鏈接:https://github.com/yunlong10/Awesome-LLMs-for-Video-Understanding
docs:Vid-LLM
本項目是關于視頻大語言模型(Vid-LLMs)的全面綜述與精選列表。
探討了這些智能系統如何處理和理解視頻內容,詳細介紹了它們多樣的架構與訓練方法、旨在完成的特定任務,以及用于開發和評估的數據集與基準測試。
可視化
章節列表
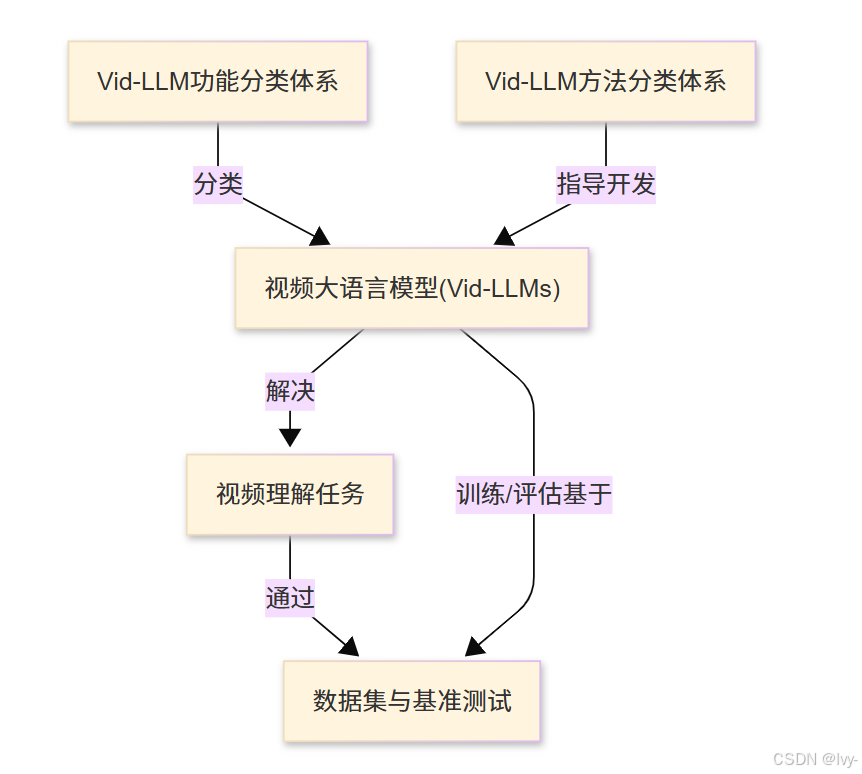
- 視頻大語言模型(Vid-LLMs)
- 視頻理解任務
- Vid-LLM方法分類體系
- Vid-LLM功能分類體系
- 數據集與基準測試
Why we need Vid-LLMs?
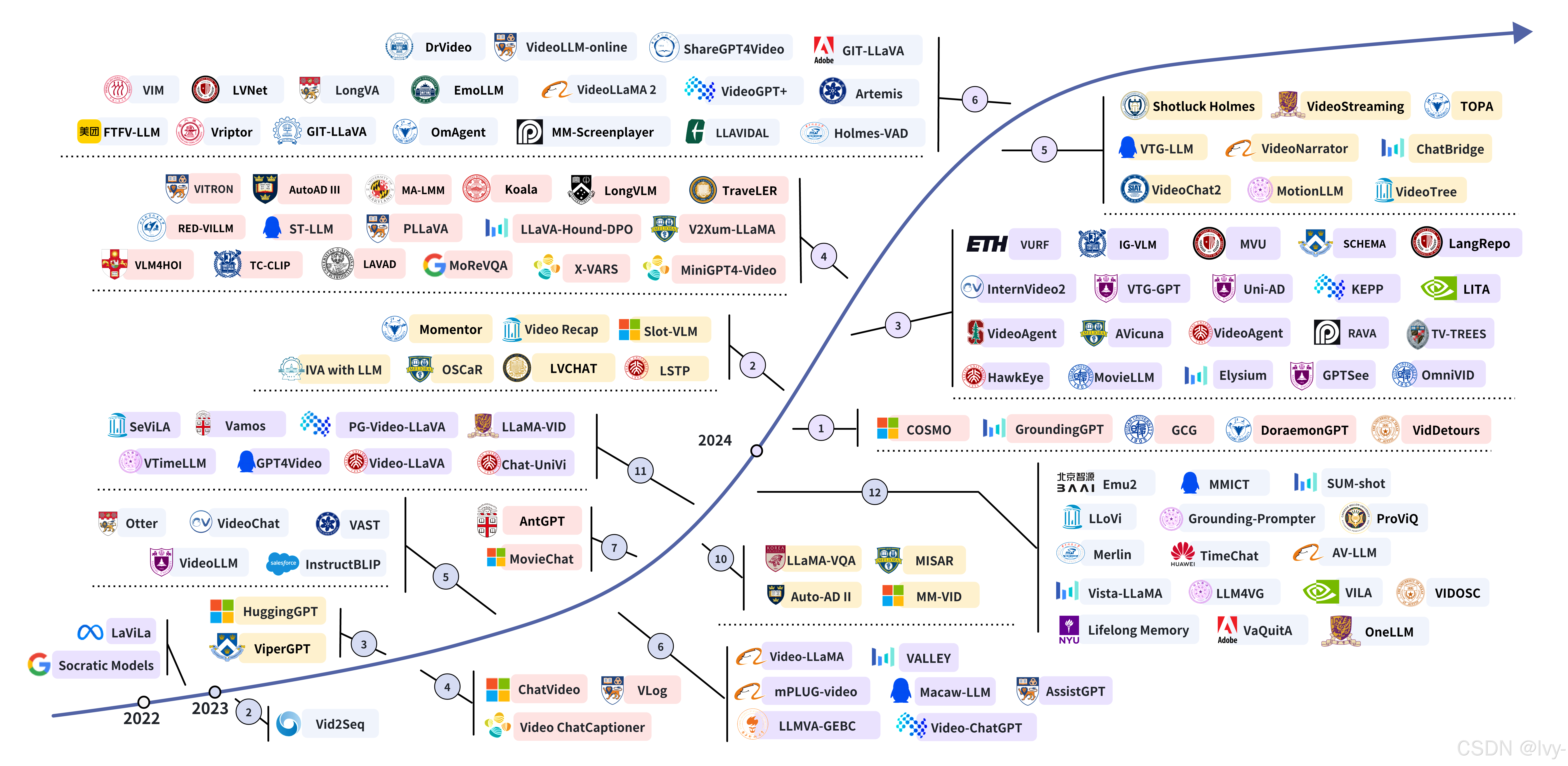
Vid-LLMs: Models
本文將介紹視頻大語言模型(Vid-LLMs)及其應用。
Vid-LLMs通過結合視覺處理和語言理解能力,使AI能夠"觀看"視頻并回答相關問題
-
文章概述了Vid-LLMs的工作原理:將視頻分解為關鍵信息,轉化為語言模型可理解的表征,再結合問題生成回答。
