隨著人工智能技術的快速發展,多模態模型成為了當前研究的熱點。多模態模型的核心思想是能夠同時處理和理解來自不同模態(如文本、圖像、音頻等)的數據,從而為模型提供更加全面的語境理解和更強的泛化能力。
楊新宇,卡內基梅隆大學博士生,InfiniAI實驗室與Catalyst實驗室成員,AI領域的創新研究者之一。在其最新研究中,楊新宇創新提出了Multiverse模型,這一新型AI架構旨在突破傳統模型的局限,通過動態調整并行度,實現更高效的推理與生成,推動AI模型在多任務和多模態數據處理上的進展。

本課題將分為上下兩篇文章。本文作為上篇,將介紹Multiverse模型的設計理念與應用,深入探討其創新過程及核心亮點。
一、模型架構設計與應用的出發點
基于數據特性——以CNN與RNN為例
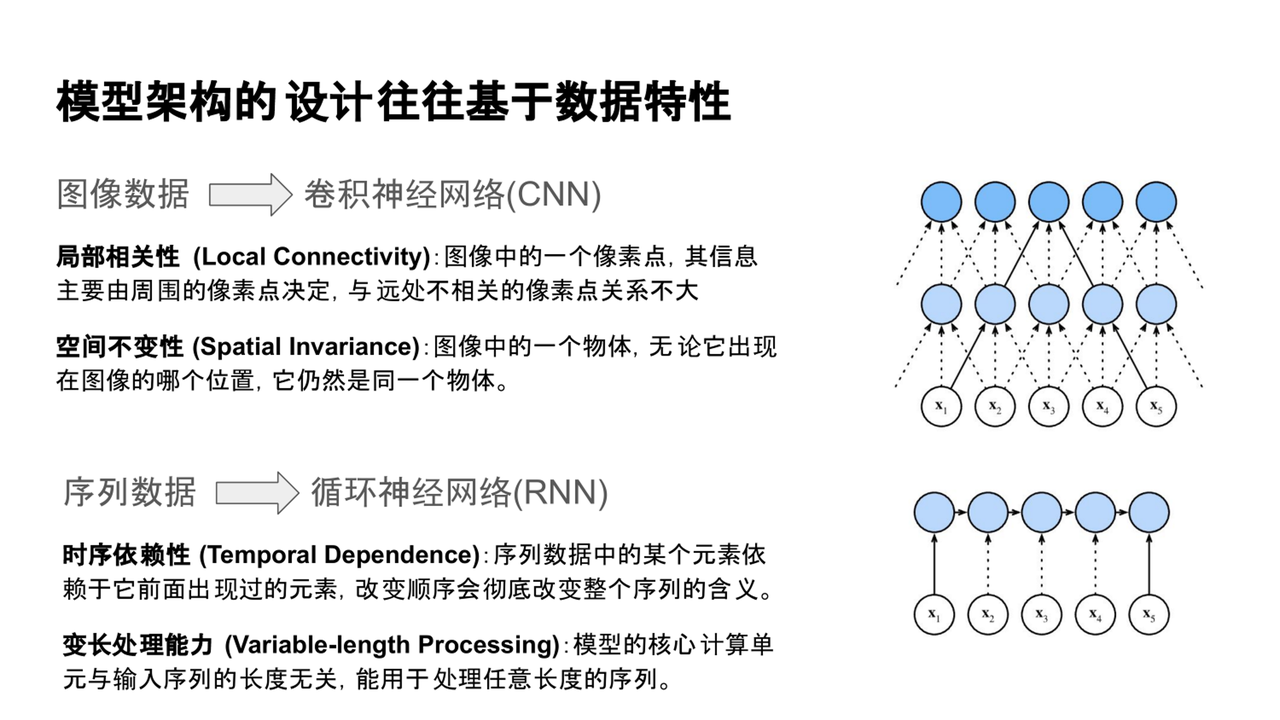
為什么模型架構的設計往往需要以數據本身的特性為基礎?可以從兩個早期的經典例子談起:
1、圖像數據處理:CNN的設計
