地址:Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
摘要
大型語言模型(LLM)能夠編碼豐富的世界語義知識,這類知識對于機器人執行自然語言表達的高層級、時間擴展指令具有重要價值。然而,語言模型的一大顯著缺陷是缺乏現實世界經驗,這使其難以在特定實體(如機器人)中用于決策。例如,讓語言模型描述如何清理灑出的液體,可能會得到合理的敘述,但該敘述未必適用于特定智能體(如機器人)在特定環境中執行此任務的場景。本文提出通過預訓練技能實現現實世界接地:利用預訓練技能約束模型,使其提出既可行又符合上下文的自然語言動作。其中,機器人可作為語言模型的 “手和眼”,而語言模型則為任務提供高層級語義知識。我們展示了如何將低層級技能與大型語言模型結合:語言模型提供執行復雜、時間擴展指令的高層級流程知識,而與這些技能相關的價值函數則提供必要的接地能力,將該知識與特定物理環境關聯。我們在多個現實世界機器人任務上評估了該方法,結果表明現實世界接地的必要性,且該方法能夠讓移動操作機器人完成長時程、抽象的自然語言指令。項目網站、演示視頻及桌面領域的開源代碼可在this https URL獲取。
概述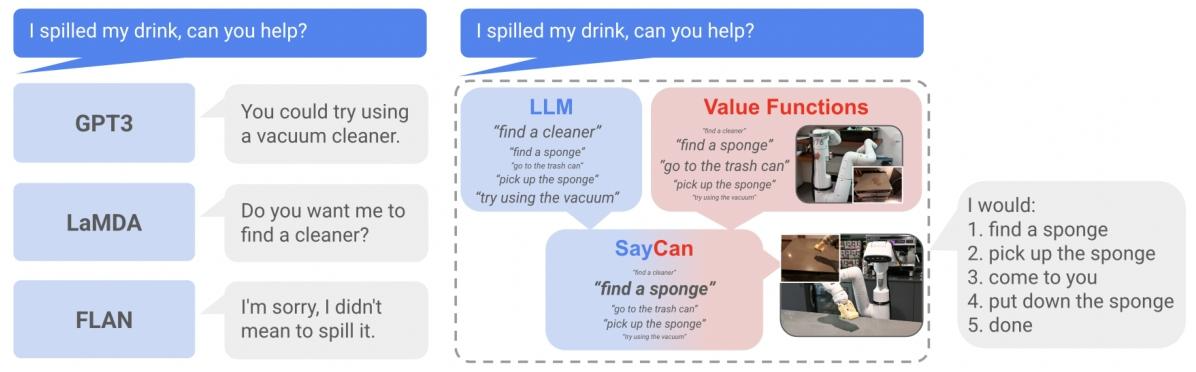
1. 研究背景與問題
- LLM 的優勢與局限:LLM 從海量文本中學習到豐富的語義知識,能理解高層級任務指令,但無物理世界交互經驗,輸出可能 “不落地”(如建議機器人用 “吸塵器清理灑出的飲料”,但場景中無吸塵器或機器人無法操作)。
- 核心挑戰:如何讓具身智能體(如機器人)提取并利用 LLM 的知識,將抽象語言指令轉化為符合自身能力和當前環境的可執行動作序列。
2. 解決方案:SayCan 方法
SayCan 的核心是 “Say(說)” 與 “Can(做)” 的協同:
- Say(LLM 的角色):提供 “任務接地”,通過語義知識判斷低層級技能對高層級任務的相關性(即 “該技能是否有助于完成任務”),量化為概率
i為用戶指令)。 - Can(價值函數的角色):提供 “世界接地”,通過預訓練的價值函數判斷技能在當前環境狀態下的可行性(即 “機器人能否成功執行該技能”),量化為概率
s為當前狀態, - 協同邏輯:技能的綜合優先級由兩者乘積決定
,迭代選擇最優技能執行,直至輸出 “done” 終止。
3. 實驗驗證與關鍵結果
-
實驗設置:
- 環境:模擬廚房(技能訓練環境)和真實辦公廚房(泛化測試環境);
- 機器人:Everyday Robots 的移動操作機器人(7 自由度機械臂 + 兩指夾爪);
- 任務:7 類共 101 個指令(單原語、抽象名詞 / 動詞、結構化語言、具身狀態、眾包指令、長時程任務);
- 評估指標:計劃成功率(技能序列是否符合任務目標)、執行成功率(機器人是否實際完成任務,均由 3 名人類標注者多數投票判定)。
-
核心結果:
- 接地有效性:在模擬廚房中,SayCan(基于 PaLM-540B)實現 84% 計劃成功率和 74% 執行成功率;真實廚房中為 81% 計劃成功率和 60% 執行成功率,接地機制使性能較無接地基線接近翻倍。
- LLM 規模影響:LLM 參數越大,機器人性能越好 ——PaLM-540B(84% 計劃成功率)優于 PaLM-62B(72%)和 PaLM-8B(38%),且 PaLM 系列優于同等規模的 FLAN(70% 計劃成功率)。
- 擴展能力:支持添加新技能(如抽屜操作,計劃成功率 100%)、鏈式思維處理否定指令(如 “帶無咖啡因的果味飲料”)、多語言指令(中 / 法 / 西語計劃成功率接近 100%)。
4. 局限性與未來方向
- 局限性:繼承 LLM 的訓練偏差;技能范圍和魯棒性是系統瓶頸;無法動態調整技能失敗后的策略。
- 未來方向:利用機器人現實經驗反哺 LLM(提升事實性與物理常識);擴展接地來源(非機器人場景);探索自然語言作為機器人編程本體的合理性。
