作業:
自行學習參考如何使用kaggle平臺,寫下使用注意點,并對下述比賽提交代碼
kaggle泰坦尼克號人員生還預測
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
# 數據處理清洗包
import pandas as pd
import numpy as np
import random as rnd
# 可視化包
import seaborn as sns
import matplotlib.pyplot as plt
# 機器學習算法相關包
from sklearn.linear_model import LogisticRegression, Perceptron, SGDClassifier
# 設置中文字體(解決中文顯示問題)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系統常用黑體字體
plt.rcParams['axes.unicode_minus'] = False # 正常顯示負號
data_train = pd.read_csv(r'train.csv') #讀取訓練集數據
data_test = pd.read_csv(r'test.csv') #讀取測試集數據
combine = [data_train, data_test] # 合并數據
#這只是放到一個列表,以便后續合并,現在還沒合并
print(data_train.isnull().sum())
print(data_test.isnull().sum())
#刪除無用特征 Ticket
print("Before", data_train.shape, data_test.shape, combine[0].shape, combine[1].shape)
data_train = data_train.drop(['Ticket'], axis=1)
data_test = data_test.drop(['Ticket'], axis=1)
combine = [data_train, data_test]
print("After", data_train.shape, data_test.shape, combine[0].shape, combine[1].shape)# 轉換分類特征Sex
for dataset in combine:dataset['Sex'] = dataset['Sex'].map( {'female': 1, 'male': 0} ).astype(int) #男性賦值為0,女性賦值為1,并轉換為整型數據
data_test.head()# 創建空數組
guess_ages = np.zeros((2,3))
guess_ages# 遍歷 Sex (0 或 1) 和 Pclass (1, 2, 3) 來計算六種組合的 Age 猜測值
for dataset in combine:# 第一個for循環計算每一個分組的Age預測值for i in range(0, 2):for j in range(0, 3):guess_df = dataset[(dataset['Sex'] == i) & \(dataset['Pclass'] == j+1)]['Age'].dropna()age_guess = guess_df.median()# 將隨機年齡浮點數轉換為最接近的 0.5 年齡(四舍五入)guess_ages[i,j] = int( age_guess/0.5 + 0.5 ) * 0.5# 第二個for循環對空值進行賦值 for i in range(0, 2):for j in range(0, 3):dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1),\'Age'] = guess_ages[i,j]dataset['Age'] = dataset['Age'].astype(int)
data_train.head()# Embarked: 僅2個缺失,用眾數填充
data_train['Embarked'].fillna(data_train['Embarked'].mode()[0], inplace=True)
data_test['Embarked'].fillna(data_test['Embarked'].mode()[0], inplace=True)
print(data_train.isnull().sum())
# Fare: 極少數缺失,用中位數填充
data_test['Fare'].fillna(data_test['Fare'].median(), inplace=True)# 姓名對預測生存率的影響較小,除非從中提取出有用的信息(如頭銜、家庭關系等)
data_train['Title'] = data_train['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)
data_train['Title'] = data_train['Title'].replace(['Lady', 'Countess', 'Dr', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
data_train['Title'] = data_train['Title'].replace('Mlle', 'Miss').replace('Ms', 'Miss').replace('Mme', 'Mrs')
data_test['Title'] = data_test['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)
data_test['Title'] = data_test['Title'].replace(['Lady', 'Countess', 'Dr', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
data_test['Title'] = data_test['Title'].replace('Mlle', 'Miss').replace('Ms', 'Miss').replace('Mme', 'Mrs')
# 計算家庭成員數量,家庭規模可能影響生存率
data_train['FamilySize'] = data_train['SibSp'] + data_train['Parch'] + 1
data_test['FamilySize'] = data_test['SibSp'] + data_test['Parch'] + 1
# 結合 FamilySize 創建新特征(如是否獨自乘船):
data_train['IsAlone'] = (data_train['FamilySize'] == 1).astype(int)
