Spring循環依賴以及三個級別緩存
什么是循環依賴?
循環依賴,顧名思義,就是指兩個或多個 Spring Bean 之間相互依賴,形成一個閉環。
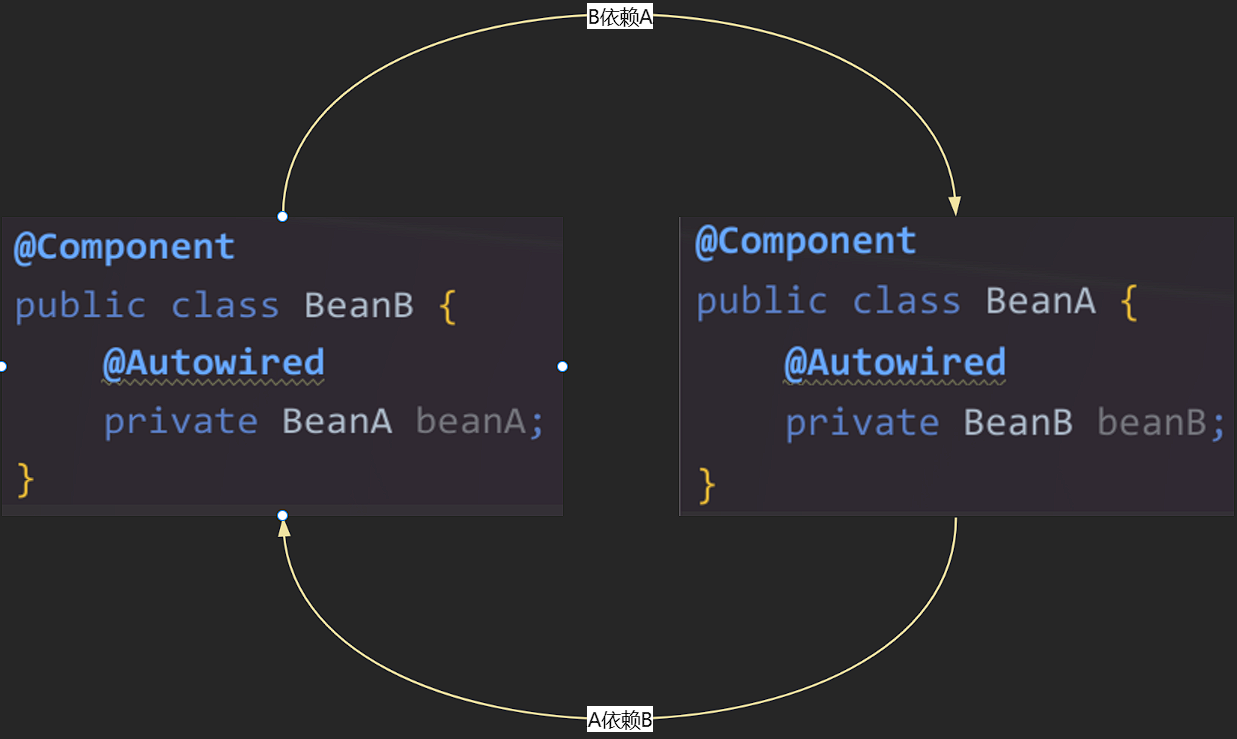
最常見也是 Spring 能夠“解決”的循環依賴是構造器注入 和 setter 注入 混合或單獨使用時,發生在 單例(Singleton) Bean 上的情況。
什么是三級緩存?
第一級緩存:singletonObjects (一級緩存 / 成品 Bean 緩存)
-
類型:
ConcurrentHashMap<String, Object> -
作用: 存放已經完全初始化好,并且可供使用的單例 Bean。當一個 Bean 在這里被找到時,它就是“成品”了,可以直接返回給請求者。
第二級緩存:earlySingletonObjects (二級緩存 / 早期暴露對象緩存)
-
類型:
ConcurrentHashMap<String, Object> -
作用: 存放已經實例化但尚未完成屬性填充和初始化的 Bean。這些 Bean 是“半成品”,但它們被提前暴露出來,以便解決循環依賴。
第三級緩存:singletonFactories (三級緩存 / 早期單例工廠緩存)
- 類型:
HashMap<String, ObjectFactory<?>> - 作用: 存放創建 Bean 的 ObjectFactory。這個工廠負責生產“半成品”的 Bean 實例(可能經過 AOP 代理)。它是解決循環依賴的關鍵所在,尤其是在涉及到 AOP 代理的場景。
- 特點: 這里的不是 Bean 實例本身,而是一個能夠獲取早期 Bean 引用(可能是原始對象,也可能是代理對象)的工廠。
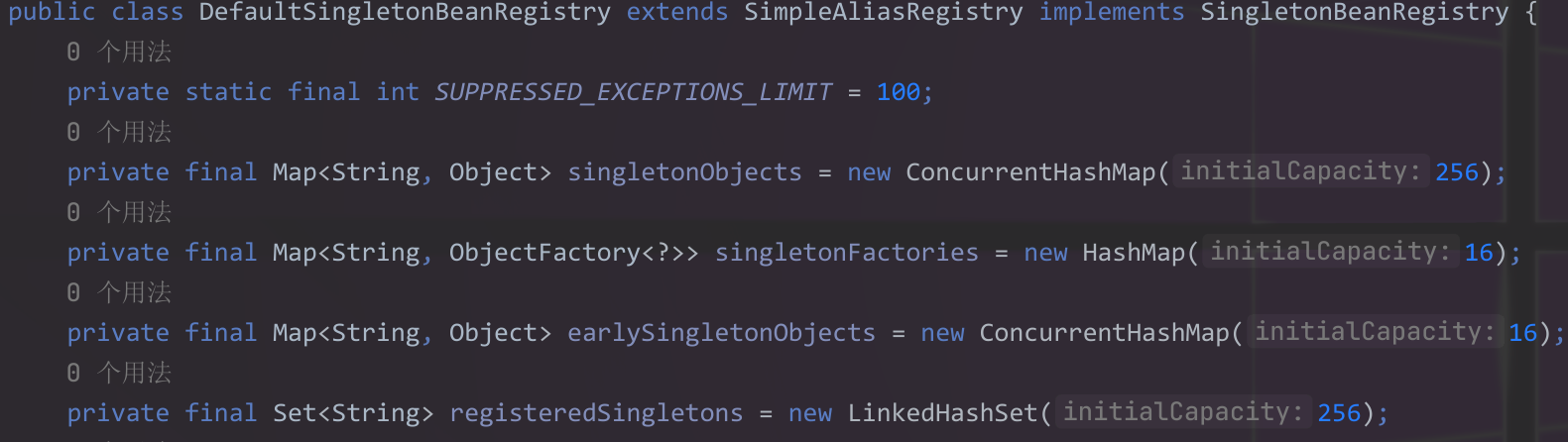
我們可以看到三級緩存singletonFactories的類型是HashMap,并且map的value值為ObjectFactory,不同于其他兩級緩存。
💠為什么 value 是 ObjectFactory 而不是 Object?
-
這就是第三級緩存的精妙之處,也是它能夠解決循環依賴與 AOP 代理同時存在問題的關鍵:
- 延遲生成早期引用:
- 在 Bean A 實例化后,它會立即將一個