一、論文動機
1. LLM 缺乏 “世界接地”:輸出技能無法執行
LLM 僅通過文本學習語義知識,無物理世界交互經驗,導致其生成的技能序列可能與機器人能力或當前環境沖突,無法實際執行。例如,用戶要求 “清理灑出的飲料” 時,LLM 可能建議 “用吸塵器”,但場景中無吸塵器或機器人無法操作吸塵器(1-4、1-13);或生成 “去商店買蘋果” 這類脫離機器人能力范圍的抽象步驟,無法轉化為具體動作(1-26)。
2. 傳統策略缺乏 “任務接地”:無法理解高層級指令
單純的行為克隆(BC)或強化學習(RL)策略僅能執行低層級、固定的技能(如 “拾取蘋果”),無法解析高層級、抽象的自然語言指令(如 “拿一個健康的零食”)。例如,BC 策略直接輸入 “補充米餅” 這類抽象指令時,無法拆解為 “找米餅→拾取→放置到操作臺” 的序列,執行成功率為 0%(1-69、1-73);且無法動態調整策略以適應長時程任務(如 “扔可樂 + 拿清潔用品”)(1-67)。
3. 技能選擇無動態可行性判斷:難以應對環境變化
傳統 LLM 生成模式(如直接輸出動作文本)僅考慮 “任務相關性”,忽略 “環境可行性”,導致技能選擇僵化。例如,機器人已持有蘋果時,LLM 仍可能因 “拿蘋果” 的任務相關性高而選擇該技能,造成冗余或失敗;或在無目標物體的場景中,仍輸出 “拾取” 技能(1-30、1-70)。
4. 系統擴展性差:新技能、多語言等需求適配成本高
傳統機器人系統添加新技能(如抽屜操作)需重構策略網絡,處理多語言指令需額外訓練多語言模型,無法利用 LLM 的現有能力快速適配。例如,新增 “打開抽屜” 技能時,傳統方法需重新采集數據、訓練獨立模型,而無法通過簡單擴展技能描述實現(1-80、1-99);且對否定指令(如 “不要蘋果”)、模糊指代(如 “拿那個紅色的”)處理能力不足(1-67、1-96)。
二、設計架構
SayCan 的核心原理是通過 “雙接地機制” 將 LLM 的抽象語義知識與機器人的物理執行能力綁定,解決 “語言不落地” 問題,具體邏輯如下:
1. 核心概念定義
- 技能(Skill, π):機器人的低層級原子行為(如 “找海綿”“拿起海綿”),每個技能包含:
- 語言描述
- 執行策略(控制機器人完成動作的算法,由行為克隆 BC 或強化學習 RL 訓練);
- 可供性函數
s下技能成功執行的概率)。
- 語言描述
- 任務接地(Task Grounding):由 LLM 計算
?_π是完成指令i的有效步驟的概率”,本質是利用 LLM 的語義知識關聯 “任務目標” 與 “技能用途”。 - 世界接地(World Grounding):由價值函數計算
s下,機器人成功執行技能?_π的概率”,本質是將技能與物理環境的可行性綁定。
2. 概率協同邏輯
SayCan 的技能選擇基于 “綜合概率最大化”,公式推導如下:
- 目標:選擇 “既能推進任務,又能成功執行” 的技能,即最大化 “技能成功執行且推進任務” 的概率
- 分解假設:若技能成功(
- 最終公式:
3. 迭代執行流程
- 輸入用戶指令
i和當前環境狀態s; - LLM 對所有預訓練技能的
- 價值函數模塊對所有技能評分,得到
- 計算每個技能的綜合概率,選擇概率最大的技能執行;
- 將已執行的
s; - 重復步驟 2-5,直至 LLM 輸出 “done”(終止令牌)。
三、訓練方法
SayCan 的實現需分三部分:預訓練技能與價值函數、LLM 適配、技能選擇與執行,具體方法如下:
1. 預訓練技能與價值函數
(1)技能策略訓練
- 訓練方法:結合行為克隆(BC)和強化學習(RL),按需選擇:
- BC 策略:基于 BC-Z 方法,用 10 臺機器人 11 個月收集的 6.8 萬條遠程操作演示數據,輔以 12 萬條成功的自主執行數據訓練;采用 ResNet-18 架構,以 “通用句子編碼器(USE)” 生成的
