目錄
一、Numpy
1.NumPy 是什么?
? 1.1安裝numpy
?1.2 導入numpy模塊
2.NumPy 的核心:ndarray
2.1?什么是 ndarray?
2.2?ndarray 的創建方式
2.3?常見屬性(用于查看數組結構)
2.4?ndarray 的切片與索引
2.5?ndarray 的運算(向量化)
2.6?ndarray 的形狀變換
2.7?數據類型轉換
3.NumPy 的常見功能
4.NumPy 的優勢
5.使用場景
6.簡單示例
二、Pandas
1.Pandas是什么?
1.1安裝 Pandas
1.2 導入 Pandas 模塊
2.核心數據結構
2.1?Series(一維標簽數組)
2.1.1創建Series的常見方法
2.1.1.1 創建 Series 空對象
2.1.1.2 ndarray 創建 Series 對象
2.1.1.3 字典創建 Series 對象
2.1.2遍歷Series
2.2?DataFrame(二維表格型數據)
2.2.1 創建 DataFrame 對象
2.2.1.1 創建空對象
2.2.1.2 列表嵌套字典
2.2.1.3 字典嵌套列表
2.2.1.4 使用Series
2.2.2 列索引操作
2.2.2.1 選取數據
2.2.2.2 添加數據
2.2.2.3 修改數據
2.2.2.4 刪除數據
2.2.3 行索引操作
2.2.3.1 loc 選取數據
2.2.3.2 iloc 選取數據
2.2.3.3 切片多行選取
2.2.3.4 添加數據行
2.2.3.5 刪除數據行
3.函數
3.1 常用的統計學函數
3.2 重置索引
3.3 遍歷
3.3.1 DataFrame 遍歷
3.4 排序
3.4.1 sort_values
3.5 去重
3.6 分組
3.7 合并
3.8 空值處理
3.8.1 檢測空值
3.8.2 填充空值
3.8.3 刪除空值
4. 讀取CSV文件
4.1 to_csv()
4.2 read_csv()
5.Pandas繪圖基礎
5.1?折線圖(默認)
5.2?柱狀圖
5.3?直方圖(hist)
5.4?餅圖(pie)
三、Matplotlib
1.概念
2.安裝
3.應用場景
4.常用API
4.1 繪圖類型
4.2 Image 函數
4.3 Axis 函數
4.4 Figure 函數
5.pylab 模塊
6.常用函數
6.1 plot 函數
6.2 figure 函數
6.2.1 figure.add_axes()
6.2.2 axes.legend()
6.3 標題中文亂碼
6.4 subplot 函數
6.5 subplots 函數
7.繪制圖表
7.1 柱狀圖
7.2 直方圖
7.3 餅圖
7.4 折線圖
7.5 散點圖
7.6 圖片讀取
四、常見的鏡像源網站?
1.pip 常用鏡像源網址
2.conda 常用鏡像源網址(Anaconda)
一、Numpy
1.NumPy 是什么?
NumPy(Numerical Python) 是 Python 科學計算的基礎包。它提供了:
高性能的 多維數組對象(ndarray)
廣播功能(Broadcasting)
向量化運算(比 Python 原生循環更快)
豐富的 數學函數庫
用于數值計算、線性代數、傅里葉變換、隨機數等科學運算
? 1.1安裝numpy
#安裝numpy
pip install numpy大家可以自行添加合適的鏡像源,常見的鏡像源在之前的文章有介紹,在本文章末尾會再次介紹?
?1.2 導入numpy模塊
import numpy as np?習慣上使用 np?作為別名,方便簡潔書寫。
2.NumPy 的核心:ndarray
2.1?什么是 ndarray?
ndarray是 NumPy 的核心類,代表一個 多維數組對象全稱是 N-dimensional array
用于存儲同一種數據類型的元素(int、float、bool 等)
支持 向量化運算、廣播機制、高效索引切片 等高級功能
2.2?ndarray 的創建方式
import numpy as np
?
a = np.array([1, 2, 3]) ? ? ? ? ? ? ? ? ? # 創建一維數組
b = np.array([[1, 2], [3, 4]]) ? ? ? ? ? ?# 創建二維數組
c = np.zeros((2, 3)) ? ? ? ? ? ? ? ? ? ? ?# 創建全 0 數組
d = np.ones((3, 3)) ? ? ? ? ? ? ? ? ? ? ? # 創建全 1 數組
e = np.arange(0, 10, 2) ? ? ? ? ? ? ? ? ? # 類似 range
f = np.linspace(0, 1, 5) ? ? ? ? ? ? ? ? ?# 線性間隔2.3?常見屬性(用于查看數組結構)
| 屬性名 | 說明 | 示例值 |
|---|---|---|
.ndim | 數組的維度 | 1、2、3... |
.shape | 各維度的大小(元組) | (2, 3) |
.size | 數組中元素總數 | 6 |
.dtype | 數組中元素的數據類型 | int32、float64 |
.itemsize | 每個元素的字節大小 | 4、8(視類型而定) |
.data | 指向實際數據的內存地址 | (一般不直接使用) |
示例:
a = np.array([[1, 2, 3], [4, 5, 6]])
print(a.ndim) ? ? ?# 輸出: 2
print(a.shape) ? ? # 輸出: (2, 3)
print(a.size) ? ? ?# 輸出: 6
print(a.dtype) ? ? # 輸出: int642.4?ndarray 的切片與索引
和 Python 的列表類似,但功能更強大:
a = np.array([[1, 2, 3], [4, 5, 6]])
?
print(a[0, 1]) ? ? ? ? # 取第一行第二列,輸出:2
print(a[1, :]) ? ? ? ? # 第二行全部,輸出:[4 5 6]
print(a[:, 0]) ? ? ? ? # 所有行第一列,輸出:[1 4]2.5?ndarray 的運算(向量化)
普通運算將自動應用到所有元素(無需 for 循環):
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
?
print(a + b) ? ? ?# 輸出:[5 7 9]
print(a * 2) ? ? ?# 輸出:[2 4 6]
print(np.sqrt(a)) # 輸出:[1. 1.4142 1.7320]2.6?ndarray 的形狀變換
a = np.array([[1, 2, 3], [4, 5, 6]])
?
print(a.reshape(3, 2)) ? ? # 重塑形狀為 3 行 2 列
print(a.T) ? ? ? ? ? ? ? ? # 轉置
print(a.flatten()) ? ? ? ? # 轉為一維數組2.7?數據類型轉換
a = np.array([1.2, 3.4])
print(a.dtype) ? ? ? ? ? ? ?# float64
print(a.astype(int)) ? ? ? ?# 轉換為整數型:[1 3]總結:為什么使用 ndarray?
-
高性能(基于 C 實現,避免 Python for 循環)
-
可用于處理大規模數據(圖像、信號、機器學習等)
-
支持矩陣運算、廣播機制、向量化計算等
-
是 Pandas、TensorFlow、Scikit-learn 等庫的底層依賴
3.NumPy 的常見功能
| 功能類別 | 說明 | 示例函數或方法 |
|---|---|---|
| 數組創建 | 快速創建數組 | np.array(), np.zeros(), np.ones(), np.arange() |
| 數組操作 | 形狀變換、轉置、拼接、切片 | .reshape(), .T, np.concatenate() |
| 數學運算 | 對整個數組執行加減乘除、三角函數 | np.add(), np.sin(), np.mean() |
| 廣播機制 | 自動擴展形狀維度,使數組可運算 | 不同形狀自動對齊操作 |
| 隨機數生成 | 生成隨機整數、浮點數 | np.random.randint(), np.random.rand() |
| 線性代數 | 矩陣乘法、求逆、特征值 | np.dot(), np.linalg.inv() |
| 文件讀寫 | 保存和加載 .npy, .txt 文件 | np.save(), np.load() |
4.NumPy 的優勢
速度快:基于 C 實現,比 Python 原生循環快幾十倍以上
代碼簡潔:一行代碼即可實現復雜數學操作
兼容性強:是 Pandas、Matplotlib、Scikit-learn 等庫的底層依賴
便于科學計算:適合處理大規模矩陣和向量數據
5.使用場景
數據預處理(如標準化)
圖像處理(圖像就是像素矩陣)
機器學習(數據矩陣運算)
數值模擬(如模擬股票、物理系統)
學術研究和工程應用
6.簡單示例
import numpy as np
?
# 創建一個 3x3 的數組
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
?
# 求和、平均值、轉置
print(np.sum(a)) ? ? ? # 輸出:45
print(np.mean(a)) ? ? ? # 輸出:5.0
print(a.T) ? ? ? ? ? ? # 輸出轉置矩陣
?
# 向量加法(廣播)
b = np.array([1, 2, 3])
print(a + b)二、Pandas
1.Pandas是什么?
