25年7月來自清華、中科大和上海交大的論文“Tactile-VLA: Unlocking Vision-Language- Action Model’s Physical Knowledge For Tactile Generalization ”。
視覺-語言-動作 (VLA) 模型已展現出卓越的成就,這得益于其視覺-語言組件豐富的隱性知識。然而,要實現通用機器人智體,需要精確地扎根于物理交互,尤其是在接觸頻繁的場景中,細粒度的力控制至關重要。VLA 的隱性知識從確定要做什么提升到指導如何與現實世界進行物理交互。 Tactile-VLA,是一個深度融合視覺、語言、動作和觸覺感知的全新框架。該框架包含一個混合的位置-力控制器,用于將模型的意圖轉化為精確的物理動作,以及一個推理模塊,使機器人能夠根據觸覺反饋調整其策略。實驗證明 Tactile-VLA 在三個關鍵方面的有效性和泛化能力:(1)支持觸覺-覺察指令的遵循;(2)利用與觸覺相關的常識;以及(3)促進自適應觸覺推理。一項關鍵發現是,VLM 的先驗知識已經包含對物理交互的語義理解;只需幾次演示,即可將其連接到機器人的觸覺傳感器,從而激活這些先驗知識,在接觸密集型任務中實現零樣本泛化。
通才機器人智體(能夠在非結構化環境中理解和執行各種任務的系統)的開發,因視覺-語言-動作 (VLA) 模型的興起而得到了極大的加速 (Brohan,2022;Zitkovich,2023;Black,2024;Pertsch,2025;Wen,2025)。這些模型利用預訓練的視覺語言主干網絡來解讀抽象指令,并展現出跨任務、模態和環境的出色泛化能力。然而,盡管目前的 VLA 擅長高級推理和規劃,但它們在將決策基于現實世界的細粒度物理現實方面往往存在不足,尤其是在接觸密集、精確力控制至關重要的環境中 (Hao,2025;Xue,2025)。
這一追求中缺失的一個關鍵環節是觸覺感知。與提供高級語義信息的視覺和語言不同,觸覺感知提供關于物理交互的豐富、局部且時間動態的反饋——這些信息對于涉及摩擦、柔順性或材料敏感性的任務至關重要(Spelmezan 2009;Sinico 2025)。盡管近期一些研究已將觸覺技術融入機器人框架(Pattabiraman;Jones,2025;Yu,2025),但觸覺通常僅被視為一種補充感知模態,并未直接參與策略的行動生成。
機器人策略中的觸覺集成。除了 VLA 范式之外,大量的研究已經探索將觸覺信號集成到機器人策略中。技術策略多種多樣,從經典的控制方法到基于學習的現代策略,涵蓋諸如抓取(Calandra,2018;Polic,2019)、插入(Dong,2021;Ma,2019)、手部操作(She,2021,Qi 2023)、織物處理(Sunil,2023)和工具使用(She,2021)等任務。這些努力催生了各種有效的專用策略。在基于學習的方法中,已經開發出一些策略,例如將規劃與控制分離的分層架構(Xue,2025)、帶有形狀獎勵的強化學習(Schoettler,2020)、以力為中心的模仿學習(Liu,2024)以及端到端的視覺-觸覺策略(Yu,2024)。雖然這些專門的策略在其預期任務中表現出色,但由于通常不包含語言模態,它們泛化到新指令、推理抽象目標或利用常識性知識的能力可能有限。
本文工作旨在將這些基于觸覺的策略的物理精確性與現代 VLA 的語義靈活性和廣泛的世界知識相結合。Tactile-VLA 是一種深度融合視覺、語言、動作和觸覺的全新方法和框架,用于完成接觸式操控任務。Tactile-VLA 超越現有范式,它不僅利用視覺-語言模型中的隱性知識進行規劃(Yang;Wang,2024;Mei,2024;Hu,2024),還能在力控制層面直接指導物理交互。
如圖所示,實驗證明這種跨三個維度深度集成的優勢:觸覺-覺察指令跟蹤,使機器人能夠學習與力相關的語言的含義,例如“輕柔”或“用力”等副詞,從而使機器人能夠彌合抽象意圖和物理執行之間的差距,即使在零樣本場景中也是如此;觸覺相關常識,使機器人能夠應用世界知識和語義推理,根據目標屬性和上下文線索調整其接觸行為;觸覺參與推理,促進反饋驅動的控制調整和自主重新規劃。這是通過思維鏈 (CoT) 過程實現的,其中模型明確地推理觸覺反饋來診斷故障并制定糾正措施,尤其是在面對新場景或故障情況時。

