一、作品詳細簡介
1.1附件文件夾程序代碼截圖

?全部完整源代碼,請在個人首頁置頂文章查看:
學行庫小秘_CSDN博客?編輯https://blog.csdn.net/weixin_47760707?spm=1000.2115.3001.5343
1.2各文件夾說明
1.2.1 main.m主函數文件
該MATLAB 代碼實現了一個基于基于XGBoost算法的數據回歸預測模型,主要步驟分解如下:
1.?數據導入
- 從Excel文件數據集.xlsx中讀取數據,存儲到矩陣res中。
- 假設數據包含103行(樣本)和8列(前7列為特征,第8列為標簽)。
2.?劃分訓練集與測試集
- 隨機劃分:randperm打亂樣本順序,避免順序偏差。
- 訓練集:80個樣本的特征(P_train)和標簽(T_train)。
- 測試集:23個樣本的特征(P_test)和標簽(T_test)。
- 特征矩陣轉置為?行表示特征,列表示樣本(適配后續XGBoost輸入)。
3.?數據歸一化
- 歸一化目的:消除量綱影響,提升模型收斂速度。
- 訓練集:計算歸一化參數(ps_input為特征參數,ps_output為標簽參數)。
- 測試集:復用訓練集的歸一化參數,確保數據分布一致。