Pandas 是一個開源的第三方 Python 庫,從 Numpy 和 Matplotlib 的基礎上構建而來
Pandas 名字衍生自術語 "panel data"(面板數據)和 "Python data analysis"(Python 數據分析)
Pandas 已經成為 Python 數據分析的必備高級工具,它的目標是成為強大、靈活、可以支持任何編程語言的數據分析工具
Pandas 是 Python 語言的一個擴展程序庫,用于數據分析
Pandas 是一個開放源碼、BSD 許可的庫,提供高性能、易于使用的數據結構和數據分析工具
Pandas 一個強大的分析結構化數據的工具集,基礎是 Numpy(提供高性能的矩陣運算)
Pandas 可以從各種文件格式比如 CSV、JSON、SQL、Microsoft Excel 導入數據
Pandas 可以對各種數據進行運算操作,比如歸并、再成形、選擇,還有數據清洗和數據加工特征
Pandas 廣泛應用在學術、金融、統計學等各個數據分析領域
Pandas 的出現使得 Python 做數據分析的能力得到了大幅度提升,它主要實現了數據分析的五個重要環節:加載數據、整理數據、操作數據、構建數據模型、分析數據
1.1安裝 Pandas
pip install pandas大家可以自行添加合適的鏡像源,常見的鏡像源在之前的文章有介紹,在本文章末尾會再次介紹
建議搭配 numpy、jupyter、matplotlib 一起使用。
1.2 導入 Pandas 模塊
import pandas as pd習慣上使用 pd 作為別名,方便簡潔書寫。
2.核心數據結構
2.1?Series(一維標簽數組)
import pandas as pddata = pd.Series([10, 20, 30, 40], index=['a', 'b', 'c', 'd'])
print(data)特點:
類似于一維數組,但帶有索引(標簽);
支持 NumPy 的大多數操作;
可以通過標簽或位置訪問元素。
data['b'] # 通過標簽
data[1] # 通過位置2.1.1創建Series的常見方法
2.1.1.1 創建 Series 空對象
import pandas as pd
?
# Series 空對象
def one():series_one = pd.Series(dtype='f8')print('空對象:\n', series_one)直接賦值創建Series 對象
series_one = pd.Series([1,2,3,4,5], dtype='f8')
print('Series對象:\n', series_one)2.1.1.2 ndarray 創建 Series 對象
import pandas as pd
import numpy as np
?
array_one = np.array(['小明', '小紅', '小紫'])
series_one = pd.Series(data=array_one)
print('ndarray 創建 Series 對象:')
print(series_one)
?
# 輸出:
0 ? ?小明
1 ? ?小紅
2 ? ?小紫
dtype: object2.1.1.3 字典創建 Series 對象
import pandas as pd
?
# 字典創建 Series 對象
?
data = {"name": "zhangsan", "gender": "男"}
result = pd.Series(data=data)
print('字典創建 Series 對象:')
print(result)
?
# 輸出:
name ? ? ?zhangsan
gender ? ? ? ? ? 男
dtype: object2.1.2遍歷Series
使用 items()
import pandas as pd
?
# 創建一個示例 Series
series = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
for index, value in series.items():print(f"Index: {index}, Value: {value}")#輸出:
Index: a, Value: 1
Index: b, Value: 2
Index: c, Value: 3使用 index 屬性
import pandas as pd
?
# 創建一個示例 Series
series = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
?
# 遍歷索引
for index in series.index:print(f"Index: {index}, Value: {series[index]}")#輸出:
Index: a, Value: 1
Index: b, Value: 2
Index: c, Value: 3使用 values 屬性
import pandas as pd
?
# 創建一個示例 Series
series = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
?
# 遍歷值
for value in series.values:print(f"Value: {value}")# 輸出:
Value: 1
Value: 2
Value: 32.2?DataFrame(二維表格型數據)
| 函數名 | 參數 |
|---|---|
| pd.DataFrame( data, index, columns, dtype, copy) | data:一組數據(ndarray、series, map, lists, dict 等類型) index:索引值,或者可以稱為行標簽 columns:列標簽,默認為 RangeIndex (0, 1, 2, …, n) dtype:數據類型 copy:默認為 False,表示復制數據 data |
Dataframe和Series的關系:
在 Pandas 中,DataFrame 的每一行或每一列都是一個 Series。
DataFrame 是一個二維表格,可以看作是由多個 Series 組成的。
如何區分行和列的 Series:
列的
Series:
標簽是行索引。
值是該列的所有行數據。
行的Series:
標簽是列名。
值是該行的所有列數據。
示例:
# 創建一個 DataFrame
data = {'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
}
df = pd.DataFrame(data)# 列的 Series
print(df['A']) # 標簽是行索引,值是列 A 的所有行數據
# 行的 Series
print(df.loc[0]) # 標簽是列名,值是第 0 行的所有列數據# 輸出:
0 1
1 2
2 3
Name: A, dtype: int64
A 1
B 4
C 7
Name: 0, dtype: int642.2.1 創建 DataFrame 對象
創建 DataFrame 對象的方式:
2.2.1.1 創建空對象
import pandas as pd
?
# 創建 DataFrame 空對象
def one():result = pd.DataFrame()print(result)2.2.1.2 列表嵌套字典
案例:如果其中某個元素值缺失,也就是字典的 key 無法找到對應的 value,將使用 NaN 代替。
import pandas as pd
?
# 列表嵌套字典創建 DataFrame 對象
def four():data = [{'name': "張三", 'age': 18},{'name': "小紅", 'gender': "男", 'age': 19}]result = pd.DataFrame(data=data)print(result)# 輸出:name ?age gender
0 ? 張三 ? 18 ? ?NaN
1 ? 小紅 ? 19 ? ? ?男2.2.1.3 字典嵌套列表
案例:
import pandas as pd
?
# 典創建 DataFrame 對象
def five():data = {"name":['小米','小紅','小紫'],"age":[18,19,20]}result = pd.DataFrame(data=data)print(result)2.2.1.4 使用Series
案例:對于 one 列而言,此處雖然顯示了行索引 'd',但由于沒有與其對應的值,所以它的值為 NaN。
import pandas as pd
?
# Series 創建 DataFrame 對象
def seven():data = {'one': pd.Series([1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}result = pd.DataFrame(data=data)print(result)第一列Series比第二列少一個元素,則以NaN填充,數據類型轉換為float
2.2.2 列索引操作
DataFrame 可以使用列索(columns index)引來完成數據的選取、添加和刪除操作
2.2.2.1 選取數據
import pandas as pd
?
# 選取數據
def eight():data = {'one': pd.Series([1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}result = pd.DataFrame(data=data)print(result)print(result['one'])2.2.2.2 添加數據
案例1:添加新列,直接賦值添加
data = {'one': pd.Series(data=[1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series(data=[1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
result = pd.DataFrame(data=data)
# 直接賦值添加,注意:列表長度要和Dataframe的行數一致,否則報錯
result['three'] = [1,2,3,4]
?
print(result)案例2:通過assign方法添加新列
assign 方法可以用于添加新列,并且可以鏈式調用。
data = {'one': pd.Series(data=[1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series(data=[1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
result = pd.DataFrame(data=data)
# 注意:列表長度要和Dataframe的行數一致,否則報錯
result = result.assign(three = [1,2,3,4])
?
print(result)案例3:在指定的位置插入新列
使用insert方法在指定位置插入新列,參數:
# 創建一個 DataFrame
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd'])
?
# 使用 insert 方法在位置 1 插入新列 'D'
df.insert(1, 'D', [13, 14, 15, 16])
?
print("插入新列后的 DataFrame:")
print(df)2.2.2.3 修改數據
案例1:修改列的值
import pandas as pd
?
# 修改數據
def ten():data = {'one': pd.Series(data=[1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series(data=[1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}result = pd.DataFrame(data=data)print(result)result['two'] = pd.Series(data=[1,2,3],index=['a','b','c'])print("修改數據:")print(result)案例2:基于現有列的值修改列
data = {'one': pd.Series(data=[1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series(data=[1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
result = pd.DataFrame(data=data)
# 將one列的值加100賦給two列
result['two'] = result['one'] + 100
?
print(result)案例3:修改列名
data = {'one': pd.Series(data=[1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series(data=[1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
result = pd.DataFrame(data=data)
?
result.columns = ['A','B']
?
print(result)案例4:使用 rename 方法修改列名
data = {'one': pd.Series(data=[1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series(data=[1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
result = pd.DataFrame(data=data)
?
result = result.rename(columns={'one':'A','two':'B'})
?
print(result)案例3與案例4不同:案例3直接修改dataframe的列名,案例4修改列名后生成一個副本,原dataframe不受影響
案例5:修改列的數據類型
data = {'one': pd.Series(data=[1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series(data=[1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
result = pd.DataFrame(data=data)
?
result['two'] = result['two'].astype(np.float32)
?
print(result)2.2.2.4 刪除數據
. 通過drop方法刪除 DataFrame 中的數據,默認情況下,drop() 不會修改原 DataFrame,而是返回一個新的 DataFrame。
語法:
DataFrame.drop(labels=None, axis=0, index=None, columns=None,level=None, inplace=False, errors='raise')參數:
labels:
類型:單個標簽或列表。
描述:要刪除的行或列的標簽。如果 axis=0,則 labels 表示行標簽;如果 axis=1,則 labels 表示列標簽。
axis:
類型:整數或字符串,默認為 0。
描述:指定刪除的方向。axis=0 或 axis='index' 表示刪除行,axis=1 或 axis='columns' 表示刪除列。
index:
類型:單個標簽或列表,默認為 None。
描述:要刪除的行的標簽。如果指定,則忽略 labels 參數。
columns:
類型:單個標簽或列表,默認為 None。
描述:要刪除的列的標簽。如果指定,則忽略 labels 參數。
level:
類型:整數或級別名稱,默認為 None。
描述:用于多級索引(MultiIndex),指定要刪除的級別。
inplace:
類型:布爾值,默認為 False。
描述:如果為 True,則直接修改原 DataFrame,而不是返回一個新的 DataFrame。
errors:
類型:字符串,默認為 'raise'。
描述:指定如何處理不存在的標簽。'raise' 表示拋出錯誤,'ignore' 表示忽略錯誤。
案例1:刪除列
import pandas as pd
?
