一,關于分類問題及其損失函數的一些討論。
在構建分類模型是,我們的最后一層往往是softmax函數(起到歸一化的作用),如果是二分類問題也可以用sigmoid函數。
?
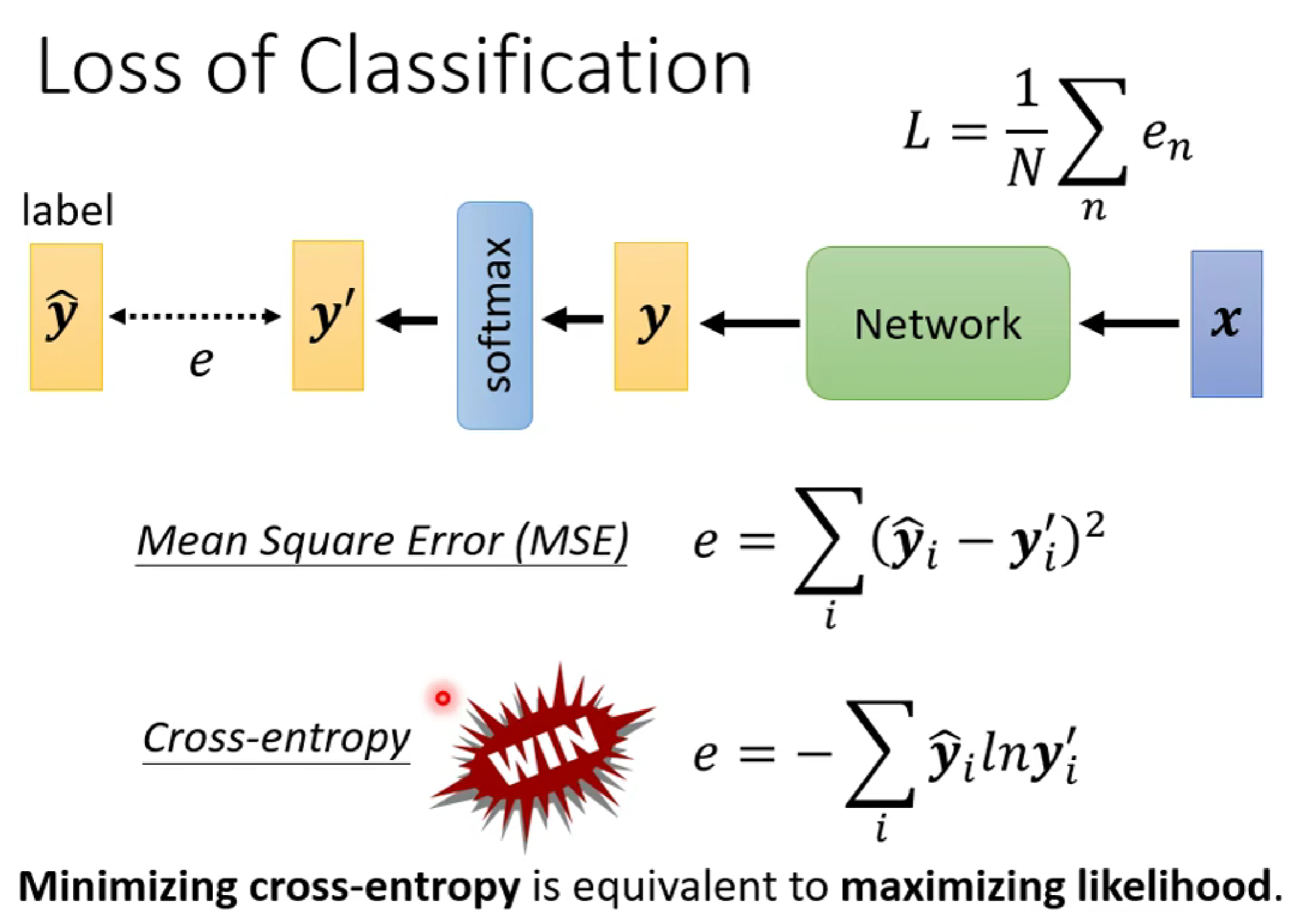
在loss函數的選擇上,一般采用交叉熵損失函數(cross-entropy),為什么呢?