一、Netty的零拷貝機制
零拷貝的基本理念:避免在用戶態和內核態之間拷貝數據,從而降低 CPU 占用和內存帶寬的消耗除了系統層面的零拷貝。
1、FileRegion 接口
FileRegion 是 Netty 提供的用于文件傳輸的接口,它通過調用操作系統的 sendfile 函數實現文件的零拷貝傳輸。sendfile 函數可以將文件數據直接從文件系統發送到網絡接口,而無需經過用戶態內存拷貝。
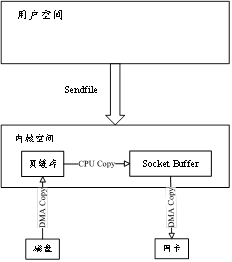
2、ByteBuf
ByteBuf提供了直接緩沖區(Direct Buffer)和堆緩沖區(Heap Buffer)兩種類型
- HeapBuffer: 網絡 IO、文件 IO 這種系統調用時,需要從 JVM 堆內存拷貝一次到內核態(socket buffer 或page cache); 即:JVM堆內 → JVM堆外(臨時內存) → 內核內存
- DirectBuffer: JVM 分配的堆外內存可以直接暴露給內核,系統調用時 省了一次 JVM 內存 →內核的拷貝。即:JVM堆外(直接可用) → 內核內存
DirectBuffer 的好處是“避免 JVM 內存到內核內存的拷貝”
3、CompositeByteBuf
它是 Netty 提供的一種組合緩沖區,它可以將多個 ByteBuff 實例組合成一個邏輯上的緩沖區,而不需要實際拷貝數據。這種方式可以避免內存拷貝,提高內存使用效率。
沒有 CompositeByteBuf 的話,我要合并三段數據(無論堆內還是 DirectBuffer)都得 拷貝 3 次字節;
有了 CompositeByteBuf,就可以 0 拷貝地把三段數據拼成一個整體,只在 最終 write 到 socket 時拷貝一次!
4、內存映射文件(Memory-Mapped File)
Netty 支持使用內存映射文件來實現文件的零拷貝。通過 MappedByteBuffer,文件可以被映射到內存中,并直接進行讀取和寫入操作,而不需要額外的內存拷貝。
MappedByteBuffer 是一種“把文件變成內存”的操作方式,它不是真正讀了文件,而是借助操作系統提供的“內核頁緩存 + 頁面調度機制”來讓你用內存方式讀寫文件內容,從而跳過傳統 IO 調用,提升性能,減少拷貝,即減少了傳統 read() IO 中“從內核態拷貝到用戶態”的那一步內存拷貝。
傳統文件讀取流程:read() 的拷貝路徑
磁盤 →(DMA)→ 內核頁緩存(Page Cache) → memcpy → 用戶空間 byte[]
1?、磁盤讀取文件數據,用 DMA 拷貝到 Page Cache(內核態)
2?、系統調用 read() 把 Page Cache 中的數據 memcpy 一份給用戶傳進來的 byte[](用戶態)
這一步會發生一次額外的數據拷貝:內核態 → 用戶態
MappedByteBuffer 是怎么優化的?
磁盤 →(DMA)→ 內核頁緩存(Page Cache)→ 直接映射到你的虛擬地址空間
1、把 Page Cache 的那塊物理內存直接映射到你的進程的虛擬地址空間中
2、你訪問這塊內存時,系統不會再復制數據,而是讓你直接讀取那塊 Page Cache 中的物理頁
所以,數據是:
? 從磁盤 → Page Cache(依然是必要的!)