result = pd.DataFrame()
result['one'] = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
result['two'] = pd.Series([5, 6, 7, 8], index=['a', 'b', 'c', 'd'])
print(result)
?
result1 = result.drop(['one'],axis=1)
print(result1)案例2:刪除行
result = pd.DataFrame()
result['one'] = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
result['two'] = pd.Series([5, 6, 7, 8], index=['a', 'b', 'c', 'd'])
print(result)
?
result1 = result.drop(['a'],axis=0)
print(result1)案例3:直接刪除原DataFrame和行或列
result = pd.DataFrame()
result['one'] = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
result['two'] = pd.Series([5, 6, 7, 8], index=['a', 'b', 'c', 'd'])
print(result)
?
result.drop(['a'], axis=0, inplace=True)
print(result)2.2.3 行索引操作
2.2.3.1 loc 選取數據
df.loc[] 只能使用標簽索引,不能使用整數索引。當通過標簽索引的切片方式來篩選數據時,它的取值前閉后閉,也就是只包括邊界值標簽(開始和結束)
loc方法返回的數據類型:
1.如果選擇單行或單列,返回的數據類型為Series
2.選擇多行或多列,返回的數據類型為DataFrame
3.選擇單個元素(某行某列對應的值),返回的數據類型為該元素的原始數據類型(如整數、浮點數等)。
語法:
DataFrame.loc[row_indexer, column_indexer]參數:
案例:
import pandas as pd
?
# 創建一個示例 DataFrame
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd'])
?
# 使用 loc 選擇數據
print(df.loc['a']) ?# 選擇行標簽為 'a' 的行
print(df.loc['a':'c']) ?# 選擇行標簽從 'a' 到 'c' 的行
print(df.loc['a', 'B']) ?# 選擇行標簽為 'a',列標簽為 'B' 的元素
print(df.loc[['a', 'c'], ['A', 'C']]) ?# 選擇行標簽為 'a' 和 'c',列標簽為 'A' 和 'C' 的數據2.2.3.2 iloc 選取數據
iloc 方法用于基于位置(integer-location based)的索引,即通過行和列的整數位置來選擇數據。
語法:
DataFrame.iloc[row_indexer, column_indexer]參數:
ignore_index: 如果為 True,則忽略原始索引并生成新的索引。
keys: 用于在連接結果中創建層次化索引。
levels: 指定層次化索引的級別。
names: 指定層次化索引的名稱。
verify_integrity: 如果為 True,則在連接時檢查是否有重復索引。
sort: 如果為 True,則在連接時對列進行排序。
copy: 如果為 True,則復制數據。
案例1:按行連接(垂直堆疊)
# 創建兩個示例 DataFrame
df1 = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6]
})
?
df2 = pd.DataFrame({'A': [7, 8, 9],'B': [10, 11, 12]
})
?
# 按行連接 df1 和 df2
result = pd.concat([df1, df2], axis=0)
?
print(result)案例2:按列連接(水平堆疊)
# 創建兩個示例 DataFrame
df1 = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6]
})
?
df2 = pd.DataFrame({'C': [7, 8, 9],'D': [10, 11, 12]
})
?
# 按列連接 df1 和 df2
result = pd.concat([df1, df2], axis=1)
?
print(result)案例3:使用 ignore_index
# 創建兩個示例 DataFrame
df1 = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6]
})
?
df2 = pd.DataFrame({'A': [7, 8, 9],'B': [10, 11, 12]
})
?
# 按行連接 df1 和 df2,并忽略原始索引
result = pd.concat([df1, df2], axis=0, ignore_index=True)
?
print(result)案例4:使用 join='inner',按行合并
# 創建兩個示例 DataFrame
df1 = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6]
}, index=[0, 1, 2])
?
df2 = pd.DataFrame({'A': [7, 8, 9],'B': [10, 11, 12],'D': [13, 14, 15]
}, index=[1, 2, 3])
?
# 按行合并,只匹配column相同的列,行被堆疊
result = pd.concat([df1, df2], axis=0, join='inner')
print(result)
# 按列合并,只匹配index相同的行,列被堆疊
result = pd.concat([df1, df2], axis=1, join='inner')
print(result)案例5:Dataframe和Series連接
# 創建一個示例 DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6]
})
?
# 創建一個示例 Series
series = pd.Series([7, 8, 9], name='C')
?
# 按行連接 DataFrame 和 Series
result_row = pd.concat([df, series], axis=0)
?
# 按列連接 DataFrame 和 Series
result_col = pd.concat([df, series], axis=1)
?
print("按行連接結果:")
print(result_row)
print("\n按列連接結果:")
print(result_col)案例:
import pandas as pd
?
# 創建一個示例 DataFrame
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd'])
?
# 使用 iloc 選擇數據
print(df.iloc[0]) ?# 選擇第 0 行的數據
print(df.iloc[0:2]) ?# 選擇第 0 到 1 行的數據
print(df.iloc[0, 1]) ?# 選擇第 0 行,第 1 列的元素
print(df.iloc[[0, 2], [0, 2]]) ?# 選擇第 0 和 2 行,第 0 和 2 列的數據2.2.3.3 切片多行選取
通過切片的方式進行多行數據的選取
案例:
import pandas as pd
?
# 創建一個示例 DataFrame
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd'])
?
# 使用 df[0:2] 選擇前兩行
result = df[0:2]
print(type(result)) ?# 輸出: <class 'pandas.core.frame.DataFrame'>
print(result)切片獲取行和通過iloc方法獲取行從結果上沒有區別,切片是基于位置的切片操作,iloc是基于位置的索引操作。
2.2.3.4 添加數據行
loc方法添加新行
# 創建一個 DataFrame
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd'])
?
# 添加新行 'e'
df.loc['e'] = [17, 18, 19, 20]
?
print("添加新行后的 DataFrame:")
print(df)concat拼接
語法:
pd.concat(objs, axis=0, join='outer', ignore_index=False,keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=True)參數:
objs: 要連接的 DataFrame 或 Series 對象的列表或字典。
axis: 指定連接的軸,0 或 'index' 表示按行連接,1 或 'columns' 表示按列連接。
join: 指定連接方式,'outer' 表示并集(默認),'inner' 表示交集。
2.2.3.5 刪除數據行
參考2.2.2.4 刪除數據
3.函數
3.1 常用的統計學函數
| 函數名稱 | 描述說明 |
|---|---|
| count() | 統計某個非空值的數量 |
| sum() | 求和 |
| mean() | 求均值 |
| median() | 求中位數 |
| std() | 求標準差 |
| min() | 求最小值 |
| max() | 求最大值 |
| abs() | 求絕對值 |
| prod() | 求所有數值的乘積 |
案例:
# 創建一個示例 DataFrame
data = {'A': [1, 2, 3, 4, 5],'B': [10, 20, 30, 40, 50],'C': [100, 200, 300, 400, 500]
}
df = pd.DataFrame(data)
?
# 計算每列的均值
mean_values = df.mean()
print(mean_values)
?
# 計算每列的中位數
median_values = df.median()
print(median_values)
?
#計算每列的方差
var_values = df.var()
print(var_values)
?
# 計算每列的標準差
std_values = df.std()
print(std_values)
?
# 計算每列的最小值
min_values = df.min()
print("最小值:")
print(min_values)
?
# 計算每列的最大值
max_values = df.max()
print("最大值:")
print(max_values)
?
# 計算每列的總和
sum_values = df.sum()
print(sum_values)
?
