0.前言
????????參考CSDN大佬(太陽花的小綠豆)的代碼,梳理了一下vit的網絡結構,代碼地址如下:
deep-learning-for-image-processing/pytorch_classification/vision_transformer at master · WZMIAOMIAO/deep-learning-for-image-processing · GitHub
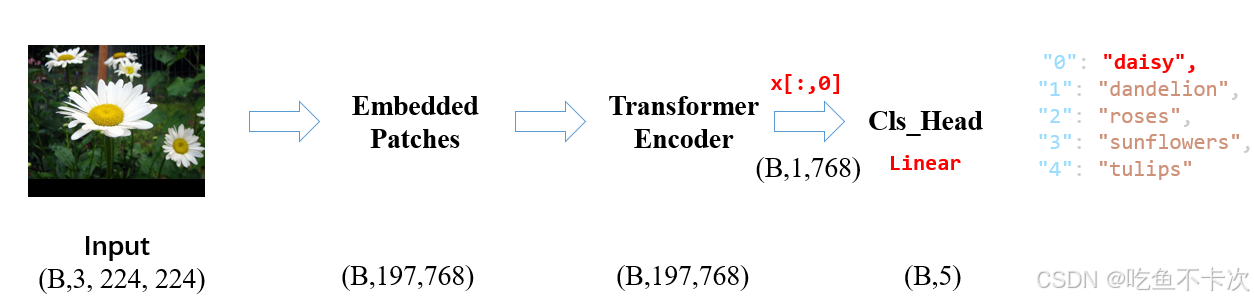
????????本文以ViT-Base model,img_size=224,patch_size=16為例子說明Vit的網絡結構。
????????如下圖所示,輸出224x224尺寸的圖片,需要依次經過Embedded Patches 、Transformer Encoder以及Cls_Head,最后輸出圖片對應的類別。
????????后面將按照這個順序分別介紹這一過程。
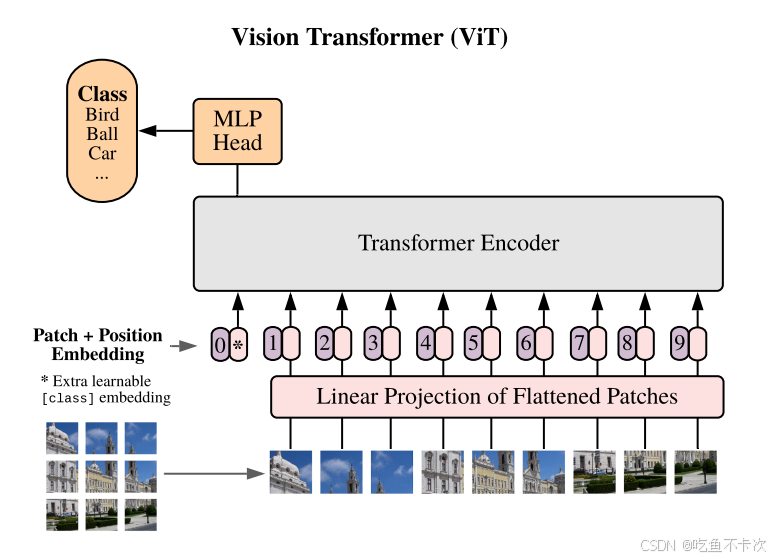
1.Embedded Patches
????????參考自Vit論文(https://arxiv.org/pdf/2010.11929)的插圖,Embedded Patches的步驟如下:
????????(1)首先,輸入一張圖片,對該圖片進行切分,得到互不重合的patch塊,如下圖所示該圖片被切分成了9個patch;
????????(2)其次,再對這9個patch經過線性變化得到9個token;
????????(3)再次,在首位加上一個cls token,這個token最后是用來預測類別的,此時一共有10個token;
????????(4)最后,給每個token加上Position embedding位置編碼后,將處理后的10個token作為Transformer Encoder模塊的輸入。
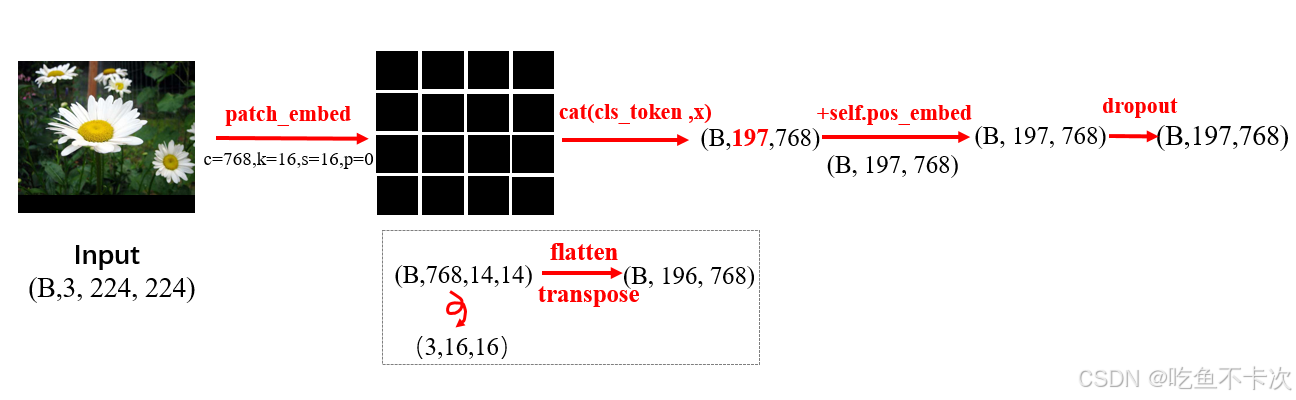
????????實際上在代碼中,是通過卷積的方式將圖片切分成一個個token,然后在首位加上一個cls token,以及給每個token補充一維位置編碼信息,最后輸出給Transformer Encoder模塊。
????????下圖是以ViT-Base model(img_size=224,patch_size=16)中Embedded Patches模塊的處理流程,有幾個需要注意的地方,path_embed和cls_token以及pose_embed,輸入和輸出的Shape是從(B,3,224,224)變化為(B,197,768),后面將詳細來介紹這個流程。
1.1patch_embed
????????pathch_embed方法實現了對圖片的切分及向量化(展平成一維),也就是前面的第(1)、(2)步驟,并且實現的方法也很簡單,就是通過一個最常用的Conv2d卷積實現,由下圖可知:該卷積核的輸入、輸出通道數分別為3和768,卷積核大小為16x16,步長也為16;
#Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)????????因此,輸入一個Shape為(3,224,224)的數據,經過該卷積核之后,通道數從3變成了768,分辨率從(224,224)變成了(14,14),輸出分辨率的計算可以參考下面這條公式,H表示輸入分辨率的高,P表示padding,k表示卷積核大小,S表示步長,Hout表示輸出分辨率的高。同理,輸出分辨率的寬也是通過這條公式進行計算的。
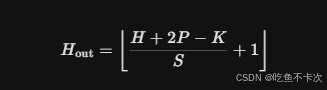
????????經過該卷積核之后,Shape從(3,224,224)變成了(768,14,14),至于為什么輸出通道數是768,我覺得這就是人為故意設計成這樣的。
????????patch_size=Kernel_size=stride=16
????????首先patch_size=16,說明了將原圖劃分成16x16尺寸的patch,因此水平方向上有224/16=14個patch,垂直方向上也有224/16=14個patch,一共有14x14=196個patch,并且每個patch塊有3x16x16=768個參數.