? 正省掉的是 “Page Cache → JVM堆內存”這一步;
FileRegion和ByteBuf功能上的區別
FileRegion 是為了解決 “文件發送”時避免拷貝(sendfile);
ByteBuf 是為了處理 內存中動態字節數據的讀寫、拼接、編碼、解析。
兩者職責完全不同,不是你用上 FileRegion,ByteBuf 就沒用了,而是:
? 要發的是文件,就用 FileRegion
? 要發的是內存里的消息、請求體、序列化數據、協議幀,那就必須用 ByteBuf
| 功能 | FileRegion | ByteBuf | MappedByteBuffer |
|---|---|---|---|
| 定位用途 | **高效“文件→網絡”**發送 | 內存中動態字節操作 | 直接把文件映射到內存操作 |
| 適用場景 | 大文件下載、文件轉發 | 普通的內存字節處理(協議解析、緩存) | 大文件讀寫、隨機訪問、內存級文件解析 |
| 是否省拷貝 | ? sendfile 內核實現,零拷貝,省 內核態→用戶態 | ? IO 時還是要經歷 內核態 → 用戶態 | ? mmap 機制,省 內核態 → 用戶態 拷貝 |
| 是否跨內核和用戶態 | 直接文件 → socket,用戶態不介入 | 用戶態玩數據,涉及 IO 時交互頻繁 | 雖然你用的是用戶態地址,但指向的是 Page Cache |
| 寫操作友好性 | ? 不可修改,只是數據“搬運工” | ? 任意讀寫內存 | ?? 寫入時會 臟頁同步到 Page Cache → 文件,有刷盤成本 |
| 核心優勢 | 零拷貝、文件轉發超快 | 靈活讀寫、內存拼接、操作方便 | 直接訪問文件內容、適合大文件,訪問就像數組一樣快 |
| 底層依賴 | sendfile() 系統調用 | JVM堆或 DirectBuffer | mmap() 系統調用 |
二、 Netty如何解決粘包拆包問題?
Netty 提供了豐富的自帶解碼器為我們解決粘包和拆包的問題,也可以讓我們自定義序列化解碼器。
Netty 自帶的解碼器
1、DelimiterBasedFrameDecoder:分隔符解碼器,使用特定分隔符來分割消息。
2、FixedLengthFrameDecoder:固定長度的解碼器,可以按照指定長度對消息進行拆包,如果長度不夠的話,可以使用空格進行補全,適用于每個消息長度固定的場景。
3、LengthFieldBasedFrameDecoder:可以根據接收到的消息的長度實現消息的動態切分解碼,適用于消息頭包含表示消息長度的字段的場景。
4、LineBasedFrameDecoder:發送端發送數據包的時候,數據包之間使用換行符進行分割,LineBasedFrameDecoder就是直接遍歷 ByteBuf中的可讀字節,根據換行符進行數據分割。
三、 介紹一下Reactor線程模型
Reactor 是服務端在網絡編程時的一個編程模式,主要由一個基于 Selector (底層是select/poll/epoll)的死循環線程,也稱為 Reactor 線程
基于事件驅動,將 I/0 操作抽象成不同的事件,每個事件都配置對應的回調函數,由Selector 監聽連接上事件的發生,再進行分發調用相應的回調函數進行事件的處理。
Reactor 線程模型分為三種,分別為單 Reactor 單線程模型、單 Reactor 多線程模型、主從 Reactor 多線程模型。
1)單 Reactor 單線程模型:所有的操作都是由一個 I/O 線程處理。
·優點:對系統資源消耗較少
·缺點:沒辦法支持高并發場景。
2)單 Reactor 多線程模型:一個線程負責接收建連事件和后續的連接 I/0 處理(read
send等),線程池處理具體業務邏輯。
·優點:可以很好地應對大部分的場景,也提高了事件的處理效率。
·缺點:并發量大的時候,一個線程可能沒辦法接收所有的事件請求,可能導致性能瓶頸。
3)主從 Reactor 多線程模型:主 Reactor 線程負責接收建連事件,從 Reactor 線程負責處理建連后的后續連接 I/0 處理(read、send等),線程池處理具體業務邏輯
·優點:解決海量并發請求。
·缺點:相對而言,實現復雜度較高,對系統資源的管理要求會高一點
Reactor 模式的核心意義
Reactor 的核心在于“對事件作出反應”。用一個線程(或少量線程)來監聽多個連接上的事件,根據事件類型分發調用相應的處理邏輯,從而避免為每個連接都分配一個線程。與傳統模型對比,傳統阻塞 I/0 是一個線程對應一個連接,資源浪費嚴重;而 Reactor 模式能實現一對多的映射,更適合高并發場景。
四、 有幾種I/O模型?
