一、魔塔社區平臺介紹
1.1 什么是魔塔社區?
魔塔(ModelScope)是由阿里巴巴達摩院推出的開源模型即服務(MaaS)共享平臺,匯聚了計算機視覺、自然語言處理、語音等多領域的數千個預訓練AI模型。其核心理念是"開源、開放、共創",通過提供豐富的工具鏈和社區生態,降低AI開發門檻,尤其為企業本地私有化部署提供了一條高效路徑。
ModelScope官網:https://modelscope.cn/home
1.2 魔塔社區的五大核心優勢
-
海量模型,即取即用
覆蓋文本生成(如通義千問)、圖像識別、語音合成等場景,提供Apache 2.0等商業友好協議模型,支持開發者快速調用API或下載模型權重文件(沒有HuggingFace全但是他是國內的呀,支持國產替代原則)。
-
私有化部署全鏈路支持
-
ModelScope SDK:提供模型加載、推理、微調的Python工具包,一行代碼即可本地部署。
-
SWIFT框架:支持LoRA等輕量級微調技術,無需昂貴算力即可定制企業專屬模型。
-
容器化封裝:結合Kubernetes技術實現生產級高可用部署,保障服務穩定性。
-
企業級數據安全
通過本地化部署規避云端數據泄露風險,支持企業內部網絡隔離,特別適合金融、醫療等隱私敏感行業。
-
開發者友好生態
- 詳盡的模型文檔和實戰教程(如圖像生成、RAG知識庫構建)
- 活躍的論壇答疑和技術博客共享
- 定期線上黑客松大賽激勵創新
-
產學研聯動創新
與高校、研究機構合作開源頂尖模型(如多模態模型OFA),推動技術民主化進程。
GitHub 地址:https://github.com/moka-ai
官方文檔中心:https://moka.ai/docs
魔塔開源大模型榜(中文模型性能對比):https://huggingface.co/spaces/moka-ai/leaderboard
1.3 魔塔社區 vs Hugging Face
| 維度 | 魔塔社區(Moka Community) | Hugging Face |
|---|---|---|
| 🏷? 定位 | 中文大模型開源社區,強調國產、中文優化、低門檻落地 | 國際領先的AI模型平臺,全球開源 AI 社區中心 |
| 🌍 語言支持 | 聚焦中文及國內場景優化 | 以英文為主,支持多語種,中文相對薄弱 |