ObjectFactory放入第三級緩存。 - 這個工廠只有在另一個 Bean B 發生循環依賴,并且需要提前獲取 Bean A 的引用時,才會被調用(
singletonFactory.getObject())。 - 這種延遲機制使得 Spring 可以在真正需要 Bean A 的早期引用時,才決定并生成它。
- 在 Bean A 實例化后,它會立即將一個
- 處理 AOP 代理:
- 如果 Bean A 需要進行 AOP 代理(例如,因為它上面有
@Transactional注解,或者被某個切面匹配到),那么在ObjectFactory的getObject()方法被調用時,Spring 的 AOP 邏輯會被觸發。 - 此時,
getObject()方法將不會簡單地返回 Bean A 的原始實例,而是會返回 Bean A 的代理實例。 - 這個代理實例隨后會被放入第二級緩存
earlySingletonObjects,供依賴方使用。
- 如果 Bean A 需要進行 AOP 代理(例如,因為它上面有
總結來說:
- 一級和二級緩存直接存放Bean 實例(成品或半成品)。
- 第三級緩存存放的是一個**“生產 Bean 實例的工廠”**。這個工廠在被調用時,能根據 Bean 的特性(特別是是否需要 AOP 代理),決定是返回原始實例還是其代理實例。
正是因為
singletonFactories存儲的是一個能夠“生產”早期 Bean 實例的工廠,而不是直接的 Bean 實例,Spring 才能夠在循環依賴的場景下,靈活地提供經過 AOP 代理的早期 Bean 引用,從而保證了 Bean 引用的一致性,解決了復雜場景下的循環依賴問題。 - 延遲生成早期引用:
💠為什么 singletonFactories 使用 HashMap?
-
singletonObjects和earlySingletonObjects需要ConcurrentHashMap是因為它們是并發訪問的熱點,需要內部的并發控制來保證性能和線程安全。 -
singletonFactories使用HashMap是因為它的所有相關操作都已經被外部的synchronized (this.singletonObjects)鎖保護起來,本身不需要內部的并發機制。 在這個全局鎖的保護下,使用HashMap既滿足了線程安全,又因為其操作頻率相對較低而沒有性能瓶頸。
循環依賴流程?