1)同步阻塞I/O(Blocking I/O,BIO)
線程調用 read 時,如果數據還未到來,線程會一直阻塞等待;數據從網卡到內核,再從內核拷貝到用戶空間,這兩個拷貝過程都為阻塞操作。
·優點:實現簡單,邏輯直觀;調用后直接等待數據就緒
·缺點:每個連接都需要一個線程,即使沒有數據到達,線程也會被占用,導致資源浪費,不適合高并發場景。
2)同步非阻塞I/0(Non-blocking I/O,NIO)在非阻塞模式下,read 調用如果沒有數據就緒會立即返回錯誤(或特定狀態),不會阻塞線程;應用程序需要不斷輪詢判斷數據是否就緒,但當數據拷貝到用戶空間時依然是阻塞的。
·優點:線程不會長時間阻塞,可以在無數據時執行其他任務;適用于部分實時性要求較高的場景。
·缺點:輪詢方式會頻繁進行系統調用,上下文切換開銷較大,CPU占用率較高,不適合大規模連接。
3)I/0 多路復用
通過一個線程(或少量線程)使用 select、等系統調用,監控多個連接的poll ,epoll狀態;只有當某個連接的數據就緒時,系統才通知應用程序,再由應用程序調用read 進行數據讀取(讀取時仍為阻塞操作)。
·優點:大大減少了線程數量和上下文切換,能高效處理大量并發連接;資源利用率高。
·缺點:依賴系統內核的支持,不同的多路復用實現(如 select vs epoll)有各自局限。
4)信號驅動 I/O
由內核在數據就緒時發出信號通知應用程序,應用程序收到信號后再調用read(依然阻塞)
·優點:理論上可以避免輪詢,數據就緒時由內核主動通知。
·缺點:對于 TCP 協議,由于同一個信號可能對應多種事件,難以精確區分(所以實際應用中使用較少)。
五、 Netty應用場景
Netty 的應用場景主要有以下幾個:許多框架底層通信的實現,比如說 RocketMQ、Dubbo、Elasticsearch、Cassandra等,底層都使用到了 Netty。
游戲行業,在游戲服務器開發中,Netty 用于處理大量并發的游戲客戶端連接,提供低延遲的網絡通信能力
實現一個通訊系統,比如聊天室、IM 等,處理高并發的實時消息傳輸。
物聯網即 IOT 場景,Netty 可用于設備與服務器之間的通信,處理設備數據的收集和命令下發。
六、 為什么不使用原生的NIO而選擇Netty?
使用 Netty 的優勢:
1)Netty 封裝了 NIO 的復雜 API,提供了更簡單、直觀的編程接口,使開發者更容易上手和維護。
2)Netty 提供了優化的多線程模型(如 Reactor 模型),可以更高效地處理 //O 事件和任務調度,提升并發處理能力。
3)Netty 支持多種傳輸協議(http、dns、tcp、udp 等等),并且有自帶編碼器,解決了 TCP 粘包和拆包的問題。
4)在原生 NIO 的基礎上解決了 Selector 空輪詢 Bug 的問題,且準備內部的細節做了優化,例如 JDK 實現的 selectedKeys 是 Set 類型,Netty 使用了數組來替換這個類型,相比 Set 類型而言,數組的遍歷更加高效,其次數組尾部添加的效率也高于 Set,畢竟 Set還可能會有 Hash 沖突,這是 Netty 為追求底層極致優化所做的。
5)采用了零拷貝機制,避免不必要的拷貝,提升了性能。
七、 Netty性能高的原因
Netty 性能高的主要原因如下:
非阻塞 I/O 模型(如何監聽事件):Netty 底層使用了 NIO 非阻塞模型,并且利用IO多路復用,通過 Selector 監聽多個 Channel的 IO 事件,使得系統資源得到了充分利用,減少了線程開銷。
優秀的線程模型(事件來了由誰處理):Netty 底層有很多優秀的線程模型,比如 Reactor 模型、主從Reactor 模型、多線程模型等,可以高效地發揮系統資源的優勢,減少鎖沖突,實現無鎖串行,針對不同業務場景的訴求,可以自定靈活控制線程,提高系統的并發處理能力。
零拷貝(數據傳輸):DirectBuffer 減少堆內外的拷貝、CompositeBuffer 減少數據拼接時的拷貝、FileRegion 減少文件傳輸時的拷貝。
高效的內存操作與內存池設計:ByteBuf提供了豐富的功能,如動態擴展、復合緩沖區等,能高效地進行內存操作,并使用內存池技術來優化 ByteBuf的分配和回收,減少頻繁的內存分配和釋放操作,提高性能。
八、 Netty如何解決NIO中的空輪詢BUG?