-
重點介紹了Vid-LLMs的核心優勢和多模態交互能力,并通過烹飪視頻示例展示了其問答功能。
-
最后簡要提及了視頻理解任務分類,包括識別當前內容和預測未來事件等應用場景。
該項目提供了Vid-LLMs的全面技術資料和資源列表。
第1章:視頻大語言模型(Vid-LLMs)
是否曾觀看視頻時,希望能像詢問知識淵博的朋友那樣直接向視頻提問?想象觀看烹飪教程時立即知道"主要食材有哪些?“,或是看到體育精彩片段時詢問"誰進的球?”
這聽起來像科幻情節,但得益于視頻大語言模型(Vid-LLMs),這正在成為現實~
Vid-LLMs解決什么問題?
我們已經擁有**大語言模型(LLMs)**這類神奇工具,如ChatGPT。
它們是能理解和生成類人文本的智能助手,可以創作故事、回答問題甚至協助編程。
但普通LLM僅能理解文本。對于視頻中的視覺和聽覺信息,它既"看不見"也"聽不到"。這是重大局限,因為世界上大量信息以視頻形式存在——從社交媒體片段到教學講座和安防錄像。
Vid-LLMs正是為此而生。它們賦予LLM"觀看"和真正理解視頻的能力,將其升級為能同時理解人類語言和動態視頻世界的超級智能助手。
Vid-LLMs究竟是什么?