如圖所示 Tactile- VLA 的概覽架構:
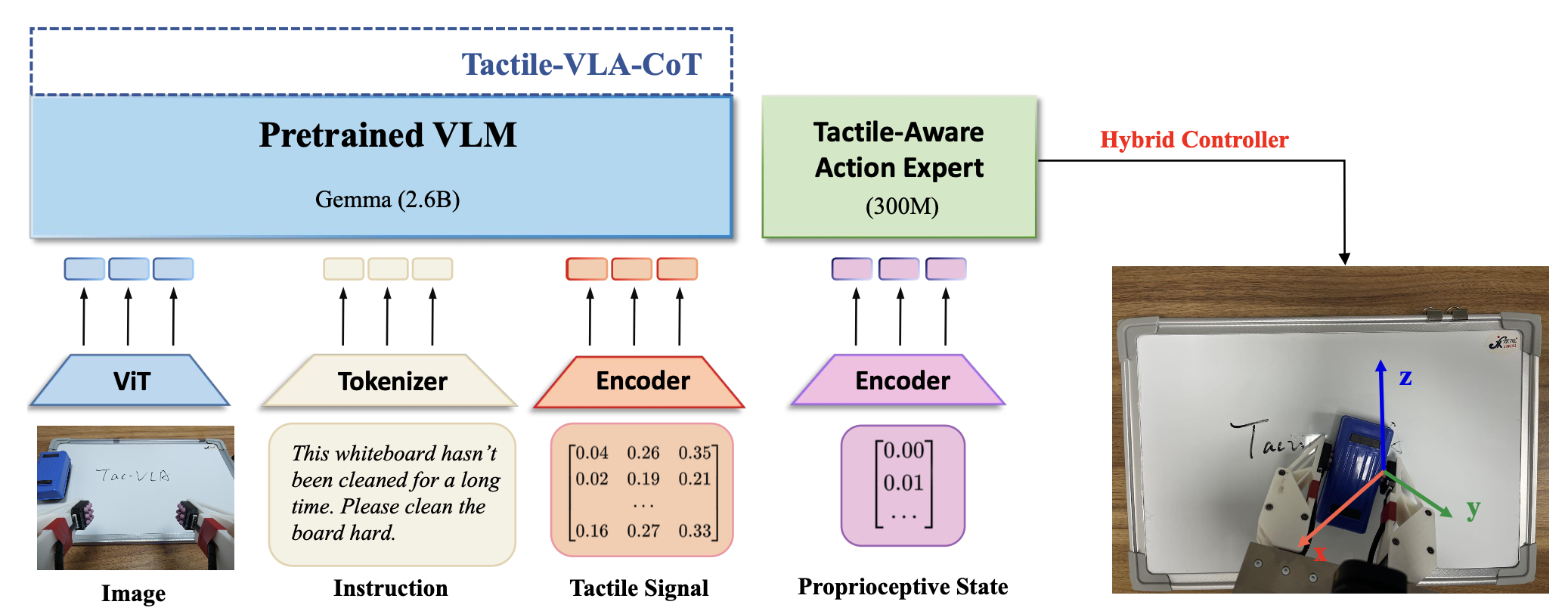
策略架構與學習
Tactile-VLA 的核心設計目標是解鎖視覺-語言-動作 (VLA) 模型中固有的物理知識,將其對交互的抽象理解轉化為精確的、現實世界的力控制。這種能力對于區分具有相同動作但力不同的命令至關重要,例如“用力插入 USB”和“輕輕插入 USB”。模型通過創建從多模態感知輸入到力感知動作輸出的直接映射來實現這一點,并以流匹配目標進行端到端訓練。
該架構采用 token 級融合方法,將輸入前綴中的多模態信息深度集成到 Transformer 主干網絡。這種設計對于 Tactile-VLA 的高級推理能力至關重要,尤其是對于 Tactile-VLA-CoT 變型中的思維鏈 (CoT) 過程。為了實現這一點,引入針對每種模態特征定制的編碼器。對于視覺信息,用預訓練的 Vision Transformer (ViT) 編碼器 (E′_vis)(Dosovitskiy et al., 2020) ,類似于 π_0 (Black et al., 2024),將最后的 H 幀編碼為一系列不同的 token 集。對于觸覺信號,一個簡單的 MLP 充當編碼器 E_ψ′,它將 H 個觸覺測量值的串聯歷史記錄處理成一個融合的 token,以表示交互的時間動態。然后,將這些生成的視覺、觸覺和語言 token 串聯起來,形成統一的輸入前綴序列 S_t。
S_t 由模型的 Transformer 主干進行處理。此前綴上的非因果注意機制允許視覺、語言和觸覺 token 自由地交叉關注,從而創建深度集成且具有語境關聯的表征。
這種豐富的表征構成了生成力-覺察動作的基礎。前綴隨后被饋送到觸覺-覺察動作專家,專家輸出一個增強的動作向量,明確指定目標位置 Ptarget 和目標接觸力 F_target。這些目標由用于模仿學習的專家演示提供。通過將力直接納入動作空間,模型可以學習控制物理交互的強度。
該模型通過模仿學習進行端到端微調來學習這種復雜的映射。該過程首先使用來自 π_0(Black,2024)的預訓練參數初始化共享組件,π_0 是一種通用的視覺-語言-動作策略。相反,新引入的模塊(例如觸覺編碼器和改進的動作專家)則隨機初始化。然后,通過采用條件流匹配 (CFM) 目標對整個模型進行微調,其中損失函數會懲罰預測動作序列在運動學和力維度上的偏差。這種學習機制迫使模型利用 VLM 的潛物理知識,最終在語言細微差別(例如“輕輕地”)與其相應的物理力量大小(例如 0.5N)之間建立直接映射。
混合位置-力控制器
