注:本文為 “線性代數 · 直觀理解矩陣” 相關合輯。
英文引文,機翻未校。
如有內容異常,請看原文。
Understanding matrices intuitively, part 1
直觀理解矩陣(第一部分)
333 March 201120112011 William Gould
Introduction to Matrix Visualization
矩陣可視化簡介
I want to show you a way of picturing and thinking about matrices. The topic for today is the square matrix, which we will call A\mathbf{A}A. I’m going to show you a way of graphing square matrices, although we will have to limit ourselves to the 2×22 \times 22×2 case. That will be, as they say, without loss of generality. The technique I’m about to show you could be used with 3×33 \times 33×3 matrices if you had a better 333-dimensional monitor, and as will be revealed, it could be used on 3×23 \times 23×2 and 2×32 \times 32×3 matrices, too. If you had more imagination, we could use the technique on 4×44 \times 44×4, 5×55 \times 55×5, and even higher-dimensional matrices.
我想給大家展示一種想象和思考矩陣的方法。今天的主題是方陣,我們將其稱為 A\mathbf{A}A。我會展示一種繪制方陣圖形的方法,不過我們得把范圍限制在 2×22 \times 22×2 的情況。正如人們所說,這不會損失一般性。如果有更好的 333D 顯示器,我要展示的這種方法也適用于 3×33 \times 33×3 矩陣,而且稍后會發現,它同樣適用于 3×23 \times 23×2 和 2×32 \times 32×3 矩陣。要是你想象力更豐富些,這種方法還能用于 4×44 \times 44×4、5×55 \times 55×5 甚至更高維的矩陣。
But we will limit ourselves to 2×22 \times 22×2. A\mathbf{A}A might be
但我們還是先限于 2×22 \times 22×2 矩陣。A\mathbf{A}A 可能是
[211.52]\left[ \begin{matrix} 2 & 1 \\ 1.5 & 2 \\ \end{matrix} \right][21.5?12?]
From now on, I’ll write matrices as
從現在起,我會把矩陣寫成這樣:
A\mathbf{A}A = (222, 111 \ 1.51.51.5, 222)
where commas are used to separate elements on the same row and backslashes are used to separate the rows.
其中,逗號用于分隔同一行的元素,反斜杠用于分隔不同的行。
Transforming Points in Space
空間中的點變換
To graph A\mathbf{A}A, I want you to think about
要繪制 A\mathbf{A}A 的圖形,我希望大家思考這樣一個式子:
y\mathbf{y}y = Ax\mathbf{A}\mathbf{x}Ax
where
其中
y\mathbf{y}y: 2×12 \times 12×1,
A\mathbf{A}A: 2×22 \times 22×2, and
x\mathbf{x}x: 2×12 \times 12×1.
That is, we are going to think about A\mathbf{A}A in terms of its effect in transforming points in space from x\mathbf{x}x to y\mathbf{y}y. For instance, if we had the point
也就是說,我們要從 A\mathbf{A}A 將空間中的點從 x\mathbf{x}x 變換到 y\mathbf{y}y 的作用這個角度來理解 A\mathbf{A}A。例如,如果我們有這樣一個點:
x\mathbf{x}x = (0.750.750.75 \ 0.250.250.25)
then
那么
y\mathbf{y}y = (1.751.751.75 \ 1.6251.6251.625)
because by the rules of matrix multiplication y[1]=0.75×2+0.25×1=1.75y[1] = 0.75 \times 2 + 0.25 \times 1 = 1.75y[1]=0.75×2+0.25×1=1.75 and y[2]=0.75×1.5+0.25×2=1.625y[2] = 0.75 \times 1.5 + 0.25 \times 2 = 1.625y[2]=0.75×1.5+0.25×2=1.625. The matrix A\mathbf{A}A transforms the point (0.750.750.75 \ 0.250.250.25) to (1.751.751.75 \ 1.6251.6251.625). We could graph that:
因為根據矩陣乘法規則,y[1]=0.75×2+0.25×1=1.75y[1] = 0.75 \times 2 + 0.25 \times 1 = 1.75y[1]=0.75×2+0.25×1=1.75,y[2]=0.75×1.5+0.25×2=1.625y[2] = 0.75 \times 1.5 + 0.25 \times 2 = 1.625y[2]=0.75×1.5+0.25×2=1.625。矩陣 A\mathbf{A}A 將點 (0.750.750.75 \ 0.250.250.25) 變換成了 (1.751.751.75 \ 1.6251.6251.625)。我們可以把這個過程畫出來:

Visualizing Matrix Transformations
可視化矩陣變換
To get a better understanding of how A\mathbf{A}A transforms the space, we could graph additional points:
為了更好地理解 A\mathbf{A}A 是如何變換空間的,我們可以繪制更多的點:

I do not want you to get lost among the individual points which A\mathbf{A}A could transform, however. To focus better on A\mathbf{A}A, we are going to graph y\mathbf{y}y = Ax\mathbf{A}\mathbf{x}Ax for all x\mathbf{x}x. To do that, I’m first going to take a grid,
不過,我不希望大家迷失在 A\mathbf{A}A 所能變換的各個點中。為了更專注于 A\mathbf{A}A,我們要為所有的 x\mathbf{x}x 繪制 y\mathbf{y}y = Ax\mathbf{A}\mathbf{x}Ax 的圖形。為此,我首先會用一個網格:
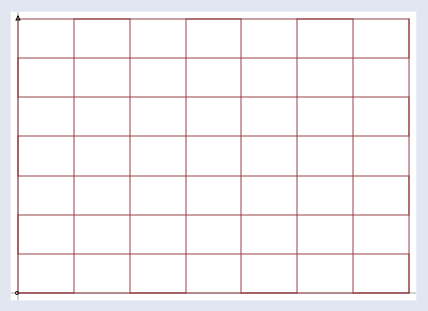
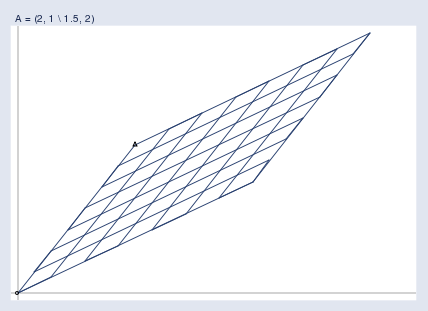
One at a time, I’m going to take every point on the grid, call the point x\mathbf{x}x, and run it through the transform y\mathbf{y}y = Ax\mathbf{A}\mathbf{x}Ax. Then I’m going to graph the transformed points:
我會逐個取出網格上的每個點,將其稱為點 x\mathbf{x}x,然后通過變換 y\mathbf{y}y = Ax\mathbf{A}\mathbf{x}Ax 對其進行處理。接著,我會繪制變換后的點:
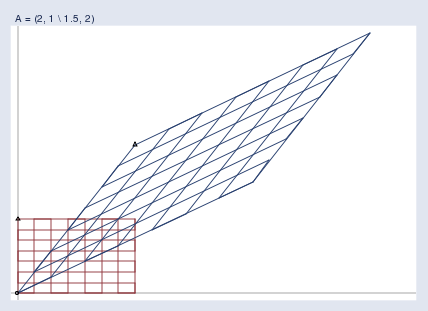
Finally, I’m going to superimpose the two graphs:
最后,我會將這兩個圖形疊加在一起:
Matrix Effects
矩陣的作用
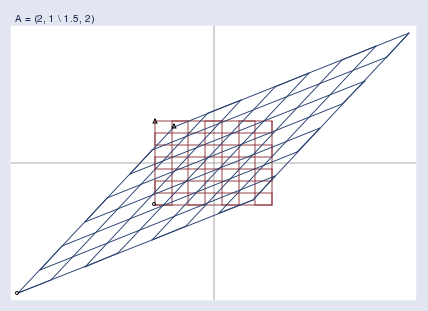
In this way, I can now see exactly what A\mathbf{A}A = (222, 111 \ 1.51.51.5, 222) does. It stretches the space, and skews it.