?_π嵌入作為 FiLM 條件,輸出機械臂位姿、夾爪狀態和終止動作。 - RL 策略:基于 MT-Opt 方法,在仿真環境中訓練(用 RetinaGAN 減少 sim-to-real 差距),通過 “仿真演示初始化 + 在線數據迭代優化” 提升性能;架構類似 MT-Opt,輸入圖像、
?_π嵌入、機器人狀態(如夾爪高度),輸出 Q 值。
- BC 策略:基于 BC-Z 方法,用 10 臺機器人 11 個月收集的 6.8 萬條遠程操作演示數據,輔以 12 萬條成功的自主執行數據訓練;采用 ResNet-18 架構,以 “通用句子編碼器(USE)” 生成的
- 多任務優化:不單獨為每個技能訓練策略,而是訓練 “語言條件的多任務模型”,降低訓練成本(支持 551 個技能,涵蓋拾取、放置、導航等 7 類)。
(2)價值函數訓練
- 本質定義:稀疏獎勵下的 “技能成功概率”—— 任務完成時獎勵為 1,否則為 0,價值函數
Q^π(s,a)即 “從狀態s執行動作a后,遵循策略π的折扣獎勵和”,對應技能成功概率。 - 訓練方法:基于時序差分(TD)的 RL 方法,最小化以下 TD 損失:
其中L_TD(θ) = E_{(s,a,s')~D} [ R(s,a) + γ·E_{a*~π} Q_θ^π(s',a*) - Q_θ^π(s,a) ]D為狀態 - 動作數據集,θ為 Q 函數參數,γ為折扣因子,R(s,a)為稀疏獎勵(0 或 1)。 - 可行性校準:對不同技能的價值函數結果進行歸一化(如拾取技能
2. LLM 適配:從 “生成” 到 “評分”
LLM 默認生成自由文本,需通過以下方法約束其輸出為 “機器人可執行的技能序列”:
- 提示工程(Prompt Engineering):在 LLM 輸入中加入示例(如 “人類:幫我拿蘋果?機器人:1. 找蘋果,2. 拿蘋果,3. 遞給你,4.done”),定義 “人類指令 - 機器人技能序列” 的對話格式,約束輸出結構(附錄 D.3 提供 17 個示例的完整 Prompt)。
- 評分模式(Scoring Mode):不使用 LLM 的 “生成模式”(避免輸出無效動作),而是用 “評分模式” 計算每個預定義
i的下一步” 的置信度。 - 迭代上下文更新:每次選擇技能后,將其追加到 LLM 的對話歷史(如 “機器人:1. 找海綿,2.XXX”),確保 LLM 理解任務進度,避免重復或無關技能。
3. 系統集成與執行
- 語言條件輸入:技能的策略和價值函數均以 “USE 嵌入的
- 環境反饋機制:通過價值函數實時獲取環境狀態
s(如物體位置、機器人位姿),確保技能可行性判斷的時效性;若技能執行失敗(如未拿起物體),價值函數會降低該技能的后續評分。 - 終止判斷:為 “done” 技能設置固定低可行性(
p_{terminate}^{affordance}=0.1),僅當所有有效技能的綜合概率均低于 “done” 時,系統終止任務。
四、數據集
論文中數據集主要服務于低層級技能的策略訓練(行為克隆 BC、強化學習 RL)?和系統性能評估,具體來源可分為三類:訓練數據集(BC/RL 策略)、評估數據集(101 個指令),兩類數據集的采集場景、方式和規模均有明確界定。
1. 訓練數據集:技能策略與價值函數訓練
訓練數據集用于學習機器人的低層級技能(如拾取、放置、導航)及其對應的價值函數,分為行為克隆(BC)策略訓練數據和強化學習(RL)策略訓練數據兩類,均圍繞 “廚房場景中的機器人操作” 展開。
(1)行為克隆(BC)策略訓練數據
BC 策略的數據以 “真實機器人遠程操作演示” 為核心,輔以 “自主執行數據” 擴充規模,具體來源如下:
- 核心演示數據:通過 10 臺機器人組成的機器人 fleet,在 11 個月內持續采集的68000 條遠程操作演示數據。采集時,操作員使用 VR 頭顯控制器追蹤手部動作,動作被映射為機器人末端執行器的位姿;同時可通過操縱桿控制機器人底座移動,確保演示覆蓋 “拾取 - 放置 - 導航” 等核心技能場景(如廚房中的物體搬運、位置移動)。