卷積神經網絡(CNN)最早被廣泛應用于圖像任務。CNN的核心思想是通過滑動窗口提取圖像的局部特征,重點關注局部區域的信息聚合。這種設計來源于對圖像數據特性的理解:
(1)局部相關性:圖像中一個像素點的信息主要由其周圍像素點決定,遠處像素的關系較弱。
(2)空間不變性:物體的語義與其在圖像中的位置無關
通過這些例子,我們可以看到,模型架構設計通常是基于數據特性的需求來進行的。
2、序列數據處理:RNN的設計
循環神經網絡(RNN)用于處理時序數據,尤其是語言等序列數據。其設計的原因在于:
(1)時序依賴性:一個元素通常依賴于其前面出現的元素,順序不可改變。
(2)變長處理能力:RNN具有處理不同長度輸入的能力。
通過這些例子,我們可以看到,模型架構設計通常是基于數據特性的需求來進行的。
基于硬件友好——架構應用的迭代
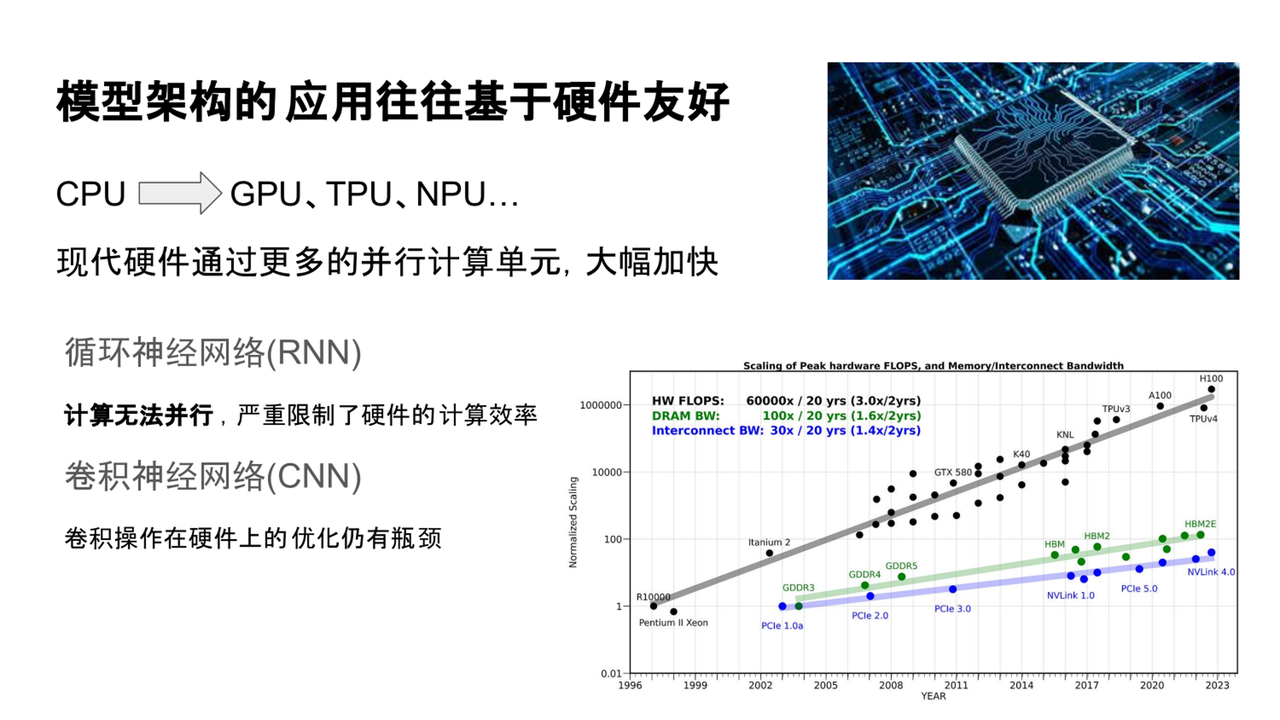