# 計算每列的非空值數量
count_values = df.count()
print(count_values)注意:numpy的方差默認為總體方差,pandas默認為樣本方差
總體方差:
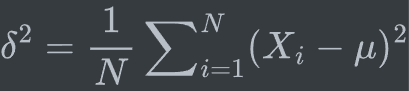
樣本方差:
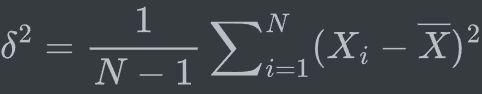
分母為n-1的樣本方差的期望等于總體的方差,因此樣本方差是總體方差的無偏估計。
3.2 重置索引
重置索引(reindex)可以更改原 DataFrame 的行標簽或列標簽,并使更改后的行、列標簽與 DataFrame 中的數據逐一匹配。通過重置索引操作,您可以完成對現有數據的重新排序。如果重置的索引標簽在原 DataFrame 中不存在,那么該標簽對應的元素值將全部填充為 NaN。
reindex
reindex() 方法用于重新索引 DataFrame 或 Series 對象。重新索引意味著根據新的索引標簽重新排列數據,并填充缺失值。如果重置的索引標簽在原 DataFrame 中不存在,那么該標簽對應的元素值將全部填充為 NaN。
語法:
DataFrame.reindex(labels=None, index=None, columns=None,
axis=None, method=None, copy=True, level=None,fill_value=np.nan, limit=None, tolerance=None)參數:
labels:
類型:數組或列表,默認為 None。
描述:新的索引標簽。
index:
類型:數組或列表,默認為 None。
描述:新的行索引標簽。
columns:
類型:數組或列表,默認為 None。
描述:新的列索引標簽。
axis:
類型:整數或字符串,默認為 None。
描述:指定重新索引的軸。0 或 'index' 表示行,1 或 'columns' 表示列。
method:
類型:字符串,默認為 None。
描述:用于填充缺失值的方法。可選值包括 'ffill'(前向填充)、'bfill'(后向填充)等。
copy:
類型:布爾值,默認為 True。
描述:是否返回新的 DataFrame 或 Series。
level:
類型:整數或級別名稱,默認為 None。
描述:用于多級索引(MultiIndex),指定要重新索引的級別。
fill_value:
類型:標量,默認為 np.nan。
描述:用于填充缺失值的值。
limit:
類型:整數,默認為 None。
描述:指定連續填充的最大數量。
tolerance:
類型:標量或字典,默認為 None。
描述:指定重新索引時的容差。
案例:
# 創建一個示例 DataFrame
data = {'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
?
# 重新索引行
new_index = ['a', 'b', 'c', 'd']
df_reindexed = df.reindex(new_index)
print(df_reindexed)
?
# 重新索引列
new_columns = ['A', 'B', 'C', 'D']
df_reindexed = df.reindex(columns=new_columns)
print(df_reindexed)
?
# 重新索引行,并使用前向填充
# 新的行索引 ['a', 'b', 'c', 'd'] 包含了原索引中不存在的標簽 'd',使用 method='ffill' 進行前向填充,因此 'd' 對應的行填充了前一行的值。
new_index = ['a', 'b', 'c', 'd']
df_reindexed = df.reindex(new_index, method='ffill')
print(df_reindexed)
?
# 重新索引行,并使用指定的值填充缺失值
new_index = ['a', 'b', 'c', 'd']
df_reindexed = df.reindex(new_index, fill_value=0)
print(df_reindexed)3.3 遍歷
DataFrame 這種二維數據表結構,遍歷會獲取列標簽
案例:
import pandas as pd
?
series_data = pd.Series(['a','b','c','d','e','f',None])
?
print('Series:')
for item in series_data:print(item, end=' ')#輸出:
a b c d e f None 3.3.1 DataFrame 遍歷
dataFrame_data = pd.DataFrame({'one': pd.Series([1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
})
# 遍歷dataframe得到的是列標簽
print('DataFrame:')
for item in dataFrame_data:print(item, end=' ')
?
#輸出:
one two 遍歷行
itertuples() 方法用于遍歷 DataFrame 的行,返回一個包含行數據的命名元組。
案例:
import pandas as pd
?
# 創建一個示例 DataFrame
data = {'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
?
# 使用 itertuples() 遍歷行
for row in df.itertuples():print(row)for i in row:print(i)
#輸出:
Pandas(Index='a', A=1, B=4, C=7)
a
1
4
7
Pandas(Index='b', A=2, B=5, C=8)
b
2
5
8
Pandas(Index='c', A=3, B=6, C=9)
c
3
6
9
# 忽略索引
for row in df.itertuples(index=False):print(row)for i in row:print(i)itertuples() 是遍歷 DataFrame 的推薦方法,因為它在速度和內存使用上都更高效。
遍歷列
items() 方法用于遍歷 DataFrame 的列,返回一個包含列名和列數據的迭代器。
案例:
import pandas as pd
?
# 創建一個示例 DataFrame
data = {'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
?
# 使用 items() 遍歷列
for column_name, column_data in df.items():print(f"Column Name: {column_name}, Column Data: {column_data}")
#輸出:
Column Name: A, Column Data: a ? ?1
b ? ?2
c ? ?3
Name: A, dtype: int64
Column Name: B, Column Data: a ? ?4
b ? ?5
c ? ?6
Name: B, dtype: int64
Column Name: C, Column Data: a ? ?7
b ? ?8
c ? ?9
Name: C, dtype: int64使用屬性遍歷
loc 和 iloc 方法可以用于按索引或位置遍歷 DataFrame 的行和列。
import pandas as pd
?
# 創建一個示例 DataFrame
data = {'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
?
# 使用 loc 遍歷行和列
for index in df.index:for column in df.columns:print(f"Index: {index}, Column: {column}, Value: {df.loc[index, column]}")# 輸出:
Index: a, Column: A, Value: 1
Index: a, Column: B, Value: 4
Index: a, Column: C, Value: 7
Index: b, Column: A, Value: 2
Index: b, Column: B, Value: 5
Index: b, Column: C, Value: 8
Index: c, Column: A, Value: 3
Index: c, Column: B, Value: 6
Index: c, Column: C, Value: 93.4 排序
3.4.1 sort_values
sort_values 方法用于根據一個或多個列的值對 DataFrame 進行排序。
語法:
DataFrame.sort_values(by, axis=0, ascending=True,inplace=False, kind='quicksort', na_position='last')參數:
by:列的標簽或列的標簽列表。指定要排序的列。
axis:指定沿著哪個軸排序。默認為 0,表示按行排序。如果設置為 1,將按列排序。
ascending:布爾值或布爾值列表,指定是升序排序(True)還是降序排序(False)。可以為每個列指定不同的排序方向。
inplace:布爾值,指定是否在原地修改數據。如果為 True,則會修改原始數據;如果為 False,則返回一個新的排序后的對象。
kind:排序算法。默認為 'quicksort',也可以選擇 'mergesort'(歸并排序) 或 'heapsort'(堆排序)。
na_position:指定缺失值(NaN)的位置。可以是 'first' 或 'last'。
案例:
import pandas as pd
?
# 創建一個示例 DataFrame
data = {'A': [3, 2, 1],'B': [6, 5, 4],'C': [9, 8, 7]
}
df = pd.DataFrame(data, index=['b', 'c', 'a'])
?
# 按列 'A' 排序
df_sorted = df.sort_values(by='A')
print(df_sorted)
?
# 按列 'A' 和 'B' 排序
df_sorted = df.sort_values(by=['A', 'B'])
print(df_sorted)
?
# 按列 'A' 降序排序
df_sorted = df.sort_values(by='A', ascending=False)
print(df_sorted)
?
# 按列 'A' 和 'B' 排序,先按A列降序排序,如果A列中值相同則按B列升序排序
df = pd.DataFrame({'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],'Age': [25, 30, 25, 35, 30],'Score': [85, 90, 80, 95, 88]
})
df_sorted = df.sort_values(by=['Age', 'Score'], ascending=[False, True])
print(df_sorted)3.5 去重
drop_duplicates 方法用于刪除 DataFrame 或 Series 中的重復行或元素。
語法:
drop_duplicates(by=None, subset=None, keep='first', inplace=False)
Series.drop_duplicates(keep='first', inplace=False)參數:
by:用于標識重復項的列名或列名列表。如果未指定,則使用所有列。
subset:與 by 類似,但用于指定列的子集。
keep:指定如何處理重復項。可以是:
'first':保留第一個出現的重復項(默認值)。
'last':保留最后一個出現的重復項。
False:刪除所有重復項。
inplace:布爾值,指定是否在原地修改數據。如果為 True,則會修改原始數據;如果為 False,則返回一個新的刪除重復項后的對象。
案例:
import pandas as pd
?
# 創建一個示例 DataFrame
data = {'A': [1, 2, 2, 3],'B': [4, 5, 5, 6],'C': [7, 8, 8, 9]
}
df = pd.DataFrame(data)
?
# 刪除所有列的重復行,默認保留第一個出現的重復項
df_unique = df.drop_duplicates()
print(df_unique)
?
# 刪除重復行,保留最后一個出現的重復項
df_unique = df.drop_duplicates(keep='last')
print(df_unique)3.6 分組
groupby 方法用于對數據進行分組操作,這是數據分析中非常常見的一個步驟。通過 groupby,你可以將數據集按照某個列(或多個列)的值分組,然后對每個組應用聚合函數,比如求和、平均值、最大值等。
語法:
DataFrame.groupby(by, axis=0, level=None, as_index=True,
sort=True, group_keys=True, squeeze=False, observed=False, **kwargs)參數:
by:用于分組的列名或列名列表。
axis:指定沿著哪個軸進行分組。默認為 0,表示按行分組。
level:用于分組的 MultiIndex 的級別。
as_index:布爾值,指定分組后索引是否保留。如果為 True,則分組列將成為結果的索引;如果為 False,則返回一個列包含分組信息的 DataFrame。
sort:布爾值,指定在分組操作中是否對數據進行排序。默認為 True。
group_keys:布爾值,指定是否在結果中添加組鍵。
squeeze:布爾值,如果為 True,并且分組結果返回一個元素,則返回該元素而不是單列 DataFrame。
observed:布爾值,如果為 True,則只考慮數據中出現的標簽。
import pandas as pd
?
