stevensu1/EC0720
表 API 和 SQL#
表 API 和 SQL——用于統一流和批處理 加工。表 API 是適用于 Java、Scala 和 Python 的語言集成查詢 API,它 允許組合來自關系運算符的查詢,例如 selection、filter 和 join in 一種非常直觀的方式。Flink 的 SQL 支持基于實現 SQL 標準的?Apache Calcite。任一接口中指定的查詢具有相同的語義 并指定相同的結果,無論輸入是連續的(流式處理:無界)還是有界的(批處理:有界)。
我們的目標是同步mysql表和數據
先完成maven依賴:這里我們只引入flink-table-api-java:概覽 |Apache Flink

如果在ide中運行:還要引入<!--flink-clients,flink-table-runtime,flink-table-planner-loader- -->三個模塊:概覽 |Apache Flink

接著是mysql連接相關JDBC |Apache Flink
JDBC SQL 連接器
JDBC 連接器允許使用 JDBC 驅動程序從任何關系數據庫讀取數據和將數據寫入任何關系數據庫。本文檔介紹如何設置 JDBC 連接器以針對關系數據庫運行 SQL 查詢。
如果在 DDL 上定義了主鍵,則 JDBC 接收器以更新插入模式運行,以便與外部系統交換 UPDATE/DELETE 消息,否則,它以追加模式運行,不支持使用 UPDATE/DELETE 消息。
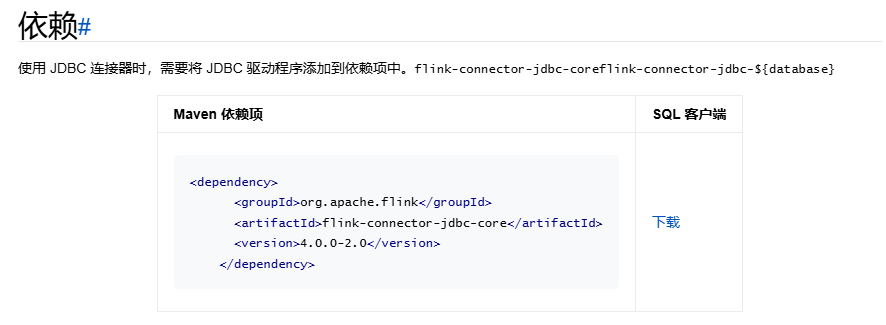
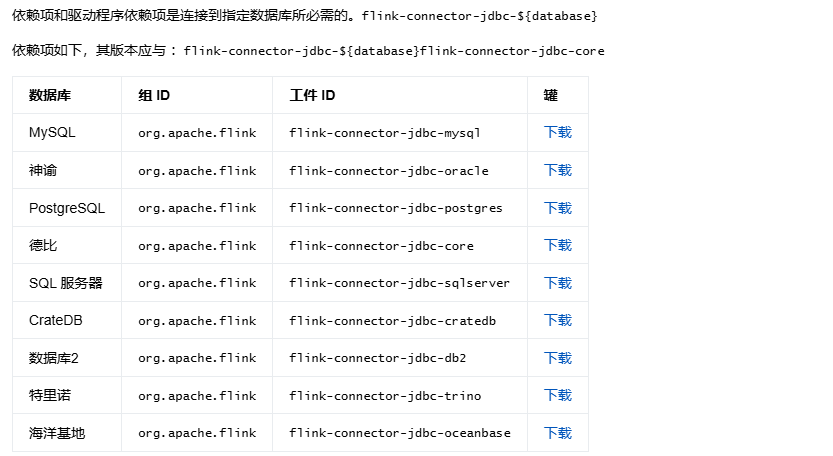
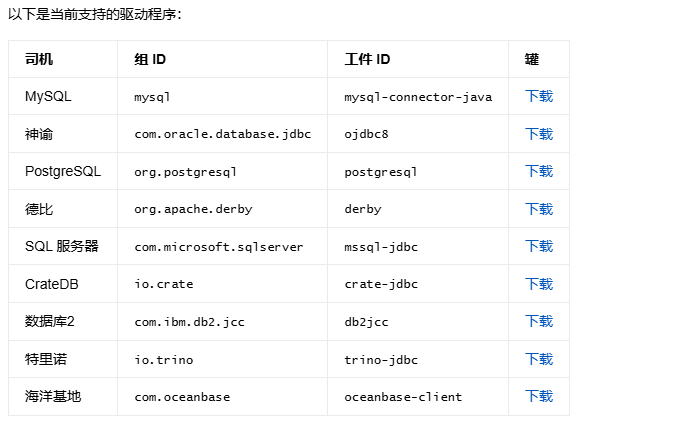
依次引入對應maven依賴:<!--flink-connector-jdbc-core,mysql-connector-java,flink-connector-jdbc-mysql -->
到此所需的依賴引入完成。不過程序通常需要打包并通過web ui上傳到Fink服務器上運行,Fink服務器通過java SPI服務發現運行我們的jar,關于java SPI接口,前面的文章《關于Red Hat Single Sign-On的User Storage SPI》里有提到過。
這是官網的插件配置地址:
第一步 |Apache Flink,所以要需要添加官方提供的maven打包插件:使用 Maven |Apache Flink

最后完整的依賴如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>FLINKTAS-TEST-Catalog</artifactId><version>1.0-SNAPSHOT</version><packaging>jar</packaging><name>FLINKTAS-TEST-Catalog</name><url>http://maven.apache.org</url><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><flink.version>2.0.0</flink.version></properties><dependencies><!--flink-clients,flink-table-runtime,flink-table-planner-loader- --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-loader</artifactId><version>2.0.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-runtime</artifactId><version>2.0.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>2.0.0</version></dependency><!--flink-table-api-java --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java</artifactId><version>2.0.0</version></dependency><!