目錄
認識Kafka
消息隊列
消息隊列的核心概念
核心價值與解決的問題
Kafka
ZooKeeper
Kafka的基本使用
環境安裝
啟動zookeeper
啟動Kafka
消息主題
創建主題
查詢主題
修改主題
發送數據
命令行操作
?JavaAPI操作
消費數據
?命令行操作
JavaAPI操作
認識Kafka
消息隊列
消息隊列是分布式系統和現代應用架構中至關重要的中間件。它的核心作用是解耦、異步和削峰填谷,像一個高效的“通信員”和“緩沖池”協調不同組件之間的工作。
消息隊列的核心概念
-
生產者:?產生消息(數據、任務請求、事件通知)并發送到隊列的應用程序或服務。
-
消息隊列:?一個臨時的、持久化的存儲區域(通常基于內存、磁盤或數據庫),用于存放生產者發送的消息。消息按照先進先出的順序存儲,但很多隊列支持優先級、延遲等特性。
-
消費者:?從隊列中獲取消息并進行處理的應用程序或服務。
-
消息:?隊列中傳輸的數據單元,通常包含有效載荷(實際數據)和元數據(如ID、時間戳、優先級等)。
核心價值與解決的問題
-
解耦:
-
問題:?系統組件(服務)之間直接調用會導致緊密耦合。一個組件的變更、故障或性能瓶頸會直接影響其他依賴它的組件。擴展也變得困難。
-
解決:?生產者只需將消息發送到隊列,無需知道誰(消費者)會處理它,消費者只需從隊列訂閱消息,無需知道消息是誰(生產者)發送的。雙方只依賴隊列,不直接依賴對方,大大降低了耦合度。系統更靈活、更易于維護和擴展。
-
-
異步:
-
問題:?同步調用要求調用方(生產者)必須等待被調用方(消費者)處理完成并返回結果才能繼續執行。如果處理耗時很長,調用方會被阻塞,資源利用率低,用戶體驗差(如網頁卡頓)。
-
解決:?生產者發送消息到隊列后即可返回,無需等待消費者處理。消費者在后臺異步地從隊列拉取消息進行處理。這顯著提高了系統的吞吐量和響應速度。
-
-
削峰填谷:
-
問題:?系統流量往往存在高峰和低谷。高峰期如果請求量遠超消費者處理能力,會導致系統過載、崩潰或請求超時。低谷期資源又可能閑置。
-
解決:?隊列作為緩沖區,在流量高峰時積壓請求,平滑地將大量請求暫存起來。消費者按照自己的穩定處理能力從隊列中拉取消息進行處理,避免了瞬間洪峰壓垮下游系統。在流量低谷時,消費者可以繼續處理隊列中積壓的消息。
-
-
冗余與可靠性:
-
問題:?直接調用時,如果消費者臨時不可用(故障、重啟、維護),生產者的請求會丟失或失敗。
-
解決:?消息隊列通常提供消息持久化功能(將消息寫入磁盤)。即使消費者暫時離線,消息也會安全存儲在隊列中,待消費者恢復后繼續處理,確保消息不丟失。許多隊列還提供確認機制(ACK),消費者處理成功后才會從隊列中移除消息。
-
-
可伸縮性:
-
問題:?單一消費者處理能力有限,難以應對增長的業務量。
-
解決:?可以很容易地增加消費者的數量(水平擴展),讓多個消費者并行地從同一個隊列中拉取消息進行處理,顯著提高系統的整體吞吐量。隊列本身也可以做成分布式集群來應對高吞吐量需求。
-
-
順序保證:
-
問題:?在分布式環境中保證消息處理的嚴格順序很困難。
-
解決:?雖然完全全局有序很難,但許多消息隊列能保證分區有序或隊列有序(在單個隊列/分區內,消息按照發送順序被消費)。這對于某些需要保證因果關系的業務場景(如賬戶流水)非常重要。
-
-
緩沖:
-
問題:?生產者和消費者的處理速度不一致。
-
解決:?隊列天然提供了緩沖能力,允許生產者和消費者以各自不同的速率工作,不會互相拖累。