# 創建一個示例 DataFramedata = {'A': ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],'C': [1, 2, 3, 4, 5, 6, 7, 8],'D': [10, 20, 30, 40, 50, 60, 70, 80]}df = pd.DataFrame(data)
?# 按列 'A' 分組grouped = df.groupby('A')
?# 查看分組結果for name, group in grouped:print(f"Group: {name}")print(group)print()
?mean = df.groupby(['A']).mean()print(mean)#輸出:C ? ? DA ? ? ? ? ? ? bar ?4.0 ?40.0foo ?4.8 ?48.0mean = grouped['C'].mean()print(mean)#輸出:Abar ? ?4.0foo ? ?4.8# 在分組內根據C列求平均值# transform用于在分組操作中對每個組內的數據進行轉換,并將結果合并回原始 DataFrame。mean = grouped['C'].transform(lambda x: x.mean())df['C_mean'] = meanprint(df)#輸出:A ? ? ?B ?C ? D ?C_mean0 ?foo ? ?one ?1 ?10 ? ? 4.81 ?bar ? ?one ?2 ?20 ? ? 4.02 ?foo ? ?two ?3 ?30 ? ? 4.83 ?bar ?three ?4 ?40 ? ? 4.04 ?foo ? ?two ?5 ?50 ? ? 4.85 ?bar ? ?two ?6 ?60 ? ? 4.06 ?foo ? ?one ?7 ?70 ? ? 4.87 ?foo ?three ?8 ?80 ? ? 4.8
?
?# 在分組內根據C列求標準差std = grouped['C'].transform(np.std)df['C_std'] = stdprint(df)
?# 在分組內根據C列進行正太分布標準化norm = grouped['C'].transform(lambda x: (x - x.mean()) / x.std())df['C_normal'] = normprint(df)3.7 合并
merge 函數用于將兩個 DataFrame 對象根據一個或多個鍵進行合并,類似于 SQL 中的 JOIN 操作。這個方法非常適合用來基于某些共同字段將不同數據源的數據組合在一起,最后拼接成一個新的 DataFrame 數據表。
函數:
pandas.merge(left, right, how='inner', on=None,left_on=None, right_on=None, left_index=False, right_index=False,
sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)參數:
left:左側的 DataFrame 對象。
right:右側的 DataFrame 對象。
how:合并方式,可以是 'inner'、'outer'、'left' 或 'right'。默認為 'inner'。
'inner':內連接,返回兩個 DataFrame 共有的鍵。
'outer':外連接,返回兩個 DataFrame 的所有鍵。
'left':左連接,返回左側 DataFrame 的所有鍵,以及右側 DataFrame 匹配的鍵。
'right':右連接,返回右側 DataFrame 的所有鍵,以及左側 DataFrame 匹配的鍵。
on:用于連接的列名。如果未指定,則使用兩個 DataFrame 中相同的列名。
left_on 和 right_on:分別指定左側和右側 DataFrame 的連接列名。
left_index 和 right_index:布爾值,指定是否使用索引作為連接鍵。
sort:布爾值,指定是否在合并后對結果進行排序。
suffixes:一個元組,指定當列名沖突時,右側和左側 DataFrame 的后綴。
copy:布爾值,指定是否返回一個新的 DataFrame。如果為 False,則可能修改原始 DataFrame。
indicator:布爾值,如果為 True,則在結果中添加一個名為 __merge 的列,指示每行是如何合并的。
validate:驗證合并是否符合特定的模式。
案例1:內連接
import pandas as pd
?
# 創建兩個示例 DataFrame
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']
})
?
right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K4'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']
})
?
# 內連接
result = pd.merge(left, right, on='key')
?
print(result)
?
#輸出:K3、K4被忽略key ? A ? B ? C ? D
0 ?K0 ?A0 ?B0 ?C0 ?D0
1 ?K1 ?A1 ?B1 ?C1 ?D1
2 ?K2 ?A2 ?B2 ?C2 ?D2案例2:左連接
import pandas as pd
?
# 創建兩個示例 DataFrame
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']
})
?
right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K4'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']
})
?
# 左連接,以左側表為準
result = pd.merge(left, right, on='key', how='left')
?
print(result)
# 輸出:key ? A ? B ? ?C ? ?D
0 ?K0 ?A0 ?B0 ? C0 ? D0
1 ?K1 ?A1 ?B1 ? C1 ? D1
2 ?K2 ?A2 ?B2 ? C2 ? D2
3 ?K3 ?A3 ?B3 ?NaN ?NaN3.8 空值處理
3.8.1 檢測空值
isnull()用于檢測 DataFrame 或 Series 中的空值,返回一個布爾值的 DataFrame 或 Series。
notnull()用于檢測 DataFrame 或 Series 中的非空值,返回一個布爾值的 DataFrame 或 Series。
案例1:
import pandas as pd
import numpy as np
?
# 創建一個包含空值的示例 DataFrame
data = {'A': [1, 2, np.nan, 4],'B': [5, np.nan, np.nan, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)
?
# 檢測空值
is_null = df.isnull()
print(is_null)
?
# 檢測非空值
not_null = df.notnull()
print(not_null)案例2:
import pandas as pd
?
'''isnull() 和 nonull() 用于檢測 Series 中的缺失值isnull():如果為值不存在或者缺失,則返回 Truenotnull():如果值不存在或者缺失,則返回 False
'''
def eight():result = pd.Series(['a','b','c','d','e','f',None])print("isnull()如果為值不存在或者缺失,則返回 True:")print(result.isnull())print("notnull()如果值不存在或者缺失,則返回 False:")print(result.notnull())#過濾掉缺失值print(result[result.notnull()])輸出:
isnull()如果為值不存在或者缺失,則返回 True:
0 ? False
1 ? False
2 ? False
3 ? False
4 ? False
5 ? False
6 ? ? True
dtype: bool
notnull()如果值不存在或者缺失,則返回 False:
0 ? ? True
1 ? ? True
2 ? ? True
3 ? ? True
4 ? ? True
5 ? ? True
6 ? False
dtype: bool
0 ? a
1 ? b
2 ? c
3 ? d
4 ? e
5 ? f
dtype: object3.8.2 填充空值
fillna() 方法用于填充 DataFrame 或 Series 中的空值。
案例:
# 創建一個包含空值的示例 DataFrame
data = {'A': [1, 2, np.nan, 4],'B': [5, np.nan, np.nan, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)
?
# 用 0 填充空值
df_filled = df.fillna(0)
?
print(df_filled)3.8.3 刪除空值
dropna() 方法用于刪除 DataFrame 或 Series 中的空值。
案例:
# 創建一個包含空值的示例 DataFrame
data = {'A': [1, 2, np.nan, 4],'B': [5, np.nan, np.nan, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)
?
# 刪除包含空值的行
df_dropped = df.dropna()
print(df_dropped)
#輸出:A ? ?B ? C
0 ?1.0 ?5.0 ? 9
3 ?4.0 ?8.0 ?12
?
# 刪除包含空值的列
df_dropped = df.dropna(axis=1)
print(df_dropped)
#輸出:C
0 ? 9
1 ?10
2 ?11
3 ?124. 讀取CSV文件
CSV(Comma-Separated Values,逗號分隔值,有時也稱為字符分隔值,因為分隔字符也可以不是逗號),其文件以純文本形式存儲表格數據(數字和文本);
CSV 是一種通用的、相對簡單的文件格式,被用戶、商業和科學廣泛應用。
4.1 to_csv()
to_csv() 方法將 DataFrame 存儲為 csv 文件
案例:
import pandas as pd
?
# 創建一個簡單的 DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'City': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
?
# 將 DataFrame 導出為 CSV 文件
df.to_csv('output.csv', index=False)4.2 read_csv()
read_csv() 表示從 CSV 文件中讀取數據,并創建 DataFrame 對象。
案例:
import pandas as pd
?
