YOLOv8-cls epochs與數據量的關系
(1)機器學習小白入門YOLOv :從概念到實踐
(2)機器學習小白入門 YOLOv:從模塊優化到工程部署
(3)機器學習小白入門 YOLOv: 解鎖圖片分類新技能
(4)機器學習小白入門YOLOv :圖片標注實操手冊
(5)機器學習小白入門 YOLOv:數據需求與圖像不足應對策略
(6)機器學習小白入門 YOLOv:圖片的數據預處理
(7)機器學習小白入門 YOLOv:模型訓練詳解
(8)機器學習小白入門 YOLO:無代碼實現分類模型訓練全流程
(9)機器學習小白入門 YOLOv:YOLOv8-cls 技術解析與代碼實現
(10)機器學習小白入門 YOLOv:YOLOv8-cls 模型評估實操
(11)機器學習小白入門YOLOv:YOLOv8-cls epochs與數據量的關系
(12)機器學習小白入門YOLOv:YOLOv8-cls 模型微調實操
在 YOLOv8-cls 模型微調中,epochs(訓練輪數)與數據量的關系是影響模型性能的核心因素,二者需動態匹配以避免過擬合或欠擬合。以下從具體場景、調整邏輯和實操建議三方面展開說明:
先說一下基礎概念:
- 欠擬合:訓練集和驗證集的表現都很差(比如準確率低、誤差大)
類比:代碼在開發環境就跑不通,連基本功能都實現不了 - 過擬合:訓練集表現極好(誤差很小),但驗證集表現突然變差(誤差顯著增大)
類比:代碼在開發時的測試用例全通過,但換一組新測試用例就大量報錯
一、數據量與 epochs 的基礎匹配邏輯
1. 數據量少(如 100-1000 張樣本)
-
特點:數據多樣性有限,模型易記住訓練樣本細節(過擬合風險高)。
-
建議 epochs:10-20 輪。
-
原理:少量數據經過較少輪次即可讓模型學習到核心特征,過多輪次會導致模型 “死記硬背” 噪聲(如圖片背景、無關細節),反而降低泛化能力。
2. 數據量中等(如 1000-10000 張樣本)
-
特點:涵蓋一定類別差異,但仍需控制訓練強度。
-
建議 epochs:20-40 輪。
-
原理:中等數據量需要足夠輪次讓模型遍歷不同樣本組合,捕捉類別共性,但超過 40 輪后可能因重復學習導致過擬合。
3. 數據量龐大(如 10000 張以上)
-
特點:樣本多樣性豐富,模型有足夠 “素材” 學習規律。
-
建議 epochs:40-50 輪(甚至更高,需結合驗證指標判斷)。
-
原理:大量數據需要更多輪次才能讓模型充分學習各類別特征分布,且因樣本多樣,過擬合風險較低。
二、兩者相互影響的核心表現
1. 數據量固定時,epochs 過高 / 過低的影響
-
過高:訓練損失持續下降,但驗證損失先降后升(過擬合),表現為模型在訓練集準確率接近 100%,但在驗證集準確率驟降。
-
過低:訓練與驗證損失均較高(欠擬合),模型未充分學習數據規律,對新樣本的預測能力差。
2. epochs 固定時,數據量不足 / 過剩的影響
-
數據量不足:即使 epochs 適中,模型也易過擬合(如 100 張樣本訓練 30 輪,模型會記住每張圖的細節)。
-
數據量過剩:若 epochs 不足,模型可能 “學不完” 數據中的特征(如 10 萬張樣本僅訓練 10 輪,每輪僅見 10% 樣本),導致欠擬合。
三、實操中如何動態調整?
