溫馨提示:
本篇文章已同步至"AI專題精講" KOSMOS-2: 將多模態大型語言模型與世界對接
摘要
我們介紹了 KOSMOS-2,一種多模態大型語言模型(MLLM),賦予了模型感知物體描述(例如,邊界框)并將文本與視覺世界對接的新能力。具體而言,我們將引用表達式表示為 Markdown 中的鏈接形式,即 “文本片段”,其中物體描述是位置標記的序列。通過與多模態語料庫的結合,我們構建了大規模的圖像-文本對(稱為 GRIT)數據,用于訓練模型。除了現有的 MLLM 能力(例如,感知一般模態、遵循指令和執行上下文學習)外,KOSMOS-2 將對接能力集成到下游應用中。我們在廣泛的任務上評估了 KOSMOS-2,包括:(i)多模態對接,例如引用表達式理解和短語對接;(ii)多模態引用,例如引用表達式生成;(iii)感知-語言任務;以及(iv)語言理解與生成。本研究為人體化 AI 的發展奠定了基礎,并揭示了語言、多模態感知、行動和世界建模之間的大融合,這是邁向人工通用智能的關鍵步驟。代碼和預訓練模型可在 https://aka.ms/kosmos-2 獲取。


1 引言
多模態大型語言模型(MLLMs)[HSD+22, ADL+22, HDW+23, DXS+23, Ope23] 在廣泛的任務中成功地作為通用接口發揮了作用,包括語言、視覺和視覺-語言任務。MLLMs 可以感知一般模態,包括文本、圖像和音頻,并在zero-shot 和few-shot 設置下生成自由形式的文本響應。
在本工作中,我們解鎖了多模態大型語言模型的對接能力。對接能力為視覺-語言任務提供了更便捷和高效的人機交互。它使用戶能夠直接指向圖像中的物體或區域,而不是輸入詳細的文本描述來引用該物體,模型可以理解該圖像區域及其空間位置。對接能力還使得模型能夠以視覺答案(即邊界框)作出響應,這支持更多的視覺-語言任務,如引用表達式理解。與僅使用文本的響應相比,視覺答案更準確,解決了共指歧義問題。此外,對接能力能夠將生成的自由形式文本響應中的名詞短語和引用表達式與圖像區域相鏈接,從而提供更準確、更有信息性和更全面的答案。
我們介紹了 KOSMOS-2,這是一個具有對接能力的多模態大型語言模型,建立在 KOSMOS-1 基礎上。KOSMOS-2 是一個基于 Transformer 的因果語言模型,使用下一個單詞預測任務進行訓練。為了啟用對接能力,我們構建了一個大規模的圖像-文本對數據集,并將其與 KOSMOS-1 中的多模態語料庫結合,用于訓練模型。這個對接的圖像-文本對是基于 LAION-2B [SBV+22] 和 COYO-700M [BPK+22] 的圖像-文本對子集構建的。我們構建了一個管道,提取并將文本片段(即名詞短語和引用表達式)與其對應的圖像區域的空間位置(例如,邊界框)相鏈接。我們將邊界框的空間坐標轉換為一系列位置標記,然后將其附加到相應的文本片段后面。數據格式充當“超鏈接”,將圖像的物體或區域與標題連接起來。
實驗結果表明,KOSMOS-2 不僅在 KOSMOS-1 中評估的語言和視覺-語言任務上取得了競爭力的表現,而且在對接任務(短語對接和引用表達式理解)以及引用任務(引用表達式生成)上也取得了顯著的成績。如圖 2 所示,集成對接能力使得 KOSMOS-2 可以用于更多的下游任務,如對接圖像字幕和對接視覺問答。
2 構建大規模對接圖像-文本對(GRIT)