- 自主執行擴充數據:為提升數據規模和多樣性,補充了276000 條機器人自主執行的技能 episode(即機器人按已學策略執行技能的過程記錄)。對這些自主數據進行 “成功篩選”—— 僅保留人類標注為 “成功完成技能” 的 episode,最終得到12000 條有效自主數據,與核心演示數據合并用于 BC 訓練。
(2)強化學習(RL)策略訓練數據
RL 策略的數據以 “仿真環境數據” 為主,通過 “仿真 - 真實遷移” 技術減少環境差異,具體來源如下:
- 仿真演示初始化數據:在 Everyday Robots 模擬器中,生成技能演示數據(如 “打開抽屜”“拾取可樂罐” 的標準動作序列),用于初始化 RL 策略的基礎性能,避免策略從 “零經驗” 開始學習導致的收斂緩慢。
- 在線仿真迭代數據:初始化后,通過 3000 個 CPU worker 持續在仿真環境中采集在線 episode 數據(機器人執行技能的實時過程記錄),并基于這些數據迭代優化 RL 策略。同時,為縮小 “仿真 - 真實” 環境差距,使用RetinaGAN技術對仿真環境的圖像進行處理 —— 讓仿真圖像更接近真實場景,同時保留物體結構特征,確保 RL 策略遷移到真實機器人時性能穩定。
(3)價值函數訓練數據
價值函數(用于判斷技能可行性)的數據與策略訓練數據共享:BC 策略的價值函數基于 BC 訓練數據的 “成功 / 失敗標簽” 學習,RL 策略的價值函數則直接使用 RL 訓練數據中的稀疏獎勵(任務成功為 1,失敗為 0)進行時序差分(TD)學習,無需額外采集獨立數據、、。
2. 評估數據集:101 個機器人任務指令
評估數據集用于驗證 SayCan 系統在真實場景中的性能,包含7 類共 101 個自然語言指令,來源兼顧 “標準化” 和 “自然性”,具體如下:
- 眾包指令:通過 Amazon Mechanical Turk(MTurk)平臺向人類用戶征集 —— 向用戶描述 “廚房場景事件”(如 “蘋果被移到你面前”),讓用戶以自然語言向機器人下達任務;同時在真實辦公廚房中,讓工作人員基于機器人能力下達指令,最終得到 15 條非結構化眾包指令、。
- 基準參考指令:參考現有機器人語言指令基準(如 ALFRED、BEHAVIOR),設計結構化、可對比的指令(如 “把米餅移到遠操作臺”),確保評估結果可與現有方法對標。
- 自定義測試指令:為覆蓋特定能力測試目標(如 “具身狀態理解”“長時程推理”),人工設計 56 條指令,包括:
- 單原語指令(如 “放開可樂罐”,15 條);
- 抽象名詞 / 動詞指令(如 “給我拿一個水果”“補充米餅”,各 15 條);
- 具身狀態指令(如 “把可樂放操作臺上”,初始狀態不同,11 條);
- 長時程指令(如 “可樂灑了,扔掉并拿清潔用品”,15 條)、至。
五、實驗設計
1. 系統模塊組成
| 模塊名稱 | 功能描述 | 關鍵技術 / 工具 |
|---|---|---|
| LLM 模塊(Say) | 計算技能與任務的相關性 | PaLM-540B/62B/8B、FLAN,提示工程 |
| 價值函數模塊(Can) | 計算技能在當前狀態的可行性 | TD 強化學習、多任務價值網絡 |
| 技能庫 | 存儲機器人的低層級原子技能,包含 | BC-Z(策略)、MT-Opt(策略) |
| 執行控制模塊 | 解析最優技能,控制機器人執行動作,更新環境狀態和 LLM 上下文 | 移動操作機器人控制棧 |
2. 實驗細節與關鍵對比
(1)實驗環境與任務
- 環境:
- 模擬廚房:與技能訓練環境一致,包含 5 個語義位置(2 個操作臺、桌子、垃圾桶、用戶位置)和 15 類廚房物體;
- 真實廚房:辦公場景真實廚房,環境更復雜(物體位置不固定、干擾物更多)。