data_test['IsAlone'] = (data_test['FamilySize'] == 1).astype(int)
# 客艙甲板
# 提取客艙首字母(如果有的話)
data_train['Deck'] = data_train['Cabin'].str[0]
data_train['Deck'] = data_train['Deck'].fillna('Unknown') # 填充缺失值
data_test['Deck'] = data_test['Cabin'].str[0]
data_test['Deck'] = data_test['Deck'].fillna('Unknown') # 填充缺失值
# 刪除冗余特征
data_train.drop([ 'Name', 'Cabin'], axis=1, inplace=True)
data_test.drop(['Name', 'Cabin'], axis=1, inplace=True)
# 先篩選字符串變量
discrete_features = data_train.select_dtypes(include=['object']).columns.tolist()
print("離散變量:", discrete_features) # 打印離散變量列名data_train.rename(columns={'Sex': 'isFemale'}, inplace=True) # 重命名列名 -> 是否女性
data_test.rename(columns={'Sex': 'isFemale'}, inplace=True) # 重命名列名
print(data_train['isFemale'].value_counts()) # 打印Sex列的取值分布
# 對embarked和deck進行獨熱編碼(無序)
data_train = pd.get_dummies(data_train, columns=['Embarked', 'Deck'], dtype=int, drop_first=True)
data_test = pd.get_dummies(data_test, columns=['Embarked', 'Deck'], dtype=int, drop_first=True)# 確保訓練集和測試集的列順序一致
# 排除標簽列'Survived',僅比較特征列
feature_columns = [col for col in data_train.columns if col != 'Survived']
missing_cols = set(feature_columns) - set(data_test.columns)
for col in missing_cols:data_test[col] = 0
# 按照訓練集特征列的順序排序測試集列
data_test = data_test[feature_columns]print(data_train.head())
title_mapping = {'Mr': 0,'Rare': 1,'Master': 2,'Miss': 3,'Mrs': 4
}
data_train['Title'] = data_train['Title'].map(title_mapping)
data_test['Title'] = data_test['Title'].map(title_mapping)
print(data_train['Title'].value_counts()) # 打印Title列的取值分布
# 對Age, Fare 進行標準化(均值為0,方差為1)
from sklearn.preprocessing import StandardScaler, MinMaxScaler
scaler = StandardScaler()
data_train[['Age', 'Fare']] = scaler.fit_transform(data_train[['Age', 'Fare']])print(data_train.head()) # 打印前幾行數據
print(data_train.info())# 劃分一下測試集
from sklearn.model_selection import train_test_split
X = data_train.drop(['Survived'], axis=1) # 特征,axis=1表示按列刪除
y = data_train['Survived'] # 標簽
# 按照8:2劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%訓練集,20%測試集# --- 1. 默認參數的隨機森林 ---
from sklearn.ensemble import RandomForestClassifier #隨機森林分類器
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 用于評估分類器性能的指標
from sklearn.metrics import classification_report, confusion_matrix #用于生成分類報告和混淆矩陣
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息
import time
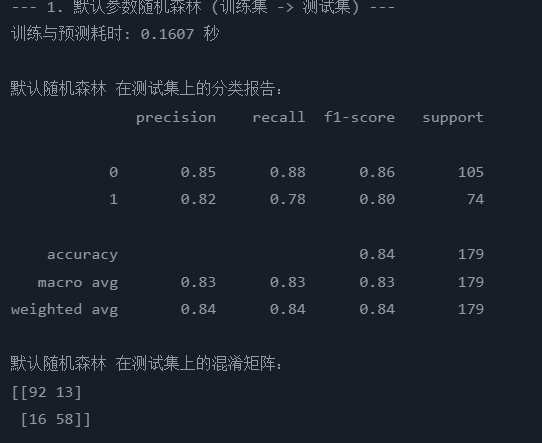
print("--- 1. 默認參數隨機森林 (訓練集 -> 測試集) ---")
start_time = time.time() # 記錄開始時間
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train) # 在訓練集上訓練
rf_pred = rf_model.predict(X_test) # 在測試集上預測
end_time = time.time() # 記錄結束時間
print(f"訓練與預測耗時: {end_time - start_time:.4f} 秒")
print("\n默認隨機森林 在測試集上的分類報告:")
print(classification_report(y_test, rf_pred))
print("默認隨機森林 在測試集上的混淆矩陣:")
print(confusion_matrix(y_test, rf_pred))
@浙大疏錦行

)










采用分布式哈希表優化區塊鏈索引結構,提高區塊鏈檢索效率)
配置元件詳解01)


)
--Cartographer在Gazebo仿真環境下的建圖以及建圖與定位階段問題(實車也可參考))