我們介紹了 GRIT2,這是一個大規模的對接圖像-文本對數據集,基于 COYO-700M [BPK+22] 和 LAION-2B [SBV+22] 的圖像-文本對子集構建。我們構建了一個管道,將文本片段(即名詞短語和引用表達式)與其對應的圖像區域鏈接。該管道主要由兩個步驟組成:生成名詞短語-邊界框對和生成引用表達式-邊界框對。我們在下面詳細描述這些步驟:
步驟 1:生成名詞短語-邊界框對
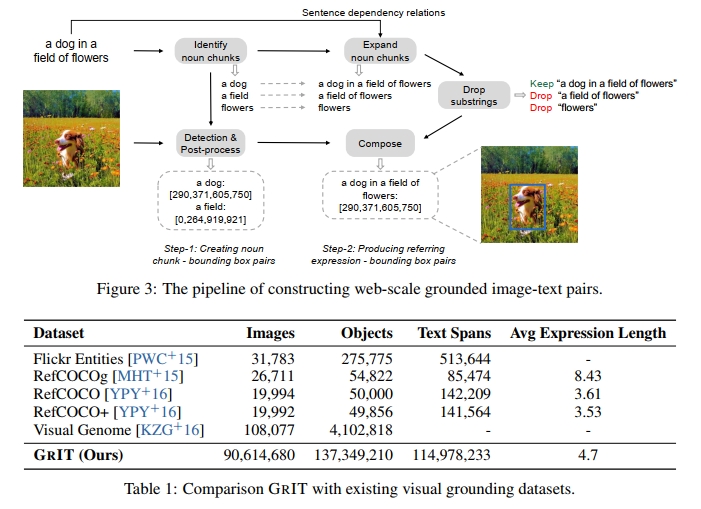
給定一個圖像-文本對,我們首先從標題中提取名詞短語,并使用預訓練的檢測器將它們與圖像區域關聯。如圖 3 所示,我們使用 spaCy [HMVLB20] 來解析標題(“a dog in a field of flowers”),并提取所有名詞短語(“a dog”,“a field”和“flowers”)。我們排除一些難以在圖像中識別的抽象名詞短語,如“time”,“love”和“freedom”,以減少潛在的噪聲。隨后,我們將圖像和從標題中提取的名詞短語輸入到預訓練的對接模型(例如 GLIP [LZZ+22])中,以獲得相應的邊界框。應用非極大抑制算法,以去除與其他邊界框有較高重疊的邊界框,即使它們并不是針對同一名詞短語。我們保留預測置信度高于 0.65 的名詞短語-邊界框對。如果沒有保留任何邊界框,我們將丟棄相應的圖像-標題對。
步驟 2:生成引用表達式-邊界框對
為了賦予模型對復雜語言描述的對接能力,我們將名詞短語擴展為引用表達式。具體來說,我們使用 spaCy 獲取句子的依賴關系。然后,我們通過遞歸遍歷名詞短語在依賴樹中的子節點,并將子節點的標記與名詞短語連接,來擴展名詞短語為引用表達式。我們不會將名詞短語擴展為并列成分。如果名詞短語沒有子節點,我們會將其保留供下一個過程使用。圖 3 中顯示的例子中,名詞短語 “a dog” 可以擴展為 “a dog in a field of flowers”,而名詞短語 “a field” 可以擴展為 “a field of flowers”。
此外,我們只保留不被其他表達包含的引用表達式或名詞短語。如圖 3 所示,我們保留引用表達式 “a dog in a field of flowers”,并刪除 “a field of flowers”(因為它是 “a dog in a field of flowers” 的蘊含),以及 “flowers”。我們將名詞短語 (“a dog”) 的邊界框分配給相應生成的引用表達式 (“a dog in a field of flowers”)。
最終,我們獲得了大約 9100 萬張圖像、1.15 億個文本片段和 1.37 億個關聯的邊界框。我們將 GRIT 與現有公開可用的視覺對接數據集進行了比較,結果見表 1。GRIT 的數據樣本顯示在附錄中。
3 KOSMOS-2: 一個具有關聯的多模態大語言模型
KOSMOS-2 是一個具有關聯能力的多模態大語言模型,相較于 KOSMOS-1,它集成了關聯和引用能力。該模型可以接受用戶通過邊界框選擇的圖像區域作為輸入,提供視覺答案(即邊界框),并將文本輸出與視覺世界進行對接。KOSMOS-2 采用與 KOSMOS-1 相同的模型架構和訓練目標。我們將關聯的圖像-文本對加入訓練數據,以賦予模型關聯和引用能力。對于一個文本片段(例如名詞短語和引用表達式)及其對應的邊界框,我們將邊界框的連續坐標離散化為一系列位置標記,并與文本標記以統一的方式進行編碼。然后,我們通過一種“超鏈接”數據格式將位置標記和其對應的文本片段連接起來。模型被訓練來建立圖像區域和它們對應的位置信號之間的映射,并將圖像區域與其關聯的文本片段連接起來。
3.1 關聯輸入表示