Vid-LLMs是經過升級、具備視頻處理與推理能力的大語言模型。
通俗理解:
- 普通LLM如同只會讀寫的高智商人士
- Vid-LLM則是同一位智者,但獲得了眼睛和耳朵,可以看電視了!它能接收視頻中的所有視覺信息(發生的事件、場景人物、出現物體)和聽覺信息(聲音、語音)
這意味著Vid-LLMs能實現:
- 回答關于視頻內容的提問
- 總結長視頻的關鍵事件或主題
- 甚至根據觀察采取行動或給出指導
它們為視頻分析帶來類人理解能力,讓我們能用自然語言與視頻交互。
Vid-LLMs工作原理(簡化版)
要讓LLM"看見"視頻,需將復雜的視聽信息轉換為LLM能理解的格式:
- 視頻分解:視頻是隨時間變化的圖像序列(
幀),通常伴有聲音 - 關鍵信息提取:專用"視頻理解組件"(
智能視覺和音頻處理器)分析這些幀和聲音,識別物體、動作、場景和語音 - 語言化轉換:提取的視頻信息被轉化為"類語言"表征,雖非原始文本但能讓LLM與人類語言協同處理
- 語言模型接管:組合信息(您的文本問題+視頻"類語言"表征)輸入LLM,
由其強大的語言理解能力關聯信息并生成相關回答
應用場景實例
回到烹飪節目例子:
場景:有一段廚師做菜的教程視頻,您想知道:“這個食譜使用的主要食材是什么?”
Vid-LLM可以幫忙
輸入Vid-LLM:
- 視頻文件(如
cooking_tutorial.mp4) - 自然語言問題:“這個食譜使用的主要食材是什么?”
雖然實際Vid-LLM代碼非常復雜,但我們可以模擬其使用方式:
# 此為概念示例,非本項目實際可運行代碼
# 展示如何與Vid-LLM交互class VidLLMModel:def __init__(self):# 真實Vid-LLM會加載大型模型print("視頻大語言模型助手已就緒!")def ask_about_video(self, video_path: str, question: str) -> str:# 內部進行視頻處理和問題解答print(f"正在處理視頻:{video_path}")print(f"解析問題:'{question}'")# ...此處進行復雜的視頻分析和語言推理...# 基于視頻分析的模擬輸出if "ingredients" in question.lower() and "cooking_tutorial.mp4" in video_path:return "根據視頻分析,主要食材有面粉、雞蛋、糖、牛奶和巧克力豆。"elif "goal" in question.lower():return "視頻顯示10號球員在比賽0:45時進球。"else:return "需要更多視頻細節才能確定。"# 初始化Vid-LLM助手
my_vid_llm = VidLLMModel()# 詢問烹飪視頻
video_file = "cooking_tutorial.mp4" # 視頻文件路徑
question_text = "這個食譜使用的主要食材是什么?"answer = my_vid_llm.ask_about_video(video_file, question_text)
print(f"\nVid-LLM回答:{answer}")
輸出:
視頻大語言模型助手已就緒!
正在處理視頻:cooking_tutorial.mp4
解析問題:'這個食譜使用的主要食材是什么?'Vid-LLM回答:根據視頻分析,主要食材有面粉、雞蛋、糖、牛奶和巧克力豆。
此例中,VidLLMModel會"觀看"烹飪教程視頻,識別動作和物體(如混合食材),理解問題后給出詳細回答,就像有位智能朋友陪您看視頻并講解內容!