隨著深度學習的發展,我們發現許多模型架構的保留或淘汰,往往依賴于其是否具備硬件友好性。現代大規模模型訓練和推理需要依賴并行計算設備,如NVIDIA GPU、Google TPU、NPU等。這些設備的計算能力不斷提升,使得高效運行大規模模型成為可能。
近年來,英偉達等廠商推出了如A100、H100等GPU架構,以滿足大規模模型對算力的需求。硬件性能的提升使得能夠高效運行參數量巨大的模型成為現實。
但追求硬件效率也導致了一些早期廣泛使用的模型架構逐漸被淘汰,尤其是在硬件計算能力越來越強的背景下。
二、基礎模型:在AI硬件上高效且有效地處理不同模態的數據
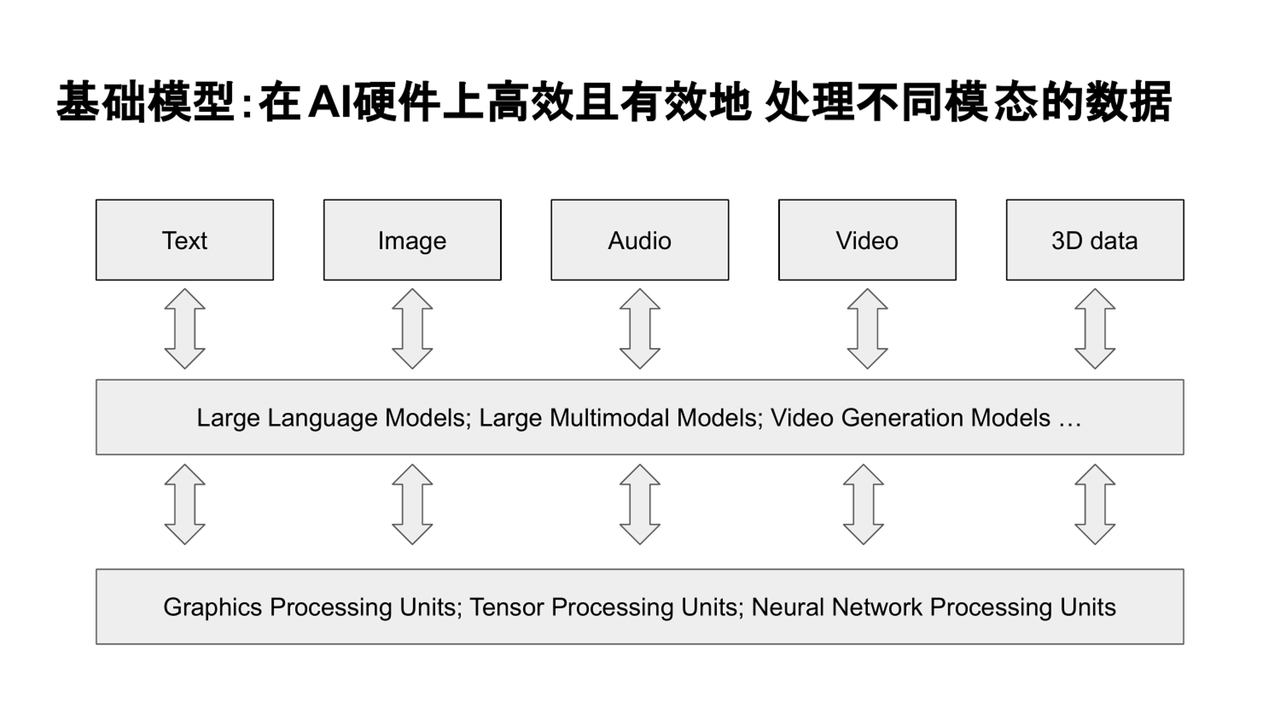
在當前的AI發展趨勢下,“基礎模型”(Foundation Models)成為了熱門話題。這類模型的核心能力是靈活處理多種任務和多模態數據。例如,一個模型不僅要處理文本信息,還要理解圖像、分析語音,甚至生成高質量的內容,同時還要能應用于推理、信息抽取、對話理解等多種任務。這種廣泛的適應性使得泛化能力成為當前模型設計的關鍵目標。