通過這種方式,我就能清楚地看到 A\mathbf{A}A = (222, 111 \ 1.51.51.5, 222) 的作用了。它會拉伸空間,并且使空間發生扭曲。
I want you to think about transforms like A\mathbf{A}A as transforms of the space, not of the individual points. I used a grid above, but I could just as well have used a picture of the Eiffel tower and, pixel by pixel, transformed it by using y\mathbf{y}y = Ax\mathbf{A}\mathbf{x}Ax. The result would be a distorted version of the original image, just as the the grid above is a distorted version of the original grid. The distorted image might not be helpful in understanding the Eiffel Tower, but it is helpful in understanding the properties of A\mathbf{A}A. So it is with the grids.
我希望大家把像 A\mathbf{A}A 這樣的變換看作是對空間的變換,而不是對單個點的變換。我上面用了網格,但我也完全可以用埃菲爾鐵塔的圖片,逐個像素地通過 y\mathbf{y}y = Ax\mathbf{A}\mathbf{x}Ax 進行變換。結果會是原始圖像的扭曲版本,就像上面的網格是原始網格的扭曲版本一樣。扭曲后的圖像可能對理解埃菲爾鐵塔沒什么幫助,但對理解 A\mathbf{A}A 的性質卻很有幫助。網格的作用也是如此。
Notice that in the above image there are two small triangles and two small circles. I put a triangle and circle at the bottom left and top left of the original grid, and then again at the corresponding points on the transformed grid. They are there to help you orient the transformed grid relative to the original. They wouldn’t be necessary had I transformed a picture of the Eiffel tower.
注意到在上面的圖像中有兩個小三角形和兩個小圓圈。我在原始網格的左下和左上位置各放了一個三角形和一個圓圈,然后在變換后的網格的對應位置也放了同樣的圖形。它們的作用是幫助你確定變換后的網格相對于原始網格的方位。如果我變換的是埃菲爾鐵塔的圖片,這些標記就沒必要了。
I’ve suppressed the scale information in the graph, but the axes make it obvious that we are looking at the first quadrant in the graph above. I could just as well have transformed a wider area.
我隱藏了圖形中的比例尺信息,但從坐標軸可以明顯看出,我們看到的是上面圖形中的第一象限。我也完全可以變換一個更大的區域。
Matrix Transformations in General
矩陣變換的一般性
Regardless of the region graphed, you are supposed to imagine two infinite planes. I will graph the region that makes it easiest to see the point I wish to make, but you must remember that whatever I’m showing you applies to the entire space.
不管繪制的是哪個區域,你都應該想象成兩個無限延伸的平面。我會選擇最容易說明我想表達的觀點的區域來繪制圖形,但你必須記住,我所展示的內容適用于整個空間。
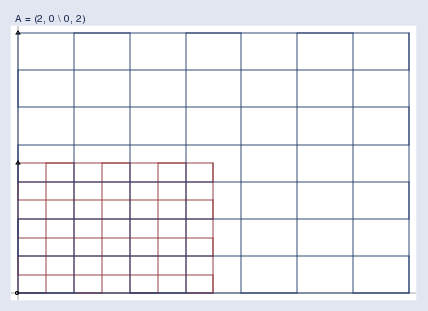
We need first to become familiar with pictures like this, so let’s see some examples. Pure stretching looks like this:
我們首先需要熟悉這樣的圖形,所以讓我們來看一些例子。純粹的拉伸是這樣的:
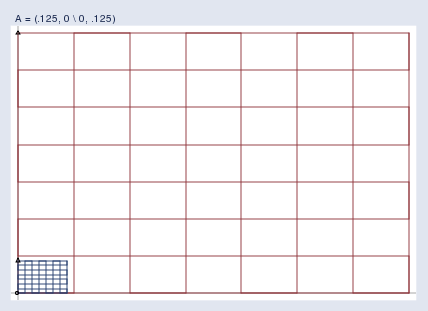
Pure compression looks like this:
純粹的壓縮是這樣的:
Pay attention to the color of the grids. The original grid, I’m showing in red; the transformed grid is shown in blue.
注意網格的顏色。我把原始網格顯示為紅色,變換后的網格顯示為藍色。
A pure rotation (and stretching) looks like this:
一個(非純粹的)旋轉(兼拉伸)是這樣的:
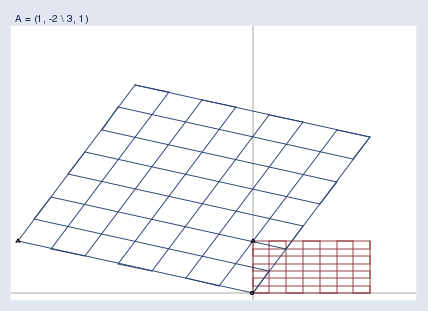
Note the location of the triangle; this space was rotated around the origin.
注意三角形的位置;這個空間是繞原點旋轉的。
Here’s an interesting matrix that produces a surprising result: A\mathbf{A}A = (111, 222 \ 333, 111).
有一個有趣的矩陣會產生令人驚訝的結果:A\mathbf{A}A = (111, 222 \ 333, 111)。
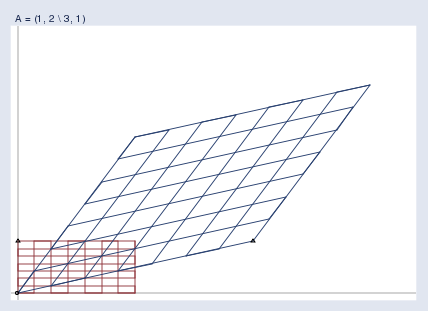
This matrix flips the space! Notice the little triangles. In the original grid, the triangle is located at the top left. In the transformed space, the corresponding triangle ends up at the bottom right! A\mathbf{A}A = (111, 222 \ 333, 111) appears to be an innocuous matrix — it does not even have a negative number in it — and yet somehow, it twisted the space horribly.
