告別等待,秒級響應!這不只是教程,這是你駕馭PB級數據的超能力!我的ClickHouse視頻課,凝練十年實戰精華,從入門到精通,從單機到集群。點開它,讓數據處理速度快到飛起,讓你的職業生涯從此開掛!
全套視頻教程聯系博主?:試聽視頻位置
主鍵索引 (稀疏索引) 的工作原理
-
核心概念:稀疏索引 (Sparse Index)
與 MySQL 等數據庫為每一行數據都建立索引(密集索引)不同,ClickHouse 的主鍵索引是稀疏的。它只為每個數據顆粒(Granule)的第一行記錄一個“路標”。
-
數據顆粒 (Granule):ClickHouse 在存儲數據時,會將表中的行分批打包,一個包就是一個 Granule。默認情況下,一個 Granule 包含 8192 行。
-
索引文件 (
primary.idx):這個文件非常小,因為它只存儲每個 Granule 的“路標”值。例如,如果ORDER BY是(event_date),那么索引文件里存的就是每個 Granule 的起始日期。
圖示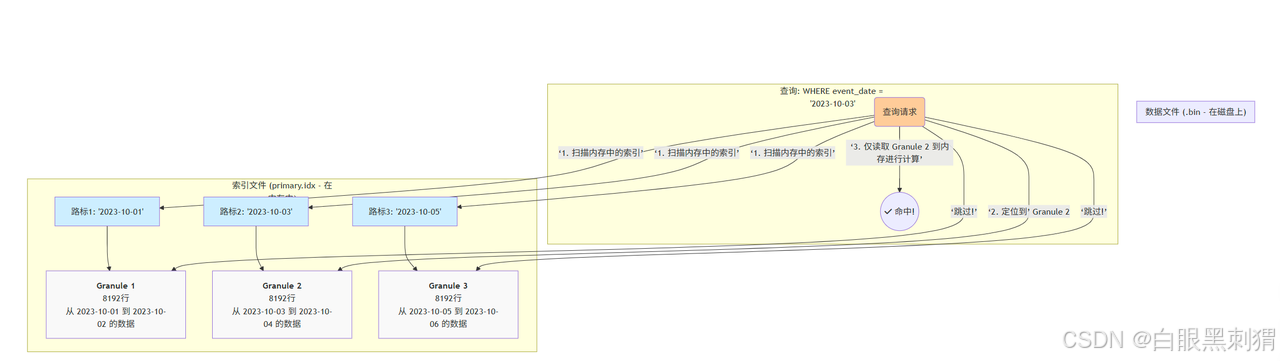
?
-
查詢來了:
WHERE event_date = '2023-10-03'。 -
掃描索引:ClickHouse 快速掃描內存中的
primary.idx文件。 -
定位范圍:它發現
'2023-10-03'這個值介于路標2 ('2023-10-03') 和路標3 ('2023-10-05') 之間。這意味著,目標數據 只可能存在于 Granule 2 中。 -
精確打擊:ClickHouse 直接跳過 Granule 1 和 Granule 3,只從磁盤讀取 Granule 2 這一個數據塊進行處理。
結論:稀疏索引的威力在于大幅減少 I/O。它不關心數據具體在哪一行,只關心數據在哪一個數據塊范圍內。
主鍵索引的設計要點:
-
列的選擇:
ORDER BY的列應該是你WHERE子句中最常用的過濾條件,尤其是范圍查詢(>,<,BETWEEN)。 -
列的順序:把基數更高(篩選能力更強)的列放在前面。例如
ORDER BY (event_date, user_id)就比ORDER BY (user_id, event_date)要好,因為日期能先過濾掉大量不相關的數據塊。
我們再強調一次:ClickHouse 的主鍵索引是稀疏的。它不像 MySQL 那樣為每一行都建索引。它只為每個數據顆粒(Granule,默認8192行) 的第一行建立一條索引記錄。
優點:索引文件非常小,可以常駐內存。 工作方式:查詢時,ClickHouse 在內存中快速掃描索引,定位到可能包含目標數據的 Granule 范圍,然后只把這些 Granule 從磁盤加載到內存中進行精確匹配。