-
常見的消息隊列有RabbitMQ,Kafka,RocketMQ。這里主要介紹Kafka。?
Kafka
Kafka?通常指?Apache Kafka,這是一個開源的、分布式的、高吞吐量、低延遲的流處理平臺。它最初由 LinkedIn 開發,后來捐贈給了 Apache 軟件基金會,并迅速成為大數據和實時數據處理領域的核心基礎設施之一。
? Kafka 不僅僅是一個消息隊列,它是一個高吞吐、低延遲、分布式、持久化、可水平擴展的流數據平臺。它設計之初就是為了處理持續產生、體量巨大、需要實時處理的“數據流”。
ZooKeeper是一個開源的分布式應用程序協調軟件,而Kafka是分布式事件處理平臺,底層是使用分布式架構設計,所以Kafka的多個節點之間是采用zookeeper來實現協調調度的。
ZooKeeper
ZooKeeper是一個開源的分布式應用程序協調軟件,而Kafka是分布式事件處理平臺,底層是使用分布式架構設計,所以Kafka的多個節點之間是采用zookeeper來實現協調調度的。
Zookeeper的核心作用
- ZooKeeper的數據存儲結構可以簡單地理解為一個Tree結構,而Tree結構上的每一個節點可以用于存儲數據,所以一般情況下,我們可以將分布式系統的元數據(環境信息以及系統配置信息)保存在ZooKeeper節點中。
- ZooKeeper創建數據節點時,會根據業務場景創建臨時節點或永久(持久)節點。永久節點就是無論客戶端是否連接上ZooKeeper都一直存在的節點,而臨時節點指的是客戶端連接時創建,斷開連接后刪除的節點。同時,ZooKeeper也提供了Watch(監控)機制用于監控節點的變化,然后通知對應的客戶端進行相應的變化。Kafka軟件中就內置了ZooKeeper的客戶端,用于進行ZooKeeper的連接和通信。
Kafka的基本使用
環境安裝
我們這里先安裝簡單的Windows單機環境。在安裝之前務必先安裝Java8。
下載Kafka:Kafka下載地址Apache Kafka: A Distributed Streaming Platform.![]() https://kafka.apache.org/downloads
https://kafka.apache.org/downloads
選擇版本為2.13-3.8.0
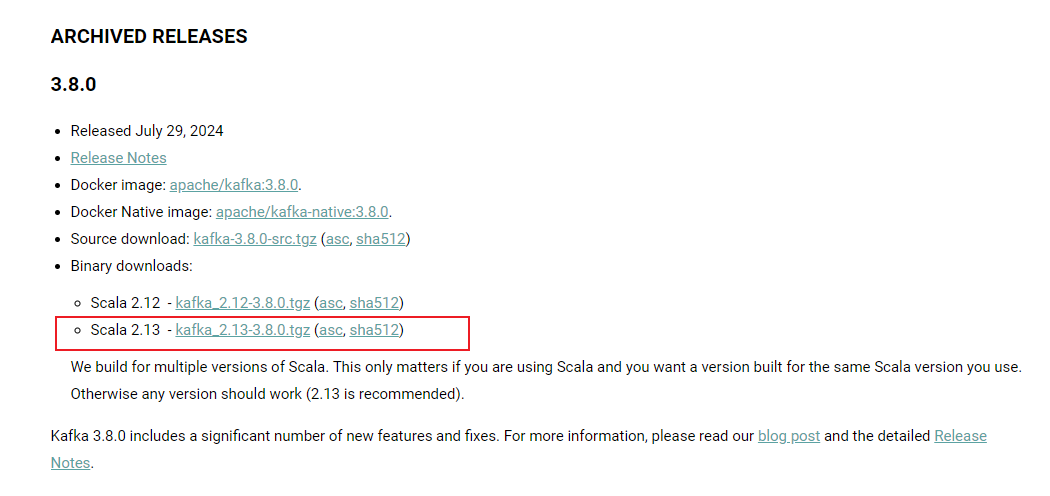
下載完成后進行解壓,解壓目錄放在非系統盤根目錄下。為了訪問方便,可以將解壓后的文件夾名稱修改為Kafka
Kafka的文件目錄
| bin | linux系統下可執行腳本文件 |
| bin/windows | windows系統下可執行腳本文件 |
| config | 配置文件 |
| libs | 依賴類庫 |
| licenses | 許可信息 |
| site-docs | 文檔 |
| logs | 服務日志 |
啟動zookeeper
當前版本的Kafka軟件仍然依賴Zookeeper,所以啟動Kafka之前,需要先啟動Zookeeper,Kafka軟件內置了Zookeeper,所以無需額外安裝,直接調用啟動腳本即可。
?1.?進入Kafka解壓縮文件夾的config目錄,修改zookeeper.properties配置文件
修改dataDir配置,用于設置ZooKeeper數據存儲位置,該路徑如果不存在會自動創建。
dataDir=D:/kafka/data/zk