一旦觸覺-覺察動作專家確定了目標位置和目標力,就需要一個低級控制器來平衡這兩個不同的目標。策略是以位置為主導,最終通過位置指令實現,并承認大多數操作任務都以精確的運動學運動為主導,僅在接觸階段才需要力控制 (Raibert & Craig, 1981)。為了整合力的目標,采用一種受阻抗控制原理 (Hogan, 1985) 啟發的間接力控制方法。這涉及將力的目標轉化為位置指令的自適應調整。
然而,與旨在實現被動柔順的經典阻抗控制不同,目標是主動跟蹤目標力。控制器測量力誤差 ?F = F_target ? F_measured,僅當其幅度 ||?F|| 超過預定閾值 τ 時,才使用該誤差計算校正位置調整,以增強操作的平滑度。
然后,PID (Willis, 1999) 控制器將機器人的關節驅動到動態更新的 P_hybird。具體來說,將兩個不同的力分量(凈外力和內部抓取力)的控制分離。這種分離的關鍵原理是建立兩個獨立的控制通道。夾持器的笛卡爾位置,用于專門調節施加于物體的凈外力,而夾持器的寬度則同時用于控制內部抓取力,從而決定物體的抓取牢固程度。
Tactile-VLA-COT:基于推理的自適應
雖然核心的 Tactile-VLA 架構提供了細粒度的力控制,但利用其固有的推理能力是進一步釋放 VLM 魯棒自適應潛力的關鍵 (Stone;Huang,2023;Shi,2024;Belkhale,2024)。為此提出 Tactile-VLA-CoT,這是一種集成思維鏈 (CoT) 的變型,可以激活和利用 VLM 的潛在推理能力 (Wei,2022;Chen,2024;Zhang,2024;Lin,2025)。在這個變型中,力和觸覺反饋不僅僅是策略輸入;它們成為自適應推理和重規劃的關鍵線索。
CoT 過程是通過使用 VLM 自身的預訓練解碼器來生成清晰的內部獨白來實現的。這種獨白使模型能夠推理故障原因(例如意外滑落),并制定糾正措施。為了實現這一點,用一個小型的、有針對性的演示數據集對模型進行微調。該數據集中的每個樣本都捕獲一個特定的故障事件(例如,滑倒擦拭黑板),并將多模態感知流與分析故障原因的語言注釋配對。這種訓練有兩個目的:首先,它保留 VLM 的通用推理能力,減輕微調過程中的災難性遺忘。更重要的是,它將這種推理擴展到觸覺模態,教會模型從傳感器信號中推斷物理現象,例如從剪切-力信號中檢測擦拭時向下的壓力不足或工具滑落。
在實踐中,這種 CoT 推理會以固定的時間間隔觸發。這種簡單有效的方法允許模型定期檢查其進度。提示結構首先要求模型確定任務是否成功完成。如果判定為失敗,則提示模型使用傳感反饋分析根本原因,如圖所示。最終的推理輸出會明確分析不同的力分量(例如,“抓握力足夠,但法向力太小”),然后制定新的糾正指令來指導下一次嘗試,例如生成“再次擦拭板子,但施加更大的向下力”。此過程通過使適應過程明確化并基于物理交互,增強了系統處理復雜場景的能力。