1. 通過驗證損失曲線判斷
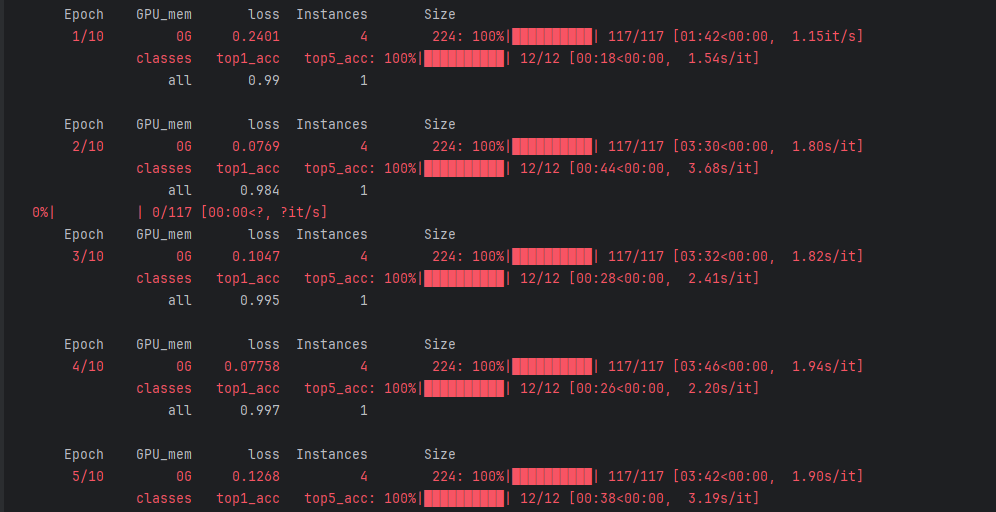
loss:損失值,衡量預測結果與真實標簽的差距,數值越小模型表現越好(如從 0.2401 逐步降到 0.07758 后小幅波動)
-
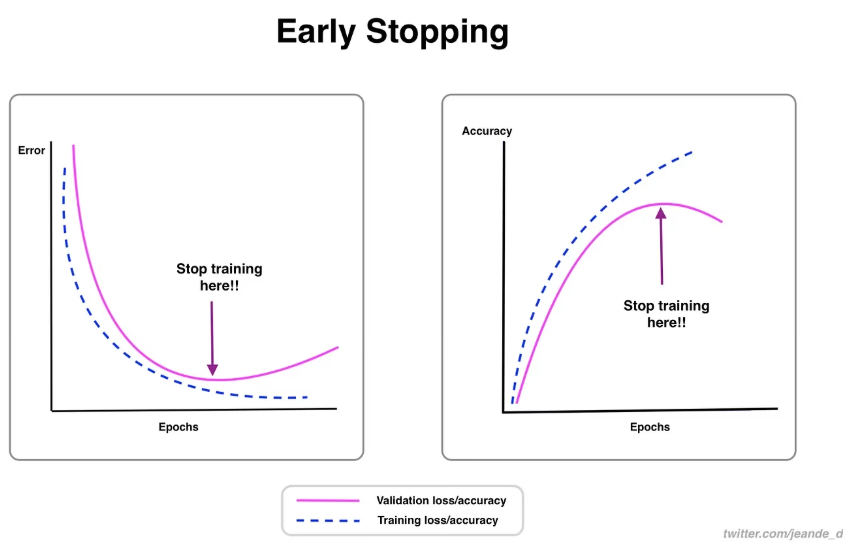
訓練過程中,若驗證損失連續 5-10 輪不再下降(甚至上升),無論當前 epochs 是否達到預設值,都應停止訓練(早停策略)。
-
示例代碼(啟用早停):
model.train(data='dataset.yaml',epochs=50, # 最大輪數patience=10, # 驗證損失10輪不下降則停止..
)
2. 數據量與 epochs 的經驗公式
對于分類任務,可參考:
總訓練樣本數 × epochs ≈ 50000-200000(根據類別復雜度調整)
- 簡單類別(如 3-5 類):取下限(5 萬),例如 5000 張樣本對應 10 輪(5000×10=5 萬)。
- 復雜類別(如 50 類以上):取上限(20 萬),例如 10000 張樣本對應 20 輪(10000×20=20 萬)。
3. 數據增強對兩者關系的影響
當數據量較少時,啟用數據增強(`augment=True`)可等效增加數據多樣性,此時可適當提高 epochs(如原 10 輪可增至 15-20 輪),但需配合驗證損失監控防止過擬合。
總結
epochs 與數據量的核心關系是 “讓模型在有限數據中充分學習,同時避免過度記憶”。實際微調時,不應機械遵循 “10-50 輪” 的建議,而需根據數據量大小、類別復雜度及驗證指標動態調整,通過早停策略和經驗公式找到最佳平衡點。例如:
-
500 張樣本 + 簡單類別 → 15-20 輪
-
5000 張樣本 + 中等復雜度 → 30-40 輪
-
10000 張樣本 + 高復雜度 → 40-50 輪(或按早停策略終止)。










)




網絡層 路由協議)
Pytorch中求逆torch.inverse和解線性方程組torch.linalg.solve有什么關系)


