文章目錄
- 介紹
- 數據操作
- 張量
- 張量的定義
- 1. **張量的維度(Rank)**
- 2. **張量的形狀(Shape)**
- 簡單的數據預處理(插值
- 線性代數
- 微積分
- 概率論
- 1. 基本概念
- (1) 隨機試驗與事件
- (2) 概率公理(Kolmogorov公理)
- 2. 概率公式
- (1) 條件概率
- (2) 全概率公式
- (3) 貝葉斯定理
- 3. 隨機變量與分布
- (1) 隨機變量類型
- (2) 常見分布
- (3) 期望與方差
- 4. 極限定理
- (1) 大數定律
- (2) 中心極限定理(CLT)
- 5. 聯合分布與獨立性
- (1) 聯合概率
- (2) 獨立性
- (3) 協方差與相關系數
課程學習自李牧老師B站的視頻和網站文檔
https://zh-v2.d2l.ai/chapter_preliminaries
介紹
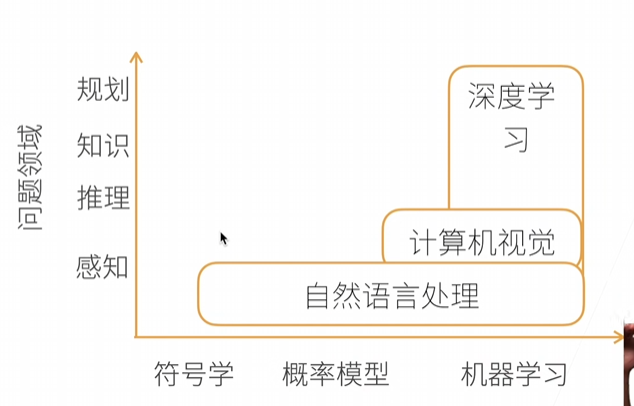
深度學習是機器學習的一種,可以做計算機視覺,可以做自然語言處理
- 在圖片分類出現了較大的突破
- 可以物體檢測和分割
- 可以樣式遷移(類似換背景
- 可以人臉合成(隨機生成的
- 可以文字生成圖片
- 文字生成模型(AI大模型
數據操作
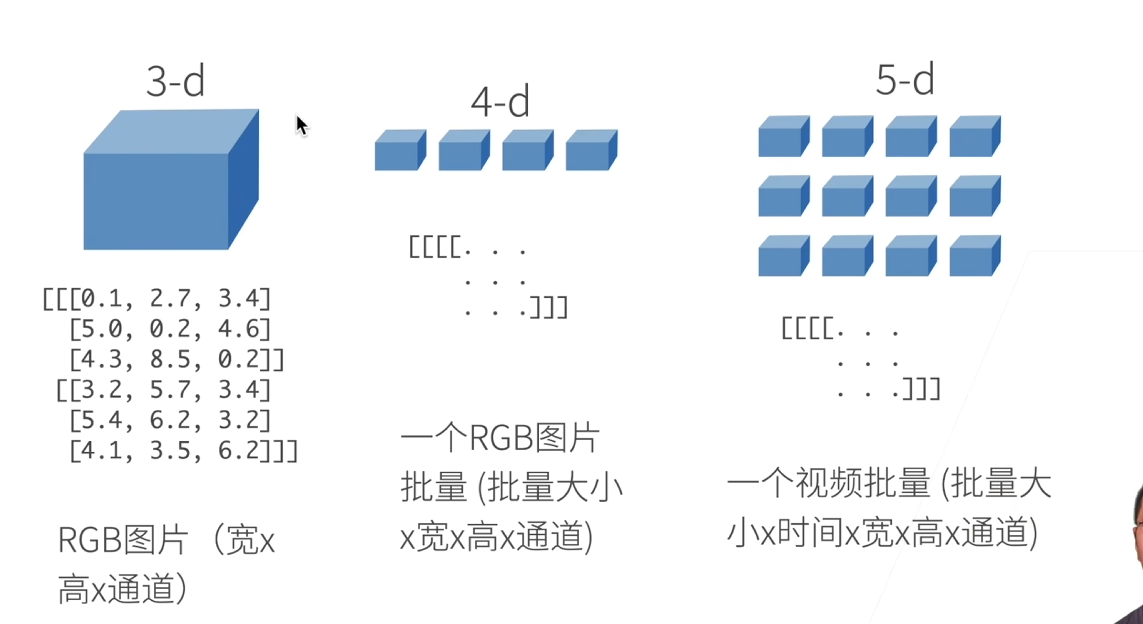
N維數組時機器學習和神經網絡的主要數據結構
- 0-d:標量(1.0這樣的一個類別
- 1-d:向量(【1.0,2.7,3.4】這樣的一個特征向量
- 2-d:矩陣(一個樣本,也就是特征矩陣
訪問元素:
- 【1:】把第一行拿出來
- 【::3】每三行一跳
張量
張量的定義
- 標量:0維張量,例如一個數字(如 5)。
- 向量:1維張量,例如 [1, 2, 3]。
- 矩陣:2維張量,例如 [[1, 2], [3, 4]]。
- 高維張量:3維或更高,例如表示圖像的張量(寬×高×通道)。
1. 張量的維度(Rank)
- 維度指的是張量的軸(axes)數量,表示張量是幾維的。
- 例如:
- 0維:標量(如 5),無軸。
- 1維:向量(如 [1, 2, 3]),1個軸。
- 2維:矩陣(如 [[1, 2], [3, 4]]),2個軸。
- 3維及以上:高維張量(如 [[[1, 2], [3, 4]], [[5, 6], [7, 8]]]),3個軸或更多。
- 維度也叫階(rank),例如2維張量的階是2。
2. 張量的形狀(Shape)
-
形狀是一個元組,描述張量在每個軸上的元素數量。
-
例如:
- 標量:形狀是 ()(空元組)。
- 向量 [1, 2, 3]:形狀是 (3,),表示1個軸有3個元素。
- 矩陣 [[1, 2], [3, 4]]:形狀是 (2, 2),表示2行2列。
- 3維張量 [[[1, 2], [3, 4]], [[5, 6], [7, 8]]]:形狀是 (2, 2, 2),表示2個矩陣,每個矩陣2行2列。
import torch# 標量(0維) scalar = torch.tensor(5) print(scalar.shape) # 輸出:torch.Size([])# 向量(1維) vector = torch.tensor([1, 2, 3]) print(vector.shape) # 輸出:torch.Size([3])# 矩陣(2維) matrix = torch.tensor([[1, 2], [3, 4]]) print(matrix.shape) # 輸出:torch.Size([2, 2])# 3維張量 tensor_3d = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]]) print(tensor_3d.shape) # 輸出:torch.Size([2, 2, 2])x.reshape函數只改變張量的形狀
tensor.zeros創建全0的張量
cat函數將張量連結在一起