--flink-connector-jdbc-core,mysql-connector-java,flink-connector-jdbc-mysql --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.28</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc-mysql</artifactId><version>4.0.0-2.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc-core</artifactId><version>4.0.0-2.0</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>3.8.1</version><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.1.1</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><artifactSet><excludes><exclude>com.google.code.findbugs:jsr305</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformerimplementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><!-- Replace this with the main class of your job --><mainClass>org.example.App</mainClass></transformer><transformerimplementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/></transformers></configuration></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><configuration><source>15</source><target>15</target></configuration></plugin></plugins></build>
</project>
現在來實現java處理流程:
先理解一下Catalogs:他可把整個數據庫一次性注冊到表環境TableEnvironment中
Catalogs | Apache Flink

flink-connector-jdbc-mysql模塊已經對mysql的Catalogs 做了實現MySqlCatalog,但是它不能創建物理表,對此需要對其進行擴展實現對應的建表邏輯。
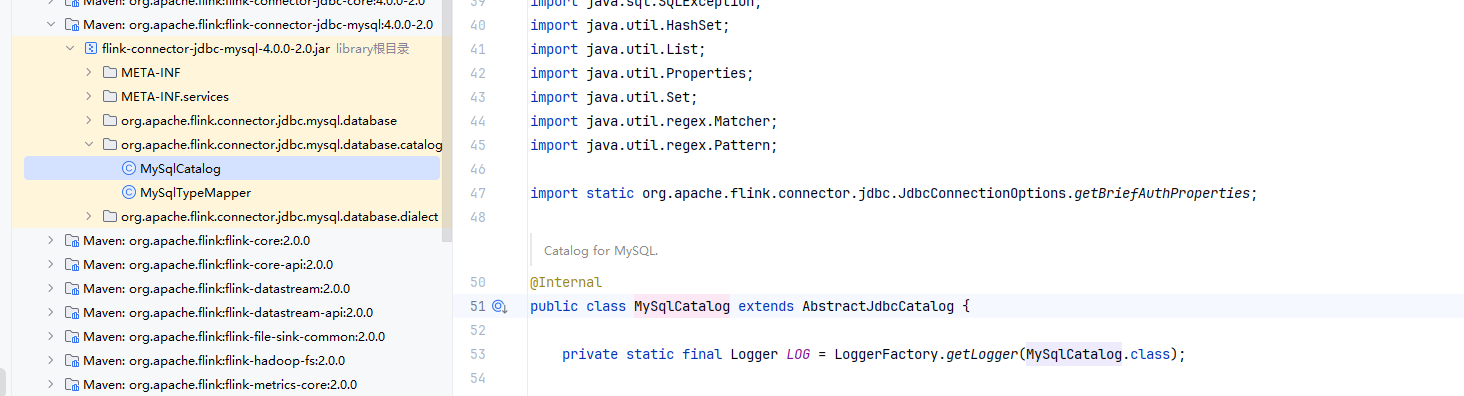
這是我的實現:
package org.example;import org.apache.flink.connector.jdbc.mysql.database.catalog.MySqlCatalog;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.catalog.*;
import org.apache.flink.table.catalog.exceptions.CatalogException;
import org.apache.flink.table.catalog.exceptions.DatabaseNotExistException;
import org.apache.flink.table.catalog.exceptions.TableAlreadyExistException;
import org.apache.flink.table.types.DataType;import java.sql.*;
import java.util.*;public class MyMySqlCatalog extends MySqlCatalog {public MyMySqlCatalog(ClassLoader userClassLoader, String catalogName, String defaultDatabase, String username, String pwd, String baseUrl) {super(userClassLoader, catalogName, defaultDatabase, username, pwd, baseUrl);}public MyMySqlCatalog(ClassLoader userClassLoader, String