在kafka解壓縮后的目錄中創建Zookeeper啟動腳本文件:zk.cmd。
輸入:
call bin/windows/zookeeper-server-start.bat config/zookeeper.properties
上述指令就是調用zookeeper啟動命令,同時指定配置文件?
雙擊啟動即可:
?啟動完成。
啟動Kafka
進入Kafka解壓縮文件夾的config目錄,修改server.properties配置文件.

設置Kafka數據的存儲目錄。如果文件目錄不存在,會自動生成。
在kafka解壓縮后的目錄中創建Kafka啟動腳本文件:kfk.cmd。
輸入:
call bin/windows/kafka-server-start.bat config/server.properties
雙擊啟動即可:?
?
DOS窗口中,輸入jps指令,查看當前啟動的軟件進程:
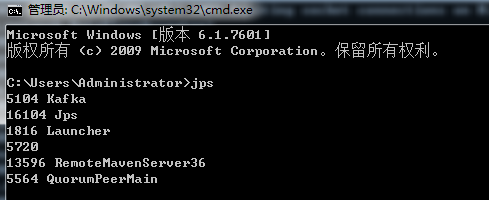
這里名稱為QuorumPeerMain的就是ZooKeeper軟件進程,名稱為Kafka的就是Kafka系統進程。此時,說明Kafka已經可以正常使用了。?
消息主題
? 在發布訂閱模型中,為了讓消費者對感興趣的消息進行消費,而不是消費所有消息,所以就定義了主題(Topic),也就是說將不同的消息進行分類,分成不同的主題(Topic),然后消息生產者在生成消息時,就會向指定的主題(Topic)中發送,而消息消費者也可以訂閱自己感興趣的主題(Topic)并從中獲取消息。
有很多種方式都可以操作Kafka消息中的主題(Topic):命令行、第三方工具、Java API、自動創建。而對于初學者來講,掌握基本的命令行操作是必要的。所以接下來,我們采用命令行進行操作。
創建主題
使用命令行方式創建主題test
打開DOS窗口,在確保Zookeeper和Kafkfa啟動的情況下,進入Kafkfa解壓目錄下的bin/windows目錄。
輸入如下命令創建主題test: kafka-topics.bat?--bootstrap-server localhost:9092 --create --topic test

test主題創建完成。
查詢主題
輸入如下命令進行主題查詢:kafka-topics.bat?--bootstrap-server localhost:9092 --list

修改主題
kafka-topics.bat --bootstrap-server localhost:9092 --topic test --alter --partitions 2
上述命令將test主題的分區數量設置為2.關于分區的信息,后面會詳細介紹。
發送數據
命令行操作
使用命令行方式發送:
kafka-console-producer.bat --bootstrap-server localhost:9092 --topic test

上述操作就是在控制臺生成數據,hello kafka 這里的數據需要回車,才會發送到Kafka服務器。
?JavaAPI操作
引入依賴
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.8.0</version>
</dependency>?編寫生產者
public class ProducerTest {public static void main(String[] args) {// 配置屬性集合Map<String, Object> configMap = new HashMap<>();// 配置屬性:Kafka服務器集群地址configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");// 配置屬性:Kafka生產的數據為KV對,所以在生產數據進行傳輸前需要分別對K,V進行對應的序列化操作configMap.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");configMap.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");// 創建Kafka生產者對象,建立Kafka連接// 構造對象時,需要傳遞配置參數KafkaProducer<String, String> producer = new KafkaProducer<>(configMap);// 準備數據,定義泛型// 構造對象時需要傳遞 【Topic主題名稱】,【Key】,【Value】三個參數for (int i = 0; i < 10; i++) {ProducerRecord<String, String> record = new ProducerRecord<String, String>("test", "key" + i, "value" + i);// 生產(發送)數據producer.send(record);}// 關閉生產者連接producer.close();}
}消費數據
?命令行操作
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning

JavaAPI操作
public class ConsumerTest {public static void main(String[] args) {
// 創建配置對象Map<String, Object> configMap = new HashMap<>();configMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
// 反序列化類配置configMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());configMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 組ID配置configMap.put(ConsumerConfig.GROUP_ID_CONFIG, "test");// 創建消費者對象KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configMap);// 從kafka主題中獲取對象 訂閱主題consumer.subscribe(Collections.singleton("test"));// 消費者從Kafka主題中拉取數據while (true) {ConsumerRecords<String, String> datas = consumer.poll(100);for (ConsumerRecord<String, String> data : datas) {System.out.println(data);}}// 關閉消費者對象// consumer.close();}
}




封裝、繼承和多態)
)