這個矩陣會使空間翻轉!注意那些小三角形。在原始網格中,三角形位于左上位置。在變換后的空間中,對應的三角形最終出現在右下位置!A\mathbf{A}A = (111, 222 \ 333, 111) 看起來是一個無害的矩陣——里面甚至沒有負數——但不知怎的,它把空間扭曲得很厲害。
Singular Matrices
奇異矩陣
So now you know what 2×22 \times 22×2 matrices do. They skew, stretch, compress, rotate, and even flip 222-space. In a like manner, 3×33 \times 33×3 matrices do the same to 333-space; 4×44 \times 44×4 matrices, to 444-space; and so on.
現在你知道 2×22 \times 22×2 矩陣的作用了。它們會扭曲、拉伸、壓縮、旋轉甚至翻轉二維空間。同樣地,3×33 \times 33×3 矩陣會對三維空間做同樣的操作;4×44 \times 44×4 矩陣會對四維空間做同樣的操作,以此類推。
Well, you are no doubt thinking, this is all very entertaining. Not really useful, but entertaining.
毫無疑問,你可能會想,這些都很有趣。雖然沒什么實際用處,但挺有意思的。
Okay, tell me what it means for a matrix to be singular. Better yet, I’ll tell you. It means this:
那好,告訴我奇異矩陣是什么意思。更確切地說,我來告訴你。它的意思是這樣的:
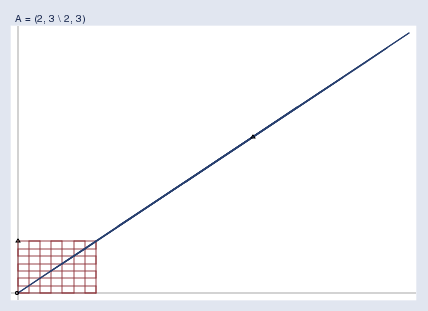
A singular matrix A\mathbf{A}A compresses the space so much that the poor space is squished until it is nothing more than a line. It is because the space is so squished after transformation by y\mathbf{y}y = Ax\mathbf{A}\mathbf{x}Ax that one cannot take the resulting y\mathbf{y}y and get back the original x\mathbf{x}x. Several different x\mathbf{x}x values get squished into that same value of y\mathbf{y}y. Actually, an infinite number do, and we don’t know which you started with.
奇異矩陣 A\mathbf{A}A 會極大地壓縮空間,把原本的空間擠壓成一條線。正是因為經過 y\mathbf{y}y = Ax\mathbf{A}\mathbf{x}Ax 變換后空間被擠壓得如此厲害,所以我們無法根據得到的 y\mathbf{y}y 反推出原始的 x\mathbf{x}x。多個不同的 x\mathbf{x}x 值會被擠壓成同一個 y\mathbf{y}y 值。實際上,有無窮多個 x\mathbf{x}x 值會這樣,我們不知道你最初用的是哪一個。
A\mathbf{A}A = (222, 333 \ 222, 333) squished the space down to a line. The matrix A\mathbf{A}A = (000, 000 \ 000, 000) would squish the space down to a point, namely (000 000). In higher dimensions, say, kkk, singular matrices can squish space into k?1k-1k?1, k?2k-2k?2, …, or 000 dimensions. The number of dimensions is called the rank of the matrix.
A\mathbf{A}A = (222, 333 \ 222, 333) 會把空間壓縮成一條線。矩陣 A\mathbf{A}A = (000, 000 \ 000, 000) 會把空間壓縮成一個點,即 (000 000)。在更高維的空間中,比如 kkk 維,奇異矩陣可以把空間壓縮成 k?1k-1k?1 維、k?2k-2k?2 維……甚至 000 維。這個維度數被稱為矩陣的秩。
Nearly Singular Matrices
近奇異矩陣
Singular matrices are an extreme case of nearly singular matrices, which are the bane of my existence here at StataCorp. Here is what it means for a matrix to be nearly singular:
奇異矩陣是近奇異矩陣的極端情況,是我在 StataCorp 工作時最頭疼的問題。近奇異矩陣的含義是這樣的:
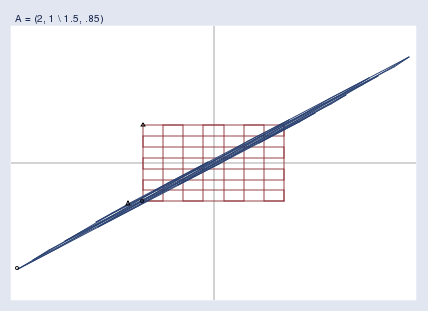
Nearly singular matrices result in spaces that are heavily but not fully compressed. In nearly singular matrices, the mapping from x\mathbf{x}x to y\mathbf{y}y is still one-to-one, but x\mathbf{x}x‘s that are far away from each other can end up having nearly equal y\mathbf{y}y values. Nearly singular matrices cause finite-precision computers difficulty. Calculating y\mathbf{y}y = Ax\mathbf{A}\mathbf{x}Ax is easy enough, but to calculate the reverse transform x\mathbf{x}x = A?1y\mathbf{A}^{-1}\mathbf{y}A?1y means taking small differences and blowing them back up, which can be a numeric disaster in the making.
近奇異矩陣會導致空間被嚴重壓縮,但沒有完全壓縮。對于近奇異矩陣,從 x\mathbf{x}x 到 y\mathbf{y}y 的映射仍然是一一對應的,但彼此距離很遠的 x\mathbf{x}x 值最終可能會有幾乎相等的 y\mathbf{y}y 值。近奇異矩陣會給有限精度的計算機帶來麻煩。計算 y\mathbf{y}y = Ax\mathbf{A}\mathbf{x}Ax 還算容易,但計算逆變換 x\mathbf{x}x = A?1y\mathbf{A}^{-1}\mathbf{y}A?1y 就意味著要處理微小的差異并將其放大,這可能會造成數值計算上的災難。
Matrix Transformations
矩陣變換
So much for the pictures illustrating that matrices transform and distort space; the message is that they do. This way of thinking can provide intuition and even deep insights. Here’s one:
關于矩陣變換和扭曲空間的圖示就說這么多;核心信息是矩陣確實會這樣做。這種思考方式能給我們帶來直覺,甚至是深刻的見解。比如這樣一個見解:
In the above graph of the fully singular matrix, I chose a matrix that not only squished the space but also skewed the space some. I didn’t have to include the skew. Had I chosen matrix A\mathbf{A}A = (111, 000 \ 000, 000), I could have compressed the space down onto the horizontal axis. And with that, we have a picture of nonsquare matrices. I didn’t really need a 2×22 \times 22×2 matrix to map 222-space onto one of its axes; a 2×12 \times 12×1 vector would have been sufficient. The implication is that, in a very deep sense, nonsquare matrices are identical to square matrices with zero rows or columns added to make them square. You might remember that; it will serve you well.
