一、訓練過程
并行批量訓練機制
- 一次性輸入64個批次數據,創建64個獨立神經網絡并行訓練。
- 所有網絡共享參數(
Ω),更新時計算64個批次的平均損失,統一更新全局參數。
梯度更新策略
- 使用
torch.no_grad()上下文管理器清理反向傳播產生的臨時數據,優化內存利用。
- 使用
多輪訓練重要性
- 單輪訓練(6萬張圖片)僅能獲得19.22%正確率,需通過循環訓練集(如10輪)提升模型收斂性。
model.train()模式確保參數持續更新,避免重復初始化。
二、測試過程
測試集評估邏輯
- 輸入測試數據后,前向傳播得到預測結果,通過
argmax提取最大概率對應的類別。 - 統計預測正確的數量,計算正確率(Correct / Total Test Samples)。
- 輸入測試數據后,前向傳播得到預測結果,通過
損失值與正確率的關系
- 測試階段仍會計算損失值,但非核心指標;正確率(如70.04%)為模型性能的關鍵衡量標準。
資源管理優化
- 使用
with torch.no_grad()減少冗余計算,提升測試效率。
- 使用
三、關鍵實現細節
數據預處理
- 測試數據需明確設備(GPU/CPU),通過
to(device)確保設備一致性。
- 測試數據需明確設備(GPU/CPU),通過
預測結果處理
- 將預測概率轉換為類別標簽,對比真實標簽統計正確率。
訓練效率優化
- 設置打印間隔(如每100批次輸出一次損失值),平衡調試需求與訓練速度。
四、實踐要點
- 超參數調整:通過增加訓練輪數(如從10輪擴展至50輪)可顯著提升模型性能。
- 驗證集作用:測試集主要用于評估最終模型效果,而非實時調參。
- 競賽策略:合理分配訓練時間,確保比賽前完成高效模型迭代。
五、關鍵代碼片段
1. 批量梯度下降訓練核心代碼
# 初始化模型參數 Ω
model = MyNeuralNetwork().to(device) # device為'cuda'或'cpu'
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
criterion = torch.nn.CrossEntropyLoss() # 分類任務損失函數# 訓練循環
for epoch in range(num_epochs):for batch_idx, (inputs, labels) in enumerate(train_loader):# 前向傳播outputs = model(inputs)loss = criterion(outputs, labels)# 反向傳播 + 參數更新optimizer.zero_grad() # 清空梯度緩存loss.backward() # 反向傳播計算梯度optimizer.step() # 更新參數 Ω# 每100批次打印一次損失值if batch_idx % 100 == 0:print(f"Epoch {epoch}, Batch {batch_idx}: Loss = {loss.item()}")
2. 多輪訓練擴展
# 外層循環控制訓練輪數
for epoch in range(num_epochs):# 內層循環執行單輪訓練(6萬張圖片)for inputs, labels in train_loader:# ...(同上訓練邏輯)...# 每輪結束后測試模型test_accuracy = evaluate_model(model, test_loader)print(f"Epoch {epoch+1} Test Accuracy: {test_accuracy}")
3. 測試集評估代碼
def evaluate_model(model, test_loader):correct = 0total = 0with torch.no_grad(): # 禁用梯度計算以節省內存for inputs, labels in test_loader:inputs = inputs.to(device) # 確保數據在正確設備上labels = labels.to(device)outputs = model(inputs) # 前向傳播_, predicted = torch.max(outputs.data, 1) # argmax獲取預測類別total += labels.size(0) # 統計總樣本數correct += (predicted == labels).sum().item() # 統計正確數return correct / total # 返回準確率
4. 關鍵優化點說明
- 設備兼容性:通過
inputs.to(device)統一數據與模型的設備(CPU/GPU) - 資源管理:
with torch.no_grad()減少測試階段的內存占用 - 批量處理:64個批次并行訓練加速收斂(需調整
DataLoader的batch_size)
六、核心問題
- 訓練效率低:原模型使用隨機梯度下降(SGD)優化器,需100輪訓練才能達到98%正確率,耗時約10分鐘;改用Adam優化器后,僅需10輪訓練即可達到96.81%正確率。
梯度消失問題:Sigmoid激活函數的導數范圍(0~0.25)導致多層網絡參數更新停滯,損失值在局部震蕩無法收斂45。
七、關鍵知識點
1. 優化器改進:從SGD到Adam
- 原理:
- SGD每次用全部數據更新參數,易陷入局部最優且收斂慢;
- Adam通過自適應學習率和動量機制加速收斂,避免SGD的“高方差”問題。
代碼示例:
# 原SGD優化器(需修改)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 改為Adam優化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
2. 學習率影響
- 現象:固定學習率(如0.01)導致訓練后期損失值震蕩,無法逼近全局最優;
- 解決思路:動態調整學習率(如學習率衰減),但需后續章節展開。
3. 激活函數優化:Sigmoid → ReLU
- 梯度消失原因:
- Sigmoid導數范圍(0~0.25)導致多層網絡參數更新時梯度逐層衰減至0;
- 數學表達:
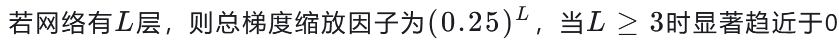
- ReLU優勢:

- 計算簡單,加速訓練
代碼示例:
# 原Sigmoid激活函數(需修改)
def sigmoid(x):return 1 / (1 + np.exp(-x))# 改為ReLU激活函數
def relu(x):return np.maximum(0, x)
八、實驗結果對比

九、擴展思考
- 深層網絡適配性:ReLU在超過3層的網絡中表現優異,是現代深度學習的基礎激活函數
- 優化器組合:AdamW(帶權重衰減的Adam)可緩解過擬合,適合遷移學習場景
:plt.pie() - 展示組成部分的餅圖)




—— Node.js介紹與入門)
)

進行c++開發的時,在debug時查看一個eigen數組內部的數值)










)