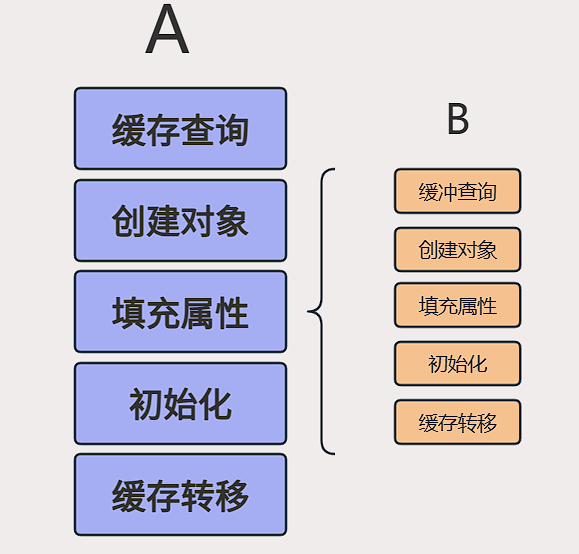
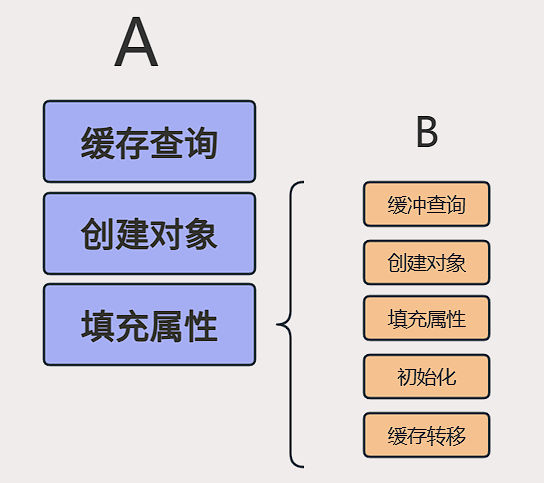
這五個是單例 Bean 的創建和緩存緊密相關的核心環節,清晰描述了 Spring 單例 Bean 的生命周期
- 緩存查詢
? 這是獲取 Bean 的第一步,也是最快、最高效的方式。
-
目標:檢查 Spring IoC 容器中是否已經存在一個完全初始化好的 Bean 實例。
-
實現:Spring 會首先去它的**一級緩存(
singletonObjects)**中查找。 -
結果:
-
如果找到了,直接返回這個 Bean 實例。這是最理想的情況,省去了后續所有創建和初始化步驟。
-
如果沒找到,并且這個 Bean 當前正在創建中(表示可能存在循環依賴),它會進一步嘗試從**二級緩存(
earlySingletonObjects)或三級緩存(singletonFactories)**獲取一個早期引用。
-
- 創建對象 (實例化)
? 如果緩存中沒有找到可用的 Bean,那么 Spring 就會開始創建新的 Bean 實例。
- 目標:根據 Bean 定義(
BeanDefinition),通過反射等方式,生成 Bean 的原始實例。 - 實現:
- 對于普通 Bean,通常是調用其構造函數來創建對象。
- 在實例化完成后,Bean 的原始實例就存在了,但此時它只是一個“空殼”,沒有任何屬性被填充,也沒有進行任何初始化操作。
- 關鍵時機:這個階段是 Bean 生命周期中首次出現具體對象的地方。也是在這個階段之后,如果存在循環依賴且允許早期引用,Spring 會將 Bean 的一個早期引用工廠(
ObjectFactory)放入三級緩存。
- 填充屬性
? 對象創建后,它需要被注入所依賴的其他 Bean 和配置。
- 目標:將 Bean 定義中聲明的屬性(通過
@Autowired、@Resource等注解或 XML 配置)注入到剛創建的 Bean 實例中。 - 實現:
- Spring IoC 容器會解析 Bean 的依賴關系。
- 如果是通過 Setter 方法注入或字段注入,Spring 會查找對應的依賴 Bean。
- 如果在這個過程中遇到循環依賴(例如,
BeanA依賴BeanB,而BeanB此時需要BeanA),Spring 會利用之前放入三級緩存中的ObjectFactory來獲取BeanA的早期引用(可能是代理對象),從而打破循環。
- 關鍵時機:循環依賴問題主要發生在這個階段。
- 初始化
? 屬性填充完成后,Bean 實例就具備了它所有的依賴,但可能還需要進行一些自定義的初始化工作。
-
目標:執行 Bean 的自定義初始化邏輯和生命周期回調。
-
實現:
- Aware 接口回調:如果 Bean 實現了
BeanNameAware、BeanFactoryAware、ApplicationContextAware等接口,Spring 會調用相應的方法注入名稱、工廠或上下文。 - BeanPostProcessor 前置處理:調用所有注冊的
BeanPostProcessor的postProcessBeforeInitialization方法。 @PostConstruct方法:執行 Bean 中被@PostConstruct注解標記的方法。InitializingBean接口afterPropertiesSet()方法:如果 Bean 實現了InitializingBean接口,調用其afterPropertiesSet()方法。- 自定義
init-method:執行 Bean 定義中指定的自定義初始化方法(如 XML 配置中的init-method)。 - BeanPostProcessor 后置處理:調用所有注冊的
BeanPostProcessor的postProcessAfterInitialization方法。AOP 代理通常在這個階段發生,postProcessAfterInitialization方法會返回 Bean 的代理對象。
- Aware 接口回調:如果 Bean 實現了
-
關鍵時機:Bean 的最終形態(包含所有代理)通常在這個階段確定。
- 緩存轉移 (放入一級緩存)
? 所有步驟都完成后,這個 Bean 就“大功告成”了。
- 目標:將完全初始化并可用的 Bean 實例,從所有臨時緩存中移除,并放入最終的成品緩存。
- 實現:
- Spring 會將這個 Bean 實例放入一級緩存(
singletonObjects)。 - 同時,從**二級緩存(
earlySingletonObjects)和三級緩存(singletonFactories)**中移除該 Bean 的相關條目,因為它現在已經是“成品”了,不再是早期引用或工廠。
- Spring 會將這個 Bean 實例放入一級緩存(
- 結果:此后,任何對該 Bean 的請求都將直接從一級緩存中獲取,高效且快速。
來看BeanA和BeanB這個循環依賴流程,在三級緩存中是怎么作用的?