因為交叉熵損失函數更容易使得optimisization到達低loss(如下圖:cross-entropy的梯度圖更為陡)
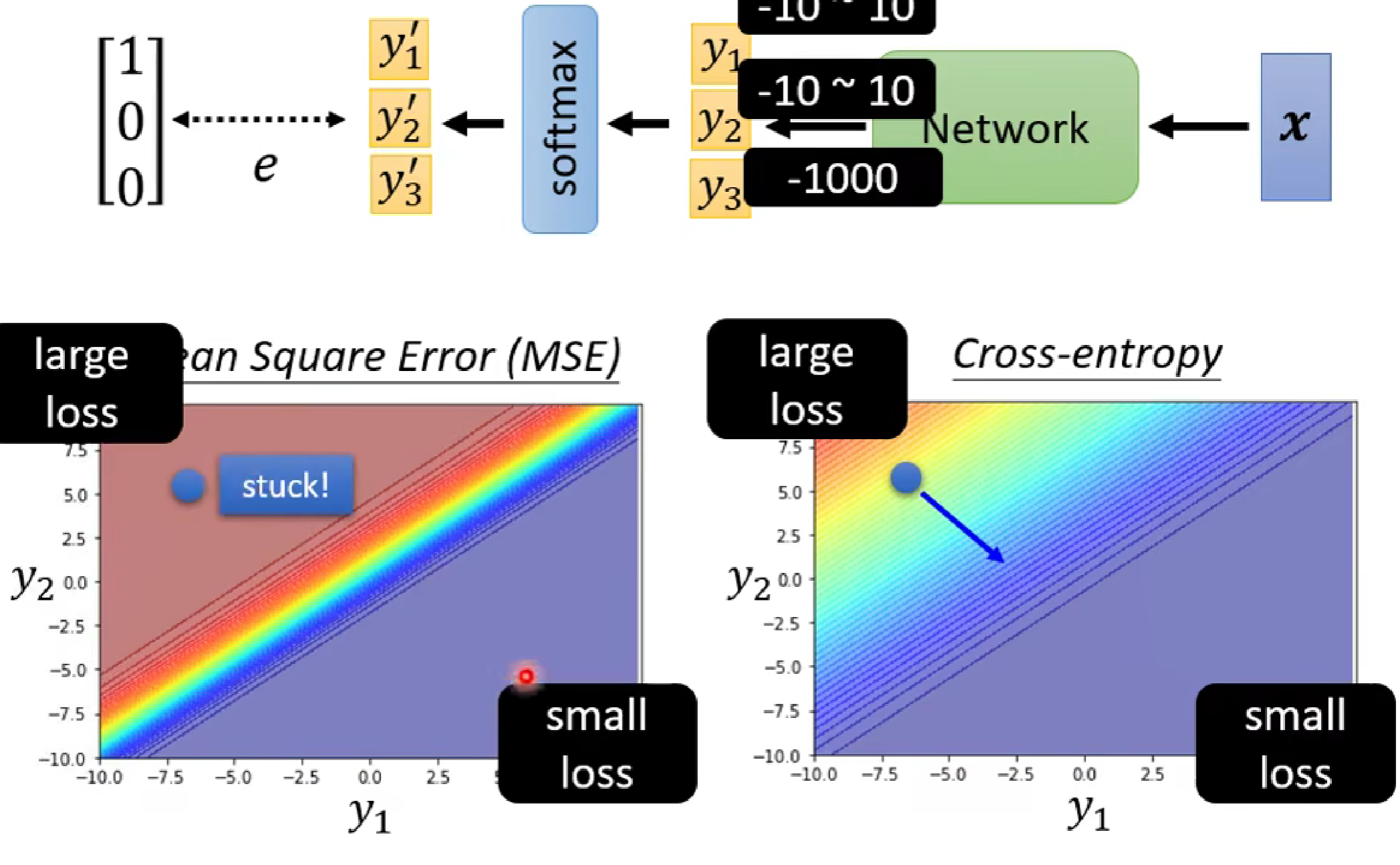
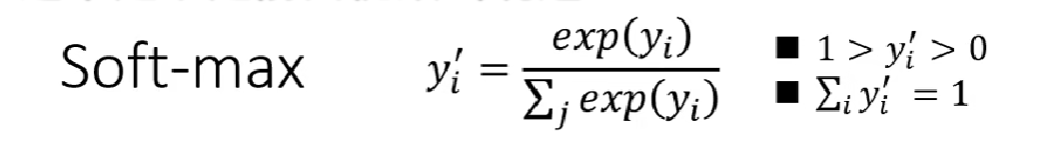 ?
