrl+C)可以安全地停止程序。
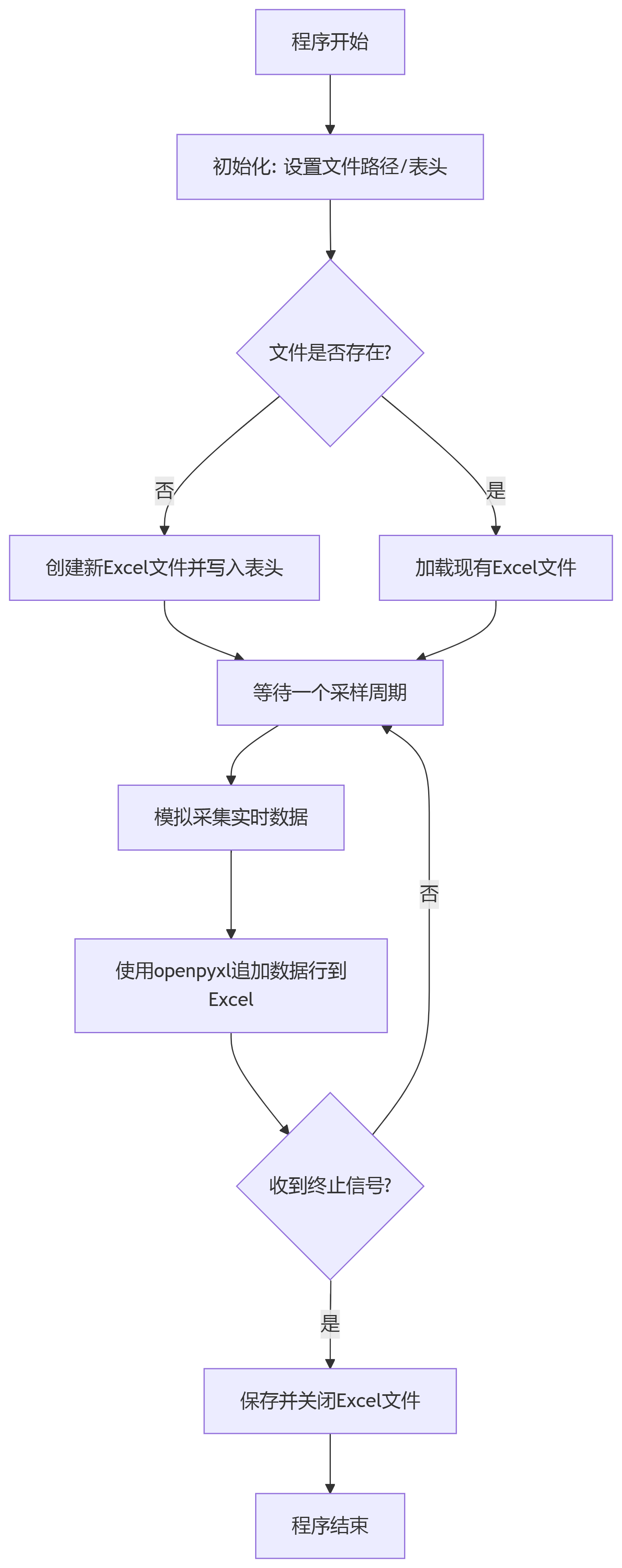
程序流程圖
大家好好看看程序流程圖,幫助厘清思路和理解后面的python程序。
以下是具體的python源程序代碼,里面有非常詳細的注釋,可以復制到自己的開發環境里面去運行體驗一下。
import pandas as pd
from openpyxl import load_workbook
import time
from datetime import datetime
import os
import scheduleclass RealTimeExcelLogger:def __init__(self, filename='real_time_data.xlsx'):"""初始化實時Excel記錄器:param filename: Excel文件名"""self.filename = filenameself.sheet_name = '監測數據'self.headers = ['時間戳', '溫度(°C)', '濕度(%RH)', '壓力(kPa)']# 初始化文件,如果文件不存在則創建self._init_excel_file()def _init_excel_file(self):"""檢查并初始化Excel文件,如果文件不存在則創建它并寫入表頭"""if not os.path.exists(self.filename):# 創建一個空的DataFrame,只包含表頭df = pd.DataFrame(columns=self.headers)# 使用to_excel創建新文件df.to_excel(self.filename, index=False, sheet_name=self.sheet_name)print(f"新建文件并初始化表頭: {self.filename}")else:print(f"文件已存在,將追加數據: {self.filename}")def _get_simulated_data(self):"""模擬生成一條實時監測數據(替換此函數以連接真實數據源):return: 一個包含傳感器數據的列表,順序與self.headers一致"""# 模擬數據生成邏輯timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")temperature = round(25 + (5 * (time.time() % 1)), 2) # 在25°C附近波動humidity = round(50 + (10 * ((time.time() + 1) % 1)), 2) # 在50%附近波動pressure = round(101.3 + (0.5 * ((time.time() + 2) % 1)), 2) # 在101.3kPa附近波動return [timestamp, temperature, humidity, pressure]def _save_data_row(self, data_row):"""使用openpyxl將一條數據記錄追加到Excel文件中:param data_row: 要寫入的數據列表"""# 加載現有工作簿book = load_workbook(self.filename)# 獲取活動工作表或指定名稱的工作表writer = pd.ExcelWriter(self.filename, engine='openpyxl', mode='a', if_sheet_exists='overlay')writer.book = bookwriter.sheets = {ws.title: ws for ws in book.worksheets}# 獲取目標工作表sheet = book[self.sheet_name]# 找到下一個空行next_row = sheet.max_row + 1# 將數據寫入對應的單元格for col_num, value in enumerate(data_row, 1):sheet.cell(row=next_row, column=col_num, value=value)# 保存工作簿book.save(self.filename)print(f"數據已保存: {data_row}")def job(self):"""定時執行的任務:獲取數據并保存"""print("執行數據采集任務...")data = self._get_simulated_data()self._save_data_row(data)def run(self, interval_seconds=5):"""運行主循環,定時采集數據:param interval_seconds: 采集間隔時間(秒)"""print(f"開始實時監測,每 {interval_seconds} 秒記錄一次數據。按 Ctrl+C 停止。")# 使用schedule庫進行調度schedule.every(interval_seconds).seconds.do(self.job)try:# 先立即執行一次self.job()while True:schedule.run_pending()time.sleep(1) # 降低CPU占用except KeyboardInterrupt:print("\n程序被用戶中斷。")finally:print("數據記錄已完成。")# 主程序入口
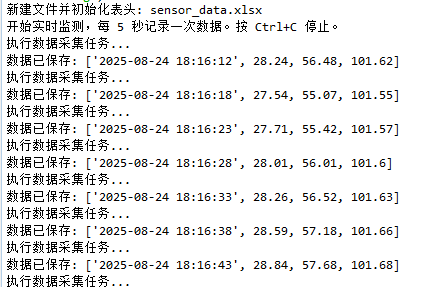
if __name__ == "__main__":# 創建記錄器實例logger = RealTimeExcelLogger('sensor_data.xlsx')# 開始運行,每5秒記錄一次logger.run(interval_seconds=5)以下是運行結果:
這是建立并已經寫入的excel文件
三、實際應用建議
-
批量寫入:?在高速數據采集場景(如每秒>10次),頻繁打開保存Excel文件會成為性能瓶頸。建議在內存中緩存一定數量的數據(例如一個
list存100條),達到閾值后再一次性寫入Excel,顯著減少I/O操作。 -
文件分割:?對于長期運行的任務,可以考慮按日期或文件大小自動分割Excel文件,避免單個文件過大導致打開緩慢或損壞。
-
替代方案 - 數據庫:?如果數據量非常大(百萬條以上)或需要復雜查詢,強烈建議使用數據庫(如SQLite, PostgreSQL, InfluxDB)作為主存儲,Excel僅用作導出和報表工具。數據庫在處理并發寫入、查詢和數據完整性方面遠勝于Excel。

)










:化繁為簡,Spring Boot自動配置的實現之秘)


)
![[Vid-LLM] docs | 視頻理解任務](http://pic.xiahunao.cn/[Vid-LLM] docs | 視頻理解任務)

![[Java惡補day51] 46. 全排列](http://pic.xiahunao.cn/[Java惡補day51] 46. 全排列)