流程參考視頻[徹底拿捏Spring循環依賴以及三個級別緩存嗶哩嗶哩bilibili]
首先來看BeanA的創建過程
?1.緩存查詢
查詢三級緩存,都沒有,回到主流程,進行創建對象。
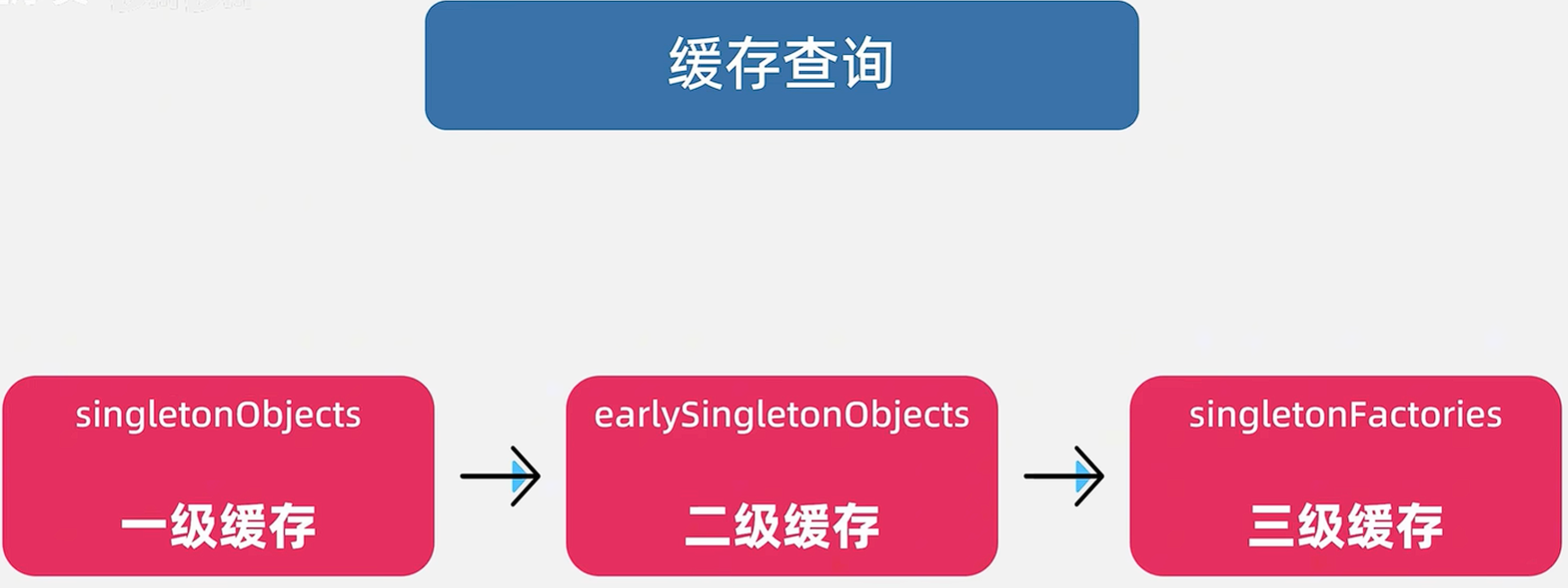
?2.創建對象
我們通過反射創建對象,包裝成ObjectFactory類型,放到三級緩存singletonFactories中,再回到主流程,進行填充屬性。
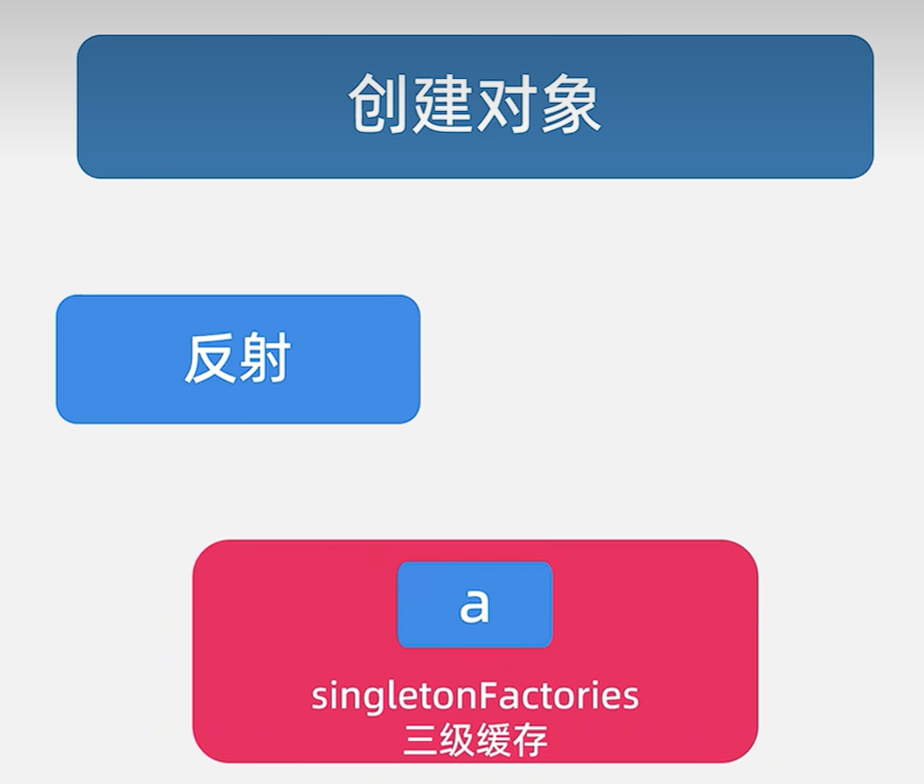
?3.填充屬性
因為填充的是BeanB,所以要開始創建BeanB,同樣走的是BeanA走的那一套流程 。
? 🎯3.1 進行緩存查詢,查詢不到,進行下一步創建對象。
? 🎯3.2 進行通過反射創建對象,此時三級緩存singletonFactories中已經有BeanA了,將BeanB放進去
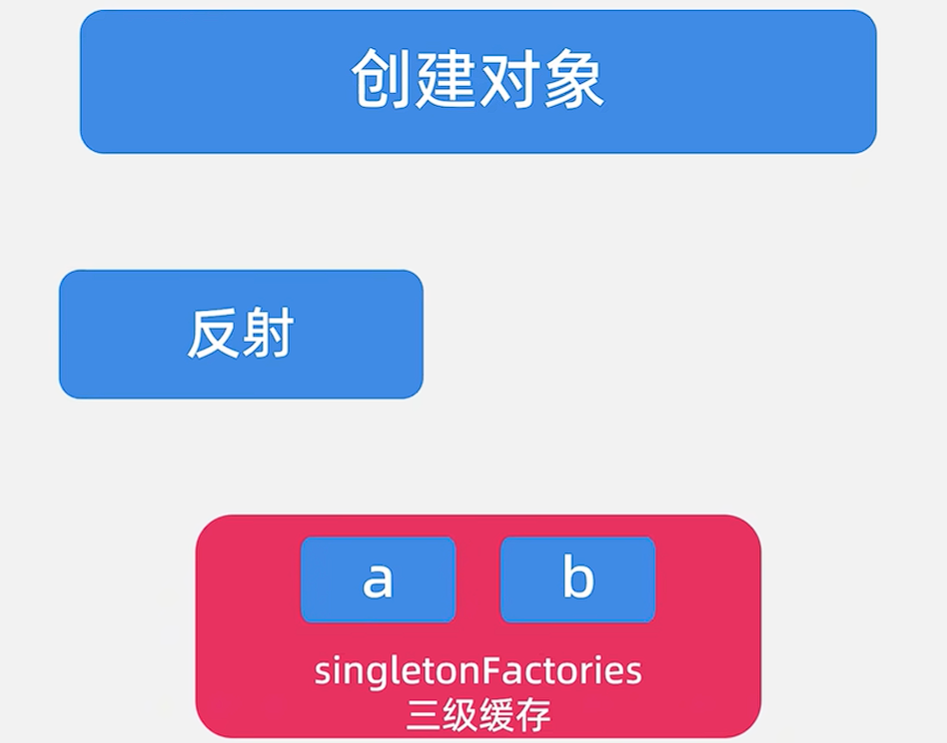
? 🎯3.3填充屬性,要填充BeanA,又要開始創建BeanA的那一套流程。
? 3.3.1 進行緩存查詢,此時三級緩存中是有的,執行一些額外操作
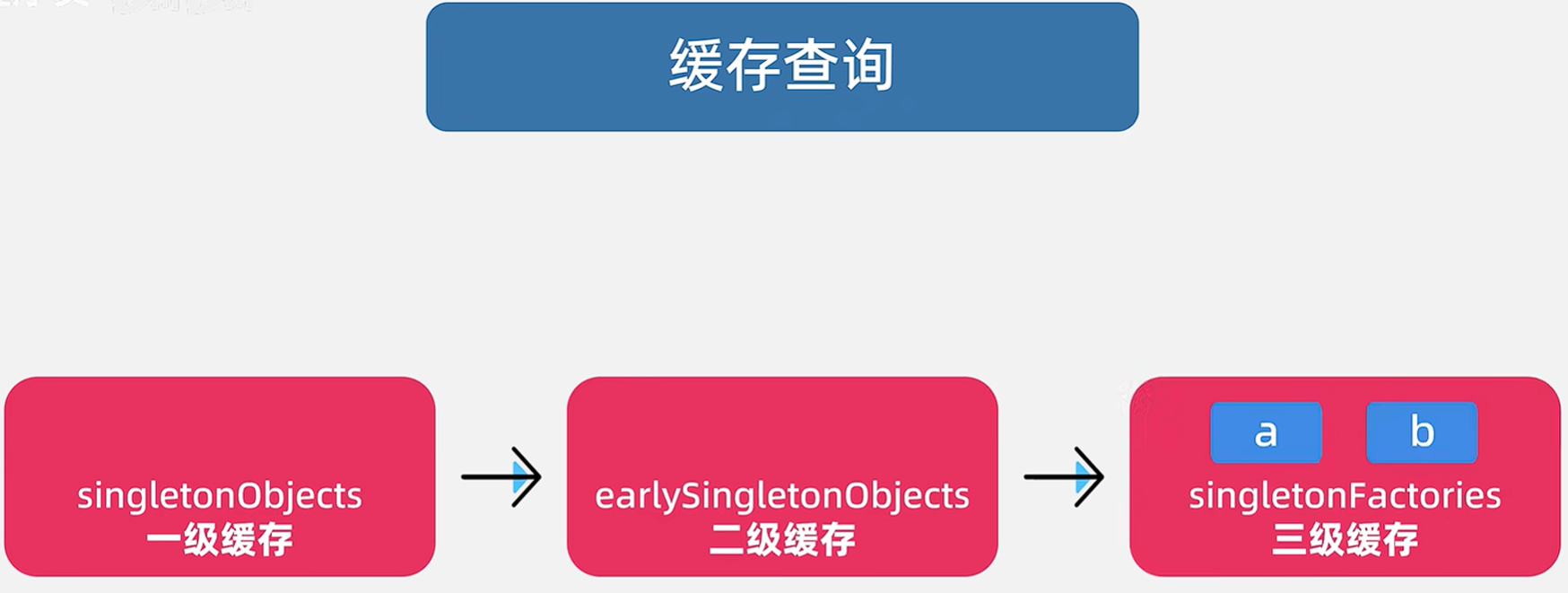
? 來看源碼,重點看2.3-2.6 ,通過getObject獲得對象,放到二級緩存中,并在三級緩存中移除它。
? 這樣BeanB的填充屬性就完成了。回到BeanB的主流程中,進行初始化