- 任務分類(7 類共 101 個,示例見表 1):
任務類別 數量 核心測試目標 示例指令 NL Single Primitive 15 單技能指令的識別與終止 “放開可樂罐” NL Nouns 15 抽象名詞(如 “水果”)的理解 “給我拿一個水果” NL Verbs 15 抽象動詞(如 “補充”)的理解 “把米餅補充到遠操作臺” Structured Language 15 結構化指令與自然語言的對比 “把米餅移到遠操作臺” Embodiment 11 環境 / 機器人狀態的理解(如手中是否有物體) “把可樂放在操作臺上”(初始狀態不同) Crowd-Sourced 15 非結構化自然指令的適配 “我最喜歡紅牛,幫我拿一罐” Long-Horizon 15 長時程多步驟推理 “可樂灑在桌子上,扔掉它并拿清潔用品”
(2)關鍵對比實驗(Ablation Study)
通過對比不同方案,驗證接地機制和 LLM 的必要性:
| 方案 | 核心邏輯 | 總計劃成功率 | 總執行成功率 | 結論 |
|---|---|---|---|---|
| PaLM-SayCan(本文) | 結合 LLM 的 | 84% | 74% | 雙接地機制效果最優 |
| No VF(無價值函數) | 僅用 LLM 選擇 | 67% | - | 世界接地不可或缺,否則技能可能無法執行 |
| Generative(生成模式) | LLM 生成自由文本,再通過 USE 嵌入匹配到最近技能 | 74% | - | 評分模式優于生成模式,生成模式丟失概率信息,可解釋性差 |
| BC NL(無 LLM) | 直接將指令i輸入 BC 策略,無技能序列規劃 | 0% | 0% | LLM 的任務接地是必要的,單純行為克隆無法理解高層級指令 |
| BC USE(無 LLM) | 將指令i通過 USE 嵌入匹配到最近技能序列,無動態規劃 | 9% | 9% | 僅單技能任務有效(60%),無法處理長時程或抽象任務 |
3. 擴展能力驗證
- 添加新技能:以 “抽屜操作” 為例,僅需添加 “打開抽屜”“關閉抽屜” 等
- 鏈式思維(Chain of Thought):通過 Prompt 添加 “Explanation” 環節(如 “用戶要無咖啡因的果味飲料,我選青檸蘇打”),讓 LLM 先推理再輸出技能,解決否定指令(如 “不要蘋果”)和復雜推理問題,示例見表 4。
- 多語言支持:利用 LLM 的多語言訓練數據,無需額外適配即可處理中、法、西語指令,計劃成功率接近 100%(僅 1 條法語指令失敗,源于語法復雜度)。
4. 局限性與未來方向
(1)當前局限性
- LLM 繼承問題:繼承 LLM 的訓練偏差(如對特定物體的偏好)和常識錯誤(如物理規律誤解);
- 技能瓶頸:系統性能受限于技能庫的范圍和魯棒性(如抽屜操作執行成功率低,無 “擦拭” 技能);
- 閉環能力弱:無法動態應對技能失敗(如未拿起物體時,不會調整策略重新嘗試);
- 否定與歧義處理不足:雖可通過鏈式思維改善,但對復雜否定(如 “不要甜的且無咖啡因的飲料”)和模糊指代(如 “拿那個紅色的”)仍存在困難。
(2)未來研究方向
- 雙向反饋:利用機器人的現實執行經驗微調 LLM,提升 LLM 的物理常識和事實性;
- 技能擴展:開發更魯棒的多模態技能(如基于視覺的動態物體抓取),降低技能庫的局限性;
- 閉環規劃:結合環境反饋(如物體檢測、人類糾正)實現動態策略調整,參考 “Inner Monologue” 方法;
- 本體探索:驗證自然語言作為機器人編程本體的合理性,對比 “圖像目標” 等其他本體的效率。
六、評價指標
論文采用2 個核心指標量化系統性能,覆蓋 “計劃合理性” 與 “執行有效性”,均通過 “人類標注” 確保客觀,具體定義與計算方式如下:
1. 核心指標 1:計劃成功率(Plan Success Rate)