在這一背景下,Transformer架構成為了當前主流大模型的基礎架構。其核心機制——注意力機制,允許每個token與其他位置的信息進行靈活的交互,從而實現全局信息的融合。這種無先驗、完全自適應的設計方式使得Transformer適用于多任務、多模態數據處理,特別是對于需要高泛化能力的基礎模型,Transformer的設計理念非常契合。
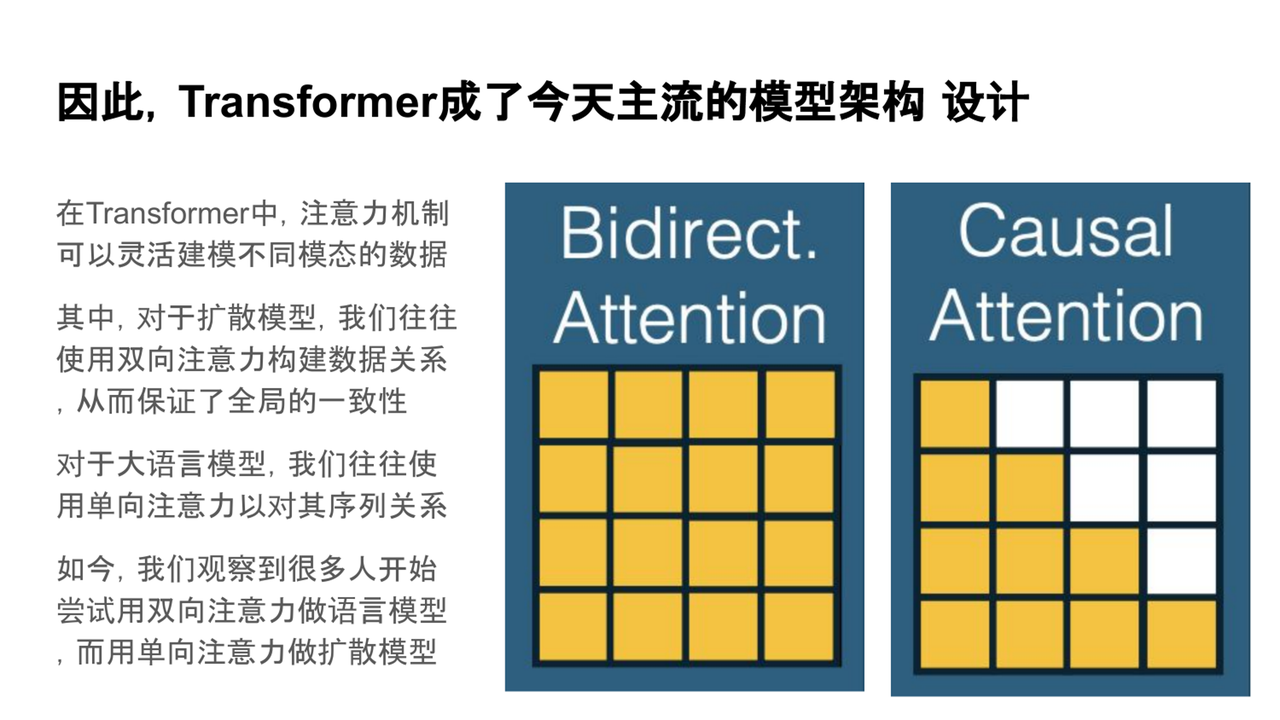
與傳統的 RNN 和 CNN 不同,Transformer 并不依賴于固定的局部感受野或序列順序等先驗結構,而是提供了一種完全開放的信息建模方式,讓模型根據數據本身去學習最合適的交互模式。這種“無先驗、自適應 ”的設計理念,正好契合了基礎模型對多任務、多模態、高泛化能力的需求。
目前最常見的兩類模型中,一類是廣泛應用于視頻生成等任務的擴散模型(diffusion models) ,另一類則是我們熟知的大語言模型(LLM) 。這兩類模型在注意力機制的設計上各有側重。