【實踐】: 為表添加跳數索引
給剛才的 user_behavior 表的 url 列添加一個布隆過濾器索引,以加速特定URL的查找。
-- 在建表時添加
CREATE TABLE user_behavior_with_index (-- ... 其他列定義和上面一樣 ...url String,-- ...INDEX idx_url url TYPE bloom_filter() GRANULARITY 1 -- GRANULARITY表示索引的粒度
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(event_date)
ORDER BY (event_date, event_type, user_id);-- 查詢時,ClickHouse會自動使用該索引
-- 這個查詢會因為idx_url索引而變得更快
SELECT count()
FROM user_behavior_with_index
WHERE url = 'https://clickhouse.com/docs/en/';?數據跳過索引 (Skipping Indexes)-Granule 的“智能標簽”
如果說主鍵索引是城市間的高速公路,那么數據跳過索引就是每個高速出口旁邊的信息指示牌。它告訴你這個出口下去的區域“有什么”和“沒有什么”,幫你決定是否要下高速。
數據跳過索引是附加在每個數據顆粒 (Granule) 上的元數據。它獨立于主鍵索引,用于對非主鍵列進行預過濾。
除了主鍵,ClickHouse 還提供了額外的“跳數索引”,它們像給數據顆粒貼上的“標簽”,進一步減少需要掃描的數據量。
-
minmax: 記錄每個顆粒內某列的最大最小值。如果查詢WHERE price > 500,而某個顆粒的minmax標簽是[100, 400],則可以直接跳過。 -
set(N): 記錄每個顆粒內某列的前N個唯一值。如果查詢WHERE color = 'Red',而某個顆粒的set標簽是{'Blue', 'Green'},則可以跳過。 -
bloom_filter: 一種概率性索引。如果你查詢WHERE has(urls, 'some_rare_url'),布隆過濾器可以快速告訴你“這個顆粒絕對沒有這個URL”,從而跳過。它可能會誤報(說有但實際沒有),但絕不會漏報。
① minmax
-
作用:記錄每個 Granule 中某一列的最小值和最大值。
-
場景:非常適合數值或日期類型。
-
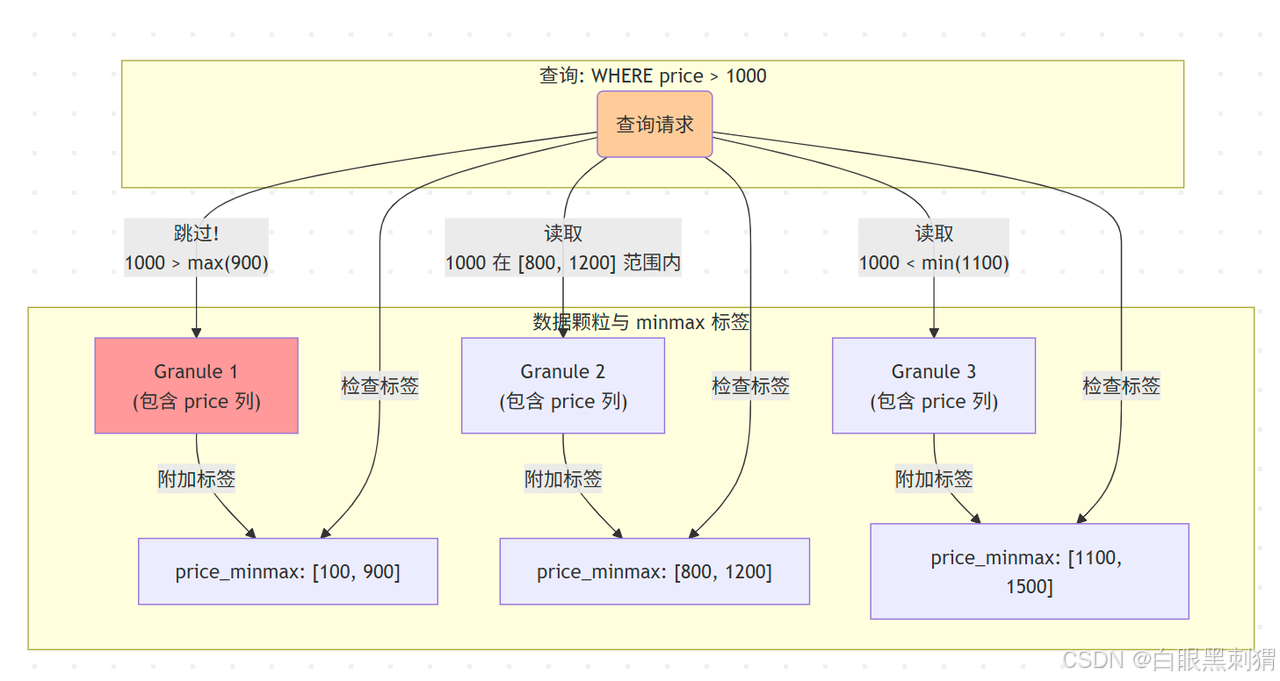
原理:查詢
WHERE price > 1000。如果某個 Granule 的minmax標簽是[100, 900],ClickHouse 就知道這個 Granule 內所有price都小于等于900,不可能滿足條件,于是直接跳過。 -