protected Object getSingleton(String beanName, boolean allowEarlyReference) {// 1. 首先嘗試從一級緩存中獲取成品 BeanObject singletonObject = this.singletonObjects.get(beanName);// 2. 如果一級緩存中沒有,并且該 Bean 正在創建中 (解決循環依賴的關鍵入口)if (singletonObject == null && this.isSingletonCurrentlyInCreation(beanName)) {// 2.1. 嘗試從二級緩存中獲取早期暴露的 BeansingletonObject = this.earlySingletonObjects.get(beanName);// 2.2. 如果二級緩存中也沒有,并且允許早期引用 (allowEarlyReference通常為true,表示允許循環依賴)if (singletonObject == null && allowEarlyReference) {// 對 singletonObjects 進行同步鎖,保證線程安全,防止多個線程同時處理同一個Bean的早期引用synchronized(this.singletonObjects) {// 再次檢查一級緩存,因為在同步塊外可能被其他線程放入singletonObject = this.singletonObjects.get(beanName);if (singletonObject == null) { // 再次確認一級緩存沒有// 再次檢查二級緩存,確保同步塊內沒有被其他線程放入singletonObject = this.earlySingletonObjects.get(beanName);if (singletonObject == null) { // 再次確認二級緩存沒有// 2.3. 從三級緩存中獲取 ObjectFactoryObjectFactory<?> singletonFactory = (ObjectFactory)this.singletonFactories.get(beanName);if (singletonFactory != null) {// 2.4. 調用 ObjectFactory 的 getObject() 方法獲取早期 Bean 實例// 這可能是原始對象,也可能是代理對象(如果AOP觸發)singletonObject = singletonFactory.getObject();// 2.5. 將獲取到的早期 Bean 實例放入二級緩存this.earlySingletonObjects.put(beanName, singletonObject);// 2.6. 從三級緩存中移除對應的 ObjectFactory,因為已經使用了this.singletonFactories.remove(beanName);}}}}}}return singletonObject;
}
? 🎯3.4 初始化,執行 Bean 的自定義初始化邏輯和生命周期回調。
? 🎯3.5 緩存轉移,因為BeanB已經完全創建完畢了,所有要將緩存里面的對象進行轉移