在上面完全奇異矩陣的圖形中,我選擇的矩陣不僅壓縮了空間,還使空間產生了一些扭曲。其實我也可以不加入這種扭曲。如果我選擇矩陣 A\mathbf{A}A = (111, 000 \ 000, 000),我可以把空間壓縮到水平軸上。由此,我們可以對非方陣有一個認識。我其實并不需要一個 2×22 \times 22×2 矩陣來將二維空間映射到它的某一個軸上;一個 2×12 \times 12×1 的向量就足夠了。這意味著,從深層次來講,非方陣等同于通過添加零行或零列使其成為方陣的矩陣。你或許可以記住這一點,它會對你很有幫助。
Here’s another insight:
再來看另一個見解:
In the linear regression formula b\mathbf{b}b = (X′X)?1X′y(\mathbf{X}'\mathbf{X})^{-1}\mathbf{X}'\mathbf{y}(X′X)?1X′y, (X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1 is a square matrix, so we can think of it as transforming space. Let’s try to understand it that way.
在線性回歸公式 b\mathbf{b}b = (X′X)?1X′y(\mathbf{X}'\mathbf{X})^{-1}\mathbf{X}'\mathbf{y}(X′X)?1X′y 中,(X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1 是一個方陣,所以我們可以把它看作是對空間的一種變換。讓我們試著從這個角度來理解它。
Begin by imagining a case where it just turns out that (X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1 = I\mathbf{I}I. In such a case, (X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1 would have off-diagonal elements equal to zero, and diagonal elements all equal to one. The off-diagonal elements being equal to 000 means that the variables in the data are uncorrelated; the diagonal elements all being equal to 111 means that the sum of each squared variable would equal 111. That would be true if the variables each had mean 000 and variance 1/N1/N1/N. Such data may not be common, but I can imagine them.
先設想一種情況:(X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1 = I\mathbf{I}I。在這種情況下,(X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1 的非對角線元素都為零,對角線元素都為 111。非對角線元素為零意味著數據中的變量是不相關的;對角線元素都為 111 意味著每個變量的平方和等于 111。如果每個變量的均值為 000,方差為 1/N1/N1/N,那么情況就是這樣。這樣的數據可能并不常見,但我可以想象出它們的樣子。
If I had data like that, my formula for calculating b\mathbf{b}b would be b\mathbf{b}b = (X′X)?1X′y(\mathbf{X}'\mathbf{X})^{-1}\mathbf{X}'\mathbf{y}(X′X)?1X′y = IX′y\mathbf{I}\mathbf{X}'\mathbf{y}IX′y = X′y\mathbf{X}'\mathbf{y}X′y. When I first realized that, it surprised me because I would have expected the formula to be something like b\mathbf{b}b = X?1y\mathbf{X}^{-1}\mathbf{y}X?1y. I expected that because we are finding a solution to y\mathbf{y}y = Xb\mathbf{X}\mathbf{b}Xb, and b\mathbf{b}b = X?1y\mathbf{X}^{-1}\mathbf{y}X?1y is an obvious solution. In fact, that’s just what we got, because it turns out that X?1y\mathbf{X}^{-1}\mathbf{y}X?1y = X′y\mathbf{X}'\mathbf{y}X′y when (X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1 = I\mathbf{I}I. They are equal because (X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1 = I\mathbf{I}I means that X′X\mathbf{X}'\mathbf{X}X′X = I\mathbf{I}I, which means that X′\mathbf{X}'X′ = X?1\mathbf{X}^{-1}X?1. For this math to work out, we need a suitable definition of inverse for nonsquare matrices. But they do exist, and in fact, everything you need to work it out is right there in front of you.
如果我有這樣的數據,那么計算 b\mathbf{b}b 的公式就是 b\mathbf{b}b = (X′X)?1X′y(\mathbf{X}'\mathbf{X})^{-1}\mathbf{X}'\mathbf{y}(X′X)?1X′y = IX′y\mathbf{I}\mathbf{X}'\mathbf{y}IX′y = X′y\mathbf{X}'\mathbf{y}X′y。當我第一次意識到這一點時,我很驚訝,因為我原本預期公式會是 b\mathbf{b}b = X?1y\mathbf{X}^{-1}\mathbf{y}X?1y 之類的形式。我之所以會這樣預期,是因為我們在求 y\mathbf{y}y = Xb\mathbf{X}\mathbf{b}Xb 的解,而 b\mathbf{b}b = X?1y\mathbf{X}^{-1}\mathbf{y}X?1y 是一個顯而易見的解。事實上,我們得到的結果正是如此,因為當 (X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1 = I\mathbf{I}I 時,X?1y\mathbf{X}^{-1}\mathbf{y}X?1y = X′y\mathbf{X}'\mathbf{y}X′y。它們相等是因為 (X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1 = I\mathbf{I}I 意味著 X′X\mathbf{X}'\mathbf{X}X′X = I\mathbf{I}I,這又意味著 X′\mathbf{X}'X′ = X?1\mathbf{X}^{-1}X?1。要讓這個數學推理成立,我們需要一個適用于非方陣的逆矩陣定義。但這樣的定義確實存在,而且實際上,你需要的所有用來推導的東西都明擺在眼前。
Anyway, when correlations are zero and variables are appropriately normalized, the linear regression calculation formula reduces to b\mathbf{b}b = X′y\mathbf{X}'\mathbf{y}X′y. That makes sense to me (now) and yet, it is still a very neat formula. It takes something that is N×kN \times kN×k — the data — and makes kkk coefficients out of it. X′y\mathbf{X}'\mathbf{y}X′y is the heart of the linear regression formula.
不管怎樣,當變量間的相關性為零且變量經過適當標準化后,線性回歸的計算公式就簡化為 b\mathbf{b}b = X′y\mathbf{X}'\mathbf{y}X′y。(現在)這對我來說是有意義的,而且這仍然是一個非常簡潔的公式。它接收一個 N×kN \times kN×k 的數據,然后從中得出 kkk 個系數。X′y\mathbf{X}'\mathbf{y}X′y 是線性回歸公式的核心。
Let’s call b\mathbf{b}b = X′y\mathbf{X}'\mathbf{y}X′y the naive formula because it is justified only under the assumption that (X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1 = I\mathbf{I}I, and real X′X\mathbf{X}'\mathbf{X}X′X inverses are not equal to I\mathbf{I}I. (X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1 is a square matrix and, as we have seen, that means it can be interpreted as compressing, expanding, and rotating space. (And even flipping space, although it turns out the positive-definite restriction on X′X\mathbf{X}'\mathbf{X}X′X rules out the flip.) In the formula (X′X)?1X′y(\mathbf{X}'\mathbf{X})^{-1}\mathbf{X}'\mathbf{y}(X′X)?1X′y, (X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1 is compressing, expanding, and skewing X′y\mathbf{X}'\mathbf{y}X′y, the naive regression coefficients. Thus (X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1 is the corrective lens that translates the naive coefficients into the coefficient we seek. And that means X′X\mathbf{X}'\mathbf{X}X′X is the distortion caused by scale of the data and correlations of variables.