catalogName, String defaultDatabase, String baseUrl, Properties connectionProperties) {super(userClassLoader, catalogName, defaultDatabase, baseUrl, connectionProperties);}public void createTable(ObjectPath tablePath, CatalogBaseTable table, boolean ignoreIfExists)throws TableAlreadyExistException, DatabaseNotExistException, CatalogException {// 檢查數據庫是否存在if (!databaseExists(tablePath.getDatabaseName())) {throw new DatabaseNotExistException(getName(), tablePath.getDatabaseName());}// 檢查表是否已存在if (tableExists(tablePath)) {if (!ignoreIfExists) {return;}}Connection conn = null;try {conn = DriverManager.getConnection(baseUrl + tablePath.getDatabaseName(), this.getUsername(), this.getPassword());String createTableSql = generateCreateTableSql(tablePath.getObjectName(), table);try (PreparedStatement stmt = conn.prepareStatement(createTableSql)) {stmt.execute();}} catch (SQLException e) {throw new CatalogException(String.format("Failed to create table %s", tablePath.getFullName()), e);} finally {try {if (conn != null) {conn.close();}} catch (SQLException e) {e.printStackTrace();}}}private String generateCreateTableSql(String tableName, CatalogBaseTable table) {StringBuilder sql = new StringBuilder();sql.append("CREATE TABLE IF NOT EXISTS `").append(tableName).append("` (");// 構建列定義Schema schema = table.getUnresolvedSchema();List<String> columnDefs = new ArrayList<>();for (Schema.UnresolvedColumn column : schema.getColumns()) {if (column instanceof Schema.UnresolvedPhysicalColumn) {Schema.UnresolvedPhysicalColumn physicalColumn =(Schema.UnresolvedPhysicalColumn) column;String columnDef = String.format("`%s` %s",physicalColumn.getName(),convertFlinkTypeToMySql((DataType) physicalColumn.getDataType()));columnDefs.add(columnDef);}}sql.append(String.join(", ", columnDefs));sql.append(")");return sql.toString();}private String convertFlinkTypeToMySql(DataType dataType) {// 簡化的類型轉換,您可以根據需要擴展String typeName = dataType.getLogicalType().getTypeRoot().name();switch (typeName) {case "INTEGER":return "INT";case "VARCHAR":return "VARCHAR(255)";case "BIGINT":return "BIGINT";case "DOUBLE":return "DOUBLE";case "BOOLEAN":return "BOOLEAN";case "TIMESTAMP_WITHOUT_TIME_ZONE":return "TIMESTAMP";default:return "TEXT";}}