?
圖解:查詢 price > 1000 時,Granule 1 被直接跳過,因為它的最大值 900 都不滿足條件。Granule 2 和 Granule 3 因為范圍有交集,所以需要被讀取。
② set(N)
-
作用:記錄每個 Granule 中某列的前 N 個唯一值。
-
場景:適合基數較低的
String或Enum列,用于等值查詢。 -
原理:查詢
WHERE city = 'Shanghai'。如果某個 Granule 的set(3)標簽是{'Beijing', 'Guangzhou', 'Shenzhen'},ClickHouse 就知道這個 Granule 里根本沒有 'Shanghai',直接跳過。
③ bloom_filter
-
作用:一種概率性數據結構,可以非常確定地判斷一個元素“絕對不存在”,但只能概率性地判斷“可能存在”。
-
場景:
-
高基數的
String列(如 URL,用戶ID)。 -
檢查數組中是否包含某個元素
has(array, 'value')。 -
檢查 Map 中是否存在某個鍵
mapContains(map, 'key')。
-
-
原理:它像一個“黑名單篩選器”。數據寫入時,把 Granule 里的值都扔進布隆過濾器。查詢時,先問布隆過濾器:“這個值在你的黑名單上嗎?”
-
如果回答“不在”(即絕對不存在),則安全跳過。
-
如果回答“可能在”(有可能是誤報),則需要讀取 Granule 進一步確認。
-
?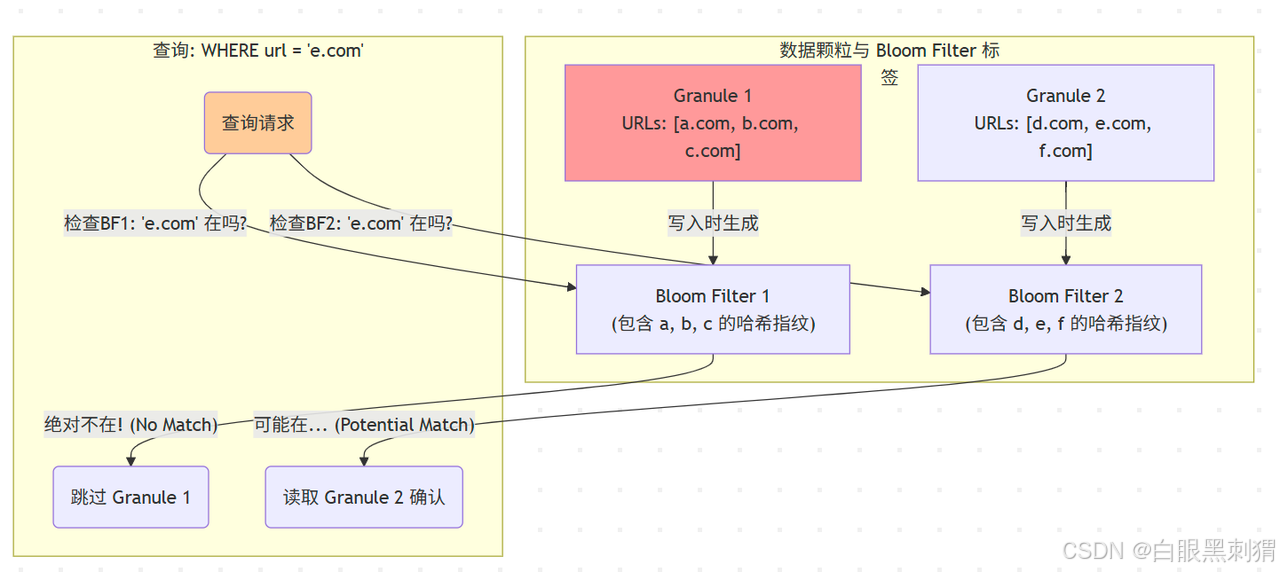
圖解:查詢 'e.com' 時,布隆過濾器 1 準確地告訴我們 Granule 1 中沒有,從而避免了一次 I/O。布隆過濾器 2 提示可能存在,我們就需要去讀取 Granule 2 來做最終的判斷。
【實踐】: 為表添加跳數索引
?
CREATE TABLE access_logs (event_time DateTime,request_id String,http_code UInt16,url String
) ENGINE = MergeTree()
ORDER BY (event_time)
SETTINGS index_granularity = 8192; -- 明確指定顆粒大小-- 為 request_id 和 http_code 添加跳數索引
ALTER TABLE access_logs ADD INDEX idx_req_id request_id TYPE bloom_filter() GRANULARITY 4;