我們把 b\mathbf{b}b = X′y\mathbf{X}'\mathbf{y}X′y 稱為樸素公式,因為它只有在 (X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1 = I\mathbf{I}I 這一假設下才成立,而實際中 X′X\mathbf{X}'\mathbf{X}X′X 的逆矩陣并不等于 I\mathbf{I}I。(X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1 是一個方陣,正如我們所看到的,這意味著它可以被理解為對空間的壓縮、擴展和旋轉(甚至是翻轉,盡管事實證明 X′X\mathbf{X}'\mathbf{X}X′X 的正定限制排除了翻轉的可能)。在公式 (X′X)?1X′y(\mathbf{X}'\mathbf{X})^{-1}\mathbf{X}'\mathbf{y}(X′X)?1X′y 中,(X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1 正在對樸素回歸系數 X′y\mathbf{X}'\mathbf{y}X′y 進行壓縮、擴展和扭曲。因此,(X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1 就像是一個校正透鏡,把樸素系數轉化為我們所尋求的系數。這意味著 X′X\mathbf{X}'\mathbf{X}X′X 是由數據的尺度和變量的相關性所引起的扭曲。
Thus I am entitled to describe linear regression as follows: I have data (y\mathbf{y}y, X\mathbf{X}X) to which I want to fit y\mathbf{y}y = Xb\mathbf{X}\mathbf{b}Xb. The naive calculation is b\mathbf{b}b = X′y\mathbf{X}'\mathbf{y}X′y, which ignores the scale and correlations of the variables. The distortion caused by the scale and correlations of the variables is X′X\mathbf{X}'\mathbf{X}X′X. To correct for the distortion, I map the naive coefficients through (X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1.
因此,我可以這樣描述線性回歸:我有數據(y\mathbf{y}y,X\mathbf{X}X),想擬合 y\mathbf{y}y = Xb\mathbf{X}\mathbf{b}Xb。樸素計算是 b\mathbf{b}b = X′y\mathbf{X}'\mathbf{y}X′y,它忽略了變量的尺度和相關性。由變量的尺度和相關性引起的扭曲是 X′X\mathbf{X}'\mathbf{X}X′X。為了校正這種扭曲,我通過 (X′X)?1(\mathbf{X}'\mathbf{X})^{-1}(X′X)?1 對樸素系數進行映射。
Intuition, like beauty, is in the eye of the beholder. When I learned that the variance matrix of the estimated coefficients was equal to s2(X′X)?1s^2(\mathbf{X}'\mathbf{X})^{-1}s2(X′X)?1, I immediately thought: s2s^2s2 — there’s the statistics. That single statistical value is then parceled out through the corrective lens that accounts for scale and correlation. If I had data that didn’t need correcting, then the standard errors of all the coefficients would be the same and would be identical to the variance of the residuals.
直覺就像美一樣,因人而異。當我得知估計系數的方差矩陣等于 s2(X′X)?1s^2(\mathbf{X}'\mathbf{X})^{-1}s2(X′X)?1 時,我立刻想到:s2s^2s2——這才是統計學的核心。這個單一的統計值然后通過考慮尺度和相關性的校正透鏡進行分配。如果我有不需要校正的數據,那么所有系數的標準誤差都會相同,并且與殘差的方差一致。
If you go through the derivation of s2(X′X)?1s^2(\mathbf{X}'\mathbf{X})^{-1}s2(X′X)?1, there’s a temptation to think that s2s^2s2 is merely something factored out from the variance matrix, probably to emphasize the connection between the variance of the residuals and standard errors. One easily loses sight of the fact that s2s^2s2 is the heart of the matter, just as X′y\mathbf{X}'\mathbf{y}X′y is the heart of (X′X)?1X′y(\mathbf{X}'\mathbf{X})^{-1}\mathbf{X}'\mathbf{y}(X′X)?1X′y. Obviously, one needs to view both s2s^2s2 and X′y\mathbf{X}'\mathbf{y}X′y though the same corrective lens.
如果你仔細看 s2(X′X)?1s^2(\mathbf{X}'\mathbf{X})^{-1}s2(X′X)?1 的推導過程,你可能會認為 s2s^2s2 僅僅是從方差矩陣中提取出來的一個因子,或許是為了強調殘差方差和標準誤差之間的聯系。但人們很容易忽略 s2s^2s2 是問題的核心這一事實,就像 X′y\mathbf{X}'\mathbf{y}X′y 是 (X′X)?1X′y(\mathbf{X}'\mathbf{X})^{-1}\mathbf{X}'\mathbf{y}(X′X)?1X′y 的核心一樣。顯然,我們需要通過同一個校正透鏡來看待 s2s^2s2 和 X′y\mathbf{X}'\mathbf{y}X′y。
I have more to say about this way of thinking about matrices. Look for part 2 in the near future.
關于這種思考矩陣的方式,我還有更多的話要說。請關注第二部分。
Understanding matrices intuitively, part 2, eigenvalues and eigenvectors
直觀理解矩陣(第二部分):特征值和特征向量
999 March 201120112011 William Gould
Visualizing Eigenvalues and Eigenvectors
可視化特征值和特征向量
Last time, I showed you a way to graph and to think about matrices. This time, I want to apply the technique to eigenvalues and eigenvectors. The point is to give you a picture that will guide your intuition, just as it was previously.
上一次,我向大家展示了一種繪制矩陣圖形和思考矩陣的方法。這次,我想把這種方法應用到特征值和特征向量上。目的是給大家一個能引導直覺的圖像,就像上次一樣。
Before I go on, several people asked after reading part 1 for the code I used to generate the graphs. Here it is, both for part 1 and part 2: matrixcode.zip.
在我繼續之前,有幾個人在讀完第一部分后問我用于生成這些圖形的代碼。這是第一部分和第二部分的代碼:matrixcode.zip。
The eigenvectors and eigenvalues of matrix A\mathbf{A}A are defined to be the nonzero x\mathbf{x}x and λ\lambdaλ values that solve
矩陣 A\mathbf{A}A 的特征向量和特征值被定義為滿足以下方程的非零 x\mathbf{x}x 和 λ\lambdaλ:
Ax\mathbf{A}\mathbf{x}Ax = λx\lambda\mathbf{x}λx
I wrote a lot about Ax\mathbf{A}\mathbf{x}Ax in the last post. Just as previously, x\mathbf{x}x is a point in the original, untransformed space and Ax\mathbf{A}\mathbf{x}Ax is its transformed value. λ\lambdaλ on the right-hand side is a scalar.