給定一個文本片段及其在關聯圖像-文本對中的邊界框,我們首先將邊界框的連續坐標轉化為一系列離散的位置信號 [CSL+21]。對于一個寬度為 W 和高度為 H 的圖像,我們將寬度和高度分別均勻劃分為 P 個部分。得到 P×PP × PP×P 個網格,每個網格由(W/P)×(H/P)( W / P ) \times ( H / P )(W/P)×(H/P) 個像素組成。對于每個網格,我們使用一個位置標記來表示該網格內的坐標。我們使用每個網格中心像素的坐標來確定圖像上的邊界框。總共引入 P×PP × PP×P 個位置標記,并將這些標記加入詞匯表中,以便與文本進行統一建模。
邊界框可以通過其左上角點(x1,y1).( x _ { 1 } , \; y _ { 1 } ) \, .(x1?,y1?). 和右下角點 (x2,y2).( x _ { 2 } , \ y _ { 2 } ) .(x2?,?y2?). 來表示。我們將左上角和右下角的坐標分別離散化為位置標記。我們將左上角位置標記 、右下角位置標記 以及特殊邊界標記 和 拼接起來,表示一個單獨的邊界框:“”。如果文本片段與多個邊界框關聯,我們使用特殊標記 將這些邊界框的位置標記連接起來:“…”。
然后,我們將文本片段及其關聯的位置標記以類似“超鏈接”的數據格式排列,像是 Markdown 格式。對于與單個邊界框關聯的文本片段,結果序列為:“ text span ”,其中 和 是指示文本片段開始和結束的特殊標記。該數據格式告訴模型,位于邊界框內的圖像區域與文本片段相關聯。
對于圖 1 中展示的示例,輸入表示為:

其中,<s> 和 </s> 分別表示序列的開始和結束,<image> 和 </image> 表示圖像嵌入的開始和結束。<grounding> 是一個特殊的標記,用于指示模型將文本輸出與視覺世界進行關聯。我們通過查找表將輸入的文本標記和位置標記映射為嵌入向量。
與 KOSMOS-1 一樣,我們使用一個視覺編碼器(vision encoder)和一個重采樣模塊(resampler module)來獲取輸入圖像的圖像嵌入。
對于語言單模態數據、跨模態配對數據(即圖像-文本對)以及交錯多模態數據,我們使用與 KOSMOS-1 相同的輸入表示方式。
3.2 基于錨定的多模態大語言模型
在 KOSMOS-1 的基礎上,KOSMOS-2 通過引入錨定(grounding)和指代(referring)能力,增強了多模態大語言模型。KOSMOS-2 同樣采用基于 Transformer 的因果語言模型(causal language model)作為主干結構,并通過下一 token 預測任務進行訓練。
除了在 KOSMOS-1 中使用的多模態語料(包括文本語料、圖像-字幕對以及圖文交錯數據),我們在訓練中加入了錨定的圖文對。訓練損失只考慮離散 token,例如文本 token 和位置 token。模型可以通過位置 token 和整張圖像來學習定位和理解圖像區域,將文本片段與圖像區域關聯起來,并使用位置 token 輸出圖像區域的邊界框(bounding boxes)。
KOSMOS-2 展示了新的錨定與指代能力。指代能力使我們能夠通過邊界框指出圖像中的特定區域。KOSMOS-2 可以通過邊界框的坐標理解用戶所指的圖像區域。指代能力提供了一種新的交互方式。不同于以往只能輸出文本的多模態大語言模型(MLLMs)[ADL+22, HSD+22, HDW+23],KOSMOS-2 不僅可以提供視覺答案(即邊界框),還能將文本輸出錨定到圖像上。錨定能力使模型能夠提供更加準確、信息豐富且全面的響應。除了在 KOSMOS-1 中評估的視覺、語言和圖文任務之外,該模型還可用于更多下游任務,例如錨定圖像字幕生成、錨定視覺問答(VQA)、指代表達理解與生成等任務。