df = pd.read_csv('output.csv')
print(df)5.Pandas繪圖基礎
Pandas 在數據分析、數據可視化方面有著較為廣泛的應用,Pandas 對 Matplotlib 繪圖軟件包的基礎上單獨封裝了一個plot()接口,通過調用該接口可以實現常用的繪圖操作;
Pandas 之所以能夠實現了數據可視化,主要利用了 Matplotlib 庫的 plot() 方法,它對 plot() 方法做了簡單的封裝,因此您可以直接調用該接口;
只用 pandas 繪制圖片可能可以編譯,但是不會顯示圖片,需要使用 matplotlib 庫,調用 show() 方法顯示圖形。
5.1?折線圖(默認)
import pandas as pd
import matplotlib.pyplot as pltdf = pd.DataFrame({ 'Year': [2020, 2021, 2022],
'Sales': [200, 250, 300] })
df.plot(x='Year', y='Sales', kind='line')5.2?柱狀圖
import pandas as pd
import matplotlib.pyplot as pltdf.plot(kind='bar', x='Year', y='Sales')5.3?直方圖(hist)
import pandas as pd
import matplotlib.pyplot as pltdf['Sales'].plot(kind='hist', bins=5)5.4?餅圖(pie)
import pandas as pd
import matplotlib.pyplot as pltdf = pd.DataFrame({ 'Product': ['A', 'B', 'C'],
'Sales': [100, 200, 150] })
df.set_index('Product').plot(kind='pie', y='Sales', autopct='%1.1f%%')注意: 繪圖前建議加上
import matplotlib.pyplot as plt和plt.show()以保證圖形顯示(特別是非 Jupyter 環境):
三、Matplotlib
1.概念
Matplotlib 庫:是一款用于數據可視化的 Python 軟件包,支持跨平臺運行,它能夠根據 NumPy ndarray 數組來繪制 2D 圖像,它使用簡單、代碼清晰易懂
Matplotlib 圖形組成:
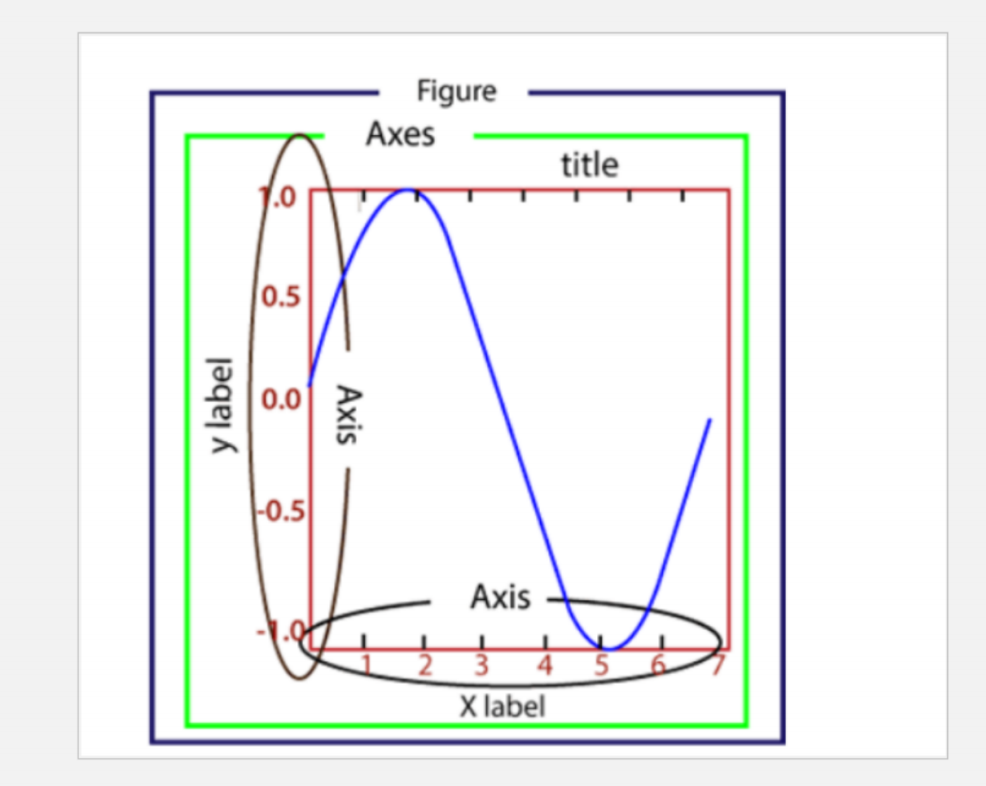
-
Figure:指整個圖形,您可以把它理解成一張畫布,它包括了所有的元素,比如標題、軸線等
-
Axes:繪制 2D 圖像的實際區域,也稱為軸域區,或者繪圖區
-
Axis:指坐標系中的垂直軸與水平軸,包含軸的長度大小(圖中軸長為 7)、軸標簽(指 x 軸,y軸)和刻度標簽
-
Artist:您在畫布上看到的所有元素都屬于 Artist 對象,比如文本對象(title、xlabel、ylabel)、Line2D 對象(用于繪制2D圖像)等
-
Matplotlib 功能擴展包:許多第三方工具包都對 Matplotlib 進行了功能擴展,其中有些安裝包需要單獨安裝,也有一些允許與 Matplotlib 一起安裝。常見的工具包如下:
-
Basemap:這是一個地圖繪制工具包,其中包含多個地圖投影,海岸線和國界線
-
Cartopy:這是一個映射庫,包含面向對象的映射投影定義,以及任意點、線、面的圖像轉換能力
-
Excel tools: 這是 Matplotlib 為了實現與 Microsoft Excel 交換數據而提供的工具
-
Mplot3d:它用于 3D 繪圖
-
Natgrid:這是 Natgrid 庫的接口,用于對間隔數據進行不規則的網格化處理
-
2.安裝
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple/3.應用場景
數據可視化主要有以下應用場景:
企業領域:利用直觀多樣的圖表展示數據,從而為企業決策提供支持
股票走勢預測:通過對股票漲跌數據的分析,給股民提供更合理化的建議
商超產品銷售:對客戶群體和所購買產品進行數據分析,促使商超制定更好的銷售策略
預測銷量:對產品銷量的影響因素進行分析,可以預測出產品的銷量走勢
4.常用API
4.1 繪圖類型
| 函數名稱 | 描述 |
|---|---|
| Bar | 繪制條形圖 |
| Barh | 繪制水平條形圖 |
| Boxplot | 繪制箱型圖 |
| Hist | 繪制直方圖 |
| his2d | 繪制2D直方圖 |
| Pie | 繪制餅狀圖 |
| Plot | 在坐標軸上畫線或者標記 |
| Polar | 繪制極坐標圖 |
| Scatter | 繪制x與y的散點圖 |
| Stackplot | 繪制堆疊圖 |
| Stem | 用來繪制二維離散數據繪制(又稱為火柴圖) |
| Step | 繪制階梯圖 |
| Quiver | 繪制一個二維按箭頭 |
4.2 Image 函數
| 函數名稱 | 描述 |
|---|---|
| Imread | 從文件中讀取圖像的數據并形成數組 |
| Imsave | 將數組另存為圖像文件 |
| Imshow | 在數軸區域內顯示圖像 |
4.3 Axis 函數
| 函數名稱 | 描述 |
|---|---|
| Axes | 在畫布(Figure)中添加軸 |
| Text | 向軸添加文本 |
| Title | 設置當前軸的標題 |
| Xlabel | 設置x軸標簽 |
| Xlim | 獲取或者設置x軸區間大小 |
| Xscale | 設置x軸縮放比例 |
| Xticks | 獲取或設置x軸刻標和相應標簽 |
| Ylabel | 設置y軸的標簽 |
| Ylim | 獲取或設置y軸的區間大小 |
| Yscale | 設置y軸的縮放比例 |
| Yticks | 獲取或設置y軸的刻標和相應標簽 |
4.4 Figure 函數
| 函數名稱 | 描述 |
|---|---|
| Figtext | 在畫布上添加文本 |
| Figure | 創建一個新畫布 |
| Show | 顯示數字 |
| Savefig | 保存當前畫布 |
| Close | 關閉畫布窗口 |
5.pylab 模塊
PyLab 是一個面向 Matplotlib 的繪圖庫接口,其語法和 MATLAB 十分相近。
pylab 是 matplotlib 中的一個模塊,它將 matplotlib.pyplot 和 numpy 的功能組合在一起,使得你可以直接使用 numpy 的函數和 matplotlib.pyplot 的繪圖功能,而不需要顯式地導入 numpy 和 matplotlib.pyplot。
優點
方便快捷:pylab 的設計初衷是為了方便快速繪圖和數值計算,使得你可以直接使用 numpy 的函數和 matplotlib.pyplot 的繪圖功能,而不需要顯式地導入 numpy 和 matplotlib.pyplot。
簡化代碼:使用 pylab 可以減少導入語句的數量,使代碼更簡潔。
缺點
命名空間污染:pylab 將 numpy 和 matplotlib.pyplot 的功能組合在一起,可能會導致命名空間污染,使得代碼的可讀性和可維護性降低。
不適合大型項目:對于大型項目或需要精細控制的項目,pylab 可能不夠靈活。
pyplot 是 matplotlib 中的一個模塊,提供了類似于 MATLAB 的繪圖接口。它是一個更底層的接口,提供了更多的控制和靈活性。
使用 pyplot 需要顯式地導入 numpy 和 matplotlib.pyplot,代碼量相對較多。例如:
import matplotlib.pyplot as plt
import numpy as np6.常用函數
6.1 plot 函數
pylab.plot 是一個用于繪制二維圖形的函數。它可以根據提供的 x 和 y 數據點繪制線條和/或標記。
語法:
pylab.plot(x, y, format_string=None, **kwargs)參數:
x: x 軸數據,可以是一個數組或列表。
y: y 軸數據,可以是一個數組或列表。
format_string: 格式字符串,用于指定線條樣式、顏色等。
**kwargs: 其他關鍵字參數,用于指定線條的屬性。
plot 函數可以接受一個或兩個數組作為參數,分別代表 x 和 y 坐標。如果你只提供一個數組,它將默認用作 y 坐標,而 x 坐標將默認為數組的索引。
格式字符串:
格式字符串由顏色、標記和線條樣式組成。例如:
顏色:
'b':藍色 'g':綠色 'r':紅色 'c':青色 'm':洋紅色 'y':黃色 'k':黑色 'w':白色
標記:
'.':點標記
',':像素標記
'o':圓圈標記
'v':向下三角標記
'^':向上三角標記
'<':向左三角標記
'>':向右三角標記
's':方形標記
'p':五邊形標記
'*':星形標記
'h':六邊形標記1
'H':六邊形標記2
'+':加號標記
'x':叉號標記
'D':菱形標記
'd':細菱形標記
'|':豎線標記
'_':橫線標記
線條樣式:
'-':實線 '--':虛線 '-.':點劃線 ':':點線
案例:
# 導入 pylab 庫
import pylab
?
