論文題目:V2M: VISUAL 2-DIMENSIONAL MAMBA FOR IMAGE REPRESENTATION LEARNING
年份:2024
期刊會議: arXiv
代碼鏈接:https://github.com/wangck20/V2M
目錄
-
- 現階段存在的問題
-
-
- 1. 二維結構信息丟失
- 2. 一維 Mamba 架構的局限性
- 3. 提升視覺任務表現
- 相關研究
-
- 方法
-
-
-
- 二維狀態空間模型設計:
-
- V2M流程
- 1. 輸入與預處理
- 2. 四向旋轉
- 3. 2D 狀態空間模型 (2D SSM) 計算
- 4. 水平方向隱狀態拆解與并行計算
- 5. 輸入變換與拼接
- 6. 2D SSM輸出拼接與旋轉復原
- 7. 最終輸出
- 實驗
-
- 分類任務
- 消融實驗
-
- 理論分析
-
現階段存在的問題
Visual 2-Dimensional Mamba(V2M)提出的核心目的在于為視覺任務設計一種保留二維結構信息、同時具有高效狀態空間建模能力的新型視覺骨干網絡。其主要解決的痛點包括:
1. 二維結構信息丟失
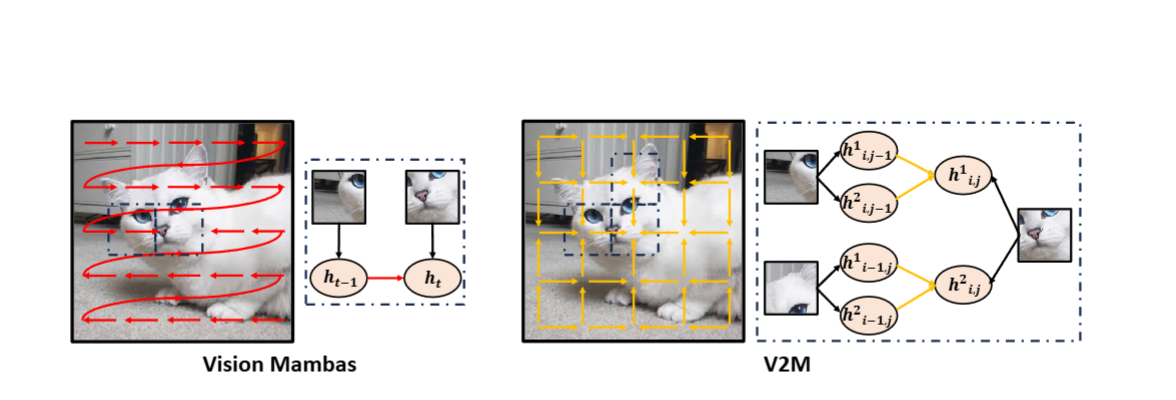
- 問題:傳統 Mamba 屬于一維序列模型,視覺任務通常將圖像切成 patch,并展平成序列輸入,這破壞了圖像的二維局部結構(如鄰域相關性)。
- 解決方案:V2M 將 SSM 從 1D 擴展至 2D,直接在二維網格上對狀態進行遞推,分別從行和列方向考慮鄰接狀態,保持局部空間結構。
2. 一維 Mamba 架構的局限性
- 問題:即使采用多種掃描策略,1D Mamba 仍難以重構原始二維空間關系。
- 解決方案:V2M 使用二維狀態方程,以更加自然的方式在二維柵格上傳播狀態(從四個角開始),避免長路徑掃描對空間連貫性的破壞。
3. 提升視覺任務表現
- 問題:1D Mamba 無法充分利用圖像的二維結構表示。
- 解決方案:V2M 通過二維 SSM 建模,提升模型對局部與全局視覺信息的捕捉能力,在 ImageNet、COCO、ADE20K 等任務上超越基線模型。