目前常見的兩類模型中,**擴散模型(Diffusion Model)和大語言模型(LLM)**都依賴于注意力機制,但它們在設計上有所側重。
-
擴散模型:常用于處理圖像、視頻等數據,通常采用雙向注意力,能夠有效建模全局信息依賴。
-
語言模型(LLM):大多數基于單向注意力機制,適合處理具有明顯序列特性的任務,如文本生成等。
為了解決生成效率問題,研究者們嘗試將擴散模型的思路引入到語言建模中。擴散語言模型(Diffusion Language Models)嘗試打破傳統自回歸建模的順序限制,提升生成效率。該模型通過使用雙向注意力和remask(重新掩碼)機制,能夠在保證生成質量的同時,利用并行計算優勢提升效率。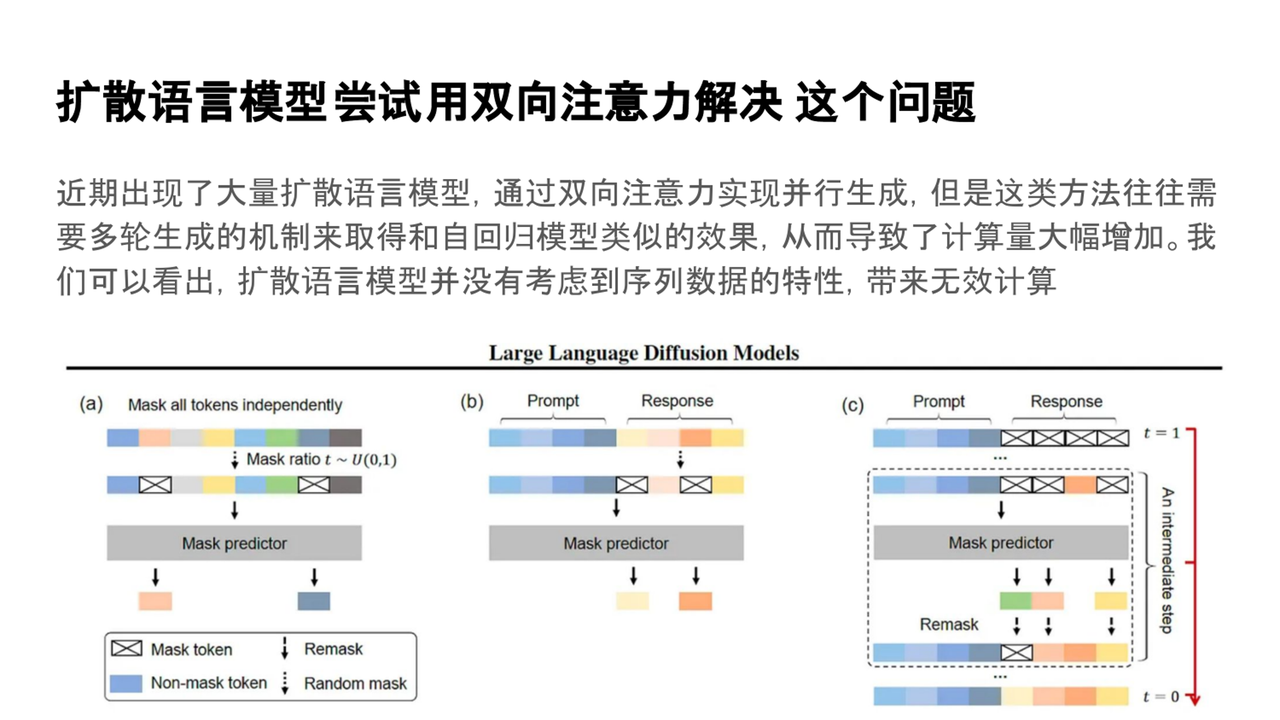
三、應對之策—— Multiverse(多元宇宙模型)
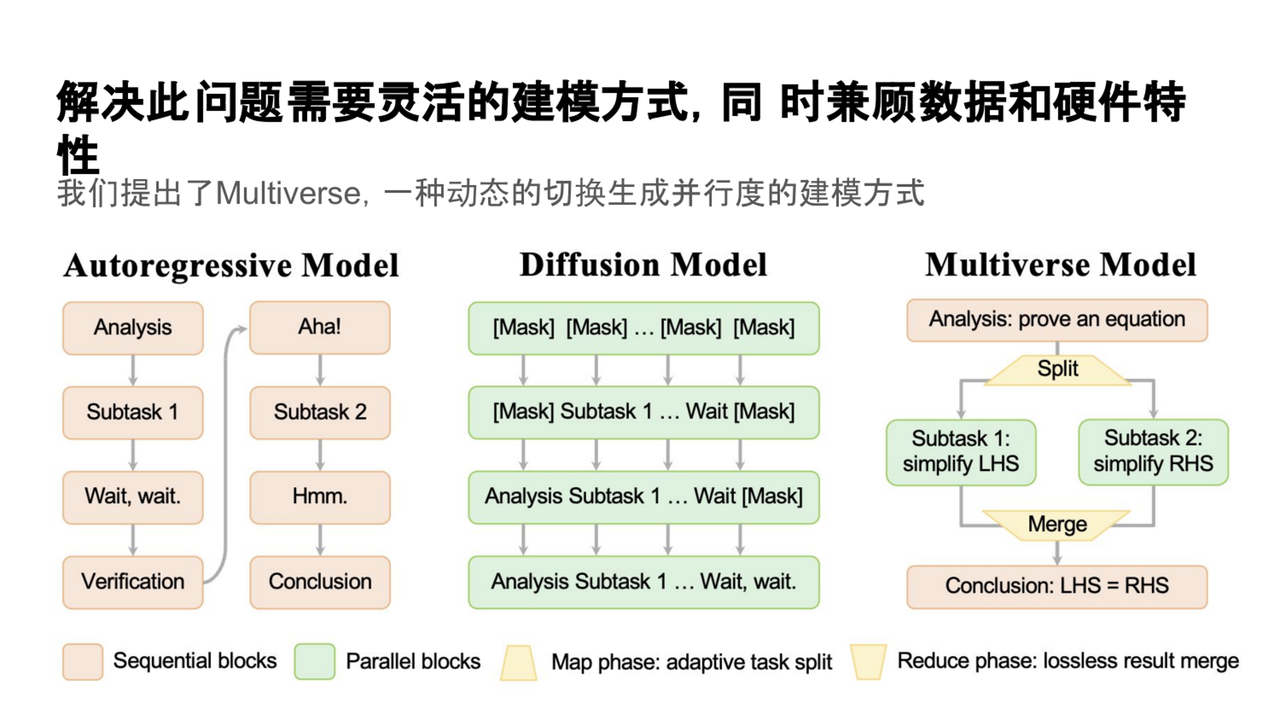