}最后貼一下做數據同步過程的代碼:
package org.example;import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.catalog.CatalogTable;
import org.apache.flink.table.catalog.Column;
import org.apache.flink.table.catalog.ObjectPath;
import org.apache.flink.table.catalog.exceptions.DatabaseNotExistException;
import org.apache.flink.table.catalog.exceptions.TableAlreadyExistException;
import java.util.List;import static org.apache.flink.table.api.DataTypes.INT;
import static org.apache.flink.table.api.DataTypes.STRING;/*** Hello world!*/
public class App {public static void main(String[] args) throws DatabaseNotExistException, TableAlreadyExistException {EnvironmentSettings settings = EnvironmentSettings.inStreamingMode();TableEnvironment tableEnv = TableEnvironment.create(settings);String name = "my_catalog";String defaultDatabase = "test";String username = "root";String password = "root";String baseUrl = "jdbc:mysql://localhost:3306";MyMySqlCatalog catalog = new MyMySqlCatalog(ClassLoader.getSystemClassLoader(),name,defaultDatabase,username,password,baseUrl);tableEnv.registerCatalog("my_catalog", catalog);// set the JdbcCatalog as the current catalog of the sessiontableEnv.useCatalog("my_catalog");List<String> tables = catalog.listTables(defaultDatabase);boolean exists = catalog.tableExists(ObjectPath.fromString("test.my_table_03"));//如果表不存在,則創建if (!exists) {// 定義表的字段和類型List<Column> columns = List.of(Column.physical("id", INT().notNull()),Column.physical("name", STRING()));Schema.Builder chemaB = Schema.newBuilder();chemaB.column("id", INT().notNull());chemaB.column("name", STRING());chemaB.primaryKey("id");Schema chema = chemaB.build();CatalogTable catalogTable = CatalogTable.newBuilder().schema(chema).build();catalog.createTable(ObjectPath.fromString("test.my_table_03"), catalogTable, true);}tableEnv.executeSql("SELECT * FROM my_table_01").print();tableEnv.executeSql("SELECT * FROM my_table_03").print();// 執行同步tableEnv.executeSql("INSERT INTO my_table_03 SELECT id, name FROM my_table_01");System.out.println("Hello World!");}