| 🧩 生態組成 | 自研模型 + 中文工具鏈 + 開源數據集 + 教程文檔 + 社區支持 | 模型庫 + Transformers 工具包 + Spaces 應用托管 + Datasets |
| 🔧 工具鏈 | 魔塔 CLI、M3E 向量模型、Maka-LoRA、中文 Instruct 數據集 | 🤗 Transformers、🤗 Datasets、🤗 PEFT、🤗 Accelerate 等強大工具 |
| 🧠 微調支持 | LoRA、Adapter、中文指令數據(對國內任務適配性高) | 全套微調方案,支持各類模型和訓練策略(全量、局部、PEFT) |
| 📊 模型側重 | 中文大模型(Qwen、BaiChuan、ChatGLM 等)為主,強調本地化部署 | 國際主流大模型(GPT2、LLaMA、T5、BERT 等),英文優化更好 |
| 🧰 使用門檻 | 中文文檔友好,適合中文初學者/企業研發快速入門 | 接口強大,文檔全面,適合熟悉英文、對模型控制力強的用戶 |
| 🤝 社區互動 | 微信群、QQ 群、中文文檔站、本地 workshop | GitHub、論壇、Discord、Twitter/X、Hugging Face Spaces |
| 🏢 適合對象 | 🇨🇳 中文開發者、中小企業、創業公司、本地部署用戶 | 🌎 國際開發者、學術研究者、平臺構建者、英文主導團隊 |
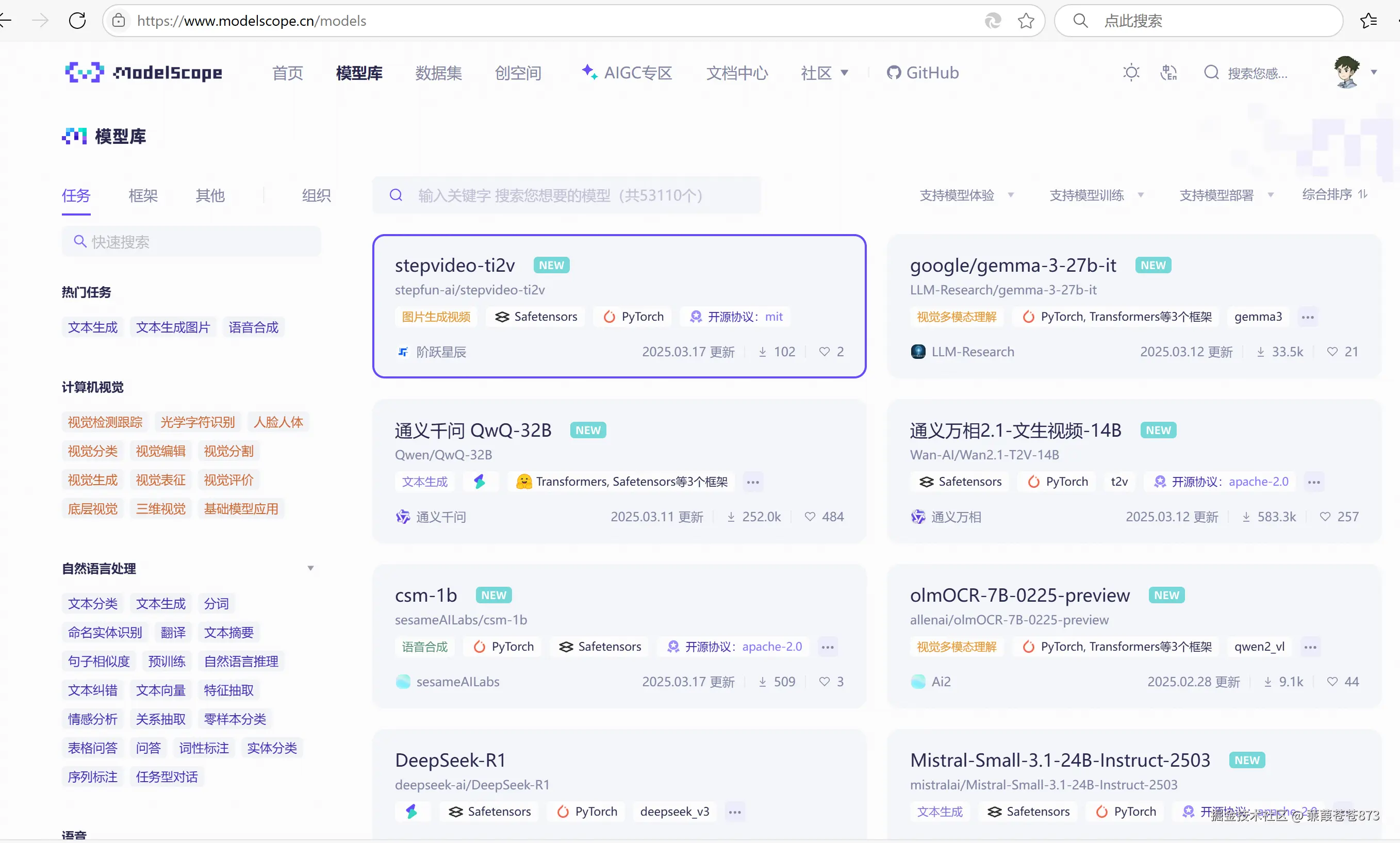
二、魔塔社區下載模型
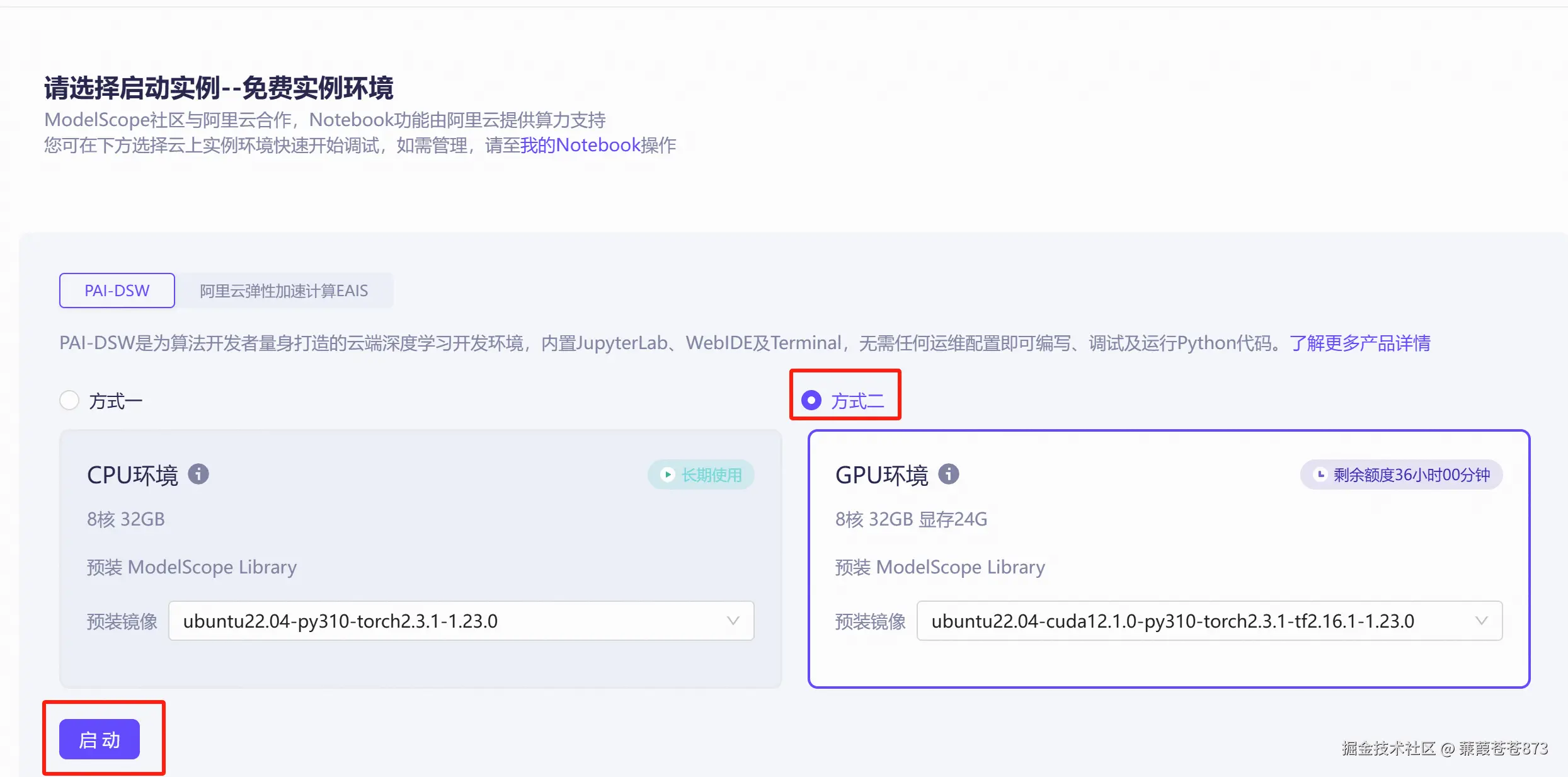
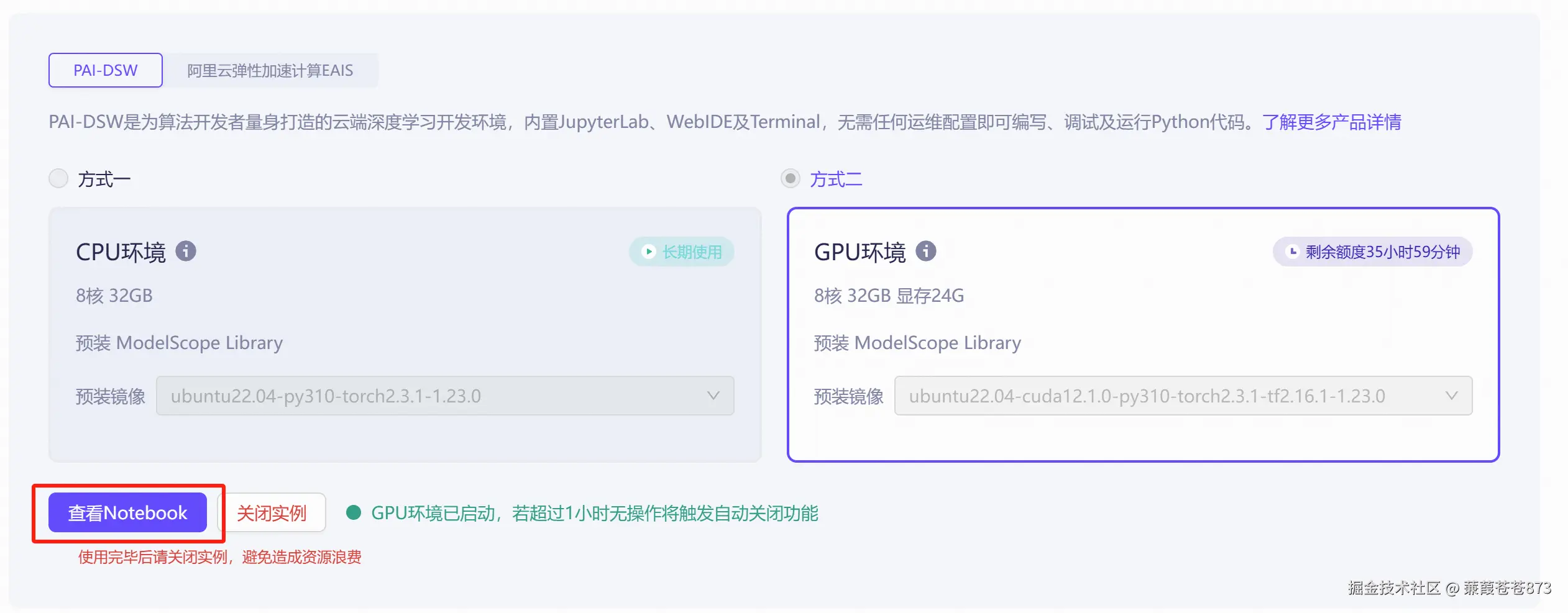
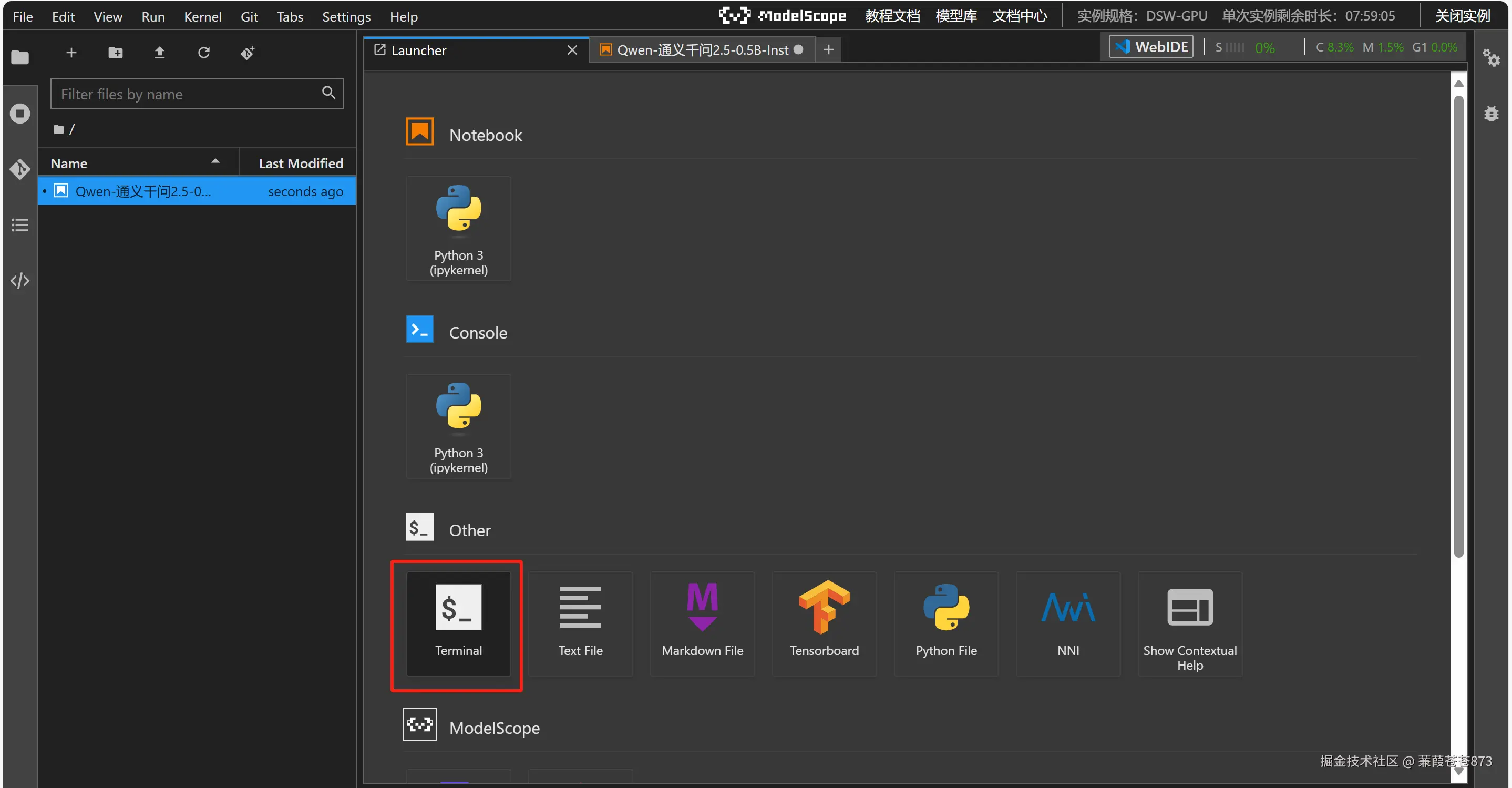
2.1 先白嫖一把阿里的服務器
- 找到通義千問
2.5-0.5B-Instruct版本點進去
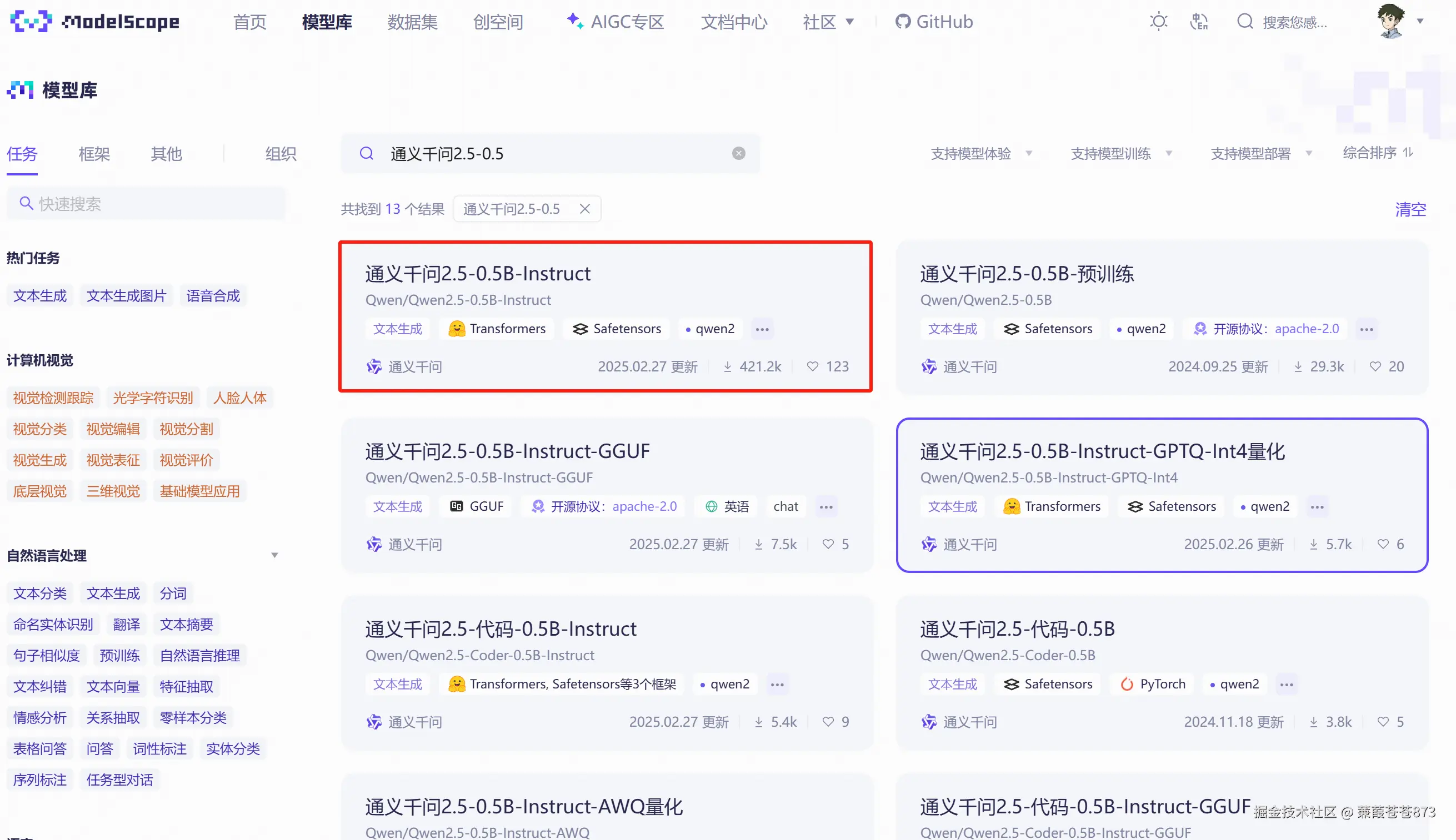
- 找到
Notebook快速開發
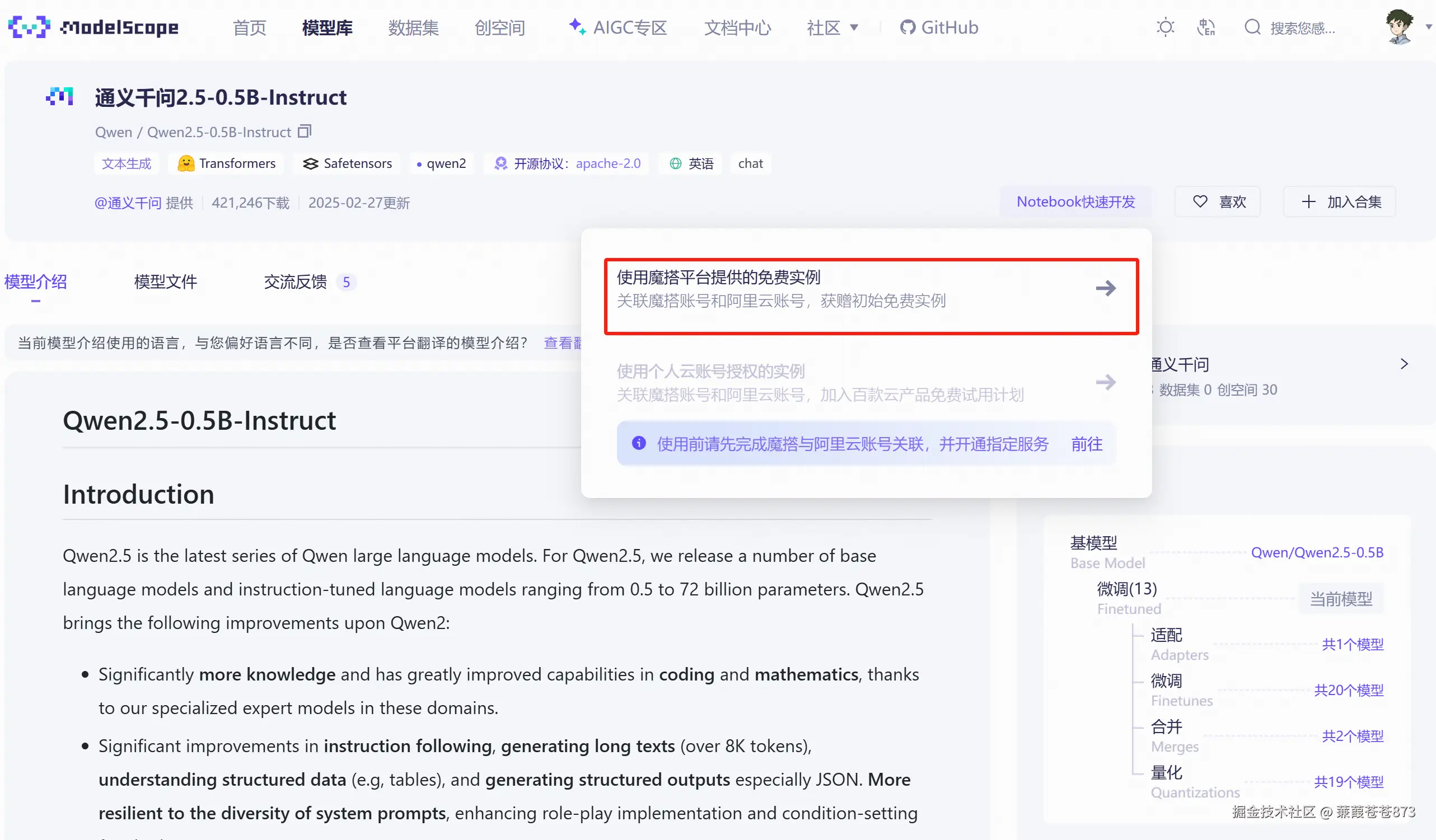
- 選方式二,然后啟動
2.2 開始下載模型
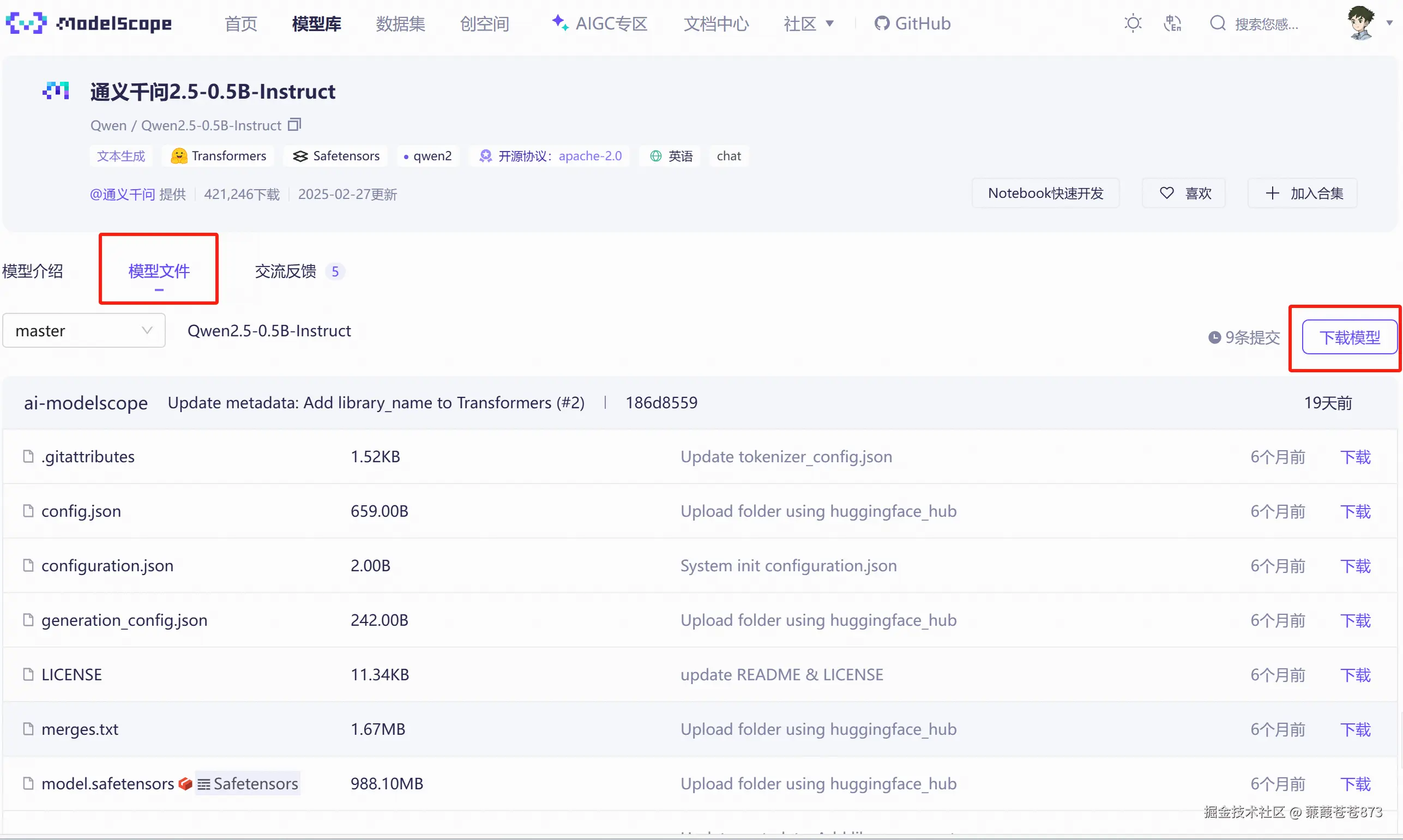