- 定義:衡量 “SayCan 輸出的技能序列是否能完成用戶指令目標”,不考慮機器人實際執行結果(僅評估 “計劃邏輯”)。
- 評估方式:
- 向 3 名標注者提供 “用戶指令 + 技能序列”(如 “拿清潔用品”+“1. 找海綿→2. 拿海綿→3. 遞給你”);
- 標注者判斷 “該序列是否能達成指令目標”,允許 “多解”(如先扔可樂再拿海綿也視為有效);
- 統計 “2/3 標注者同意成功” 的任務占比,即為計劃成功率。
- 核心結果:PaLM-SayCan 在模擬廚房中達 84%,真實廚房中 81%,無接地對照組(No VF)僅 67%。
2. 核心指標 2:執行成功率(Execution Success Rate)
- 定義:衡量 “SayCan 系統(含機器人執行)是否實際完成用戶指令”,需結合 “計劃合理性” 與 “機器人操作精度”。
- 評估方式:
- 向 3 名標注者提供 “用戶指令 + 機器人執行完整視頻”;
- 標注者回答 “機器人是否達成指令描述的任務”,忽略 “微小操作誤差”(如物體放置偏移但未影響目標);
- 統計 “2/3 標注者同意成功” 的任務占比,即為執行成功率。
- 核心結果:PaLM-SayCan 在模擬廚房中達 74%,真實廚房中 60%,無 LLM 對照組(BC NL)為 0%。
3. 輔助分析指標
- 誤差來源:65% 的失敗源于 LLM(如早期終止、否定指令處理錯誤),35% 源于價值函數(如誤判技能可行性);
- LLM 規模關聯:PaLM-540B(74% 執行成功率)> PaLM-62B(72%)> PaLM-8B(38%),證明 LLM 規模與機器人性能正相關。
七、創新點分析
1. 創新 1:雙接地機制(Task Grounding + World Grounding),解決 LLM 與機器人的接地斷層
這是論文最核心的創新,通過 “LLM 的任務接地” 與 “價值函數的世界接地” 協同,讓技能同時滿足 “任務相關性” 與 “環境可行性”:
- 任務接地(Say):利用 LLM 的語義知識,計算技能描述(
?_π)與用戶指令(i)的相關性概率p(?_π | i),回答 “該技能是否有助于完成任務”。例如,指令 “清理灑出飲料” 時,LLM 會優先選擇 “找海綿”(p高)而非 “拿可樂”(p低),實現任務層面的接地(1-14、1-25)。 - 世界接地(Can):利用強化學習訓練的價值函數,計算技能在當前環境狀態(
s)下的可行性概率p(c_π | s, ?_π),回答 “該技能能否成功執行”。例如,場景中無吸塵器時,“用吸塵器” 的p為 0,避免選擇無效技能;基于距離的導航價值函數(如 “去桌子” 的概率隨距離減小而升高)確保技能可行(1-14、1-22、1-32)。 - 協同邏輯:通過概率乘積(
p(c_i | i,s,?_π) ∝ p(c_π | s,?_π) × p(?_π | i))選擇最優技能,既保證技能符合任務目標,又確保可執行,解決了 “LLM 輸出不可行” 和 “策略無任務理解” 的雙重問題(1-25、1-33)。實驗驗證,該機制使性能較無接地基線(如 No VF、Generative)接近翻倍(1-73)。
2. 創新 2:基于 “評分模式” 的 LLM 適配,提升技能選擇的可解釋性與準確性
摒棄 LLM 的 “自由生成模式”,采用 “評分模式” 計算技能概率,解決生成模式 “丟失概率信息、可解釋性差” 的問題:
- 評分模式設計:讓 LLM 對預定義的技能描述(
?_π)逐一評分,輸出p(?_π | i),而非生成自由文本。例如,指令 “拿清潔用品” 時,LLM 直接計算 “找海綿”“找抹布” 等技能的概率,而非生成 “去廚房拿清潔工具” 這類模糊表述(1-27、1-30)。 - Prompt 工程約束:通過添加 “人類 - 機器人對話示例”(如 “人類:拿蘋果→機器人:1. 找蘋果,2. 拿蘋果,3. 遞給你”),讓 LLM 輸出結構化技能序列,確保可解析性。例如,17 個示例的 Prompt 使計劃成功率從無示例的 10% 提升至 88%(1-323、1-324)。