原理淺析
Vid-LLM如何處理視頻并關聯問題?通過序列圖簡化說明:
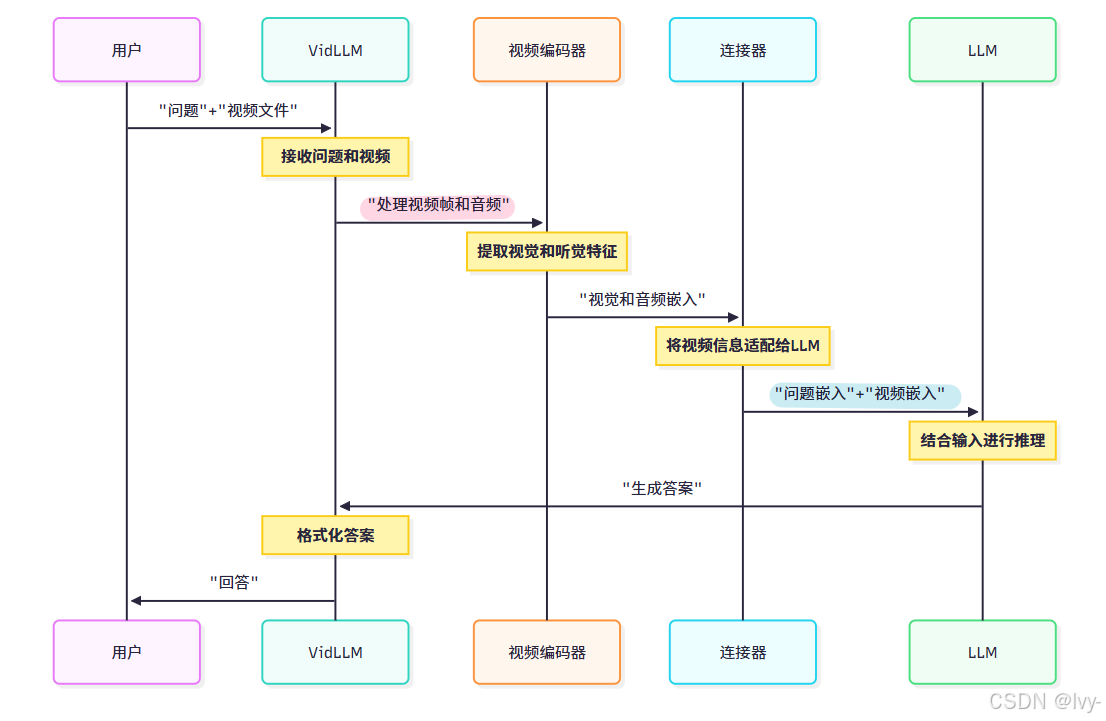
流程解析:
- 用戶:提出問題和提供視頻
- Vid-LLM:總體協調系統
- 視頻編碼器:Vid-LLM的"眼睛和耳朵",處理原始視頻(像素和聲波),提取表征視頻內容的"特征"或"嵌入"(數值化表示)
- 連接器:對齊視頻嵌入和語言模型能理解的文本嵌入,充當橋梁
- LLM:實際推理的大腦,結合問題和視頻信息生成連貫回答
Vid-LLMs核心優勢
結合兩大領域的優勢:
| 特性 | 優勢 |
|---|---|
| 多模態理解 | 能處理和理解視頻(視覺+聽覺)與文本的多源信息 |
| 上下文推理 | 可在動態視頻語境中推理事件、物體和動作 |
| 自然語言交互 | 讓用戶用日常語言與視頻互動,簡化復雜任務 |
| 多功能任務 | 能執行從摘要生成到問答和內容創作等廣泛任務 |
結語
本章介紹了激動人心的視頻大語言模型(Vid-LLMs)世界。我們了解到它們是能"觀看"、"聆聽"和"理解"視頻的先進AI模型,彌合了動態視覺內容與強大語言推理間的鴻溝。
這項能力開啟了用自然語言與視頻信息交互并提取洞察的新紀元。
現在您已了解Vid-LLMs的基礎知識,讓我們繼續探索它們能解決的具體問題和應用場景。
下一章:視頻理解任務
第2章:視頻理解任務
在前一章中,我們介紹了視頻大語言模型(Vid-LLMs)——這種神奇的AI助手能夠像知識淵博的朋友一樣"觀看"、"聆聽"和"理解"視頻內容,彌合了動態視覺內容與強大語言推理之間的鴻溝。
但當Vid-LLM具備"視覺"和"聽覺"能力后,我們究竟能讓它完成哪些具體任務?這些智能系統被設計來解決什么問題?