推薦使用SDK下載,Git下載可能會有問題,1秒就下載完了但是執行就會有問題。
- 安裝
ModelScope,執行命令:pip install modelscope
-
創建下載文件通過SDK下載,下載的時候要指定目錄
cache_dir,不然會默認下載到緩存路徑去,下載完了調用不到。from modelscope import snapshot_downloadmodel_dir = snapshot_download('Qwen/Qwen2.5-0.5B-Instruct', cache_dir = "/mnt/workspace/LLM/")下載模型時輸出如下:

三、Qwen大模型文件目錄解析
3.1 整體目錄
目前其他大模型也是差不多的結構,文件都在一層中,不像Bert模型有分層。

3.2 config.json文件詳解
{"attention_dropout": 0, // 注意力機制中的dropout概率,0表示不使用注意力丟棄"bos_token_id": 151643, // 文本開始的特殊標記(Begin-of-Sequence)的ID"eos_token_id": 151645, // 文本結束的特殊標記(End-of-Sequence)的ID"hidden_act": "silu", // 隱藏層使用的激活函數(Swish/SiLU激活函數)"hidden_size": 896, // 隱藏層維度(每個Transformer層的神經元數量)"initializer_range": 0.02, // 權重初始化的范圍(正態分布的σ值)"intermediate_size": 4864, // Feed Forward層中間維度(通常是hidden_size的4-8倍)"max_position_embeddings": 32768,// 支持的最大上下文長度(32K tokens)"max_window_layers": 21, // 使用滑動窗口注意力的最大層數(長文本優化相關)"model_type": "qwen2", // 模型架構標識(用于Hugging Face庫識別)"num_attention_heads": 14, // 注意力頭的總數(常規注意力)"num_hidden_layers": 24, // Transformer層的總數量(模型深度)"num_key_value_heads": 2, // 分組查詢注意力中的鍵值頭數(GQA技術,顯存優化)"rms_norm_eps": 0.000001, // RMS歸一化的極小值(防止計算溢出)"rope_theta": 1000000, // RoPE位置編碼的基頻參數(擴展上下文能力相關)"sliding_window": 32768, // 滑動窗口注意力大小(每個token可見的上下文范圍)"tie_word_embeddings": true, // 是否共享輸入輸出詞嵌入權重(常規做法)"torch_dtype": "bfloat16", // PyTorch張量精度類型(平衡精度與顯存)"transformers_version": "4.43.1",// 適配的Transformers庫版本"use_cache": true, // 是否使用KV緩存加速自回歸生成"use_sliding_window": false, // 是否啟用滑動窗口注意力機制(當前禁用)"vocab_size": 151936 // 模型所有詞表大小(支持的token總數量)
}
重點參數說明
1) 長上下文支持組:
max_position_embeddings + rope_theta + sliding_window
- 共同實現超長上下文處理能力(32K tokens)
"rope_theta":"1000000"
- RoPE位置編碼的基頻參數 + 滑動窗口機制,增強模型的長文本處理能力
2) 顯存優化組:
"num_key_value_heads":"2"
- 分組查詢注意力,減少顯存占用
"torch_dtype":"bfloat16"
- 數據類型
"bfloat16"
use_cache:true
- KV緩存加速提升推理效率
AI模型本質是一個大矩陣,他由很多個參數構成,這些參數的數據類型是float32(單精度),比float32精度更高的是float64(雙精度,java里是double),在AI模型中默認是單精度float32,這個精度有個特點是可以往下降,叫做精度的量化操作,可以把32位的精度降為16(半)位或者更低8位,最低是4位,精度變低,模型的體積會更小,運算的速度會更快,量化的意義就在于加速模型的推理能力,降低對于硬件的依賴。
現在使用的是通義千問2.5-0.5B-Instruct,這里的0.5B就代表著參數的數量,bfloat16就算每個參數所占的存儲空間,模型的大小=參數的數量*每個參數所占的存儲空間。
3) 架構特征組:
"hidden_act":"silu"
- 隱藏層使用現代激活函數 silu(相比ReLU更平滑)
"num_hidden_layers":"24"
- 深層網絡結構(24層)配合intermediate_size:4864 大中間層維度增強模型容量
"num_attention_heads":"14"
- 較小的注意力頭數平衡計算效率
4) 兼容性組
"transformers_version": "4.43.1"
- 明確標注Transformers庫版本確保API兼容性
"model_type": "qwen2"
- 聲明模型架構形式用于
Hugging Face庫識別
3.3 generation_config.json文件詳解
{"bos_token_id": 151643, // 文本開始標記(Begin-of-Sequence)的ID,用于標識序列的起始位置"pad_token_id": 151643, // 填充標記(Padding)的ID,用于對齊不同長度的輸入序列(罕見地與BOS共用)"do_sample": true, // 啟用采樣模式(若設為false則使用貪心解碼,關閉隨機性)"repetition_penalty": 1.1, // 重復懲罰系數(>1的值會降低重復內容的生成概率)"temperature": 0.7, // 溫度參數(0.7為適度隨機,值越高生成越多樣化但也越不可控)"top_p": 0.8, // 核采樣閾值(只保留累計概率超過80%的最高概率候選詞集合)"top_k": 20, // 截斷候選池大小(每步只保留概率最高的前20個候選token)"transformers_version": "4.37.0" // 對應的Transformers庫版本(兼容性保障)
}
核心參數詳解:
如本地化使用通義千問,可通過此文件修改文本生成的效果
1) 核心采樣機制組:
do_sample = true:
- 開啟概率采樣模式(關閉時為確定性高的貪心搜索)
temperature = 0.7:
- 中等隨機水平(比默認1.0更保守,適合作業型文本生成)
top_p=0.8 + top_k=20:
- 組合采樣策略(雙重約束候選詞的質量)
2) 文本優化控制組:
repetition_penalty=1.1:
- 溫和的重復懲罰參數(值越大越壓制重復用詞)
bos_token_id=pad_token_id:
- 特殊標記共享設計(注意:這與常規模型設計不同,可能用于處理可變長度輸入的特殊場景)
3) 工程兼容性:
明確標注transformers_version,提示用戶需對應版本的庫才能正確解析配置
3.4 model.safetensors權重文件
打不開跳過
3.5 tokenizer_config.json文件