針對現有模型的局限性,楊新宇提出了Multiverse(多元宇宙模型)。該模型的核心思想是根據任務和上下文的不同需求,動態調整生成過程中的并行度,從而提升推理效率和生成質量。
MapReduce 建模機制
Multiverse模型引入了一種新的建模機制——MapReduce機制。在這一機制中,模型會先進入規劃階段,輸出不同子任務的短期計劃。然后,為每個子任務初始化獨立進程進行并行生成,最后再將所有子任務的結果合并,繼續生成。這種流程使得模型能夠在不同任務間靈活切換,并實現高效的并行生成。
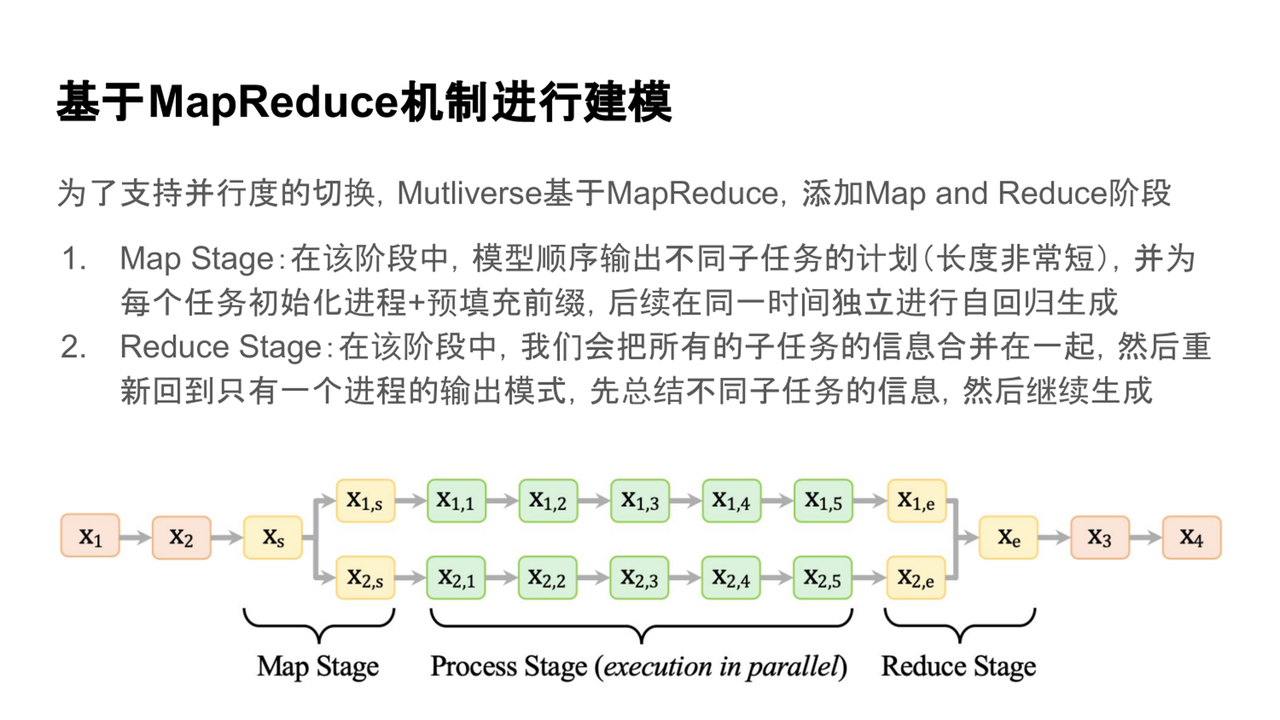
MapReduce機制的實現
MapReduce機制的實現借鑒了編譯器設計中的思想,使用特殊控制字符來引導模型與推理引擎之間的交互。這種設計確保了不同子任務的輸出能夠無損地傳遞給后續的進程,提高了信息處理效率。

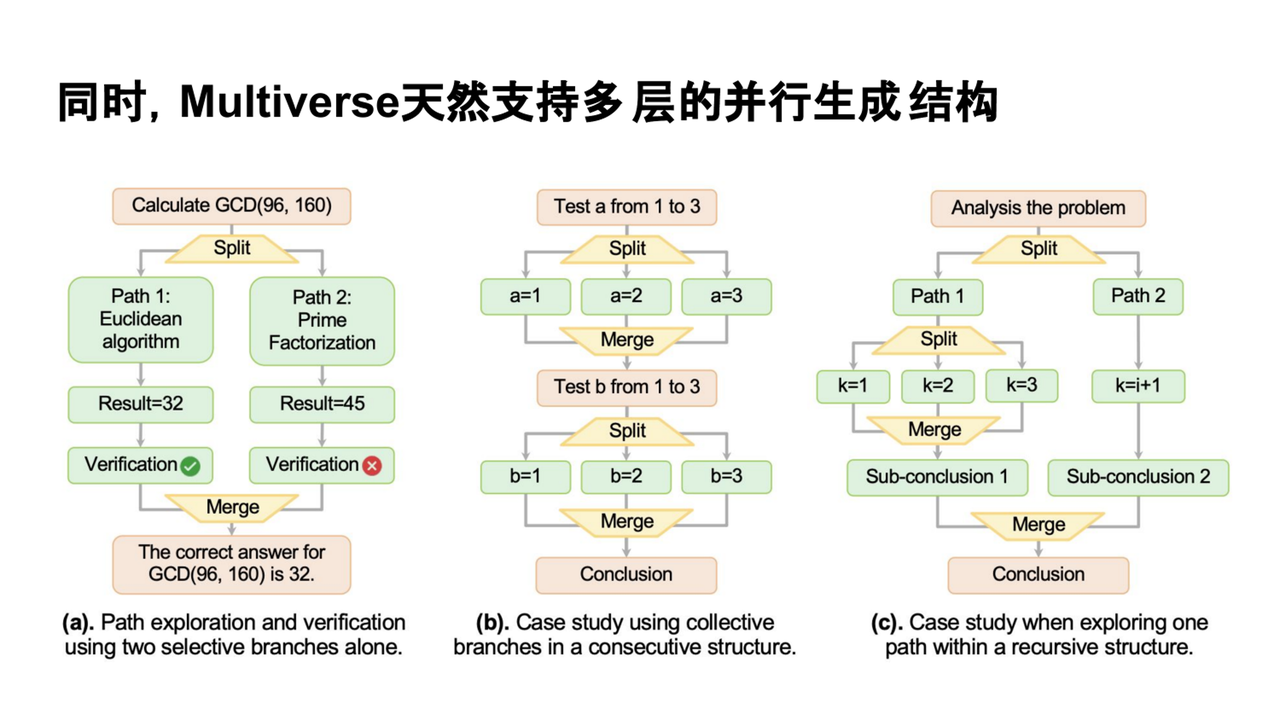