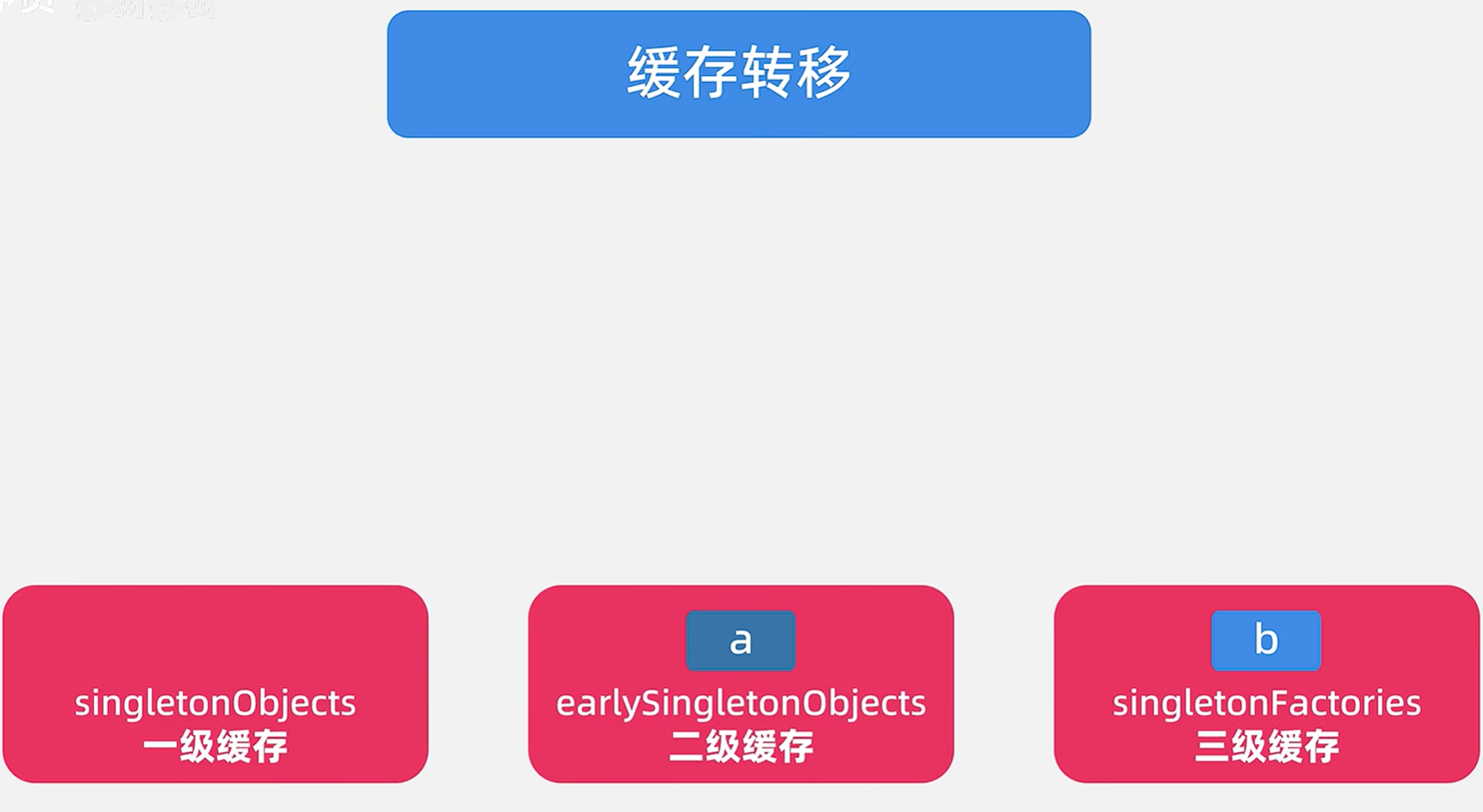
? 看源碼,將BeanB放入一級緩存中,從三級緩存中移除,從二級緩存中移除。
protected void addSingleton(String beanName, Object singletonObject) {synchronized(this.singletonObjects) {this.singletonObjects.put(beanName, singletonObject); // 放入一級緩存this.singletonFactories.remove(beanName); // 從三級緩存移除,因為已經不是早期引用了this.earlySingletonObjects.remove(beanName); // 從二級緩存移除,因為已經不是早期引用了this.registeredSingletons.add(beanName); // 記錄為已注冊的單例}
}

? 到這里整個BeanB的創建過程就完成了,但這只是BeanA填充屬性,我們還要跳回BeanA的創建過程。
?4.初始化
?5.緩存轉移
同上類似,移除二級和三級緩存中的BeanA,添加一級緩存中

為什么需要第三級緩存,有兩個不就行了
簡單來說,第三級緩存是為了解決當 Bean 存在循環依賴,并且還需要進行 AOP 代理(或者其他后置處理器處理)時的問題。
如果沒有第三級緩存,僅靠兩級緩存,Spring 無法在需要 AOP 代理時正確處理循環依賴。
為什么兩級緩存不夠?