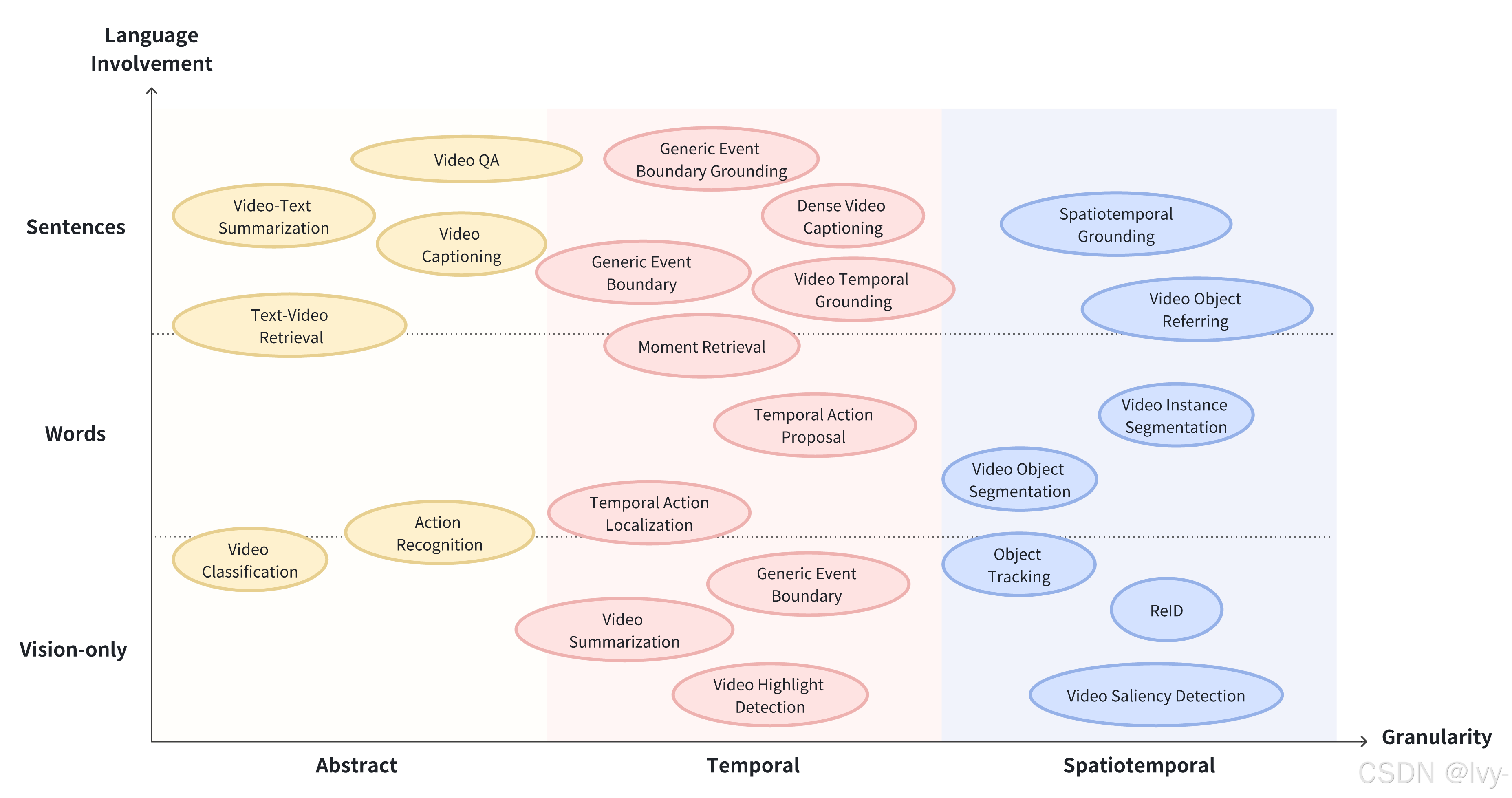
什么是視頻理解任務?
視頻理解任務是指Vid-LLMs經過訓練后能夠應對的具體挑戰、問題或疑問。
它們是Vid-LLM用來展示其視頻理解能力的各種"測試"。
假設我們擁有數小時的監控錄像、冗長的教學講座或家庭視頻集錦。我們不會簡單地要求Vid-LLM"理解這個視頻",而是會設定具體目標:“找出我的狗什么時候開始吠叫”、“總結這個講座的要點"或"告訴我視頻里我的孩子在搭建什么”。
這些具體目標就是我們所說的視頻理解任務。讓我們詳細解析其中最常見和最重要的幾類:
1. 識別:發生了什么?
描述:這項任務涉及識別并標注視頻中出現的物體、動作和事件。就像一位細致的觀察者,詳盡列出所見的所有細節。
類比:想象正在觀看一個繁忙的街景。執行"識別"任務的Vid-LLM會告訴你:“有一輛紅色汽車駛過,一個人在遛狗,還有一個街頭小販在賣椒鹽卷餅。”
概念性輸入與輸出:
- 輸入Vid-LLM:視頻片段和通用問題,如"畫面中有哪些物體?“或"正在發生什么動作?”
- 預期輸出:檢測到的物體列表(如"
汽車"、"行人"、"狗"、"樹")或動作列表(如"駕駛"、“行走”、“奔跑”、“交談”)
2. 預測:接下來會發生什么?