4.?數據轉置
- 將數據還原為?行表示樣本,列表示特征(適配XGBoost的MATLAB接口)。
5.?設置XGBoost參數
- 關鍵參數:
- num_trees:弱學習器(樹)的數量。
- eta:學習率,控制過擬合。
- max_depth:樹深度,影響模型復雜度。
6.?訓練XGBoost模型
- 輸入歸一化后的訓練數據(p_train為特征,t_train為標簽)。
- 輸出訓練好的模型model。
7.?模型預測
- 使用訓練好的模型預測訓練集和測試集結果(結果為歸一化后的值)。
8.?反歸一化
- 將預測值還原到原始標簽的量綱。
9.?評估指標計算
均方根誤差(RMSE)
- RMSE衡量預測值與真實值的偏差(值越小越好)。
R2(決定系數)
- R2表示模型解釋方差的比例(越接近1越好)。
MAE(平均絕對誤差) & MBE(平均偏差誤差)
- MAE:絕對誤差的平均值(魯棒性強)。
- MBE:預測偏差的平均值(正負表示高/低估趨勢)。
10.?結果可視化
預測值對比圖
- 紅色星號:真實值;藍色圓圈:預測值。
- 標題顯示RMSE評估結果。
預測值-真實值散點圖
- 點越接近對角線,預測越準確。
- 可直觀識別離群點或系統偏差。