}
執行結果:
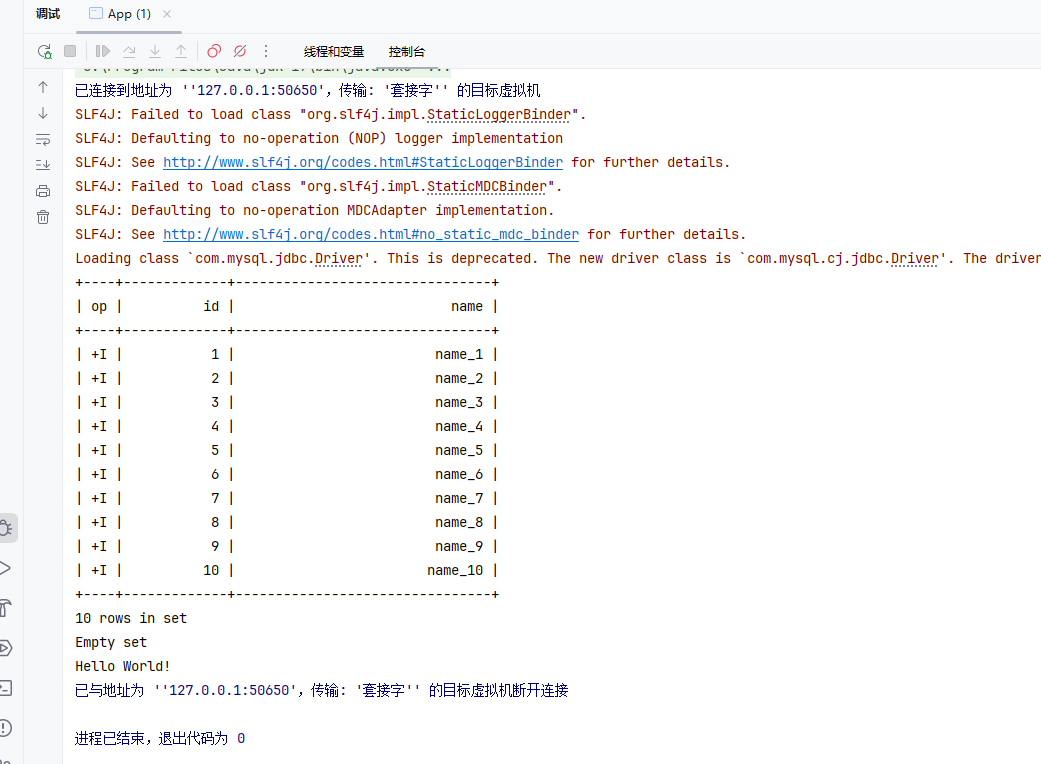
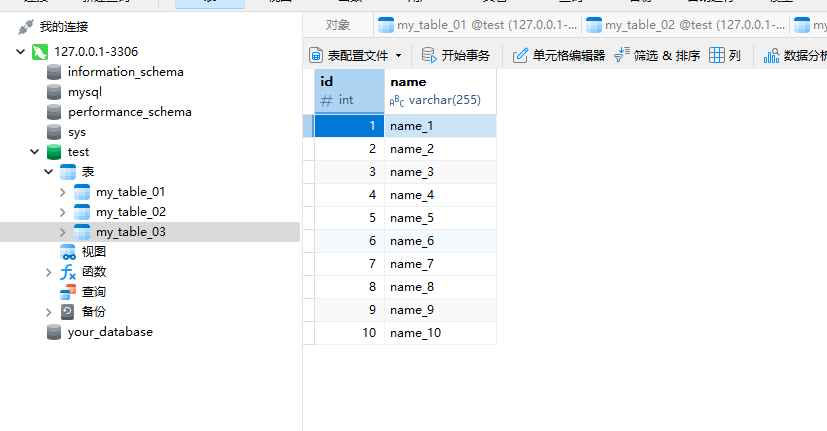
但是如果系統表太多,注冊Catalogs可能會很消耗Flink內存,所以也可以只把需要的表注冊到表環境中,
package org.example;import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;/*** Hello world!*/
public class App {public static void main(String[] args) {EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();TableEnvironment tableEnv = TableEnvironment.create(settings);registerMySqlTable(tableEnv);Table table1 = tableEnv.from("my_table_01");table1.printSchema();tableEnv.executeSql("SELECT * FROM my_table_01").print();registerMySqlTable02(tableEnv); // my_table_02Table table2 = tableEnv.from("my_table_02");table2.printSchema();tableEnv.executeSql("SELECT * FROM my_table_02").print();// 執行同步tableEnv.executeSql("INSERT INTO my_table_02 SELECT id, name FROM my_table_01");System.out.println("Hello World!");}/*** 注冊 MySQL 表 my_table_02 到 Flink 表環境中*/public static void registerMySqlTable02(TableEnvironment tableEnv) {tableEnv.executeSql("CREATE TABLE my_table_02 (" +"id INT PRIMARY KEY NOT ENFORCED, " +"name STRING" +") WITH (" +"'connector' = 'jdbc', " +"'url' = 'jdbc:mysql://localhost:3306/test', " +"'table-name' = 'my_table_02', " +"'username' = 'root', " +"'password' = 'root'" +")");}/*** 注冊 MySQL 表到 Flink 表環境中*/public static void registerMySqlTable(TableEnvironment tableEnv) {tableEnv.executeSql("CREATE TABLE my_table_01 (" +"id INT PRIMARY KEY NOT ENFORCED," +"name STRING" +") WITH (" +"'connector' = 'jdbc'," +"'url' = 'jdbc:mysql://localhost:3306/test'," +"'table-name' = 'my_table_01'," +"'username' = 'root'," +"'password' = 'root'" +")");}
}
這樣也可以實現數據同步。最后優化建議可以使用jdbc連接池技術。




封裝、繼承和多態)
)













虛擬專用網 VPN 和網絡地址轉換 NAT)