在上一篇文章中,我詳細討論了 Ax\mathbf{A}\mathbf{x}Ax。和之前一樣,x\mathbf{x}x 是原始的、未變換空間中的一個點,Ax\mathbf{A}\mathbf{x}Ax 是它的變換后的值。右邊的 λ\lambdaλ 是一個標量。
Scalar Multiplication
標量乘法
Multiplying a point by a scalar moves the point along a line that passes through the origin and the point:
用一個標量乘以一個點,會使這個點沿著一條穿過原點和該點的直線移動:

The figure above illustrates y\mathbf{y}y=λx\lambda\mathbf{x}λx when λ>1\lambda>1λ>1. If λ\lambdaλ were less than 111, the point would move toward the origin and if λ\lambdaλ were also less than 000, the point would pass right by the origin to land on the other side. For any point x\mathbf{x}x, y\mathbf{y}y=λx\lambda\mathbf{x}λx will be somewhere on the line passing through the origin and x\mathbf{x}x.
上圖展示了當 λ>1\lambda>1λ>1 時 y\mathbf{y}y=λx\lambda\mathbf{x}λx 的情況。如果 λ\lambdaλ 小于 111,這個點會向原點移動;如果 λ\lambdaλ 也小于 000,這個點會經過原點,落到另一邊。對于任何點 x\mathbf{x}x,y\mathbf{y}y=λx\lambda\mathbf{x}λx 都會在穿過原點和 x\mathbf{x}x 的直線上的某個位置。
Eigenvalues and Eigenvectors
特征值和特征向量
Thus Ax\mathbf{A}\mathbf{x}Ax = λx\lambda\mathbf{x}λx means the transformed value Ax\mathbf{A}\mathbf{x}Ax lies on a line passing through the origin and the original x\mathbf{x}x. Points that meet that restriction are eigenvectors (or more correctly, as we will see, eigenpoints, a term I just coined), and the corresponding eigenvalues are the λ\lambdaλ‘s that record how far the points move along the line.
因此,Ax\mathbf{A}\mathbf{x}Ax = λx\lambda\mathbf{x}λx 意味著變換后的值 Ax\mathbf{A}\mathbf{x}Ax 位于穿過原點和原始點 x\mathbf{x}x 的直線上。滿足這個限制條件的點就是特征向量(或者更準確地說,正如我們將看到的,是特征點,這是我剛剛創造的一個術語),而相應的特征值就是記錄這些點沿直線移動距離的 λ\lambdaλ。
Actually, if x\mathbf{x}x is a solution to Ax\mathbf{A}\mathbf{x}Ax = λx\lambda\mathbf{x}λx, then so is every other point on the line through 000 and x\mathbf{x}x. That’s easy to see. Assume x\mathbf{x}x is a solution to Ax\mathbf{A}\mathbf{x}Ax = λx\lambda\mathbf{x}λx and substitute cxc\mathbf{x}cx for x\mathbf{x}x: A(cx)\mathbf{A}(c\mathbf{x})A(cx) = λ(cx)\lambda(c\mathbf{x})λ(cx). Thus x\mathbf{x}x is not the eigenvector but is merely a point along the eigenvector.
實際上,如果 x\mathbf{x}x 是 Ax\mathbf{A}\mathbf{x}Ax = λx\lambda\mathbf{x}λx 的解,那么穿過 000 和 x\mathbf{x}x 的直線上的其他所有點也是該方程的解。這很容易理解。假設 x\mathbf{x}x 是 Ax\mathbf{A}\mathbf{x}Ax = λx\lambda\mathbf{x}λx 的解,用 cxc\mathbf{x}cx 代替 x\mathbf{x}x:A(cx)\mathbf{A}(c\mathbf{x})A(cx) = λ(cx)\lambda(c\mathbf{x})λ(cx)。因此,x\mathbf{x}x 并不是特征向量,而僅僅是特征向量上的一個點。
And with that prelude, we are now in a position to interpret Ax\mathbf{A}\mathbf{x}Ax = λx\lambda\mathbf{x}λx fully. Ax\mathbf{A}\mathbf{x}Ax = λx\lambda\mathbf{x}λx finds the lines such that every point on the line, say, x\mathbf{x}x, transformed by Ax\mathbf{A}\mathbf{x}Ax moves to being another point on the same line. These lines are thus the natural axes of the transform defined by A\mathbf{A}A.
有了這個鋪墊,我們現在可以全面解釋 Ax\mathbf{A}\mathbf{x}Ax = λx\lambda\mathbf{x}λx 了。Ax\mathbf{A}\mathbf{x}Ax = λx\lambda\mathbf{x}λx 找到的是這樣一些直線:直線上的每個點(比如 x\mathbf{x}x)經過 Ax\mathbf{A}\mathbf{x}Ax 變換后,會移動到同一條直線上的另一個點。因此,這些直線是 A\mathbf{A}A 所定義的變換的自然軸。
The equation Ax\mathbf{A}\mathbf{x}Ax = λx\lambda\mathbf{x}λx and the instructions “solve for nonzero x\mathbf{x}x and λ\lambdaλ” are deceptive. A more honest way to present the problem would be to transform the equation to polar coordinates. We would have said to find θ\thetaθ and λ\lambdaλ such that any point on the line (r,θ)(r, \theta)(r,θ) is transformed to (λr,θ)(\lambda r, \theta)(λr,θ). Nonetheless, Ax\mathbf{A}\mathbf{x}Ax = λx\lambda\mathbf{x}λx is how the problem is commonly written.
方程 Ax\mathbf{A}\mathbf{x}Ax = λx\lambda\mathbf{x}λx 以及“求解非零 x\mathbf{x}x 和 λ\lambdaλ”的說明具有迷惑性。更直觀的呈現這個問題的方式是將方程轉換到極坐標下。我們可以說,找到 θ\thetaθ 和 λ\lambdaλ,使得直線 (r,θ)(r, \theta)(r,θ) 上的任何點都變換到 (λr,θ)(\lambda r, \theta)(λr,θ)。盡管如此,Ax\mathbf{A}\mathbf{x}Ax = λx\lambda\mathbf{x}λx 是這個問題常見的寫法。
However we state the problem, here is the picture and solution for A\mathbf{A}A = (222, 111 \ 111, 222)
不管我們如何表述這個問題,下面是 A\mathbf{A}A = (222, 111 \ 111, 222) 的圖形和解答:
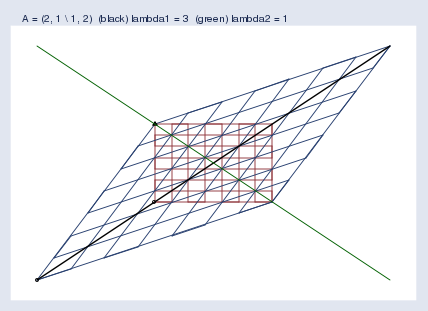
I used Mata’s eigensystem()\text{eigensystem()}eigensystem() function to obtain the eigenvectors and eigenvalues. In the graph, the black and green lines are the eigenvectors.