?
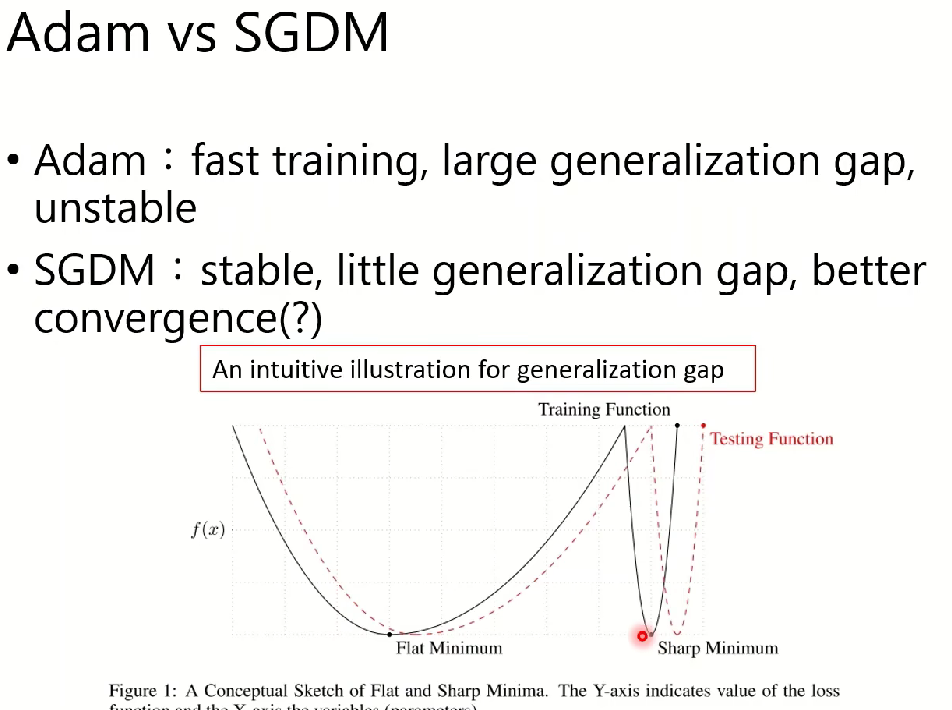
二,對于Adam和SGDM梯度優化算法的比較
Adam:訓練速度很快,但是收斂效果不佳
SGDM:訓練速度平穩,收斂性較好
SWATS算法:Adam和SGDM算法的結合:(訓練開始用Adam,在收斂時用SGDM)?