描述:這項任務需要根據視頻已發生的內容預測未來事件或動作。要求Vid-LLM理解事件模式和邏輯序列。
類比:如果看到有人拿起棒球棒站在本壘板旁,我們可能預測他即將揮棒。Vid-LLM對視頻內容進行類似的預測。
概念性輸入與輸出:
- 輸入Vid-LLM:展示當前情境的視頻片段和問題,如"這個人接下來會做什么?“或"可能會發生什么后續事件?”
- 預期輸出:對未來動作或事件的預測(如"
這個人可能會往鍋里倒水"或"汽車很可能在十字路口左轉")
3. 描述與字幕生成:描述這個視頻
描述:這項任務專注于生成類人的敘述性文本,用于總結或描述視頻內容。輸出范圍可以從簡潔的短字幕到詳細的事件段落描述。
類比:想象紀錄片旁白或新聞視頻的文字記者。Vid-LLM扮演這個敘述者角色,根據畫面和聲音創作故事。
概念性輸入與輸出:
- 輸入Vid-LLM:視頻文件和請求,如"詳細描述這個視頻"或"為這個片段生成簡短字幕"
- 預期輸出:描述視頻內容的自然語言句子或段落(如"一只金毛尋回犬在郁郁蔥蔥的公園里歡快地玩接球游戲,撿回主人拋出的紅色球"或"視頻展示了從混合原料、揉面到最終烘焙的面包制作分步教程")
4. 定位與檢索:找到那個瞬間!
描述:這項任務是在視頻中查找與給定文本查詢匹配的特定時刻或片段。就像擁有一個能在視頻內部工作的超級搜索引擎。
類比:想在電影中找到某個角色說特定臺詞的精確場景。通過描述查找內容,定位與檢索功能可以實現這一點。
概念性輸入與輸出:
- 輸入Vid-LLM:視頻文件和文本查詢,如"展示廚師加鹽的時刻"或"找出所有出現藍色汽車的片段"
- 預期輸出:精確時間戳(如"0:45-0:48")或指向特定視頻片段的鏈接
5. 問答:關于X在Y中的情況?
描述:這是最復雜的任務之一,Vid-LLM需要回答關于視頻內容的詳細且復雜的問題,要求對事件、物體及其隨時間變化的關系進行深度推理和理解。
類比:就像擁有一位真正博學的朋友,他不僅知道"發生了什么",還能回答"為什么會發生"或"兩個事件之間的關系是什么"。
概念性輸入與輸出:
- 輸入Vid-LLM:視頻文件和復雜問題(如"為什么這個人選擇那種特定木材做項目?“或"運動員在最后階段面臨的主要挑戰是什么?”)
- 預期輸出:基于視頻內容的
綜合性自然語言回答(如"這個人選擇那種木材是因為它以防腐和耐潮濕著稱,這對戶外家具很重要"或"運動員在最后一英里遭遇強逆風,導致速度略有下降")
視頻理解任務總結
以下是討論任務的快速概覽:
| 任務類別 | 功能描述 | 示例交互 |
|---|---|---|
| 識別 | 識別視頻中的物體、動作和事件 | “狗在做什么?” -> “狗在接球” |
| 預測 | 根據當前視頻事件預測后續發展 | “這個人接下來會烹飪什么?” -> “可能會切菜” |
| 描述與字幕生成 | 生成視頻內容的類人文本摘要或描述 | “描述這個視頻” -> “湖面日出的寧靜景象” |
| 定位與檢索 | 查找與文本查詢匹配的特定視頻片段 | “找出汽車左轉的時刻” -> “發生在0:23-0:25” |
| 問答 | 回答需要視頻內容推理的復雜問題 | “機器人為什么停止?” -> “檢測到障礙物” |
結語
本章我們學習了Vid-LLMs設計用于應對的各種視頻理解任務。
實現:識別,預測,描述與字幕生成,定位與檢索,問答。
每項任務都代表了我們用自然語言與視頻內容交互并提取價值的不同方式。
既然我們已經了解Vid-LLM能做什么,接下來讓我們深入探討它們如何被構建和組織以實現這些能力。
下一章:Vid-LLM方法分類體系

![[Java惡補day51] 46. 全排列](http://pic.xiahunao.cn/[Java惡補day51] 46. 全排列)



)







-理解筆記3)





)