我使用 Mata 的 eigensystem()\text{eigensystem()}eigensystem() 函數來獲取特征向量和特征值。在圖形中,黑色和綠色的線是特征向量。
The first eigenvector is plotted in black. The “eigenvector” I got back from Mata was (0.7070.7070.707 \ 0.7070.7070.707), but that’s just one point on the eigenvector line, the slope of which is 0.707/0.707=10.707 / 0.707 = 10.707/0.707=1, so I graphed the line y\mathbf{y}y = x\mathbf{x}x. The eigenvalue reported by Mata was 333. Thus every point x\mathbf{x}x along the black line moves to three times its distance from the origin when transformed by Ax\mathbf{A}\mathbf{x}Ax. I suppressed the origin in the figure, but you can spot it because it is where the black and green lines intersect.
第一條特征向量用黑色繪制。我從 Mata 得到的“特征向量”是 (0.7070.7070.707 \ 0.7070.7070.707),但這只是特征向量直線上的一個點,該直線的斜率是 0.707/0.707=10.707 / 0.707 = 10.707/0.707=1,所以我繪制了直線 y\mathbf{y}y = x\mathbf{x}x。Mata 報告的特征值是 333。因此,當通過 Ax\mathbf{A}\mathbf{x}Ax 變換時,黑色直線上的每個點 x\mathbf{x}x 都會移動到距離原點三倍于原來距離的位置。我在圖中隱藏了原點,但你可以找到它,因為它是黑色和綠色直線的交點。
The second eigenvector is plotted in green. The second “eigenvector” I got back from Mata was (?0.707-0.707?0.707 \ 0.7070.7070.707), so the slope of the eigenvector line is 0.707/(?0.707)=?10.707 / (-0.707) = -10.707/(?0.707)=?1. I plotted the line y\mathbf{y}y = ?x-\mathbf{x}?x. The eigenvalue is 111, so the points along the green line do not move at all when transformed by Ax\mathbf{A}\mathbf{x}Ax; y\mathbf{y}y=λx\lambda\mathbf{x}λx and λ=1\lambda=1λ=1.
第二條特征向量用綠色繪制。我從 Mata 得到的第二個“特征向量”是 (?0.707-0.707?0.707 \ 0.7070.7070.707),所以該特征向量直線的斜率是 0.707/(?0.707)=?10.707 / (-0.707) = -10.707/(?0.707)=?1。我繪制了直線 y\mathbf{y}y = ?x-\mathbf{x}?x。特征值是 111,所以當通過 Ax\mathbf{A}\mathbf{x}Ax 變換時,綠色直線上的點根本不會移動;y\mathbf{y}y=λx\lambda\mathbf{x}λx 且 λ=1\lambda=1λ=1。
Eigenpoints and Eigenaxes
特征點和特征軸
Here’s another example, this time for the matrix A\mathbf{A}A = (1.11.11.1, 222 \ 333, 111):
再來看另一個例子,這次是矩陣 A\mathbf{A}A = (1.11.11.1, 222 \ 333, 111):
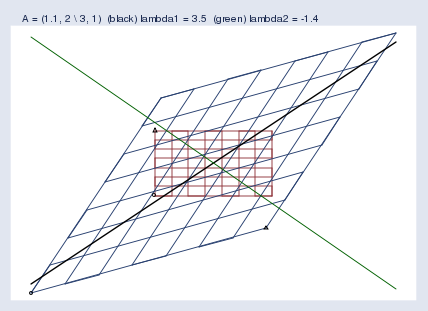
The first “eigenvector” and eigenvalue Mata reported were… Wait! I’m getting tired of quoting the word eigenvector. I’m quoting it because computer software and the mathematical literature call it the eigenvector even though it is just a point along the eigenvector. Actually, what’s being described is not even a vector. A better word would be eigenaxis. Since this posting is pedagogical, I’m going to refer to the computer-reported eigenvector as an eigenpoint along the eigenaxis. When you return to the real world, remember to use the word eigenvector.
Mata 報告的第一個“特征向量”和特征值是……等等!我厭倦了給“特征向量”這個詞加引號了。我加引號是因為計算機軟件和數學文獻都稱它為特征向量,盡管它只是特征向量上的一個點。實際上,所描述的甚至不是一個向量。一個更好的詞是特征軸。由于這篇文章是教學性的,我會把計算機報告的特征向量稱為特征軸上的特征點。當你回到實際應用中時,記得使用“特征向量”這個詞。
The first eigenpoint and eigenvalue that Mata reported were (0.6400.6400.640 \ 0.7680.7680.768) and λ\lambdaλ = 3.453.453.45. Thus the slope of the eigenaxis is 0.768/0.640=1.20.768 / 0.640 = 1.20.768/0.640=1.2, and points along that line — the green line — move to 3.453.453.45 times their distance from the origin.
Mata 報告的第一個特征點和特征值是 (0.6400.6400.640 \ 0.7680.7680.768) 和 λ\lambdaλ = 3.453.453.45。因此,特征軸的斜率是 0.768/0.640=1.20.768 / 0.640 = 1.20.768/0.640=1.2,這條直線(綠色直線)上的點會移動到距離原點 3.453.453.45 倍于原來距離的位置。
The second eigenpoint and eigenvalue Mata reported were (?0.625-0.625?0.625 \ 0.7810.7810.781) and λ\lambdaλ = ?1.4-1.4?1.4. Thus the slope is ?0.781/0.625=?1.25-0.781 / 0.625 = -1.25?0.781/0.625=?1.25, and points along that line move to ?1.4-1.4?1.4 times their distance from the origin, which is to say they flip sides and then move out, too. We saw this flipping in my previous posting. You may remember that I put a small circle and triangle at the bottom left and bottom right of the original grid and then let the symbols be transformed by A\mathbf{A}A along with the rest of space. We saw an example like this one, where the triangle moved from the top-left of the original space to the bottom-right of the transformed space. The space was flipped in one of its dimensions. Eigenvalues save us from having to look at pictures with circles and triangles; when a dimension of the space flips, the corresponding eigenvalue is negative.