x.sum()函數求和
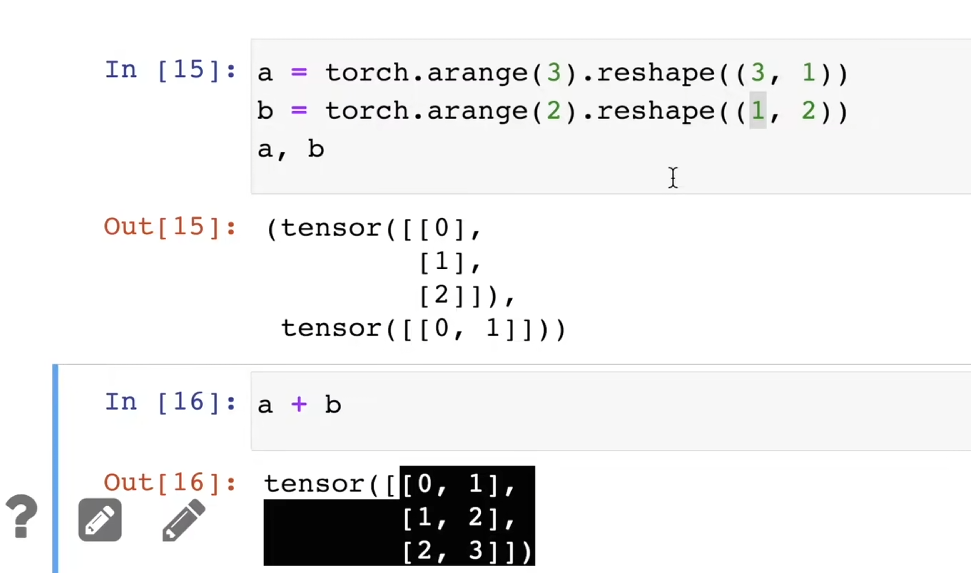
兩個張量維度一樣,但形狀不一樣,可以通過廣播機制執行(每個張量自動復制自己比另一個張量低的形狀
python用id標識元素地址,類似指針,在pytorch中有一些原地操作的函數
原地操作直接修改張量的值,而不是返回一個新張量。
在 PyTorch 中,原地操作通常以方法名后加下劃線 _ 標記,例如 .add_()、.mul_()。
轉換為numpy張量
A = X.numpy()
B = torch.tensor(A)
type(A), type(B)
(numpy.ndarray, torch.Tensor)
簡單的數據預處理(插值
假設我們有這樣的一個csv文件
import pandas as pddata = pd.read_csv(data_file)
print(data)NumRooms Alley Price
0 NaN Pave 127500
1 2.0 NaN 106000
2 4.0 NaN 178100
3 NaN NaN 140000
這里我們使用插值的方式處理,假設price可能缺失,我們就把它單獨分出來作為output,其他作為input
input中如果是數值類,則將NaN替換為其他數的平均值
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean())
print(inputs)NumRooms Alley
0 3.0 Pave
1 2.0 NaN
2 4.0 NaN
3 3.0 NaN
如果是字符類,我們采用數字01來代替存在
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)NumRooms Alley_Pave Alley_nan
0 3.0 1 0
1 2.0 0 1
2 4.0 0 1
3 3.0 0 1
線性代數
一些基本的概念