- 迭代規劃:每次選擇技能后,將其追加到 LLM 上下文,動態調整后續技能選擇(如 “拿海綿” 后,LLM 不再重復選擇該技能),適配長時程任務的步驟依賴(如 “扔可樂→拿海綿” 的順序規劃)(1-33、1-60)。
3. 創新 3:多任務與擴展能力優化,降低系統適配成本
無需重構核心模塊,即可支持新技能、多語言、復雜推理,解決傳統系統擴展性差的問題:
新技能快速集成:僅需添加新技能的?_π、對應的 BC/RL 策略及 2-3 個 Prompt 示例,即可融入現有系統。例如,添加 “抽屜操作” 技能時,僅補充 “打開抽屜”“關閉抽屜” 的?_π和價值函數(基于距離的啟發式),計劃成功率達 100%,且不影響原有技能性能(1-80、1-82)。
- 鏈式思維(Chain of Thought)處理復雜推理:通過 Prompt 添加 “Explanation” 環節(如 “用戶要無咖啡因的果味飲料→選青檸蘇打”),讓 LLM 先推理再輸出技能,解決否定指令(如 “不要蘋果”)和模糊需求(如 “拿健康的零食”)問題,示例任務成功率提升至 80% 以上(1-96、1-98)。
- 多語言零適配支持:利用 LLM 的多語言訓練數據,無需額外適配即可處理中、法、西語指令。實驗顯示,非英語指令計劃成功率接近 100%(僅 1 條法語指令因語法復雜度失敗),利用 LLM 的多語言能力降低適配成本(1-99、1-506)。
4. 創新 4:LLM 規模與機器人性能的正向關聯驗證,為跨領域協同提供依據
首次系統性驗證 “LLM 語義能力提升可直接帶動機器人性能提升”,為后續 “語言 - 機器人” 跨領域研究提供方向:
- LLM 參數規模影響:實驗表明,PaLM-540B(84% 計劃成功率、74% 執行成功率)顯著優于 PaLM-62B(72% 計劃成功率)和 PaLM-8B(38% 計劃成功率),證明 LLM 的語義知識儲備(如抽象指令理解、長時程規劃)直接決定機器人任務規劃能力(1-74、1-77)。
- 模型類型對比:通用 LLM(PaLM)優于指令微調 LLM(FLAN),PaLM-SayCan 計劃成功率 84% vs FLAN-SayCan 70%,說明 “通用語義知識” 比 “指令響應優化” 更適配機器人的物理任務規劃(1-74、1-77)。
5. 創新 5:開源可復現的實驗環境,降低研究門檻
提供基于 Google Colab 的開源桌面環境(含 UR5 機器人、CLIPort 策略、ViLD 物體檢測器),支持 “移動色塊到對應顏色碗中” 等任務,無需復雜機器人硬件即可復現 SayCan 核心邏輯。開源環境使用 GPT-3 作為 LLM,輸出 “拾取 - 放置” 代碼結構的技能序列,促進后續研究的擴展(1-102、1-103)。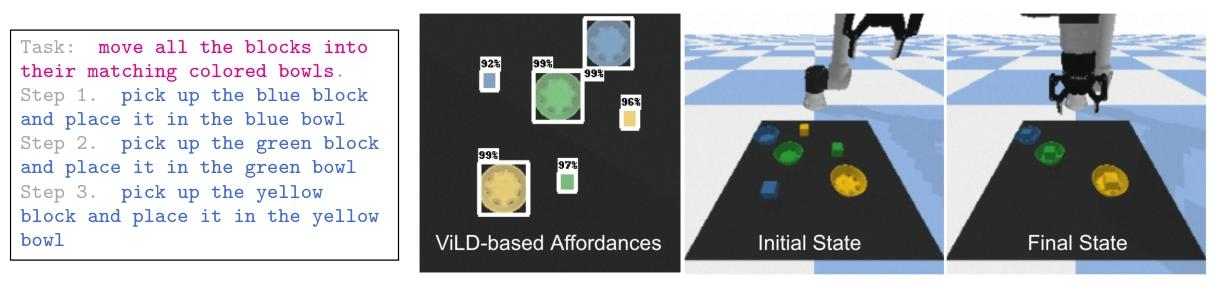
八、本論文的相關工作
論文將相關工作分為語言模型接地、語言條件行為學習、任務與運動規劃三類,每類均先總結現有研究的核心思路,再明確本文與現有工作的差異,核心邏輯是 “指出不足→凸顯本文補充價值”。
1. 第一類:語言模型接地(Grounding Language Models)
(1)現有研究核心方向
現有工作聚焦 “如何讓 LLM 關聯物理世界或具體動作”,主要分為三類方法(1-107):
- 環境輸入增強:讓 LLM 接受多模態輸入(如圖像、環境狀態)以補充物理信息,例如 VideoBERT([152])、VisualBERT([153])、ViLBERT([154])等,通過融合視覺與語言特征提升接地能力;
- 動作輸出直接映射:讓 LLM 直接生成動作序列或控制指令,例如 Embodied BERT([157])、Episodic Transformer([159]),但這類方法多依賴仿真環境訓練,缺乏真實物理交互驗證;