ALTER TABLE access_logs ADD INDEX idx_code http_code TYPE set(0) GRANULARITY 4;GRANULARITY 4:表示這個跳數索引的粒度是主索引的 4 倍。即每 4 * 8192 行數據,才生成一個跳數索引塊。這是一種在索引精度和大小之間的權衡。
2. 驗證索引是否生效: 使用 EXPLAIN 或查詢日志 system.query_log 是最好的方法。我們用一個更直觀的方式:trace_logging。
-- 執行帶 trace_logging 的查詢
SELECT count()
FROM access_logs
WHERE request_id = 'some-very-specific-request-id-abcdef'
SETTINGS log_queries=1; -- 確保查詢被記錄-- 在執行查詢后,立刻查看日志
-- 在 clickhouse-server.log 文件中,或者在 system.query_log 表中查找
-- 你會看到類似這樣的日志:
/*
<Trace> MergeTree(Reading): Mark ranges: [0, 1]
<Trace> MergeTree(Reading): Selected 1/100 parts by partition key
<Trace> MergeTree(Reading): Selected 1/50 ranges by primary key
<Trace> MergeTree(Reading): Selected 5/20 granules by skipping indexes -- 關鍵!
*/日志中的 Selected ... granules by skipping indexes 明確告訴你,數據跳過索引生效了!它幫助 ClickHouse 在主鍵篩選之后,又進一步排除了更多的 Granule。
總結與最佳實踐
-
主鍵索引是基石:
ORDER BY決定了數據的大方向,是性能優化的第一道防線。 -
跳數索引是精細化武器:它在主鍵索引篩選后的“候選范圍”內,進行二次精準打擊,進一步減少 I/O。
-
按需索驥:不要濫用索引!每個索引都會在寫入時帶來額外的計算開銷,并占用存儲空間。只為那些真正能大幅縮小查詢范圍的列創建索引。
-
如何選擇?
-
數值/日期范圍查詢 ->
minmax -
低基數
String/Enum等值查詢 ->set -
高基數
String等值查詢或has()/mapContains()->bloom_filter
-
掌握了主鍵索引和數據跳過索引的組合拳,你就掌握了開啟 ClickHouse 極致性能的鑰匙。現在,去鍛造你自己的“神兵利器”吧!
)
)








)
)




)
)