對某一維求和,其實就是沿著選擇的方向做一個壓縮
保持維度:用 keepdim=True 保留求和后的維度,便于后續操作


微積分
在深度學習中,我們“訓練”模型,不斷更新它們,使它們在看到越來越多的數據時變得越來越好。 通常情況下,變得更好意味著最小化一個損失函數(loss function), 即一個衡量“模型有多糟糕”這個問題的分數。 最終,我們真正關心的是生成一個模型,它能夠在從未見過的數據上表現良好。 但“訓練”模型只能將模型與我們實際能看到的數據相擬合。 因此,我們可以將擬合模型的任務分解為兩個關鍵問題:
- 優化(optimization):用模型擬合觀測數據的過程;
- 泛化(generalization):數學原理和實踐者的智慧,能夠指導我們生成出有效性超出用于訓練的數據集本身的模型。

偏導數:假如y有多個變量x1,x2,x3等,對其中一個變量求導,其余變量視為常數
梯度:對每個變量求偏導數,結果合成一個向量


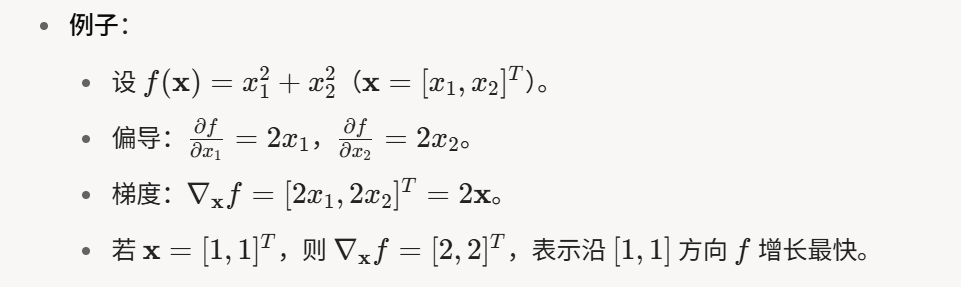
fx是一個輸入x1和x2這兩個向量得到一個標量(固定結果,可能數數字)的標量函數,而x可能是向量,求標量函數關于向量的梯度,其實就是說求fx這函數的每個x的偏導數
鏈式法則求導