Netty 實際上并沒有解決 JDK 原生 NIO 中空輪詢 bug,而是通過其他途徑繞開了這個錯誤。
具體操作如下:
1、統計空輪詢次數:Netty 通過 selectCnt 計數器來統計連續空輪詢的次數。每次執行Selector.select()方法后,如果發現沒有 I/O 事件,selectCnt 就會遞增,
2、設置閾值:Netty 定義了一個閾值 SELECTOR AUTO REBUILD THRESHOLD,默認值為 512。當空輪詢次數達到這個值時,Netty 會觸發重建 Selector 的操作。
3、重建 Selector:當達到空輪詢的閾值時,Netty 會創建一個新的 Selector,并將所有注冊的 Channel 從舊的 Selector 轉移到新的 Selector 上。這一過程涉及到取消舊日 Selector上的注冊,并在新 Selector 上重新注冊 Channel。
4、關閉舊的 Selector:在成功重建 Selector 并將Channel 重新注冊后,Netty 會關閉舊的 Selector,從而避免繼續在舊的 Selector 上發生空輪詢。總結來看,就是通過 selectCnt 統計沒有 I/0 事件的次數來判斷當前是否發生了空輪詢如果發生了就重建一個 Selector 替換之前出問題的 Selector,所以說 Netty 實際上沒解決空輪詢的 bug,只是繞開了這個問題。
空輪詢 bug 原因:
當連接的 Socket 被突然中斷(如對端異常關閉)時,epoll 會將該 Socket 的事件標記為EPOLLHUP 或 EPOLLERR,導致 Selector 被喚醒。然而,SelectionKey 并未定義處理這些異常事件的類型,導致 Selector 被喚醒后,無法處理這些異常事件,從而進入空輪詢狀態,導致 CPU 占用率過高。
Selector 底層其實用的是 epoll(Linux):
? epoll_wait() 支持監聽幾萬個 fd(也就是 SocketChannel)
? 這些 fd 上注冊的事件一般是:
? EPOLLIN → 對應 Java 的 OP_READ
? EPOLLOUT → 對應 Java 的 OP_WRITE
? 還有 EPOLLHUP(掛起) / EPOLLERR(錯誤)這兩種“系統級”異常事件
? 問題點:異常事件雖然會喚醒 epoll,但 Java 層不處理,Selector 會調用 native epoll_wait,被 EPOLLHUP、EPOLLERR 喚醒沒問題。但是,Java 的 SelectionKey 只支持處理 OP_READ / OP_WRITE / OP_ACCEPT / OP_CONNECT。它沒有暴露“這個 key 是因為異常喚醒的”這種能力,所以喚醒后,我們調用 selectedKeys(),結果是空的!這就等于:“你鬧鐘響了我就醒了,但你根本沒安排任務,那我只能干站著,反復被吵醒”
🚨 所以空輪詢本質就是:
Selector 被異常喚醒,但 Java 應用層沒有能力識別這個異常事件,也沒法處理它,導致不斷 select → 空 → select → 空,形成死循環 + 高 CPU。
為啥重建 Selector 就能好?
大多數空輪詢 bug 觸發的根因是:
? 某些 fd(Socket)狀態不干凈
? 或某個 selector 對象在 native epoll 里狀態亂了
所以重建 selector + 重新注冊 Channel的過程,相當于:
?重新 clean 一遍所有狀態,把原來 epoll 里的鬼影都清除掉了。
🛠 重建 Selector 的關鍵步驟:
- 創建一個新的 Selector
- 遍歷舊 Selector 中的所有 SelectionKey
- 對每個 key:
o 取出 channel 和監聽事件(interestOps)
o 嘗試用 channel.register(newSelector, interestOps, attachment) 重新注冊
o 如果注冊成功 → 加入新 Selector
o 如果注冊失敗(一般就是異常 socket) →
? 從舊的 Selector 中 cancel
? 手動關閉 Channel
? 打印警告日志






封裝、繼承和多態)
)