相關研究
- CNN 系列:ResNet、RegNet 等
- Vision Transformers:ViT、Swin Transformer
- Visual-Mamba 系列:Vim(Zhu et al., 2024)、LocalMamba(Huang et al., 2024)
- 狀態空間模型(SSM):S4 (Gu et al.,2021a)、Mamba (Gu & Dao,2023)
- 二維 SSM 基礎:Roesser Model (Kung et al.,1977)
- 視覺表示學習:
- 監督:ResNet,MoCo 等
- 自監督:MAE、SimCLR、BYOL 等
方法
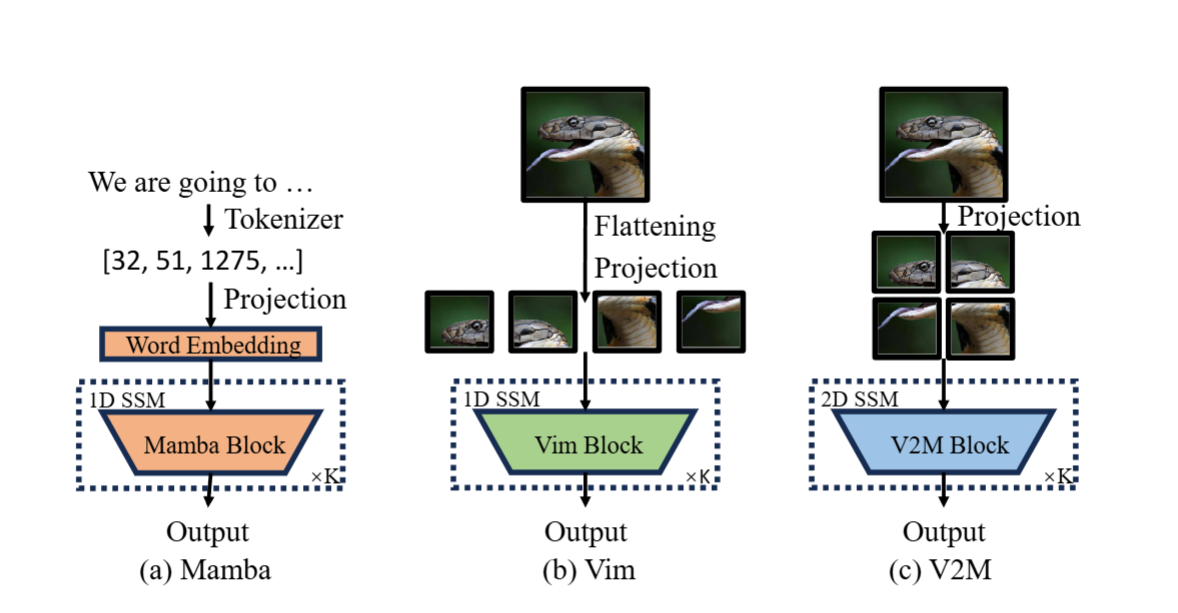
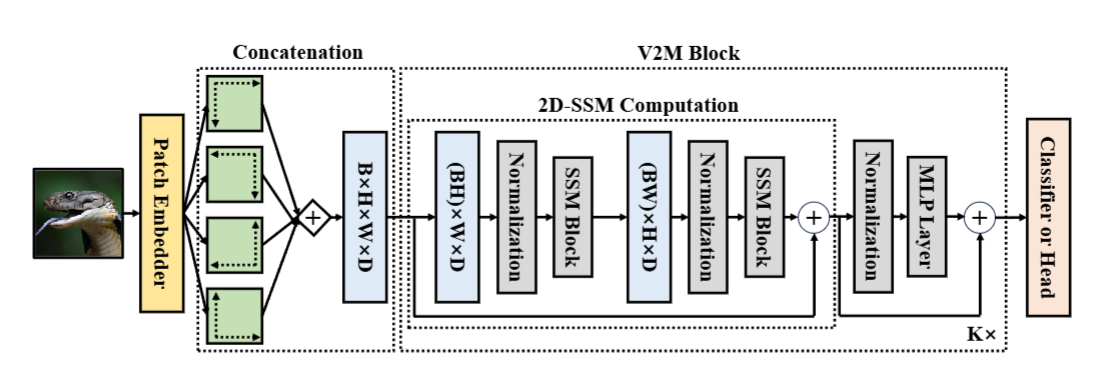
二維狀態空間模型設計:
二維狀態更新方程如下:
{ h 1 i , j + 1 = A 1 h 1 i , j + A 3 h 2 i , j + B 1 x i , j h 2 i + 1 , j = A 2 h 1 i , j + A 4 h 2 i , j + B 2 x i , j y i , j = C 1 h 1 i , j + C 2 h 2 i , j \begin{cases} h_1^{i,j+1} = A_1 h_1^{i,j} + A_3 h_2^{i,j} + B_1 x_{i,j} \\ h_2^{i+1,j} = A_2 h_1^{i,j} + A_4 h_2^{i,j} + B_2 x_{i,j} \\ y_{i,j} = C_1 h_1^{i,j} + C_2 h_2^{i,j} \end{cases} ? ? ??h1i,j+1?=A1?h1i,j?+A3?h2i,j?+B1?xi,j?h2i+1,j?=A2?h1i,j?+A4?h2i,j?+B2?xi,j?yi,j?=C1?h






)