json 體驗AI代碼助手 代碼解讀復制代碼{"add_bos_token": false, // 是否自動添加文本起始符(BOS),關閉表示輸入不額外增加開始標記"add_prefix_space": false, // 是否在文本前自動添加空格(用于處理單詞邊界,該項對中文無影響)"bos_token": null, // 不設置專門的BOS標記(模型的起始序列由對話模板控制)"chat_template": "Jinja模板內容",// 角色對話模板規范(定義:角色標記+工具調用格式+消息邊界切割規則)"clean_up_tokenization_spaces": false, // 是否清理分詞產生的空格(保留原始空格格式)"eos_token": "<|im_end|>", // 文本終止標記(用于標記每個對話輪次/整體生成的結束)"errors": "replace", // 解碼錯誤處理策略(用�符號替換非法字符)"model_max_length": 131072, // 最大處理長度(131072 tokens約等于128K上下文容量)"pad_token": "<|endoftext|>", // 填充標記(用于批量處理的序列對齊)"split_special_tokens": false, // 禁止分割特殊標記(確保類似<|im_end|>保持整體性)"tokenizer_class": "Qwen2Tokenizer", // 專用分詞器類型(特殊字詞分割規則實現)"unk_token": null // 無專用未知標記(通過errors策略處理未知字符)
}
核心參數詳解
1) 長上下文支持:
"model_max_length": 131072
- 顯式描述支持128K超長文本處理
"clean_up_tokenization_spaces": false
- 維護原始空格格式確保長文本連貫性
2) 對話格式控制:
chat_template
- 定義多模態對話邏輯:
eos_token
- 作為終止符貫穿全對話流程控制
<|im_start|>/<|im_end|>標記劃分角色邊界(system/user/assistant/tool)
tool_call
- XML塊規范函數調用輸出格式
之前的大模型是通過MaxLength來控制文本的最大輸出,現在的大模型需要根據問題的答案長短來控制文本的輸出,所以他這個模型使用eos_token定義的終止符,來做提前終止。這些特殊的終止符還有一個作用是與大模型的對話模板組合控制生成內容。
3) 中文優化特性:
"add_prefix_space": false
- 避免英文分詞策略對中文處理干擾
"unk_token": null
- 結合 “errors”: “replace” 實現對中文生僻字的容錯處理
"tokenizer_class": "Qwen2Tokenizer"
- 專用
Qwen2 Tokenizer含有中文高頻詞匯的特殊分割規則
3.6 tokenizer.json文件
應該有加密不看了
3.7 vocab.json文件
和之前Bert的vocab.txt一樣,但是這里不開放,開放了使用者的就可以修改,就沒有意義了,不看了。
四、使用transformer加載本地Qwen
transformers是HuggingFace官網開發的開源庫,它將主流的預訓練模型,如BERT、GPT等統一整合在一套API下,并提供了豐富的工具支持快速訓練、推理與部署。該庫具有統一的接口與模塊化設計,通過“自動化”類,如 AutoModel 、 AutoTokenizer 等,可以根據給定的模型名稱或路徑,自動匹配相應的模型結構、詞表和配置文件。此外,它還擁有龐大的社區Model Hub,包含成千上萬的開源模型,用戶可一鍵下載或上傳自己的模型。
transformers的這種方式,只是讓我們更好的去理解,就是現在大模型的工作原理,對這段代碼對它有一個流程化的理解,就可以了。
我們如果真正意義上面要去調用一個大模型的話,要用這三種方式:
Ollama、vLLM、LMDeploy。
from transformers import AutoModelForCausalLM,AutoTokenizerDEVICE = "cuda"#加載本地模型路徑為該模型配置文件所在的根目錄
model_dir = "/mnt/workspace/LLM/Qwen/Qwen2.5-0.5B-Instruct"#使用transformer加載模型
model = AutoModelForCausalLM.from_pretrained(model_dir,torch_dtype="auto",device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_dir)#調用模型
#定義提示詞
prompt = "你好,請介紹下你自己。"
#將提示詞封裝為message
message = [{"role":"system","content":"You are a helpful assistant system"},{"role":"user","content":prompt}]
#使用分詞器的apply_chat_template()方法將上面定義的消息列表進行轉換;tokenize=False表示此時不進行令牌化
text = tokenizer.apply_chat_template(message,tokenize=False, add_generation_prompt=True)#將處理后的文本令牌化并轉換為模型的輸入張量
model_inputs = tokenizer([text],return_tensors="pt").to(DEVICE)#將數據輸入模型得到輸出
response = model.generate(model_inputs.input_ids,max_new_tokens=512)
print(response)#對輸出的內容進行解碼還原
response = tokenizer.batch_decode(response,skip_special_tokens=True)
print(response)
執行結果:
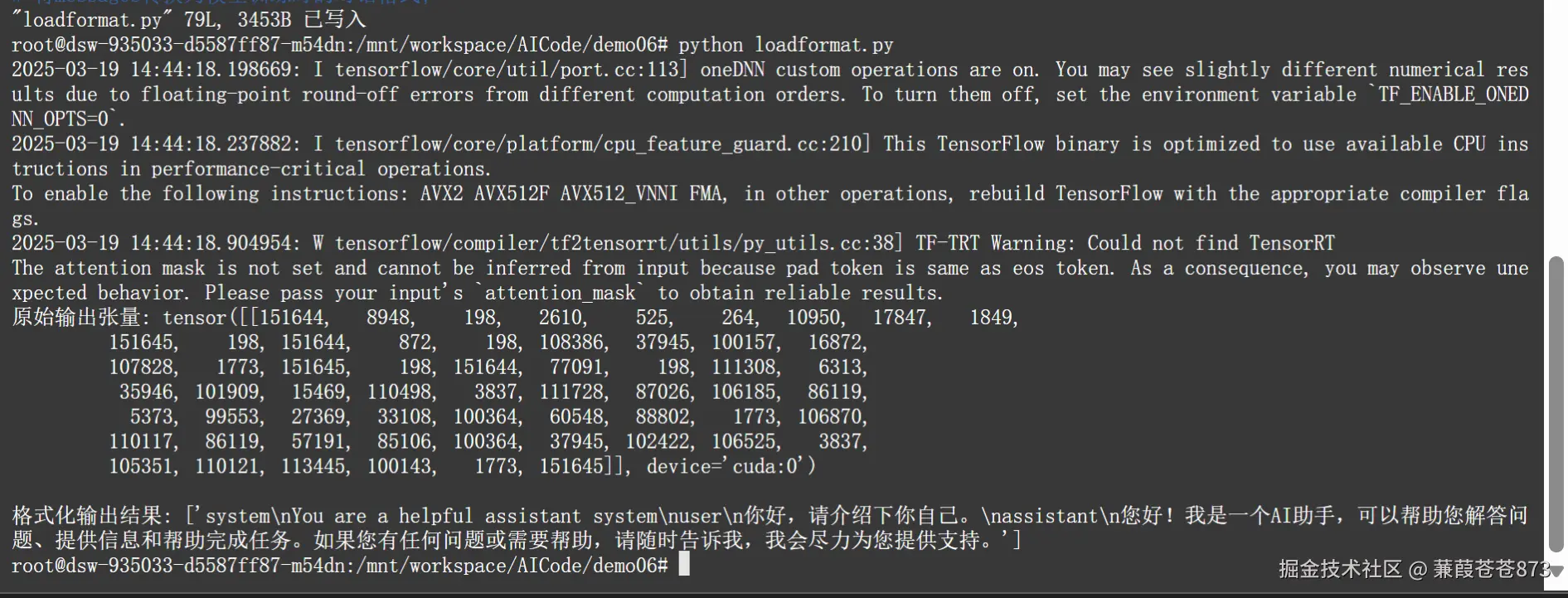
五、Ollama工具
5.1 Ollama 是什么?
Ollama 是一款開源的、專注于在本地設備上運行大型語言模型(LLM)的工具。它簡化了復雜模型的部署和管理流程,允許用戶無需依賴云端服務或網絡連接,即可在自己的電腦、服務器甚至樹莓派(微型單板計算機)等設備上體驗多種先進的 AI 模型(如 Llama3、Mistral、Phi-3 等)。其核心目標是讓本地化運行 LLM 變得低成本、高效率、高隱私。
5.2 核心功能與特點
- 本地化部署
- 隱私與安全: 所有模型運行和數據處理均在本地完成,適合需保護敏感信息的場景(如企業數據、個人隱私)。
- 離線可用: 無需互聯網連接,可在完全斷開網絡的設備使用。
- 資源優化: 支持量化模型(如 GGUF 格式),大幅降低內存占用(某些小型模型可在 8GB 內存的設備運行)。
- 豐富的模型生態
- 主流模型支持:
Llama3、Llama2、Mistral、Gemma、Phi-3、Wizard、CodeLlama等。 - 多模態擴展: 通過插件支持圖像識別、語音交互等擴展功能。
- 自定義模型: 用戶可上傳自行微調的模型(兼容 PyTorch、GGUF、Hugging Face 格式)。
- 開箱即用
- 極簡安裝: 支持 macOS、Linux(Windows 通過 Docker/WSL),僅需一行命令完成安裝。
- 統一接口: 提供命令行和 REST API,方便與其他工具(編程接口、Chat UI 應用)集成。
- 多樣化應用場景
- 開發調試: 快速構建本地 LLM 驅動的應用原型。
- 企業私有化: 內部知識庫問答、文檔分析等場景。
- 研究與教育: 低成本教學 AI 模型原理與實踐。
5.3 使用Ollama部署大模型
5.3.1 Conda創建單獨的環境
1. 創建ollama環境
阿里云魔塔社區免費給的服務器每次開啟需要重新激活conda:source /mnt/workspace/miniconda3/bin/activate
conda create -n ollama
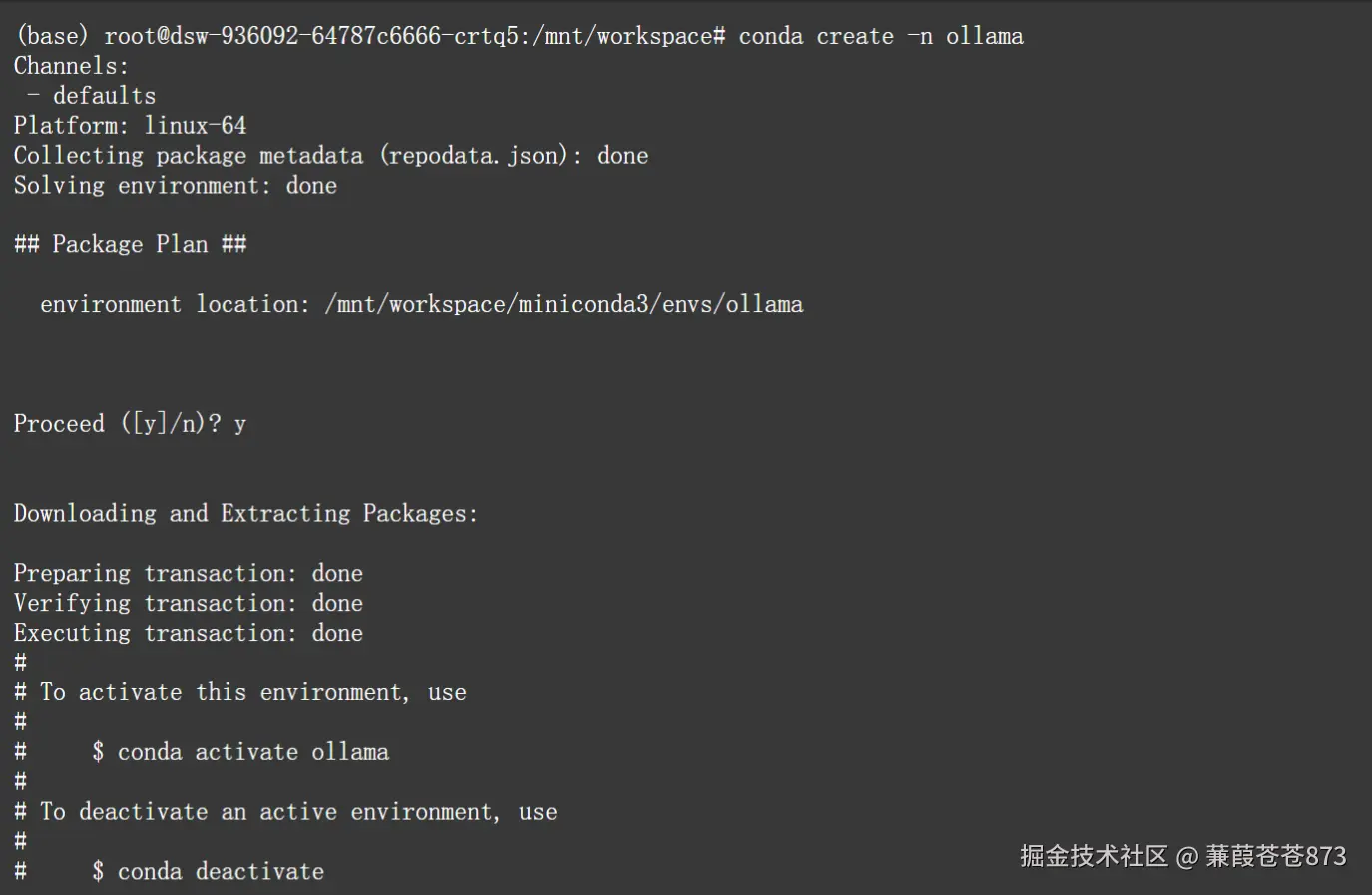
2. 激活ollama環境
查看conda環境 :conda env list
激活ollama環境: conda activate ollama