Mata 報告的第二個特征點和特征值是 (?0.625-0.625?0.625 \ 0.7810.7810.781) 和 λ\lambdaλ = ?1.4-1.4?1.4。因此,斜率是 ?0.781/0.625=?1.25-0.781 / 0.625 = -1.25?0.781/0.625=?1.25,這條直線上的點會移動到距離原點 ?1.4-1.4?1.4 倍于原來距離的位置,也就是說,它們會翻轉到另一邊,然后也向外移動。在上一篇文章中,我們看到過這種翻轉。你可能還記得,我在原始網格的左下和右下位置放了一個小圓圈和一個三角形,然后讓這些符號和空間的其他部分一起被 A\mathbf{A}A 變換。我們看到過類似這樣的例子,三角形從原始空間的左上位置移動到了變換后空間的右下位置。空間在其中一個維度上發生了翻轉。特征值讓我們不必再看帶有圓圈和三角形的圖片;當空間的某個維度發生翻轉時,相應的特征值是負數。
Near Singularity with Eigenaxes
近奇異矩陣與特征軸
We examined near singularity last time. Let’s look again, and this time add the eigenaxes:
上次我們研究了近奇異性。讓我們再看一次,這次加上特征軸:
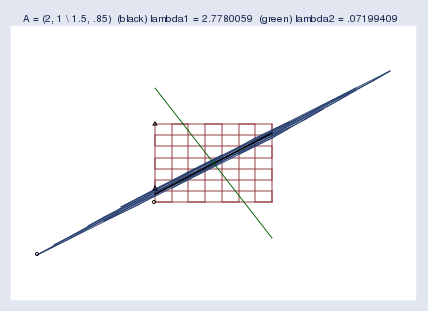
The blue blob going from bottom-left to top-right is both the compressed space and the first eigenaxis. The second eigenaxis is shown in green.
從左下到右上的藍色團塊既是壓縮后的空間,也是第一條特征軸。第二條特征軸用綠色顯示。
Mata reported the first eigenpoint as (0.7890.7890.789 \ 0.6140.6140.614) and the second as (?0.460-0.460?0.460 \ 0.8880.8880.888). Corresponding eigenvalues were reported as 2.782.782.78 and 0.070.070.07. I should mention that zero eigenvalues indicate singular matrices and small eigenvalues indicate nearly singular matrices. Actually, eigenvalues also reflect the scale of the matrix. A matrix that compresses the space will have all of its eigenvalues be small, and that is not an indication of near singularity. To detect near singularity, one should look at the ratio of the largest to the smallest eigenvalue, which in this case is 0.07/2.78=0.030.07 / 2.78 = 0.030.07/2.78=0.03.
Mata 報告的第一個特征點是 (0.7890.7890.789 \ 0.6140.6140.614),第二個是 (?0.460-0.460?0.460 \ 0.8880.8880.888)。相應的特征值分別是 2.782.782.78 和 0.070.070.07。我應該提到,零特征值表明矩陣是奇異矩陣,小特征值表明矩陣是近奇異矩陣。實際上,特征值也反映了矩陣的尺度。一個壓縮空間的矩陣,其所有特征值都會很小,但這并不表明它是近奇異矩陣。要檢測近奇異性,應該看最大特征值與最小特征值的比值,在這個例子中是 0.07/2.78=0.030.07 / 2.78 = 0.030.07/2.78=0.03。
Despite appearances, computers do not find 0.030.030.03 to be small and thus do not think of this matrix as being nearly singular. This matrix gives computers no problem; Mata can calculate the inverse of this without losing even one binary digit. I mention this and show you the picture so that you will have a better appreciation of just how squished the space can become before computers start complaining.
盡管看起來如此,計算機并不認為 0.030.030.03 很小,因此也不認為這個矩陣是近奇異的。這個矩陣不會給計算機帶來問題;Mata 可以計算它的逆矩陣,甚至不會丟失一個二進制位。我提到這一點并給你看這張圖片,是為了讓你更好地理解,在計算機開始出現問題之前,空間可以被壓縮到何種程度。
When do well-programmed computers complain? Say you have a matrix A\mathbf{A}A and make the above graph, but you make it really big — 333 miles by 333 miles. Lay your graph out on the ground and hike out to the middle of it. Now get down on your knees and get out your ruler. Measure the spread of the compressed space at its widest part. Is it an inch? That’s not a problem. One inch is roughly 5×10?65 \times 10^{-6}5×10?6 of the original space (that is, 111 inch by 333 miles wide). If that were a problem, users would complain. It is not problematic until we get around 10?810^{-8}10?8 of the original area. Figure about 0.0020.0020.002 inches.
程序編寫良好的計算機在什么時候會出現問題呢?假設你有一個矩陣 A\mathbf{A}A,并繪制了上面這樣的圖形,但你把圖形做得非常大——333 英里乘 333 英里。把圖形鋪在地上,走到中間。現在蹲下,拿出尺子,測量壓縮空間最寬處的跨度。有一英寸嗎?這沒問題。一英寸大約是原始空間的 5×10?65 \times 10^{-6}5×10?6(即 111 英寸比 333 英里寬)。如果這都是問題的話,用戶早就會抱怨了。直到壓縮到原始面積的 10?810^{-8}10?8 左右時,才會出現問題。大概是 0.0020.0020.002 英寸。
Further Insights into Eigenvalues and Eigenvectors
關于特征值和特征向量的更多見解
There’s more I could say about eigenvalues and eigenvectors. I could mention that rotation matrices have no eigenvectors and eigenvalues, or at least no real ones. A rotation matrix rotates the space, and thus there are no transformed points that are along their original line through the origin. I could mention that one can rebuild the original matrix from its eigenvectors and eigenvalues, and from that, one can generalize powers to matrix powers. It turns out that A?1\mathbf{A}^{-1}A?1 has the same eigenvectors as A\mathbf{A}A; its eigenvalues are λ?1\lambda^{-1}λ?1 of the original’s. Matrix AA\mathbf{A}\mathbf{A}AA also has the same eigenvectors as A\mathbf{A}A; its eigenvalues are λ2\lambda^2λ2. Ergo, Ap\mathbf{A}^pAp can be formed by transforming the eigenvalues, and it turns out that, indeed, A1/2\mathbf{A}^{1/2}A1/2 really does, when multiplied by itself, produce A\mathbf{A}A.
關于特征值和特征向量,我還有更多可以說的。我可以提到旋轉矩陣沒有特征向量和特征值,或者至少沒有實特征向量和實特征值。旋轉矩陣會旋轉空間,因此不存在變換后仍在穿過原點的原始直線上的點。我可以提到,人們可以根據矩陣的特征向量和特征值重建原始矩陣,由此可以將冪運算推廣到矩陣冪運算。事實證明,A?1\mathbf{A}^{-1}A?1 與 A\mathbf{A}A 有相同的特征向量,其特征值是原始特征值的 λ?1\lambda^{-1}λ?1。矩陣 AA\mathbf{A}\mathbf{A}AA 也與 A\mathbf{A}A 有相同的特征向量,其特征值是 λ2\lambda^2λ2。因此,Ap\mathbf{A}^pAp 可以通過對特征值進行變換來得到,而且事實證明,A1/2\mathbf{A}^{1/2}A1/2 與自身相乘確實會得到 A\mathbf{A}A。
via:
- Understanding matrices intuitively, part 1 - The Stata Blog
https://blog.stata.com/2011/03/03/understanding-matrices-intuitively-part-1/ - Understanding matrices intuitively, part 2, eigenvalues and eigenvectors - The Stata Blog
https://blog.stata.com/2011/03/09/understanding-matrices-intuitively-part-2/
:策略模式)




)
——前世今生)










)