# 創建數據,使用 linspace 函數
# pylab.linspace 函數生成一個等差數列。這個函數返回一個數組,數組中的數值在指定的區間內均勻分布。
x = pylab.linspace(-6, 6, 40)
# 基于 x 構建 y 的數據
y = x**2
# 繪制圖形
pylab.plot(x,y,'r:')
# 展示圖形
pylab.show()警告日志關閉
import logging
logging.captureWarnings(True)6.2 figure 函數
figure() 函數來實例化 figure 對象,即繪制圖形的對象,可以通過這個對象,來設置圖形的樣式等
參數:
figsize:指定畫布的大小,(寬度,高度),單位為英寸
dpi:指定繪圖對象的分辨率,即每英寸多少個像素,默認值為80
facecolor:背景顏色
dgecolor:邊框顏色
frameon:是否顯示邊框
6.2.1 figure.add_axes()
Matplotlib 定義了一個 axes 類(軸域類),該類的對象被稱為 axes 對象(即軸域對象),它指定了一個有數值范圍限制的繪圖區域。在一個給定的畫布(figure)中可以包含多個 axes 對象,但是同一個 axes 對象只能在一個畫布中使用。
參數:
是一個包含四個元素的列表或元組,格式為 [left, bottom, width, height],其中:
left 和 bottom 是軸域左下角的坐標,范圍從 0 到 1。
width 和 height 是軸域的寬度和高度,范圍從 0 到 1。
案例:
# 創建一個新的圖形
fig = pl.figure()
?
# 添加第一個軸域
ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
x = pl.linspace(0, 10, 100)
y = pl.sin(x)
ax.plot(x, y)
?
# 顯示圖形
pl.show()6.2.2 axes.legend()
legend 函數用于添加圖例,以便識別圖中的不同數據系列。圖例會自動顯示每條線或數據集的標簽。
參數:
labels 是一個字符串序列,用來指定標簽的名稱
loc 是指定圖例位置的參數,其參數值可以用字符串或整數來表示
handles 參數,它也是一個序列,它包含了所有線型的實例
案例:
x = pl.linspace(0, 10, 100)
y1 = pl.sin(x)
y2 = pl.cos(x)
?
# 創建圖形和軸域
fig, ax = pl.subplots()
?
# 繪制數據
line1 = ax.plot(x, y1)
line2 = ax.plot(x, y2)
?
# 添加圖例,手動指定標簽
ax.legend(handles=[line1, line2], labels=['Sine Function', 'Cosine Function'],loc='center')
# 顯示圖形
pl.show()
也可以將label定義在plot方法中,調用legend方法時不用再定義labels,會自動添加labelx = pl.linspace(0, 10, 100)
y1 = pl.sin(x)
y2 = pl.cos(x)
?
# 創建圖形和軸域
fig, ax = pl.subplots()
?
# 繪制數據
line1, = ax.plot(x, y1, label='Sine Function')
line2, = ax.plot(x, y2, label='Cosine Function')
?
# 添加圖例,手動指定標簽
ax.legend(handles=[line1, line2], loc='center')
?
# 顯示圖形
pl.show()legend() 函數 loc 參數:
| 位置 | 字符串表示 | 整數數字表示 |
|---|---|---|
| 自適應 | best | 0 |
| 右上方 | upper right | 1 |
| 左上方 | upper left | 2 |
| 左下 | lower left | 3 |
| 右下 | lower right | 4 |
| 右側 | right | 5 |
| 居中靠左 | center left | 6 |
| 居中靠右 | center right | 7 |
| 底部居中 | lower center | 8 |
| 上部居中 | upper center | 9 |
| 中部 | center | 10 |
6.3 標題中文亂碼
如果標題設置的是中文,會出現亂碼
局部處理:
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False全局處理:
首先,找到 matplotlibrc 文件的位置,可以使用以下代碼:
import matplotlib
print(matplotlib.matplotlib_fname())然后,修改 matplotlibrc 文件,找到 font.family 和 font.sans-serif 項,設置為支持中文的字體,如 SimHei。
同時,設置 axes.unicode_minus 為 False 以正常顯示負號。
修改完成后,重啟pyCharm。如果不能解決,嘗試運行以下代碼來實現:
from matplotlib.font_manager import _rebuild
_rebuild()6.4 subplot 函數
subplot 是一個較早的函數,用于創建并返回一個子圖對象。它的使用比較簡單,通常用于創建網格狀的子圖布局。subplot 的參數通常是一個三位數的整數,其中每個數字代表子圖的行數、列數和子圖的索引。
add_subplot 是一個更靈活的函數,它是 Figure類的一個方法,用于向圖形容器中添加子圖。推薦使用 add_subplot,因為它提供了更好的靈活性和控制。
語法:
fig.add_subplot(nrows, ncols, index)案例:
import matplotlib.pyplot as plt
import numpy as np
?
# 創建數據
x = np.linspace(0, 10, 100)
y1 = np.sin(x)
y2 = np.cos(x)
y3 = np.tan(x)
?
# 創建圖形,figsize=(寬度, 高度),單位是英寸,圖形寬度為 12 英寸,高度為 4 英寸
fig = plt.figure(figsize=(12, 4))
?
# 第一個子圖
ax1 = fig.add_subplot(1, 3, 1)
ax1.plot(x, y1, label='sin(x)')
ax1.set_title('Sine Wave')
ax1.set_xlabel('X-axis')
ax1.set_ylabel('Y-axis')
ax1.legend()
?
# 第二個子圖
ax2 = fig.add_subplot(1, 3, 2)
ax2.plot(x, y2, label='cos(x)')
ax2.set_title('Cosine Wave')
ax2.set_xlabel('X-axis')
ax2.set_ylabel('Y-axis')
ax2.legend()
?
# 第三個子圖
ax3 = fig.add_subplot(1, 3, 3)
ax3.plot(x, y3, label='tan(x)')
ax3.set_title('Tangent Wave')
ax3.set_xlabel('X-axis')
ax3.set_ylabel('Y-axis')
ax3.legend()
?
# 顯示圖形
plt.tight_layout()
plt.show()6.5 subplots 函數
subplots 是 matplotlib.pyplot 模塊中的一個函數,用于創建一個包含多個子圖(subplots)的圖形窗口。subplots 函數返回一個包含所有子圖的數組,這使得你可以更方便地對每個子圖進行操作。
語法:
fig, axs = plt.subplots(nrows, ncols, figsize=(width, height))參數:
nrows: 子圖的行數。
ncols: 子圖的列數。
figsize: 圖形的尺寸,以英寸為單位。
案例:
import matplotlib.pyplot as plt
import numpy as np
?
# 創建數據
x = np.linspace(0, 10, 100)
y1 = np.sin(x)
y2 = np.cos(x)
y3 = np.tan(x)
?
# 創建圖形和子圖
fig, axs = plt.subplots(1, 3, figsize=(12, 4))
?
# 第一個子圖
axs[0].plot(x, y1, label='sin(x)')
axs[0].set_title('Sine Wave')
axs[0].set_xlabel('X-axis')
axs[0].set_ylabel('Y-axis')
axs[0].legend()
?
# 第二個子圖
axs[1].plot(x, y2, label='cos(x)')
axs[1].set_title('Cosine Wave')
axs[1].set_xlabel('X-axis')
axs[1].set_ylabel('Y-axis')
axs[1].legend()
?
# 第三個子圖
axs[2].plot(x, y3, label='tan(x)')
axs[2].set_title('Tangent Wave')
axs[2].set_xlabel('X-axis')
axs[2].set_ylabel('Y-axis')
axs[2].legend()
?
# 顯示圖形
plt.tight_layout()
plt.show()7.繪制圖表
7.1 柱狀圖
柱狀圖(Bar Chart)是一種常用的數據可視化工具,用于展示分類數據的分布情況。
語法:
ax.bar(x, height, width=0.8, bottom=None, align='center', **kwargs)參數:
x: 柱狀圖的 X 軸位置。
height: 柱狀圖的高度。
width: 柱狀圖的寬度,默認為 0.8。
bottom: 柱狀圖的底部位置,默認為 0。
align: 柱狀圖的對齊方式,可以是 'center'(居中對齊)或 'edge'(邊緣對齊)。
**kwargs: 其他可選參數,用于定制柱狀圖的外觀,如 color、edgecolor、linewidth 等。
案例1:
from matplotlib import pyplot as plt
import numpy as np
?
?
# 數據
categories = ['A', 'B', 'C', 'D']
values = [20, 35, 30, 25]
?
# 創建圖形和子圖
fig, ax = plt.subplots()
?
# 繪制柱狀圖
ax.bar(categories, values, color='skyblue', linewidth=1.5, width=0.6)
?
# 設置標題和標簽
ax.set_title('Customized Bar Chart')
ax.set_xlabel('Categories')
ax.set_ylabel('Values')
?