前面由base切換到了ollama環境,切換成功。
5.3.2 下載ollama的Linux版本
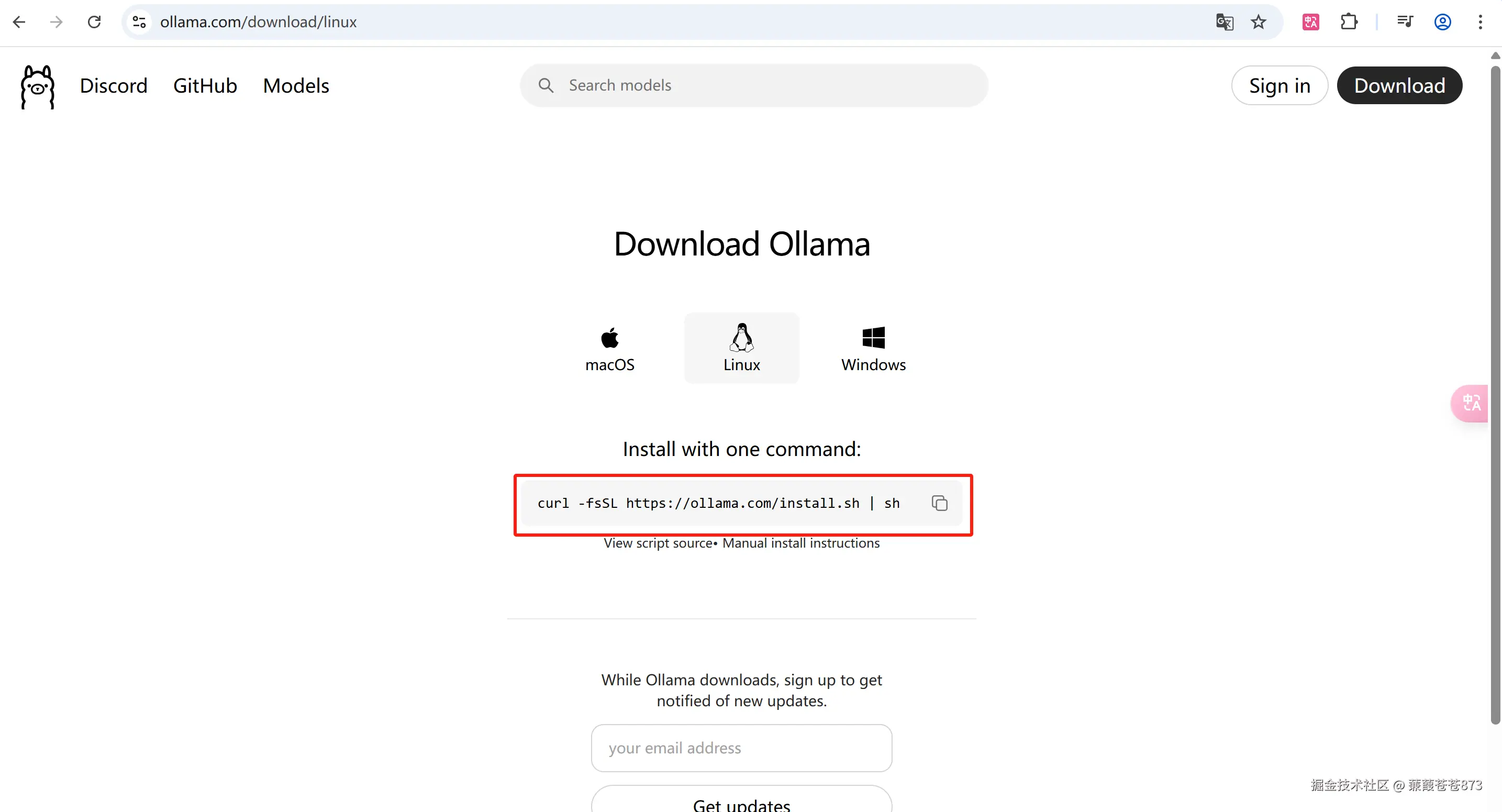
1. 進入官網
ollama官網:https://ollama.com/download/linux
2. 執行命令
curl -fsSL ollama.com/install.sh | sh
但是這個玩意下載的時候很慢,這東西網絡很不穩定,就是有有一段時間它的下載速度會比較快,有一段時間它下載的速度會非常慢。甚至于有一段時間它會提示你這個網絡連接錯誤,網絡連接錯誤。如果出現了這種情況,一般的解決方法就是最完美的解決方法是在你的服務器上面去掛個梯子,但是這個掛梯子不一定有效。所以說這個東西最大的困難就在于安裝起來得靠運氣。
5.3.3 下載安裝包安裝(推薦)
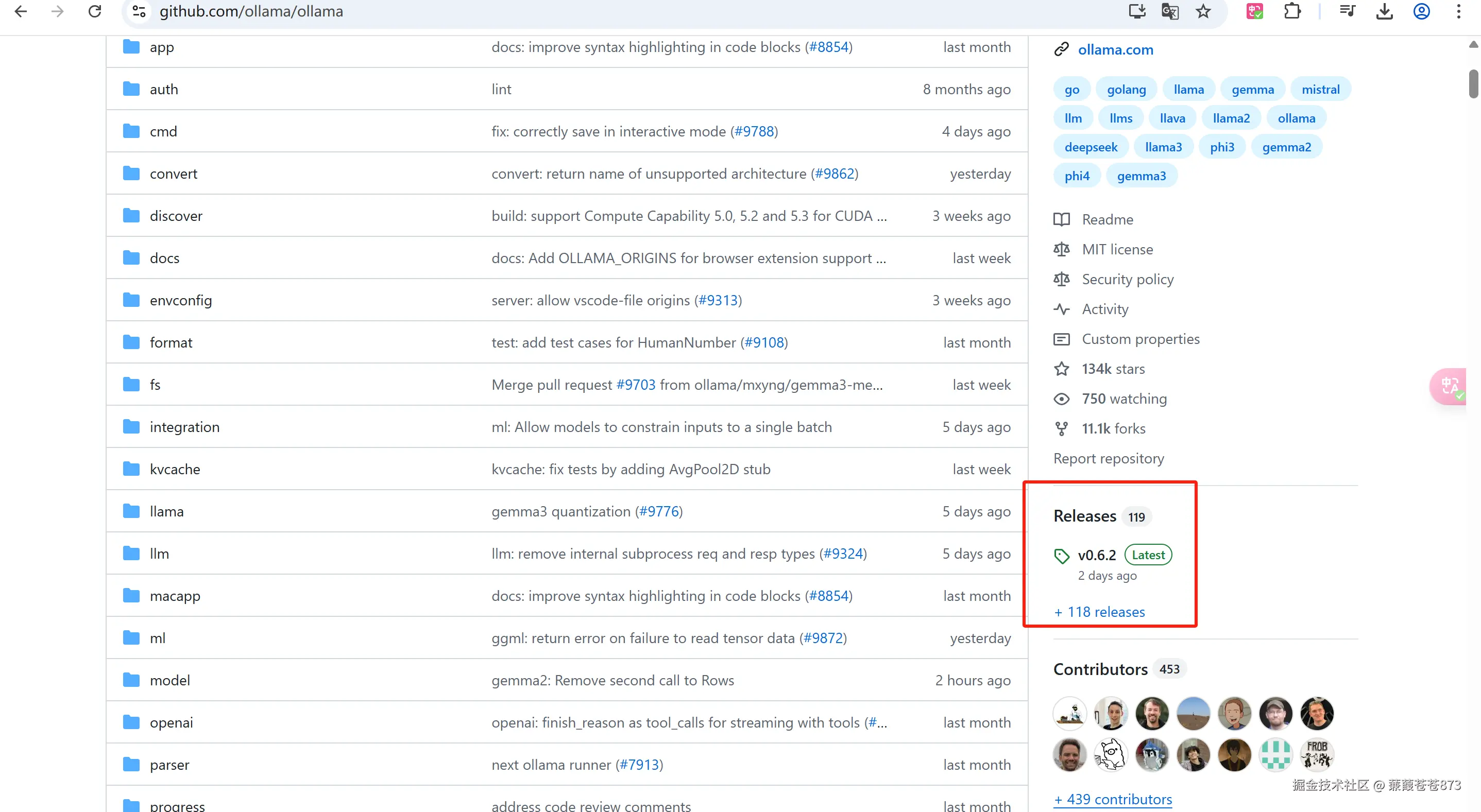
1.登錄Github
找到ollama的Releases 或者直接跳轉開始下載:ollama安裝包下載
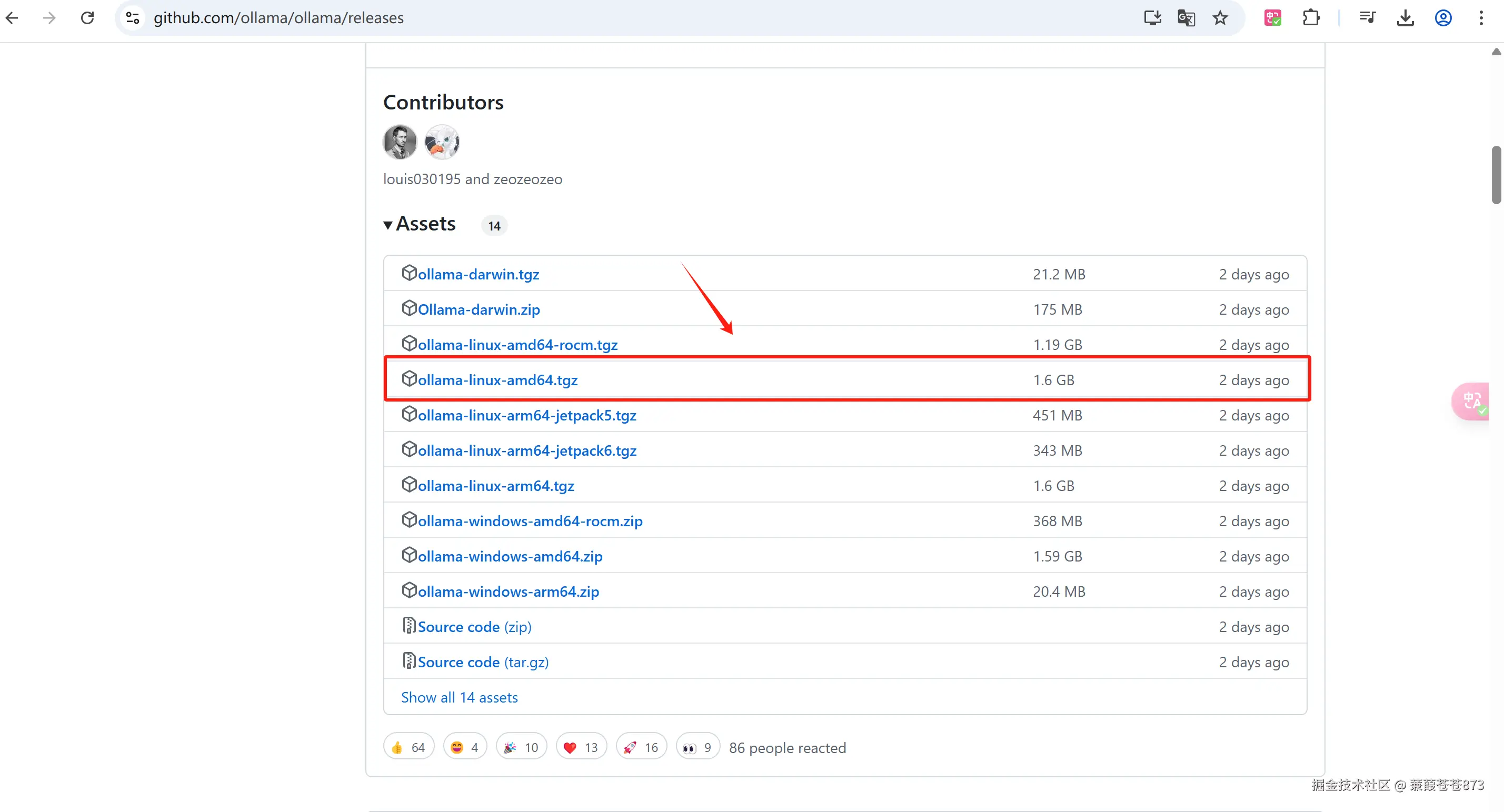
2.選擇ollama-linux-amd64.tgz
5.3.4.github下載加速
github.moeyy.xyz/ 但是實測下來用不了因為文件1.6個G太大了會變成下圖這樣,老老實實慢慢下載