四、在真實任務中落地
對于實際應用中的團隊,尤其是那些資源有限的團隊,如何快速構建AI應用是一個關鍵問題。傳統的自回歸模型可以通過微調快速應用,但Multiverse模型的設計目標是使其具備良好的可遷移性和易用性,即使資源有限的團隊也能輕松構建并部署高效模型。
部署挑戰:數據、算法、引擎
Multiverse模型的實現涉及數據設計、算法設計和系統設計三個方面:
-
數據設計:我們提供了一整套prompting流程,借助現有的自回歸模型推理能力和改寫能力,將數據轉化為Multiverse模型可用的訓練樣本。
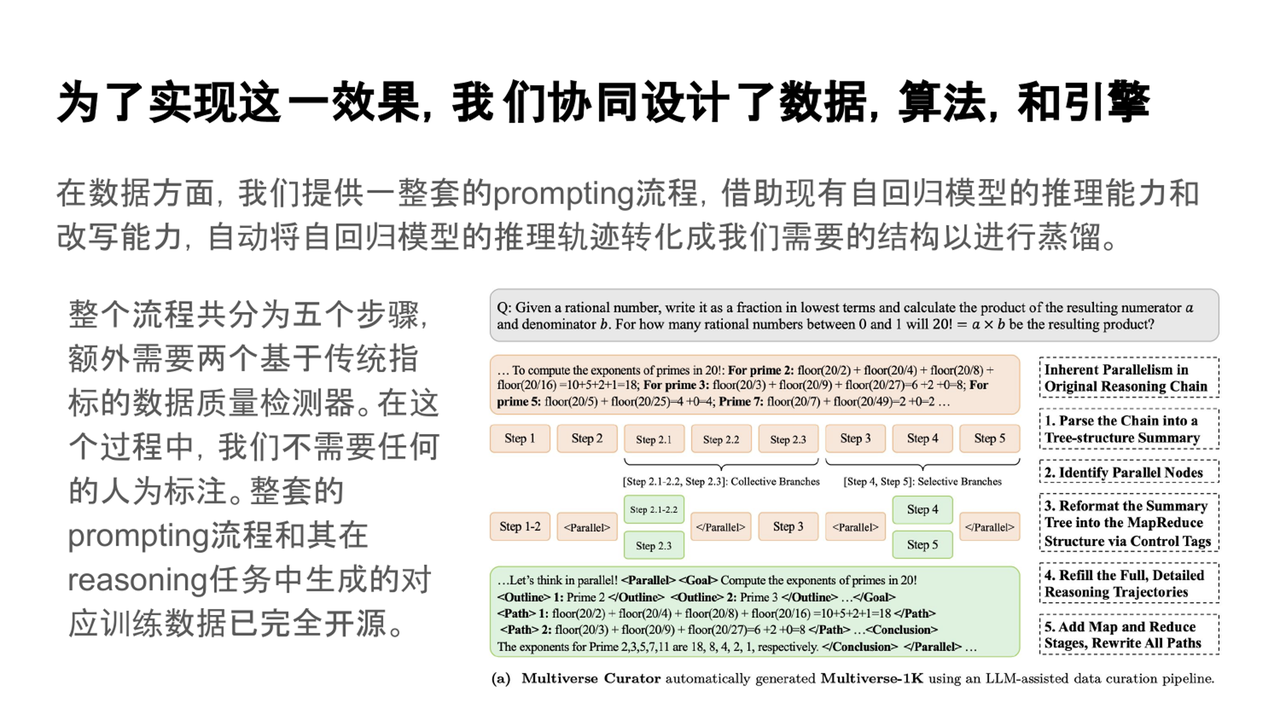
-
算法設計:引入了Multiverse Attention機制,通過精心設計的注意力掩碼,實現任務之間的高效并行生成。

-
系統設計:基于SGLang平臺,開發了Multiverse Engine,通過簡單集成即可支持不同推理場景,實現高效的推理能力。