- 提示工程(Prompt Engineering):通過設計示例讓 LLM 生成符合任務需求的文本,例如 Huang 等人的 “LLM 作為零樣本規劃器”([23]),但該方法僅依賴文本生成,未結合環境可行性判斷,屬于 “無世界接地” 的生成模式。
(2)本文與現有研究的差異
現有方法的共性缺陷是 “缺乏真實物理交互反饋”,導致 LLM 輸出可能脫離機器人能力或環境約束(1-107);而本文的創新補充在于:
- 無需微調 LLM:通過 “預訓練技能的價值函數” 為 LLM 提供世界接地,避免因環境數據微調 LLM 導致的泛化性損失;
- 零樣本長時程任務:利用 LLM 的語義知識(任務接地)與價值函數的可行性判斷(世界接地),實現真實機器人的零樣本長時程任務規劃,而現有方法多局限于單步驟或仿真任務。
2. 第二類:語言條件行為學習(Learning Language-Conditioned Behavior)
(1)現有研究核心方向
該領域旨在 “讓機器人通過語言理解并執行行為”,主要依賴兩類學習范式(1-108):
- 模仿學習(Imitation Learning):通過人類演示數據訓練 “語言→動作” 映射模型,例如 BC-Z([13])、CLIPort([26]),可處理拾取、放置等低層級技能,但無法理解高層級抽象指令(如 “拿健康的零食”);
- 強化學習(Reinforcement Learning):通過獎勵信號優化語言條件的行為策略,例如 MT-Opt([14])、Language as Abstraction([57]),部分方法可處理仿真環境的長時程任務,但真實場景中因獎勵稀疏、環境復雜度高,性能受限。
(2)本文與現有研究的差異
現有方法的核心局限是 “技能序列規劃能力弱”—— 僅能執行預定義的低層級技能,無法動態拆解高層級指令(1-108);而本文的創新補充在于:
- 高層級規劃依賴 LLM:利用 LLM 的語義知識拆解抽象指令(如 “清理灑出的飲料”→“找海綿→拿海綿→遞給用戶”),突破傳統行為克隆 / 強化學習的 “無規劃” 缺陷;
- 多技能協同:通過 “LLM 評分 + 價值函數” 動態選擇技能,而非依賴固定技能序列,適配真實場景的環境變化(如 “無海綿時不選擇該技能”)。
3. 第三類:任務與運動規劃(Task and Motion Planning)
(1)現有研究核心方向
該領域聚焦 “如何將高層級任務拆解為低層級運動指令”,分為兩類方法(1-109 至 1-111):
- 傳統符號規劃 / 優化:基于顯式規則或數學優化生成技能序列,例如 STRIPS([185])、Logic-Geometric Programming([189]),需手動定義物體屬性、動作約束,泛化性差;
- 機器學習驅動規劃:通過數據學習抽象任務的規劃邏輯,例如 Neural Task Programming([191])、Hierarchical Foresight([204]),可處理部分長時程任務,但多依賴仿真數據,且缺乏語言與物理世界的動態關聯。
(2)本文與現有研究的差異
現有方法的核心缺陷是 “語言理解能力弱”—— 無法通過自然語言動態調整規劃邏輯(如用戶指令從 “拿蘋果” 改為 “拿香蕉” 時,需重新訓練或定義規則)(1-111);而本文的創新補充在于:
- 自然語言驅動規劃:利用 LLM 的語義理解能力,直接將自然語言指令轉化為技能序列,無需手動定義符號規則;
- 真實場景魯棒性:結合價值函數的環境可行性判斷,避免傳統規劃 “僅考慮邏輯正確、忽略物理執行” 的問題,例如 “不選擇無吸塵器場景中的‘用吸塵器’技能”。





-- 基礎語法與數據類型)







)

:并發編程的 4 個優化維度)



的Elasticsearch鏡像)