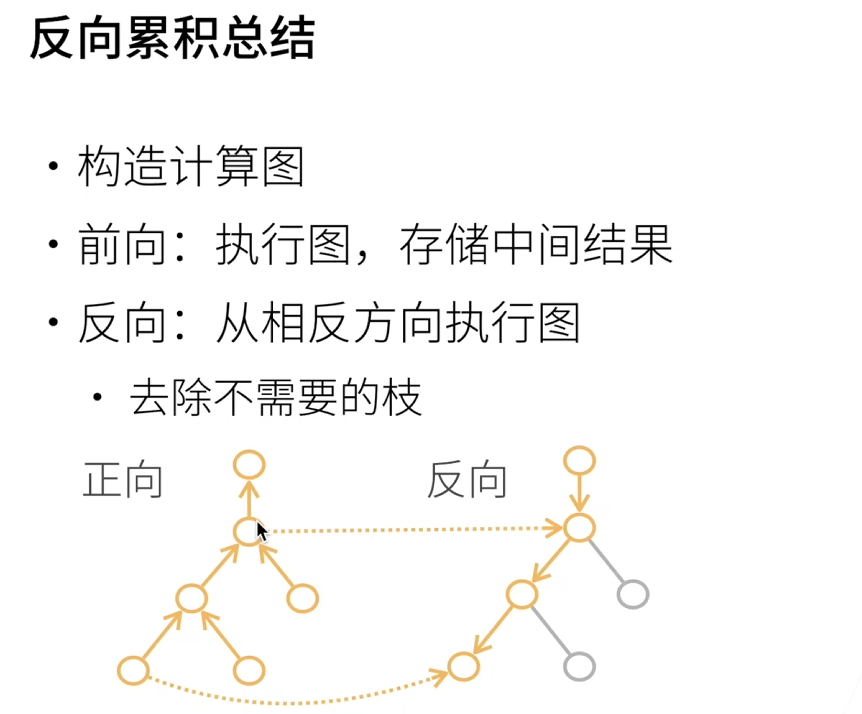
反向需要把正向存儲的中間結果拿過來用
非標量反向傳播依賴自動微分工具(如 PyTorch 的 .backward()),手動推導需注意維度匹配。
梯度累積可能需要清零(如 optimizer.zero_grad())。
計算圖的概念:

分離計算:假如我們希望將y視為一個常數,可以引入變量u
x.grad.zero_()
y = x * x
u = y.detach()
z = u * xz.sum().backward()
x.grad == u
由于記錄了y的計算結果,我們可以隨后在y上調用反向傳播, 得到y=x*x關于的x的導數,即2*x
x.grad.zero_()
y.sum().backward()
x.grad == 2 * x
使用自動微分的一個好處是: 即使構建函數的計算圖需要通過Python控制流(例如,條件、循環或任意函數調用),我們仍然可以計算得到的變量的梯度。 在下面的代碼中,while循環的迭代次數和if語句的結果都取決于輸入a的值。
def f(a):b = a * 2while b.norm() < 1000:b = b * 2if b.sum() > 0:c = belse:c = 100 * breturn c
a = torch.randn(size=(), requires_grad=True)
d = f(a)
d.backward()
概率論
1. 基本概念
(1) 隨機試驗與事件
- 樣本空間:Ω={所有可能結果}\Omega = \{\text{所有可能結果}\}Ω={所有可能結果}
例:擲骰子的樣本空間 Ω={1,2,3,4,5,6}\Omega = \{1, 2, 3, 4, 5, 6\}Ω={1,2,3,4,5,6}。 - 事件:A?ΩA \subseteq \OmegaA?Ω,如“擲出偶數”對應 A={2,4,6}A = \{2, 4, 6\}A={2,4,6}。
(2) 概率公理(Kolmogorov公理)
對任意事件 AAA:
- 非負性:P(A)≥0P(A) \geq 0P(A)≥0
- 規范性:P(Ω)=1P(\Omega) = 1P(Ω)=1
- 可列可加性:若 A1,A2,…A_1, A_2, \dotsA1?,A2?,… 互斥,則 P(?iAi)=∑iP(Ai)P\left(\bigcup_{i} A_i\right) = \sum_i P(A_i)P(?i?Ai?)=∑i?P(Ai?)。
2. 概率公式
(1) 條件概率
P(A∣B)=P(A∩B)P(B)(P(B)>0)P(A \mid B) = \frac{P(A \cap B)}{P(B)} \quad (P(B) > 0) P(A∣B)=P(B)P(A∩B)?(P(B)>0)
(2) 全概率公式
若 B1,B2,…,BnB_1, B_2, \dots, B_nB1?,B2?,…,Bn? 是 Ω\OmegaΩ 的劃分:
P(A)=∑i=1nP(A∣Bi)P(Bi)P(A) = \sum_{i=1}^n P(A \mid B_i) P(B_i) P(A)=i=1∑n?P(A∣Bi?)P(Bi?)
(3) 貝葉斯定理
P(Bi∣A)=P(A∣Bi)P(Bi)∑jP(A∣Bj)P(Bj)P(B_i \mid A) = \frac{P(A \mid B_i) P(B_i)}{\sum_j P(A \mid B_j) P(B_j)} P(Bi?∣A)=∑j?P(A∣Bj?)P(Bj?)P(A∣Bi?)P(Bi?)?
3. 隨機變量與分布
(1) 隨機變量類型
- 離散型:X∈{x1,x2,…}X \in \{x_1, x_2, \dots\}X∈{x1?,x2?,…}
- 連續型:X∈RX \in \mathbb{R}X∈R,概率密度函數 f(x)f(x)f(x) 滿足 P(a≤X≤b)=∫abf(x)dxP(a \leq X \leq b) = \int_a^b f(x) dxP(a≤X≤b)=∫ab?f(x)dx。
(2) 常見分布
| 分布名稱 | 概率質量/密度函數 | 參數 |
|---|---|---|
| 伯努利分布 | P(X=k)=pk(1?p)1?kP(X=k) = p^k (1-p)^{1-k}P(X=k)=pk(1?p)1?k | k∈{0,1}k \in \{0,1\}k∈{0,1} |
| 二項分布 | P(X=k)=(nk)pk(1?p)n?kP(X=k) = \binom{n}{k} p^k (1-p)^{n-k}P(X=k)=(kn?)pk(1?p)n?k | k≤nk \leq nk≤n |
| 泊松分布 | P(X=k)=λke?λk!P(X=k) = \frac{\lambda^k e^{-\lambda}}{k!}P(X=k)=k!λke?λ? | λ>0\lambda > 0λ>0 |
| 正態分布 | f(x)=1σ2πe?(x?μ)22σ2f(x) = \frac{1}{\sigma\sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}f(x)=σ2π?1?e?2σ2(x?μ)2? | μ,σ\mu, \sigmaμ,σ |
(3) 期望與方差
- 期望:E[X]=∑xP(x)\mathbb{E}[X] = \sum x P(x)E[X]=∑xP(x) 或 ∫xf(x)dx\int x f(x) dx∫xf(x)dx
- 方差:Var(X)=E[(X?E[X])2]\text{Var}(X) = \mathbb{E}[(X - \mathbb{E}[X])^2]Var(X)=E[(X?E[X])2]
4. 極限定理
(1) 大數定律
1n∑i=1nXi→PE[X]當?n→∞\frac{1}{n} \sum_{i=1}^n X_i \overset{P}{\to} \mathbb{E}[X] \quad \text{當} \ n \to \infty n1?i=1∑n?Xi?→PE[X]當?n→∞
(2) 中心極限定理(CLT)
∑i=1nXi?nμσn→dN(0,1)\frac{\sum_{i=1}^n X_i - n\mu}{\sigma \sqrt{n}} \overset{d}{\to} N(0, 1) σn?∑i=1n?Xi??nμ?→dN(0,1)
5. 聯合分布與獨立性
(1) 聯合概率
- 離散型:P(X=x,Y=y)P(X=x, Y=y)P(X=x,Y=y)
- 連續型:fX,Y(x,y)f_{X,Y}(x,y)fX,Y?(x,y)
(2) 獨立性
XXX 與 YYY 獨立 ?\iff? P(X,Y)=P(X)P(Y)P(X,Y) = P(X)P(Y)P(X,Y)=P(X)P(Y) 或 fX,Y(x,y)=fX(x)fY(y)f_{X,Y}(x,y) = f_X(x) f_Y(y)fX,Y?(x,y)=fX?(x)fY?(y)。
(3) 協方差與相關系數
- 協方差:Cov(X,Y)=E[(X?E[X])(Y?E[Y])]\text{Cov}(X,Y) = \mathbb{E}[(X-\mathbb{E}[X])(Y-\mathbb{E}[Y])]Cov(X,Y)=E[(X?E[X])(Y?E[Y])]
- 相關系數:ρX,Y=Cov(X,Y)σXσY∈[?1,1]\rho_{X,Y} = \frac{\text{Cov}(X,Y)}{\sigma_X \sigma_Y} \in [-1, 1]ρX,Y?=σX?σY?Cov(X,Y)?∈[?1,1]


 視頻教程 - 用戶登錄實現)


: Word 基本操作)






)


)
- 數據結構】數組和特殊矩陣)