數據收集
準確且語義一致的觸覺數據,對于在接觸密集的場景中訓練智能體至關重要。傳統的遠程操作不足以實現這一目標,因為人類操作員通常缺乏直接的力反饋。以這種方式收集的策略本質上不依賴于觸覺信息,因此不適合學習目標。為了解決這個問題,基于通用操作接口 (UMI)(Chi,2024),一種便攜式手持設備,構建了一個專門的數據收集裝置。為 UMI 夾持器配備雙高分辨率觸覺傳感器,能夠捕捉法向力和剪切力,使操作員能夠直接感知接觸動態并提供明確由力引導的演示。

仔細考慮時間同步的問題。在每次收集會話之前,都會對齊所有數據流的時間戳。在采集過程中,捕捉 100Hz 觸覺反饋和 20Hz 視覺數據,隨后對高頻觸覺信號進行下采樣,使其與對應的視覺幀匹配。最終生成的 VLA-T 訓練數據集包含來自視覺、語言、觸覺和動作軌跡的精確同步的多模態信息。
實現細節
基線。為了回答上述問題,在各種任務上將以下基線方法和簡化方法與所提出的 Tactile-VLA 進行比較:π0-base,一個用于通用機器人控制的“視覺-語言-動作”流程模型;π0-fast,π0-base 的一個變型;Tactile-VLA,本文方法;以及 Tactile-VLA-CoT,一個帶有 CoT 推理過程的 Tactile-VLA 變型。
任務和數據收集。主要關注三個接觸豐富的操作任務,如下所示:充電器/USB 插入和拔出、桌面抓取和擦拭電路板。在充電器/USB 插入和拔出任務中,機器人必須拔出充電器或 USB 并將其插入正確的插座。對于訓練數據,分別收集 100 個“軟”和“硬”USB 操作的演示,以及另外 100 個充電器任務的演示,以學習基本動作。在桌面抓取任務中,機器人需要以適當的力度抓取各種物體,并提前判斷這些物體是重還是易碎。這項任務的訓練使用了每個物體 50 次的演示。

如圖中可視化的六個物體在訓練階段見過,同時引入了另外六個未見過的物體進行評估。在擦拭黑板任務中,機器人需要以默認力度擦拭黑板,評估結果,然后根據需要調整力度。為了實現這一推理,訓練數據包括 100 次在白板上成功擦拭和 100 次失敗擦拭的演示,而模型在訓練期間從未遇到過擦拭黑板的場景。
觸覺-相關指令遵循
本實驗旨在評估研究的核心假設:Tactile-VLA 能否從一項任務中學習與力相關的副詞(例如“輕柔”、“用力”)的泛化理解,并將這些語義知識應用于另一個未知任務。具體而言,將探究模型在 USB 插入任務(任務 A)中訓練將“輕柔”和“用力”與特定力場關聯后,能否成功地將這種理解遷移到充電器插入任務(任務 B),因為該任務 B 只學習了動作,而沒有接收到相應的語言力指令。這旨在檢驗真正的語義基礎,即語言在零樣本情境中直接調節物理交互。
觸覺的相關常識
在現實世界的操控任務中,機器人必須展現出跨模態泛化先驗知識的能力。具體而言,將視覺語言模型 (VLM) 的先驗知識整合到觸覺信號中,對于有效操控至關重要。例如,機器人必須通過推理物體的屬性來調整抓握方式,對不同類別的物體施加不同大小的力:對堅硬且較重的物體施加較大的力,對堅硬且較輕的物體施加中等力度,對易碎且較輕的物體施加輕柔的力以防止損壞。這種基于先驗視覺和情境知識調整施加力的能力,對于有效執行各種操控任務至關重要。
觸覺推理
為了驗證模型的自適應推理能力,設計一個實驗,專門測試其解讀物理反饋并自主調整策略的能力。這超越了單純的遵循指令,而是通過觸覺交互來展示對任務成功或失敗的理解,這也是工作的一個關鍵主張。研究 Tactile-VLA-CoT 能否將學習到的推理過程從熟悉的任務(擦拭白板)推廣到一個新的、物理上不同的場景(擦拭黑板),這需要不同的力度,如圖所示。



)




)

)

——使用LED Strip組件點亮LED燈帶)

)

)



)