我們來想象一下只有兩級緩存(singletonObjects 和 earlySingletonObjects)的場景:
假設有兩個 Bean:BeanA 和 BeanB。
BeanA依賴BeanB。BeanB依賴BeanA。- 最重要的是:
BeanA需要被 AOP 代理(例如,它上面有@Transactional注解,或者自定義的切面)。
流程推演(只有兩級緩存):
- 創建
BeanA:- Spring 開始創建
BeanA。 - 實例化
BeanA的原始對象a。 - 將
a放入二級緩存earlySingletonObjects。
- Spring 開始創建
BeanA填充屬性,需要BeanB:BeanA的屬性填充過程中,發現需要BeanB。- Spring 暫停
BeanA的創建,轉而創建BeanB。
- 創建
BeanB:- Spring 開始創建
BeanB。 - 實例化
BeanB的原始對象b。 - 將
b放入二級緩存earlySingletonObjects。
- Spring 開始創建
BeanB填充屬性,需要BeanA:BeanB的屬性填充過程中,發現需要BeanA。- Spring 到緩存中查找
BeanA:- 在一級緩存
singletonObjects中找不到BeanA(因為它還沒初始化完)。 - 在二級緩存
earlySingletonObjects中找到了BeanA的原始對象a。 - 將
a注射到BeanB中。
- 在一級緩存
BeanB完成初始化:BeanB完成屬性填充和所有初始化步驟。BeanB被放入一級緩存singletonObjects,完成創建。
BeanA繼續完成初始化:BeanA現在得到了完整的BeanB。BeanA繼續進行初始化步驟,包括執行 AOP 代理邏輯。- 此時,問題來了:當
BeanA執行 AOP 代理時,它會生成一個代理對象a_proxy。這個a_proxy才是最終應該被其他 Bean 引用和使用的對象。 - 但問題是,
BeanB在第4步中已經獲取并使用了BeanA的原始對象a,而不是a_proxy。
結論: 在這種情況下,BeanB 引用的是未被 AOP 代理的 BeanA 原始對象,而其他后來的 Bean 引用的是 BeanA 的代理對象。這就導致了 Bean 實例的不一致性,后續對 BeanA 的方法調用可能無法觸發 AOP 邏輯,從而導致功能異常。
第三級緩存 singletonFactories 的作用
第三級緩存 singletonFactories 存放的不是 Bean 實例,而是一個 ObjectFactory(一個工廠)。這個工廠的 getObject() 方法,會在需要時,動態地生成并返回 Bean 的早期引用。
關鍵在于:這個工廠在生成早期引用時,會判斷當前 Bean 是否需要進行 AOP 代理。如果需要,它會直接返回代理對象;如果不需要,它就返回原始對象。
引入第三級緩存后的流程推演:
- 創建
BeanA:- Spring 開始創建
BeanA。 - 實例化
BeanA的原始對象a。 - Spring 將一個
ObjectFactory放入第三級緩存singletonFactories。 這個工廠在被調用時,會負責生成BeanA的早期引用(可能是原始對象或代理對象)。 - 同時,將
BeanA從singletonFactories中移除,將原始對象a放入earlySingletonObjects(二級緩存)。
- Spring 開始創建
BeanA填充屬性,需要BeanB:BeanA的屬性填充過程中,發現需要BeanB。- Spring 暫停
BeanA的創建,轉而創建BeanB。
- 創建
BeanB(步驟同前,不再贅述)。 BeanB填充屬性,需要BeanA:BeanB的屬性填充過程中,發現需要BeanA。- Spring 到緩存中查找
BeanA:- 在一級緩存
singletonObjects中找不到。 - 在二級緩存
earlySingletonObjects中找到了BeanA的原始對象a。 - 如果此時
BeanA需要被 AOP 代理,并且 AOP 后置處理器已經準備好,那么earlySingletonObjects中的a將不會直接返回給BeanB。 - 而是會通過
singletonFactories中對應的ObjectFactory來獲取BeanA的早期引用。 這個工廠被調用時,會觸發BeanA的 AOP 代理邏輯,生成a_proxy。 a_proxy會被放入二級緩存earlySingletonObjects,替換掉原始對象a。(重要:這里原始對象被替換為代理對象)- 然后,
a_proxy被注射到BeanB中。
- 在一級緩存
BeanB完成初始化:BeanB完成屬性填充和所有初始化步驟,并被放入一級緩存singletonObjects。
BeanA繼續完成初始化:BeanA現在得到了完整的BeanB。BeanA繼續進行剩余的初始化步驟。BeanA的最終代理對象(如果之前生成過,就是那個a_proxy;如果沒有,則在此處生成并最終確定)被放入一級緩存singletonObjects。
核心優勢:
通過三級緩存,當一個 Bean(比如 BeanA)在創建過程中被另一個 Bean(比如 BeanB)提前引用時,并且這個 BeanA 需要被 AOP 代理,三級緩存中的 ObjectFactory 能夠保證所有獲取到的早期引用都是經過 AOP 代理后的對象。這樣就確保了 Bean 實例的一致性,無論是在循環依賴中被提前引用,還是在后續正常流程中被引用,都將得到的是同一個 AOP 代理后的實例。
總結: 兩級緩存無法處理 AOP 代理的場景,因為在 Bean 完全初始化前無法確定最終是返回原始對象還是代理對象。第三級緩存通過存儲一個工廠(ObjectFactory),使得 Spring 能夠在需要時才決定并生成最終的早期引用(可以是原始對象,也可以是代理對象),從而保證了在循環依賴和 AOP 代理同時存在時的正確性和一致性。





:從零實現一個“微型React”:Virtual DOM的真面目)




)


)