# 顯示圖形
plt.show()案例2:堆疊柱狀圖
# 數據
categories = ['A', 'B', 'C', 'D']
values1 = [20, 35, 30, 25]
values2 = [15, 25, 20, 10]
?
# 創建圖形和子圖
fig, ax = plt.subplots()
?
# 繪制第一個數據集的柱狀圖
ax.bar(categories, values1, color='skyblue', label='Values 1')
?
# 繪制第二個數據集的柱狀圖,堆疊在第一個數據集上
ax.bar(categories, values2, bottom=values1, color='lightgreen', label='Values 2')
?
# 設置標題和標簽
ax.set_title('Stacked Bar Chart')
ax.set_xlabel('Categories')
ax.set_ylabel('Values')
?
# 添加圖例
ax.legend()
?
# 顯示圖形
plt.show()說明:
bottom=values1:繪制第二個數據集的柱狀圖,堆疊在第一個數據集上
案例3:分組柱狀圖
# 數據
categories = ['A', 'B', 'C', 'D']
values1 = [20, 35, 30, 25]
values2 = [15, 25, 20, 10]
?
# 創建圖形和子圖
fig, ax = plt.subplots()
?
# 計算柱狀圖的位置
x = np.arange(len(categories))
width = 0.35
?
# 繪制第一個數據集的柱狀圖
ax.bar(x - width/2, values1, width, color='skyblue', label='Values 1')
?
# 繪制第二個數據集的柱狀圖
ax.bar(x + width/2, values2, width, color='lightgreen', label='Values 2')
?
# 設置 X 軸標簽
ax.set_xticks(x)
ax.set_xticklabels(categories)
?
# 設置標題和標簽
ax.set_title('Grouped Bar Chart')
ax.set_xlabel('Categories')
ax.set_ylabel('Values')
?
# 添加圖例
ax.legend()
?
# 顯示圖形
plt.show()7.2 直方圖
直方圖(Histogram)是一種常用的數據可視化工具,用于展示數值數據的分布情況。
語法:
ax.hist(x, bins=None, range=None, density=False,
weights=None, cumulative=False, **kwargs)參數:
x: 數據數組。
bins: 直方圖的柱數,可以是整數或序列。
range: 直方圖的范圍,格式為 (min, max)。
density: 是否將直方圖歸一化,默認為 False。
weights: 每個數據點的權重。
cumulative: 是否繪制累積直方圖,默認為 False。
**kwargs: 其他可選參數,用于定制直方圖的外觀,如 color、edgecolor、linewidth 等。
案例:
from matplotlib import pyplot as plt
import numpy as np
?
# 生成隨機數據,生成均值為 0,標準差為 1 的標準正態分布的隨機樣本
data = np.random.randn(1000)
?
# 創建圖形和子圖
fig, ax = plt.subplots()
?
# 繪制直方圖
ax.hist(data, bins=30, color='skyblue', edgecolor='black')
?
# 設置標題和標簽
ax.set_title('Simple Histogram')
ax.set_xlabel('Value')
ax.set_ylabel('Frequency')
?
# 顯示圖形
plt.show()7.3 餅圖
餅圖(Pie Chart)是一種常用的數據可視化工具,用于展示分類數據的占比情況。
語法:
ax.pie(x, explode=None, labels=None, colors=None, autopct=None,
shadow=False, startangle=0, **kwargs)參數:
x: 數據數組,表示每個扇區的占比。
explode: 一個數組,表示每個扇區偏離圓心的距離,默認為 None。
labels: 每個扇區的標簽,默認為 None。
colors: 每個扇區的顏色,默認為 None。
autopct: 控制顯示每個扇區的占比,可以是格式化字符串或函數,默認為 None。
shadow: 是否顯示陰影,默認為 False。
startangle: 餅圖的起始角度,默認為 0。
**kwargs: 其他可選參數,用于定制餅圖的外觀。
案例:
from matplotlib import pyplot as plt
import numpy as np
?
# 數據
labels = ['A', 'B', 'C', 'D']
sizes = [15, 30, 45, 10]
?
# 創建圖形和子圖
fig, ax = plt.subplots()
?
# 繪制餅圖
ax.pie(sizes, labels=labels, autopct='%1.1f%%', startangle=90)
?
# 設置標題
ax.set_title('Simple Pie Chart')
?
# 顯示圖形
plt.show()7.4 折線圖
使用 plot 函數
案例:
from matplotlib import pyplot as plt
?
# 創建數據
x = np.linspace(0, 10, 100)
y1 = np.sin(x)
y2 = np.cos(x)
?
# 創建圖形和子圖
fig, ax = plt.subplots()
?
# 繪制多條折線圖
ax.plot(x, y1, label='sin(x)', color='blue')
ax.plot(x, y2, label='cos(x)', color='red')
?
# 設置標題和標簽
ax.set_title('Multiple Line Charts')
ax.set_xlabel('X-axis')
ax.set_ylabel('Y-axis')
?
# 添加圖例
ax.legend()
?
# 顯示圖形
plt.show()7.5 散點圖
散點圖(Scatter Plot)是一種常用的數據可視化工具,用于展示兩個變量之間的關系。
語法:
ax.scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None,
vmin=None, vmax=None, alpha=None, linewidths=None, edgecolors=None, **kwargs)參數:
x: X 軸數據。
y: Y 軸數據。
s: 點的大小,可以是標量或數組。
c: 點的顏色,可以是標量、數組或顏色列表。
marker: 點的形狀,默認為 'o'(圓圈)。
cmap: 顏色映射,用于將顏色映射到數據。
norm: 歸一化對象,用于將數據映射到顏色映射。
vmin, vmax: 顏色映射的最小值和最大值。
alpha: 點的透明度,取值范圍為 0 到 1。
linewidths: 點的邊框寬度。
edgecolors: 點的邊框顏色。
**kwargs: 其他可選參數,用于定制散點圖的外觀。
案例:
from matplotlib import pyplot as plt
?
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
fig = plt.figure()
axes = fig.add_axes([.1,.1,.8,.8])
x = ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']
data = [[120, 132, 101, 134, 90, 230, 210],[220, 182, 191, 234, 290, 330, 310],
]
y0 = data[0]
y1 = data[1]
axes.scatter(x,y0,color='red')
axes.scatter(x,y1,color='blue')
axes.set_title('散點圖')
axes.set_xlabel('日期')
axes.set_ylabel('數量')
plt.legend(labels=['Email', 'Union Ads'],)
plt.show()marker常用的參數值:
'o': 圓圈
's': 正方形
'D': 菱形
'^': 上三角形
'v': 下三角形
'>': 右三角形
'<': 左三角形
'p': 五邊形
'*': 星形
'+': 加號
'x': 叉號
'.': 點
',': 像素
'1': 三叉戟下
'2': 三叉戟上
'3': 三叉戟左
'4': 三叉戟右
'h': 六邊形1
'H': 六邊形2
'd': 小菱形
'|': 豎線
'_': 橫線
7.6 圖片讀取
plt.imread 是 Matplotlib 庫中的一個函數,用于讀取圖像文件并將其轉換為 NumPy 數組。這個函數非常方便,可以輕松地將圖像加載到 Python 中進行處理或顯示。
參數
fname: 圖像文件的路徑(字符串)。
format: 圖像格式(可選)。如果未指定,imread會根據文件擴展名自動推斷格式。返回值
返回一個 NumPy 數組,表示圖像的像素數據。數組的形狀取決于圖像的格式:
對于灰度圖像,返回一個二維數組
(height, width)。對于彩色圖像,返回一個三維數組
(height, width, channels),其中channels通常是 3(RGB)或 4(RGBA)。
案例:
from matplotlib import pyplot as plt
import numpy as np
import os
?
?
def read_img():dirpath = os.path.dirname(__file__)print(dirpath)
?filepath = os.path.relpath(os.path.join(dirpath, 'leaf.png'))print(filepath)
?img = plt.imread(filepath)print(img.shape)plt.imshow(img)plt.show()
?img1 = np.transpose(img, (2, 0, 1))for channel in img1:plt.imshow(channel)plt.show()
?
?
if __name__ == '__main__':read_img()四、常見的鏡像源網站?
1.pip 常用鏡像源網址
| 鏡像源 | 鏡像地址 URL | 說明 |
|---|---|---|
| 清華大學 | https://pypi.tuna.tsinghua.edu.cn/simple | ?穩定、推薦使用 |
| 阿里云 | https://mirrors.aliyun.com/pypi/simple/ | |
| 中國科技大學 | https://pypi.mirrors.ustc.edu.cn/simple/ | |
| 華中理工大學 | https://pypi.hustunique.com/simple/ | 偶爾維護 |
| 豆瓣(douban) | https://pypi.douban.com/simple/ | 曾一度關閉,謹慎使用 |
2.conda 常用鏡像源網址(Anaconda)
| 鏡像源 | 鏡像配置命令 |
|---|---|
| 清華大學 | https://mirrors.tuna.tsinghua.edu.cn/anaconda/ |
| 中科大 | https://mirrors.ustc.edu.cn/anaconda/ |
| 阿里云 | https://mirrors.aliyun.com/anaconda/ |



)




網絡層 路由協議)
Pytorch中求逆torch.inverse和解線性方程組torch.linalg.solve有什么關系)



)

圖片比對)