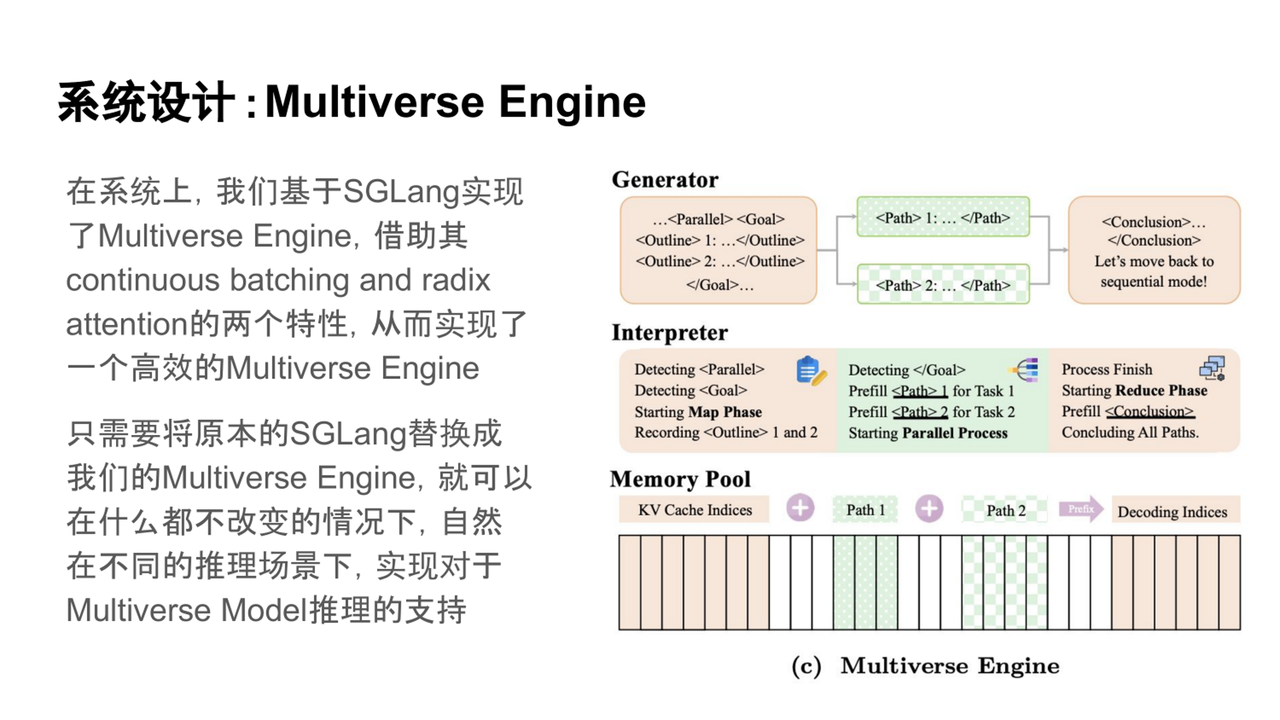
通過這一系統層面的優化設計,我們在實際測試中觀察到了顯著的推理效率提升。為了量化其性能優勢,我們設計了一個基準測試:在相同時間內,測量模型能夠生成的 token 數量,并將其與并行度進行對比分析。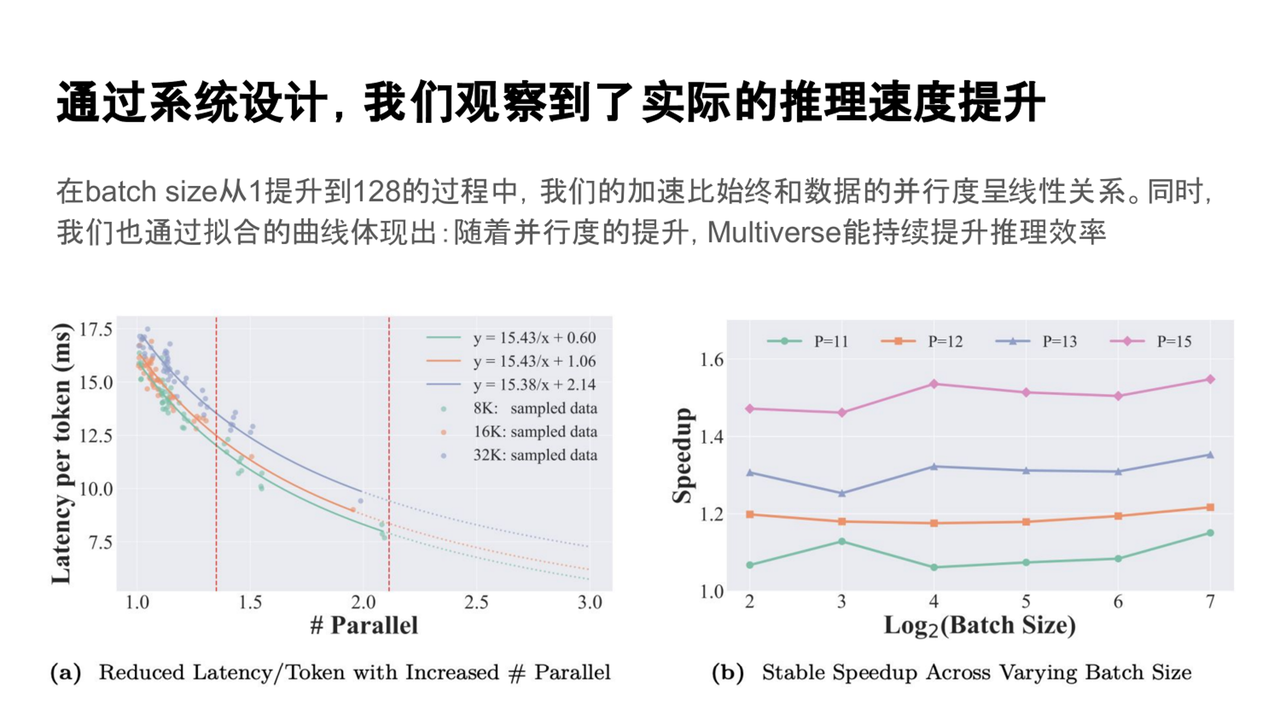
五、實驗與結果
通過系統優化設計,實際測試顯示Multiverse Engine在推理效率上顯著提升。基準測試中,生成不同長度(8K、16K、32K)的任務時,Multiverse Engine的并行效率提高了約1.3到2倍,顯著降低了延遲并增加了輸出內容。實驗結果還表明,提升并行度可進一步增強推理速度,且方法在不同批量大小下表現穩定,特別是在batch size從1到128增加時,系統有效提升了硬件資源利用率,展示了優越的擴展性和穩定性。




)



未完)






與節流(Throttle))

:策略模式)