3.3 模型訓練
訓練設置
我們在新增的錨定圖文對、單模態文本語料、圖像-字幕對以及圖文交錯數據上訓練模型。訓練過程中的 batch size 為 419K 個 token,其中包括 185K 個來自文本語料的 token,215K 個來自原始及錨定圖像-字幕對的 token,以及 19K 個來自圖文交錯數據的 token。我們將 KOSMOS-2 訓練 60K 步,相當于約 250 億個 token。優化器采用 AdamW,β = (0.9, 0.98),權重衰減(weight decay)設置為 0.01,dropout 率為 0.1。學習率在前 375 個 warm-up 步驟中線性上升至 2e-4,之后再線性衰減至 0。模型訓練使用了 256 張 V100 GPU,整個訓練過程約耗時一天。為了讓模型能夠識別何時將文本輸出錨定到視覺世界中,我們在訓練時會在錨定的字幕前加上 <grounding> token。
延續 KOSMOS-1 的設計,視覺編碼器由 24 層構成,hidden size 為 1024,前饋網絡(FFN)的中間層大小為 4096。多模態大語言模型部分采用 24 層 MAGNETO Transformer [WMH+22, MWH+22],其 hidden size 為 2048,注意力頭數為 32,前饋網絡中間層大小為 8192。可訓練參數總量約為 16 億。圖像分辨率設為 224×224,patch 大小為 14×14。我們將圖像的寬度與高度各劃分為 32 個 bin,每個 bin 包含 7×7 像素,總共添加了 32×32 個位置 token 到詞表中。KOSMOS-2 的初始化使用了 KOSMOS-1 的權重,新增的位置 token 的詞嵌入隨機初始化。在訓練和指令微調過程中,我們更新所有參數。
指令微調(Instruction Tuning)
在模型訓練完成后,我們對 KOSMOS-2 進行指令微調,使其更好地對齊人類指令。我們將視覺-語言指令數據集(如 LLaVA-Instruct [LLWL23])與語言指令數據集(如 Unnatural Instructions [HSLS22] 和 FLANv2 [LHV+23])結合起來,對模型進行微調。此外,我們還通過 GRIT 中的邊界框與表達對(例如名詞短語和指代表達)構造錨定的指令數據。對于表達-邊界框對,我們使用“<p> expression </p>”作為輸入指令,提示模型生成邊界框對應的位置 token。我們還使用如“<p> It </p><box><loc1><loc2></box> is”的提示方式,要求模型根據邊界框生成相應的表達。更多模板示例見附錄中的表 B。
4 評估
我們首先在多模態grounding任務和多模態referring任務上評估KOSMOS-2,以驗證其新增能力,然后在KOSMOS-1中評估過的語言任務和感知-語言任務上測試該模型。
- 多模態grounding
– 短語grounding
– 指代表達理解 - 多模態referring
– 指代表達生成 - 感知-語言任務
– 圖像描述
– 視覺問答 - 語言任務
– 語言理解
– 語言生成

溫馨提示:
閱讀全文請訪問"AI深語解構" KOSMOS-2: 將多模態大型語言模型與世界對接
)














封裝、繼承和多態)
)