關鍵注意事項
- 數據泄露預防:測試集使用訓練集的歸一化參數(mapminmax('apply'))。
- 隨機性:randperm確保每次運行劃分結果不同(可固定隨機種子復現結果)。
- XGBoost接口:需提前安裝MATLAB版XGBoost(xgboost_train和xgboost_test)。
- 模型評估:
- 訓練集指標(error1,?R1)反映模型擬合能力。
- 測試集指標(error2,?R2)反映泛化能力。
- MBE?可判斷預測值系統性偏高/偏低。
此流程完整覆蓋了回歸任務的典型步驟:數據準備 → 預處理 → 模型訓練 → 預測 → 反歸一化 → 評估 → 可視化。
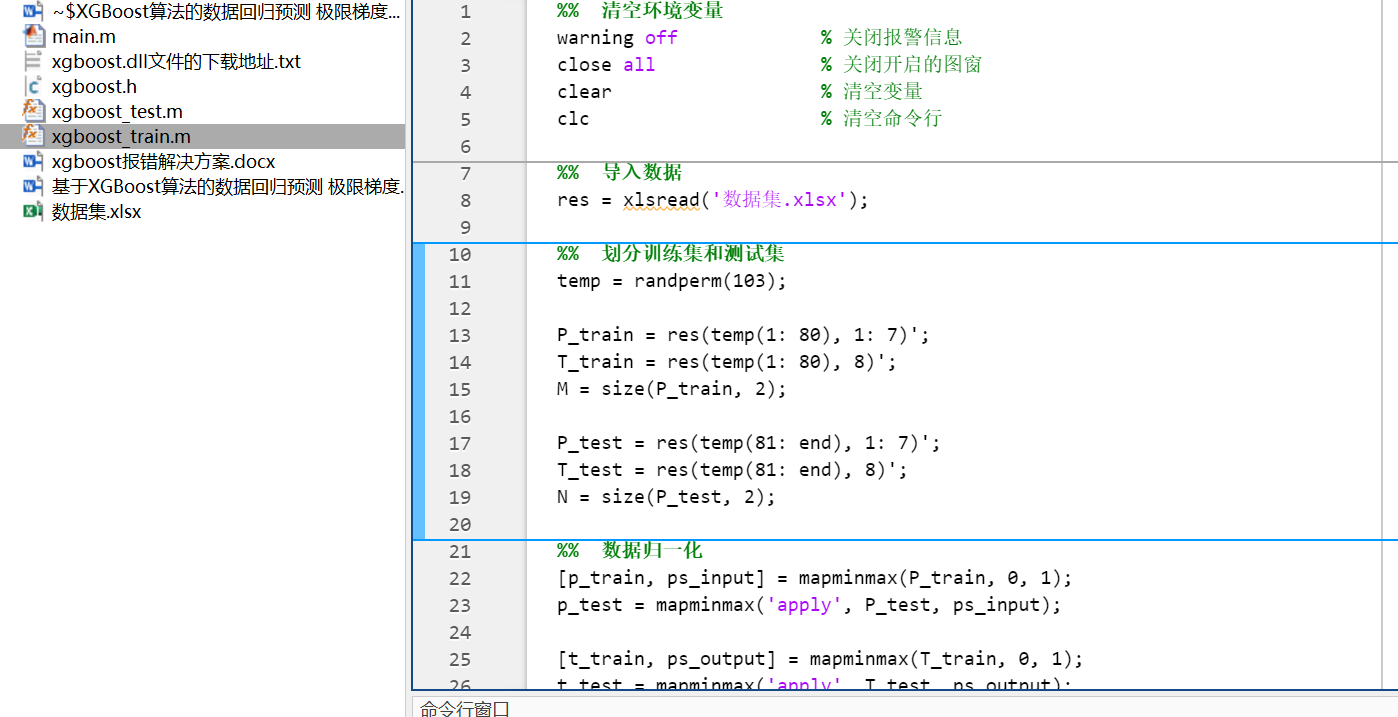
圖2? main.m主函數文件部分代碼
1.2.2 數據集文件
數據集為Excel數據csv格式文件,可以方便地直接替換為自己的數據運行程序。原始數據文件包含7列特征列數據和1列輸出標簽列數據,一共包含103條樣本數據,具體如圖所示。
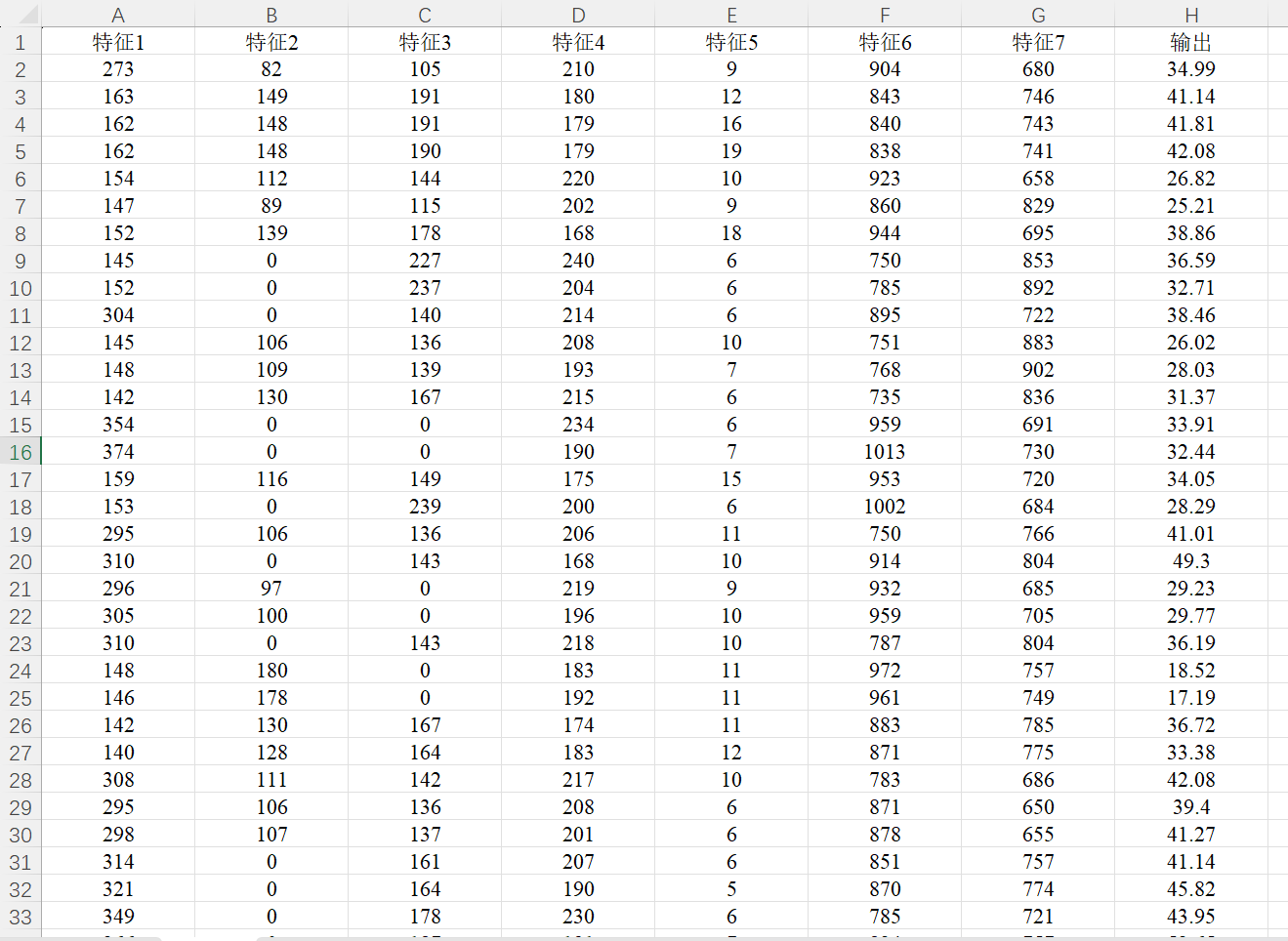
二、代碼運行結果展示
該代碼實現了一個基于XGBoost算法的回歸預測模型,用于對數據集進行建模和性能評估。