5.3.5 上傳文件到服務器并啟動
這是魔塔社區提供的SSH連接服務器的方式: 鏈接點此
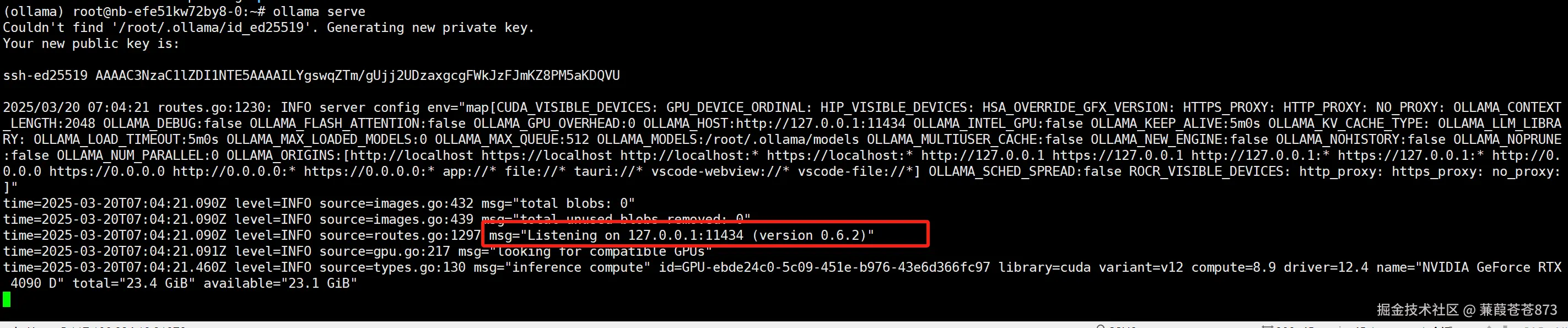
啟動ollama服務:ollama serve
- 出現下圖內容為啟動成功:
-
服務開啟后默認端口是:11434
-
服務啟動后,不要關閉這個窗口,另開一個窗口運行代碼(重要,關了服務就沒了)
可使用 ollama -v 查看版本

使用 ollama list 查看模型,現在是沒有的

5.3.6 ollama中添加模型
1.進入官網找到千問2.5
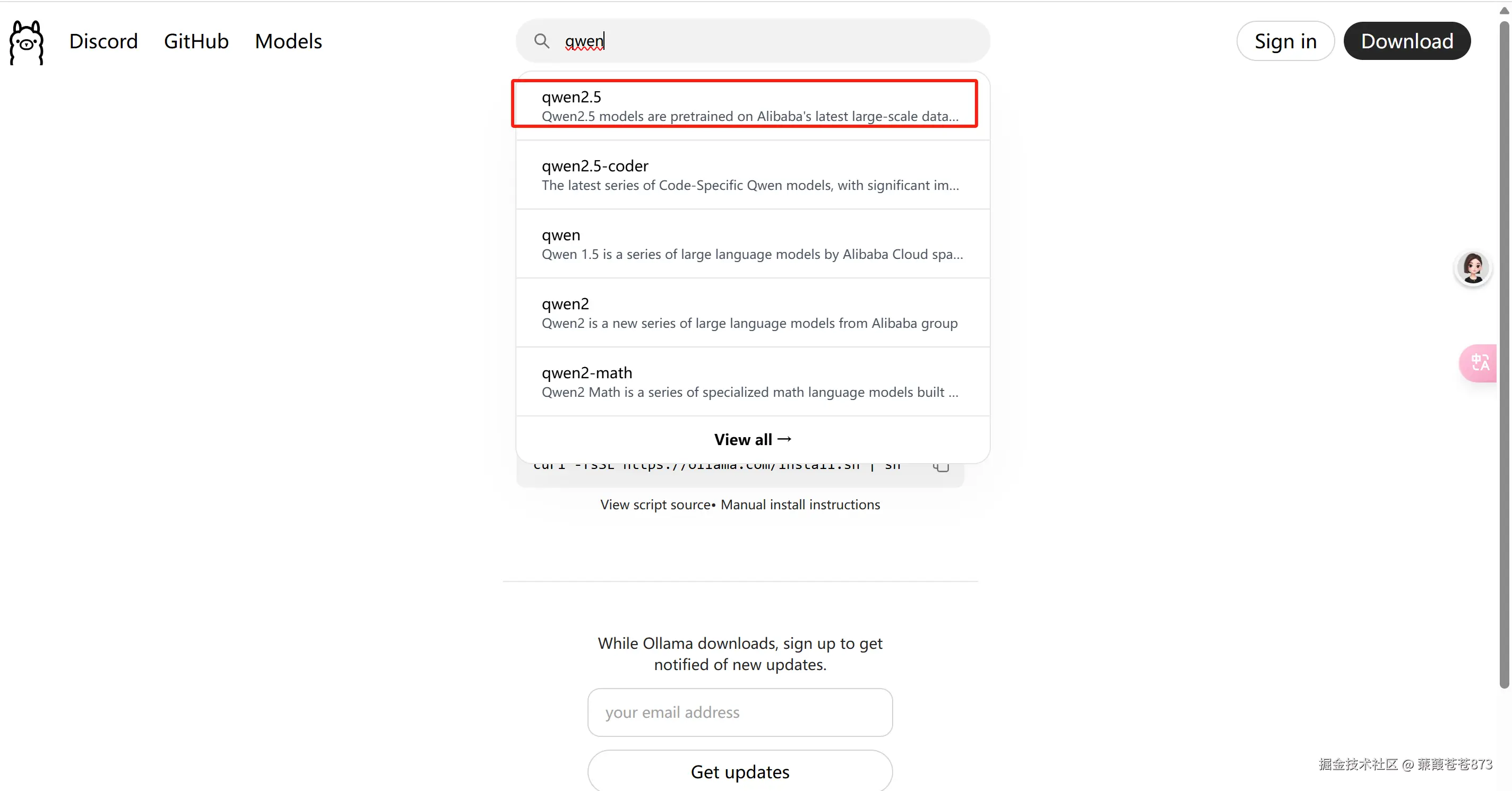
2.選擇0.5b版本,復制命令并在服務器執行
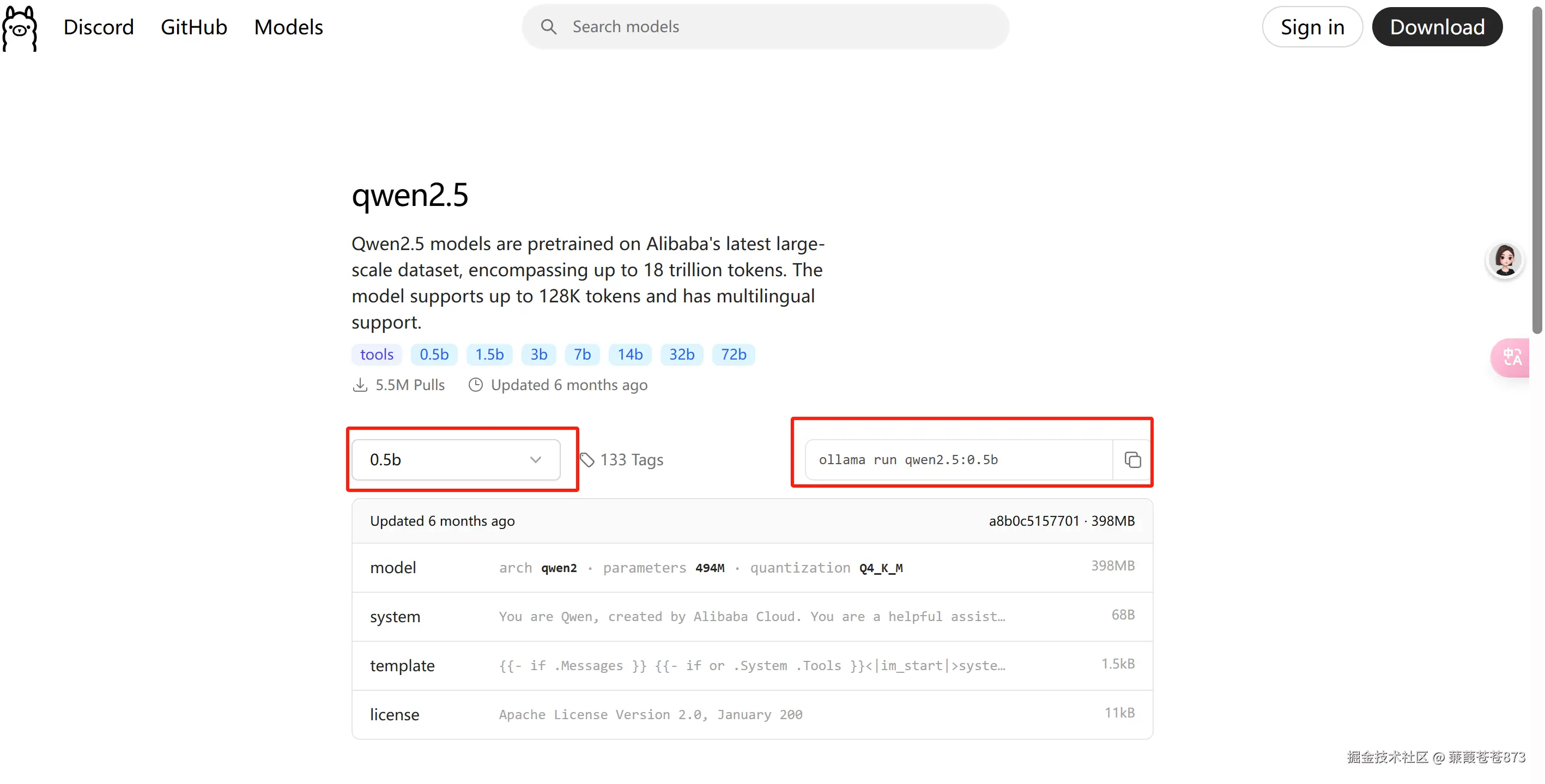
ollama run qwen2.5:0.5b:執行后就會從ollama官網拉取這個模型,拉取下來后就可以直接使用。
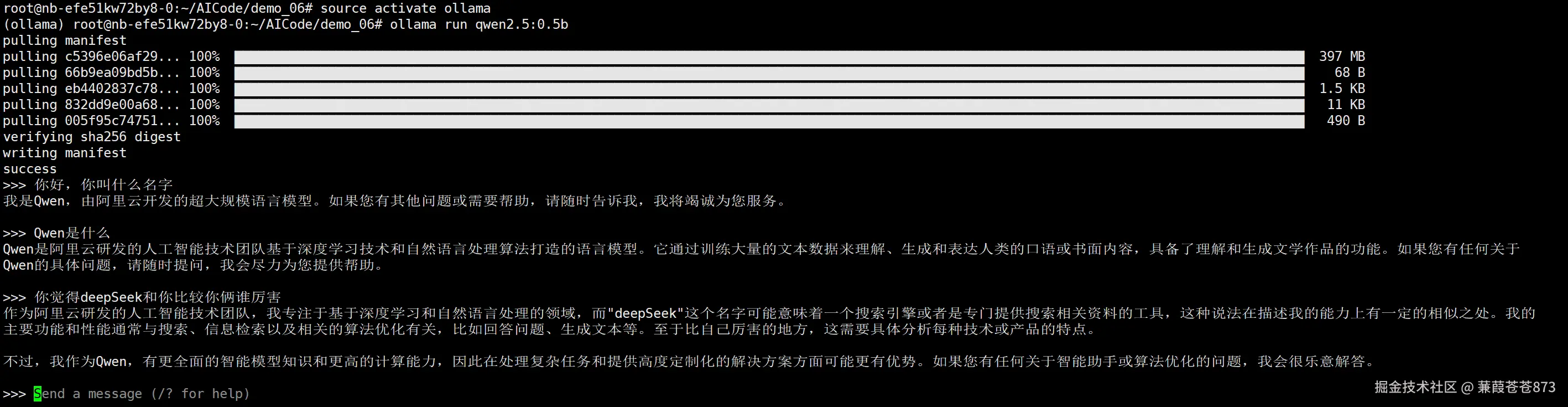
有幾個問題:
-
前面下載了一個千問的模型,為啥不能直接跑?
因為ollama,他只能支持GGUF格式的模型,所以如果要跑ollama的模型,只有兩個選擇。第一個選擇就是從它的官網上面去找模型,然后進行下載。第二個選擇是,使用魔塔社區model scope的這個模型庫去搜索GGUF格式的模型。
-
什么是
GGUF?一般指的是量化后的模型(閹割版),比正常的模型小一點,量化的缺點就算模型的效果會會變差了。
所以這個水平其實不是千問0.5B真實的水平,因為它是被量化之后的水平。但是量化帶來的優勢就在于模型的文件會變得更小,推理速度會更快,對于硬件的要求會更低。所以說ollama針對的是個人用戶,它不針對于企業。
當然
ollama也可以跑不量化的模型。
5.3.7 使用代碼調用ollama中的千問
目前的大模型推理框架里面,它的這個訪問地址的接口協議都是OpenAI API的協議OpenAI API的協議,我們可以使用OpenAI API的風格來調用這個模型,調用ollama的這個模型。
model="qwen2.5:0.5b",需要使用 ollama list 查看模型,用哪個寫哪個:

環境中是沒有openAi 的服務的執行:pip install openai 命令安裝
#使用openai的API風格調用ollama
from openai import OpenAIclient = OpenAI(base_url="http://localhost:11434/v1/",api_key="ollamaCall")chat_completion = client.chat.completions.create(messages=[{"role":"user","content":"你好,請介紹下你自己。"}],model="qwen2.5:0.5b"
)
print(chat_completion.choices[0])
成功:

六、vLLM工具
6.1 vLLM是什么
vLLM 是一個專為大語言模型(LLM)推理和服務設計的高效開源庫,由加州大學伯克利分校等團隊開發。它通過獨特的技術優化,顯著提升了模型推理的速度和吞吐量,特別適合高并發、低延遲的應用場景。
6.2 核心技術:PagedAttention
內存管理優化: 借鑒操作系統的內存分頁思想,將注意力機制的鍵值(KV Cache)分割成小塊(分頁),按需動態分配顯存。
解決顯存碎片問題: 傳統方法因顯存碎片導致利用率低(如僅60-70%),PagedAttention使顯存利用率達99%以上,支持更長上下文并行處理。
性能提升:相比 Hugging Face Transformers,吞吐量最高提升30倍。
6.3 核心優勢
極高性能: 單GPU支持每秒上千請求(如A100處理100B參數模型),適合高并發API服務。
全面兼容性: 支持主流模型(如Llama、GPT-2/3、Mistral、Yi),無縫接入Hugging Face模型庫。
簡化部署: 僅需幾行代碼即可啟動生產級API服務,支持動態批處理、流式輸出等。
開源社區驅動: 活躍開發者迭代優化,支持多GPU分布式推理。
6.4 使用vLLM
6.4.1 進入官網地址
vLLM官網地址
vLLM對環境是有要求的:
- 操作系統:Linux
- Python:3.8 - 3.12
- GPU:計算能力 7.0 或更高(例如 V100、T4、RTX20xx、A100、L4、H100 等,顯存16GB以上的基本都可以)
6.4.2 創建vLLM的Conda環境
阿里云魔塔社區免費給的服務器每次開啟需要重新激活conda:source /mnt/workspace/miniconda3/bin/activate
這個vLLM他基于CUDA的,他與CUDA的版本是掛鉤的,所以萬萬不能在base環境裝vLLM,因為一旦你在base環境上面裝了之后的話,只要你base環境的CUDA版本不是12.11的版本,它就會把你的CUDA給你卸載了,裝它對應的這個版本。目前的vLMM只支持兩個版本,一個是CUDA12.1,另外一個是CUDA11.8,其他的他不支持,所以這個玩意兒跟CUDA掛鉤。
命令:conda create -n vLLM python==3.12 -y
6.4.3 激活vLLM的Conda環境
命令:conda activate** **vLLM
從base切換到vLLM成功。
6.4.4 執行安裝vLLM
命令:pip install vllm
6.4.5 開啟vLLM服務
命令:vllm serve +模型絕對路徑
vllm serve /mnt/workspace/LLM/Qwen/Qwen2.5-0.5B-Instruct
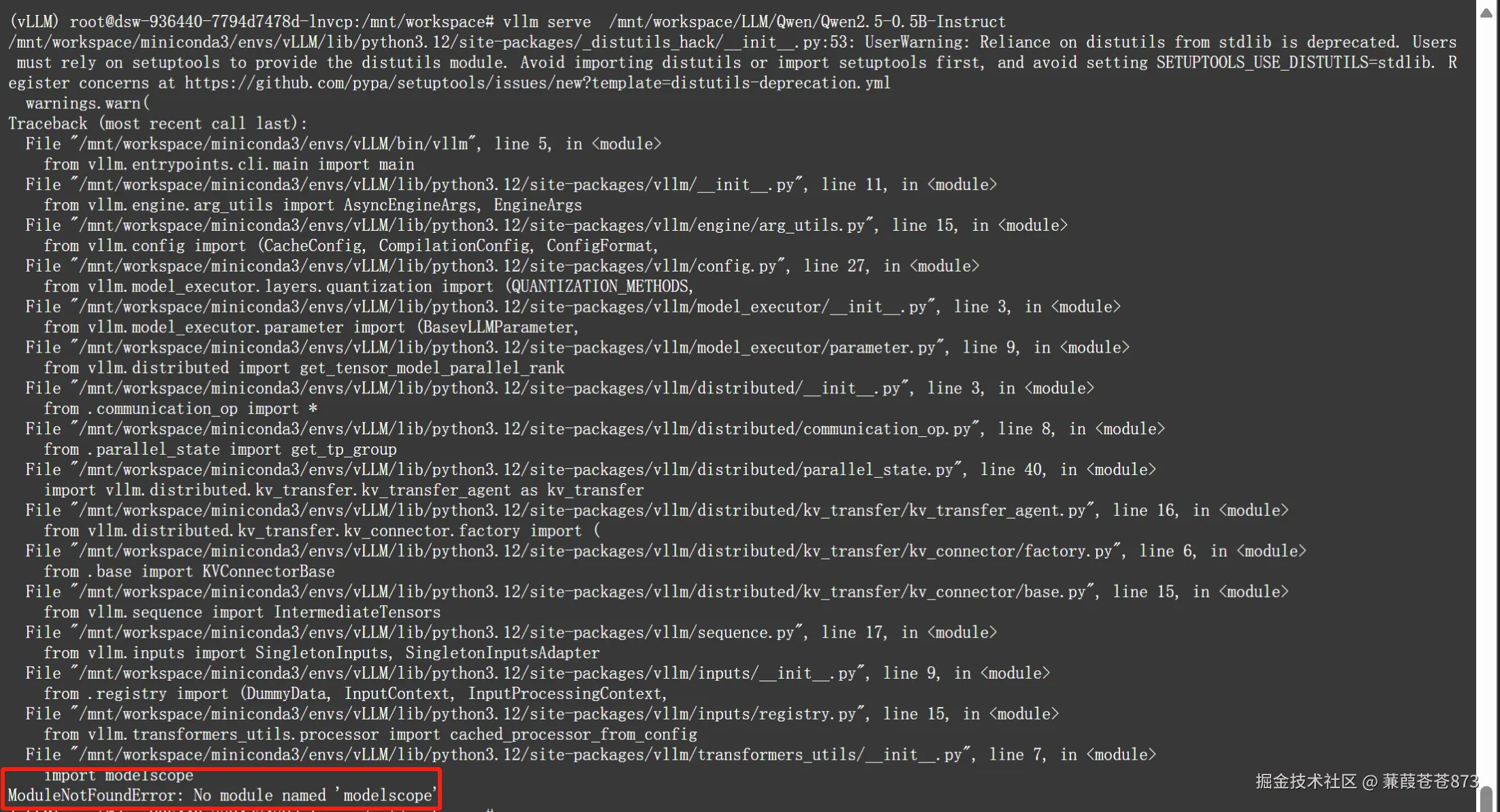
產生這個錯誤是因為服務器第一次裝的時候在root環境里面,新建的vLLM環境里面缺失modelscope的依賴包,所以執行pip install modelscope 安裝即可。
啟動成功:
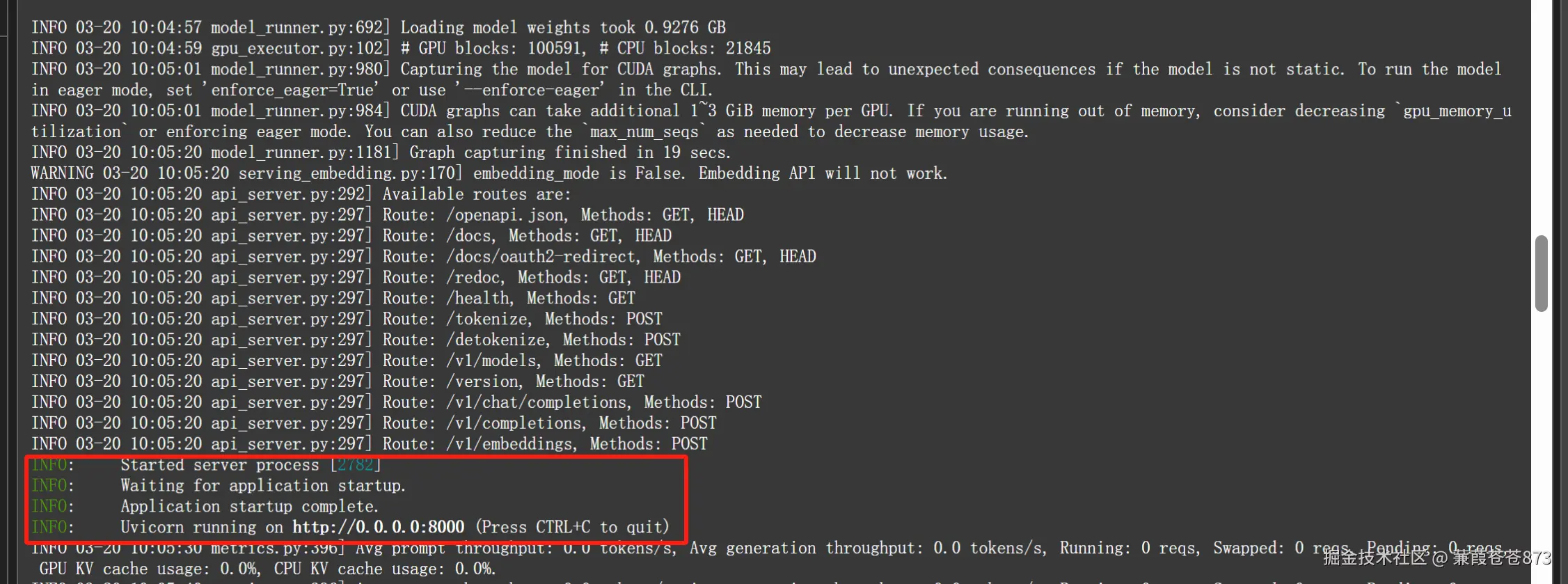
- 服務的端口是
8000
6.4.6 使用代碼調用vLLM服務中的千問
#多輪對話
from openai import OpenAI#定義多輪對話方法
def run_chat_session():#初始化客戶端client = OpenAI(base_url="http://localhost:8000/v1/",api_key="vLLMCall")#初始化對話歷史chat_history = []#啟動對話循環while True:#獲取用戶輸入user_input = input("用戶:")if user_input.lower() == "exit":print("退出對話。")break#更新對話歷史(添加用戶輸入)chat_history.append({"role":"user","content":user_input})#調用模型回答try:chat_complition = client.chat.completions.create(messages=chat_history,model="/mnt/workspace/LLM/Qwen/Qwen2.5-0.5B-Instruct")#獲取最新回答model_response = chat_complition.choices[0]print("AI:",model_response.message.content)#更新對話歷史(添加AI模型的回復)chat_history.append({"role":"assistant","content":model_response.message.content})except Exception as e:print("發生錯誤:",e)break
if __name__ == '__main__':run_chat_session()
調用成功:

七、LMDeploy工具
7.1 LMDeploy是什么
LMDeploy 是一個由 上海人工智能實驗室(InternLM團隊) 開發的工具包,專注于大型語言模型(LLM)的壓縮、部署和服務化。它的目標是幫助開發者和企業更高效地在實際場景中應用大模型(如百億到千億參數規模模型),解決高計算資源消耗和延遲等問題。
7.2 核心特點
- 高效推理優化
- 模型壓縮:支持 KV8 量化和 Weight INT4 量化,顯著降低顯存占用(最高可減少 50%),提升推理速度。
- 持續批處理(
Continuous Batch) :動態合并用戶請求的輸入,提高 GPU 利用率。 - 頁顯存管理:通過類似操作系統的顯存管理策略,進一步提升吞吐量。
- 多后端支持
- 內置高性能推理引擎 TurboMind,支持 Triton 和
TensorRT-LLM作為后端,適配本地和云端部署。 - 兼容 Transformers 模型結構,輕松部署
Hugging Face等平臺的預訓練模型。
- 多模態擴展
- 支持視覺-語言多模態模型(如 LLaVA),實現端到端的高效推理。
- 便捷的服務化
- 提供
RESTful API和 WebUI,支持快速搭建模型服務,適配云計算、邊緣計算等場景。
7.3 核心技術
-
KV Cache量化減少推理過程中鍵值(Key-Value)緩存的內存占用。
-
W4A16量化將模型權重壓縮至 INT4 精度,保持精度損失極小(<1%)。
-
深度并行化
利用模型并行、流水線并行等技術,支撐千億級模型的分布式部署。
7.4 使用LMDeploy
7.4.1 進入官網
LMDeploy官網
7.4.2 創建LMDeploy的Conda環境
命令:conda create -n lmdeploy python==3.12 -y
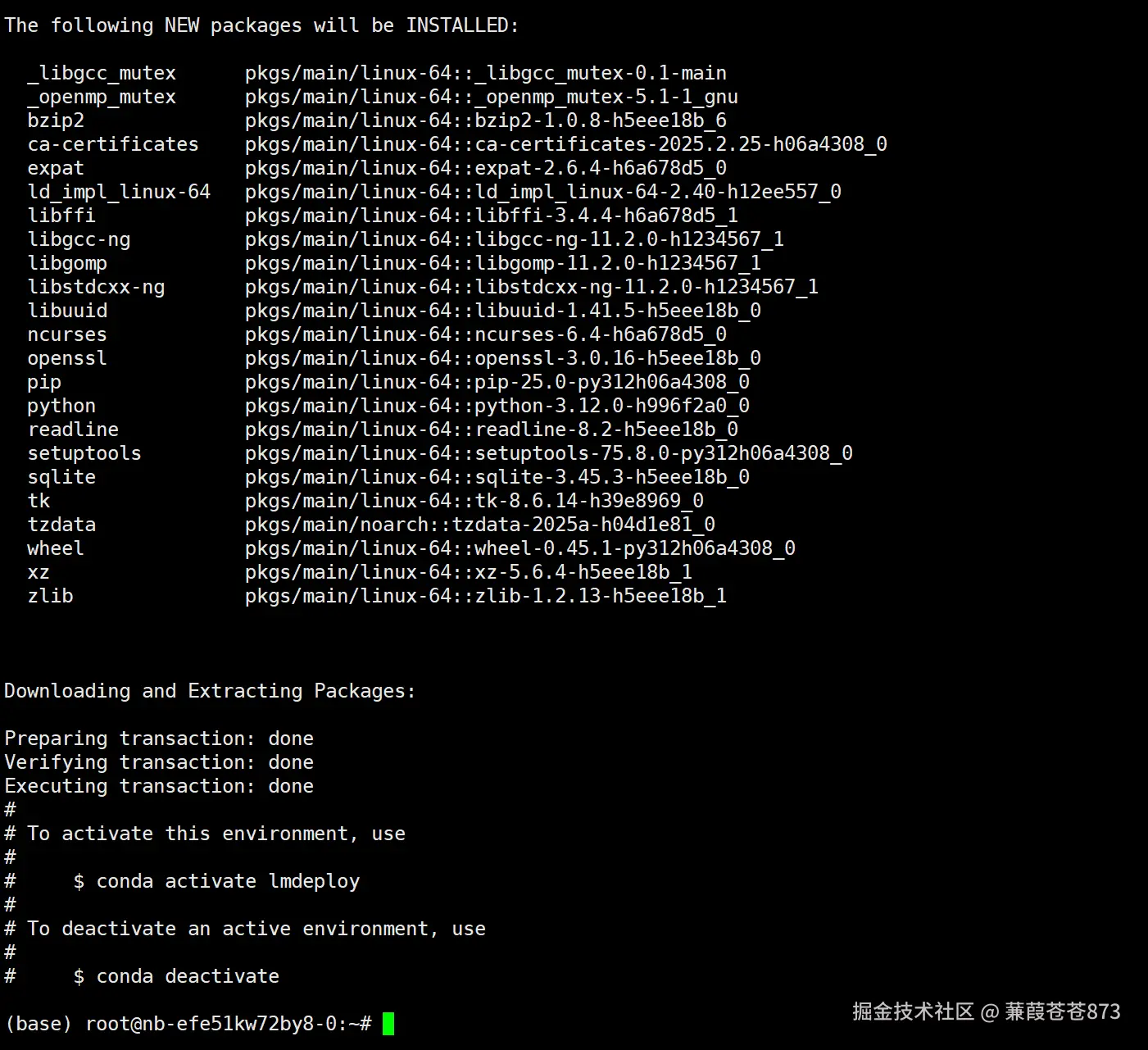
7.4.3 激活LMDeploy的Conda環境
命令:conda activate lmdeploy

7.4.4 執行安裝LMDeploy
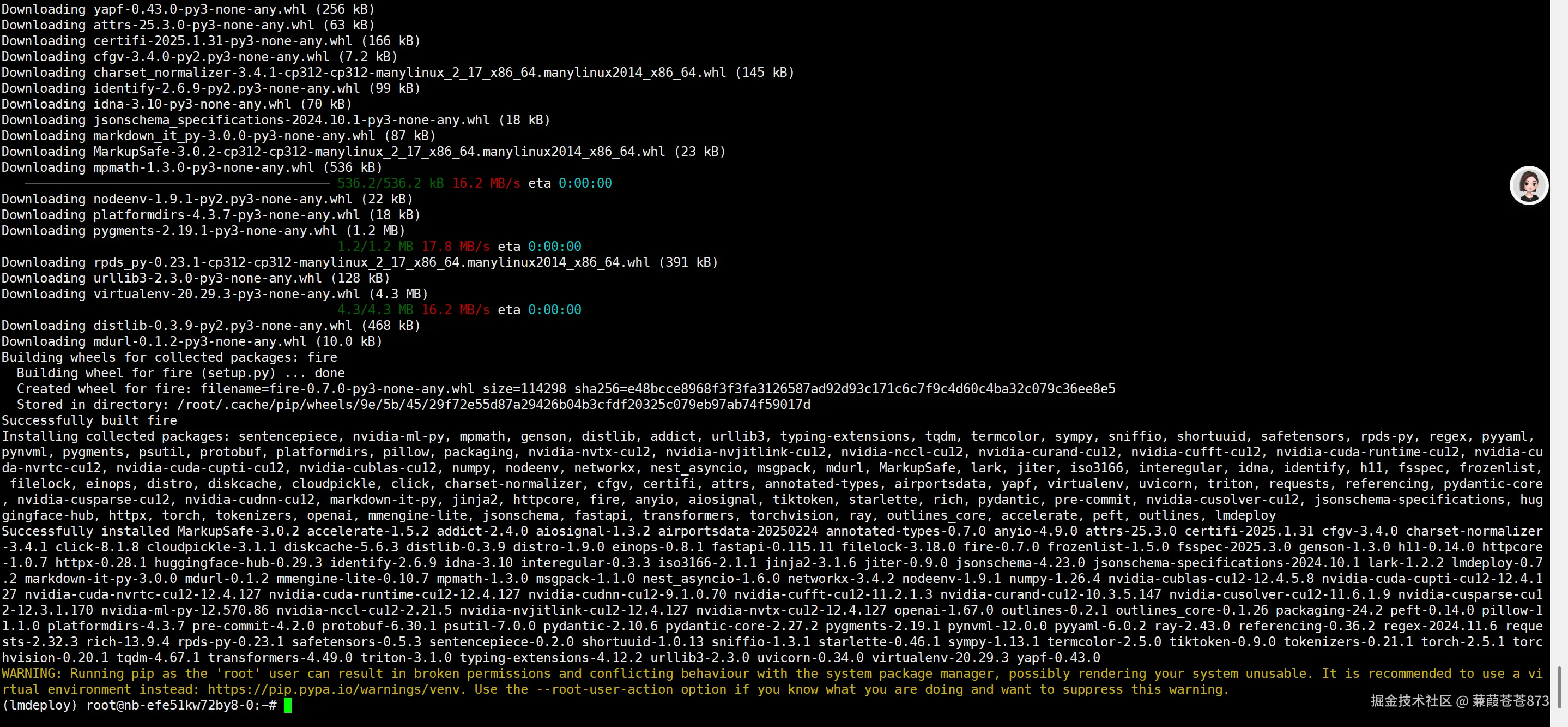
命令:pip install lmdeploy
7.4.5 開啟LMDeploy服務
lmdeploy serve api_server +模型的全路徑
- 執行:
lmdeploy serve api_server /root/LLM/Qwen/Qwen2.5-0.5B-Instruct,報了ModuleNotFoundError: No module named 'partial_json_parser',
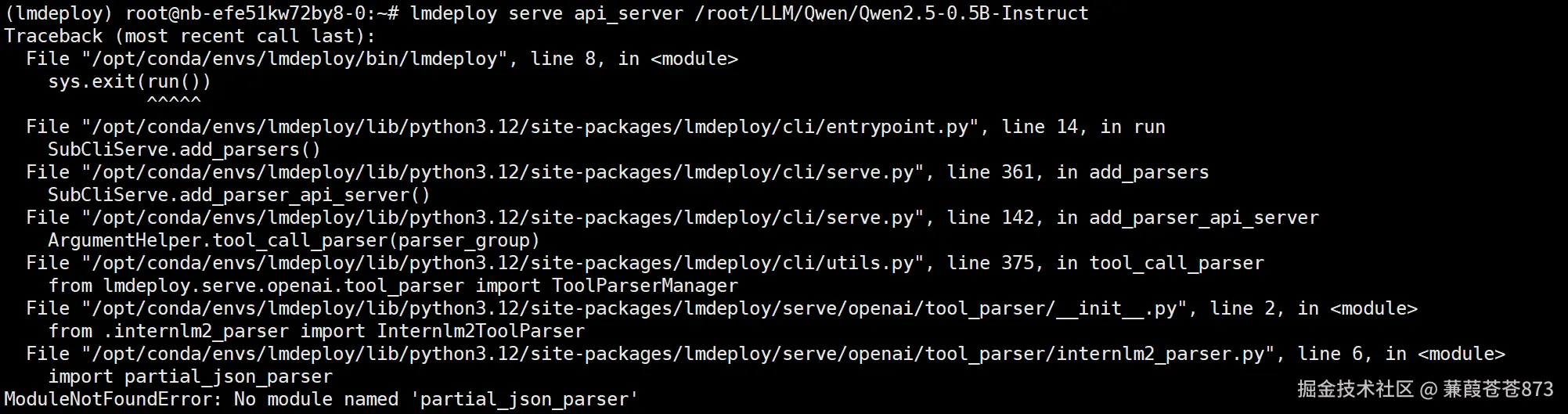
**可能是因為lmdeploy與python3.12版本的兼容問題,執行pip install partial-json-parser命令:

重新執行:lmdeploy serve api_server /root/LLM/Qwen/Qwen2.5-0.5B-Instruct
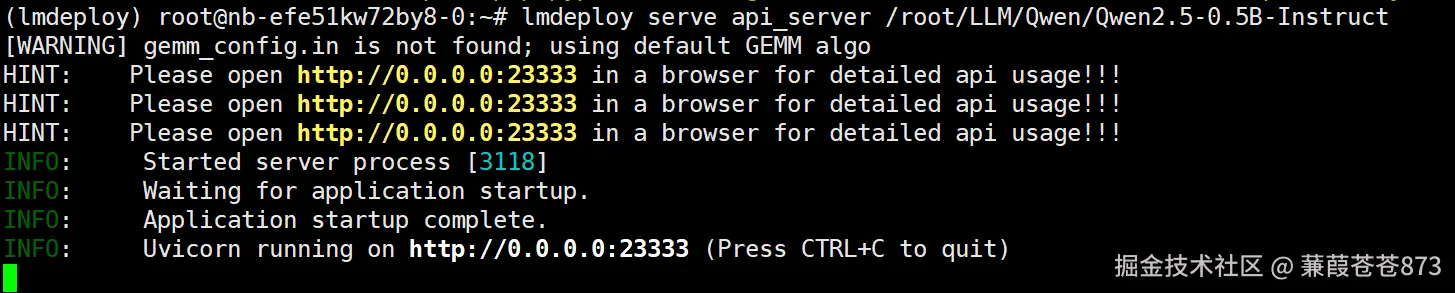
啟動成功!!!
7.4.6 使用代碼調用LMDeploy服務中的千問

LMDeploy 比vLLM在顯存的優化上要強很多,這個框架對于模型的量化支持力度比vLLM要更全要更全。它支持目前的兩種主流量化,一種是離線的量化,一種是在線的量化。





)
)


-雙鏈表)

)




)
)