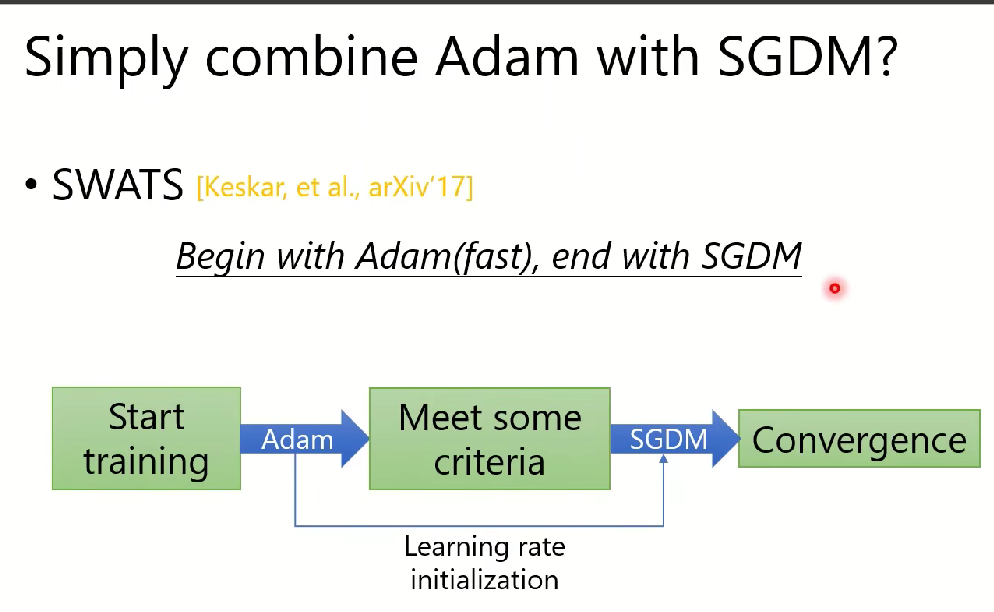
注意:使用Adam算法初始不穩定,需要進行預加熱(Warm up)?.
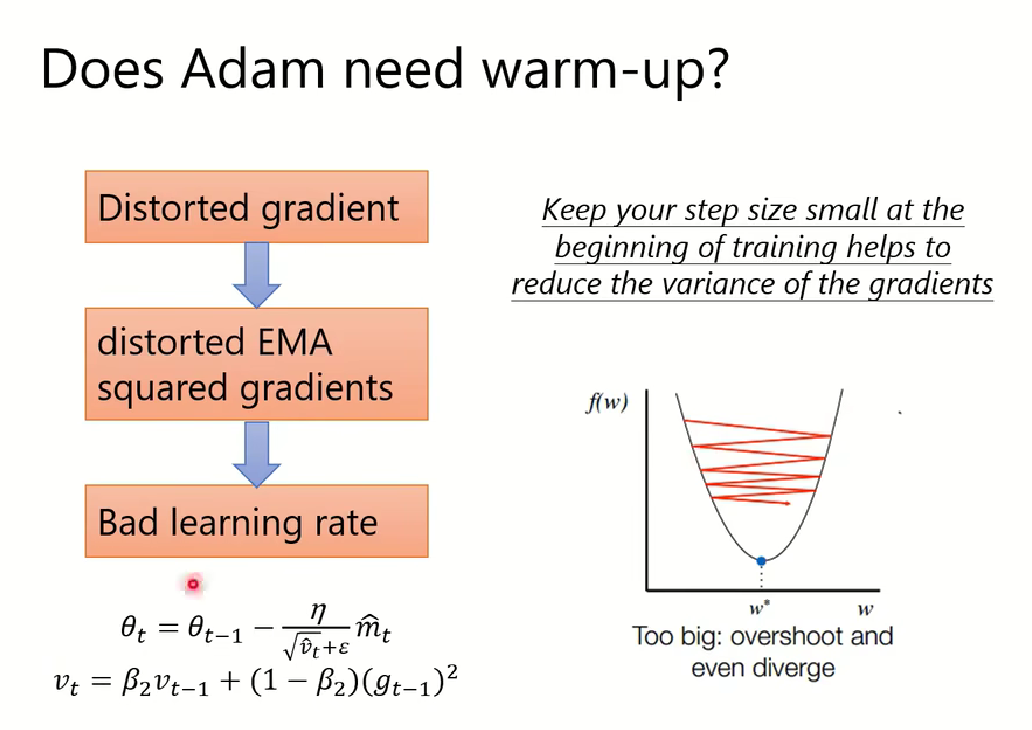
三,Radam算法與SWATS算法比較:
?

后面就有點聽不懂了,以后了解更多再來聽吧,做個記號。
(選修)To Learn More - Optimization for Deep Learning (2_2)_嗶哩嗶哩_bilibili?
筆記先做到這hh,有的笨,當先了解了。
?
?










.)

!!整數沒法進行下標)