首先,它導入Excel數據集,隨機劃分80%樣本作為訓練集、23%作為測試集,并進行特征和標簽的歸一化預處理;
其次,設置XGBoost參數(包括100棵樹、0.1學習率和5層最大深度),訓練回歸模型并在訓練/測試集上進行預測;
最后,通過反歸一化得到原始量綱的預測結果,計算RMSE、R2、MAE和MBE等評估指標,并繪制預測值對比曲線和真實值-預測值散點圖進行可視化分析。
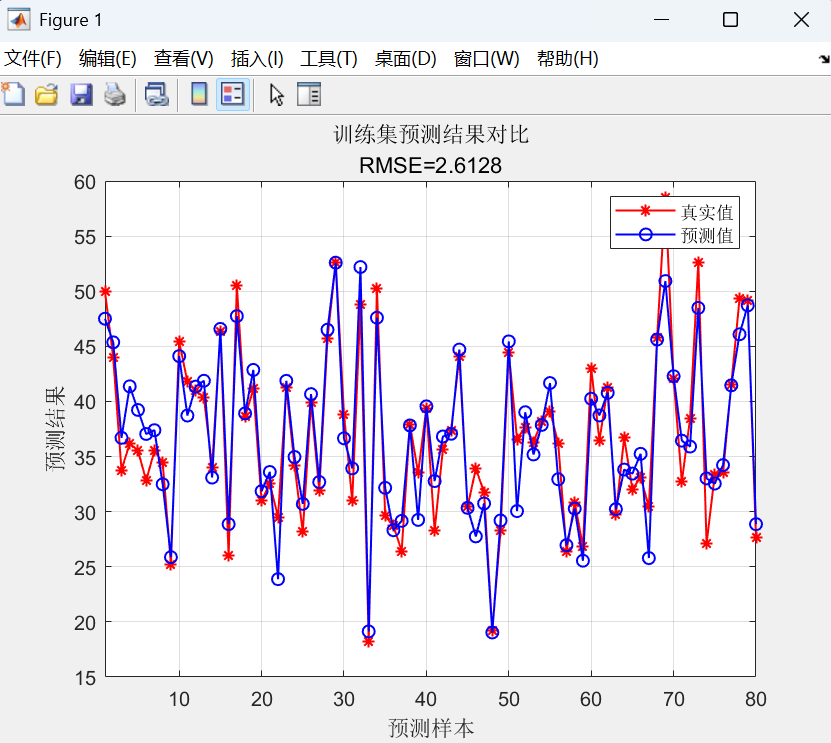
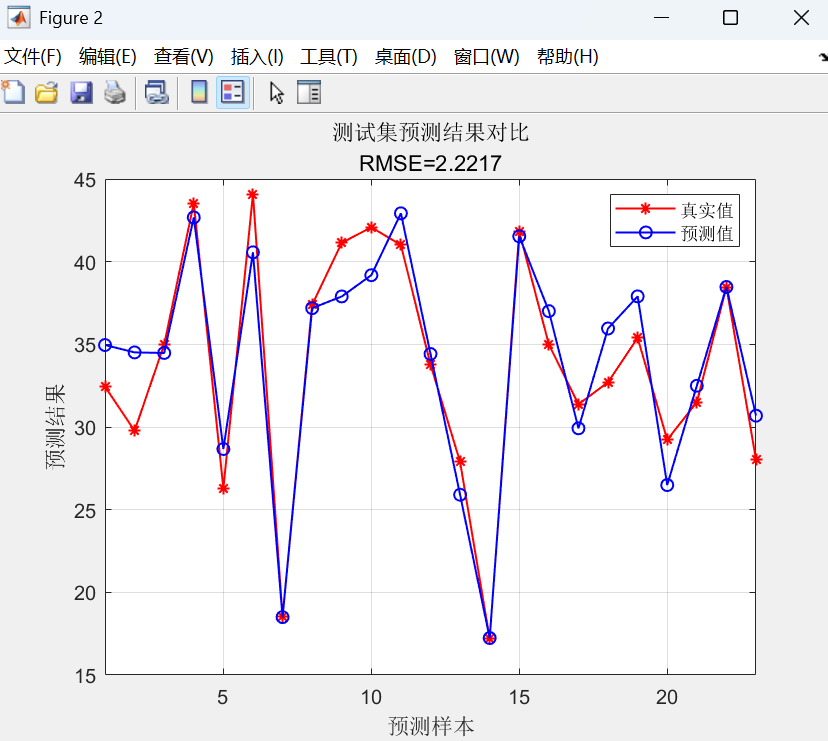
三、注意事項:
1.程序運行軟件推薦Matlab 2018B版本及以上;
2.所有程序都經過驗證,保證程序可以運行。此外程序包含簡要注釋,便于理解。
3.如果不會運行,可以幫忙遠程運行原始程序以及講解和其它售后,該服務需另行付費。
4. 代碼包含詳細的文件說明,以及對每個程序文件的功能注釋,說明詳細清楚。
5.Excel數據,可直接修改數據,替換數據后直接運行即可。


)





)






)
和 TCP/IP(使用 127.0.0.1)進程間通信(IPC)的比較)


)