????????其次Kernel_size=16,stride=16,說明了每次對圖片進行卷積的時候不會存在重疊區域.
????????最后Kernel_size=16,patch_size=16,stride=16,說明了卷積核進行卷積操作的時候,卷積的區域剛好和patch的大小是一樣的,因此為了保證卷積后不會導致patch的參數"丟失",卷積核的個數(輸出通道數)需要剛好等于768;并且每次卷積之后滑動16個像素到下一個patch塊進行下一次卷積。
????????在經過Conv2d卷積后得到(768,14,14),保留Batch size維度的話就是(B,768,14,14),再經過flatten和transpose得到(B,196,768),可以這么去理解這個向量化之后的數據,196是指那196個patch,768是指每個patch經過卷積后的參數量大小。
????????pathch_embed具體實現代碼如下:
class PatchEmbed(nn.Module):"""2D Image to Patch Embedding"""def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None):super().__init__()img_size = (img_size, img_size)patch_size = (patch_size, patch_size)self.img_size = img_sizeself.patch_size = patch_sizeself.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])self.num_patches = self.grid_size[0] * self.grid_size[1]self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()def forward(self, x):B, C, H, W = x.shapeassert H == self.img_size[0] and W == self.img_size[1], \f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."# flatten: [B, C, H, W] -> [B, C, HW]# transpose: [B, C, HW] -> [B, HW, C]x = self.proj(x).flatten(2).transpose(1, 2)x = self.norm(x)return x
1.2cls_token/Position embedding
????????cls_token和Position embedding都是可學習的參數,初始化分別對應著下面代碼中的self.cls_token和self.pos_embed.
#torch.Size([1, 1, 768])
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
#torch.Size([1, 197, 768])
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))
????????以下流程對應著前面的第(3)、(4)步驟:
????????首先來看self.cls_token,這個token作用很大,就是預測頭最后用來做分類的token。
????????self.cls_token的Shape為(1,1,768),需要先對第0維的1進行擴充至B,得到(B,1,768),這是為了能和前面pathch_embed的(B,196,768)進行通道數拼接,在第1維進行拼接后得到(B,197,768),實現代碼如下:
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
x = torch.cat((cls_token, x), dim=1) # [B, 197, 768]????????再來看看self.pos_embed,這個是為了讓模型能夠學習到每個token的位置信息,包括cls_token也有對應的位置信息,所以其Shape為(1,197,768),通過直接和前面得到的(B,197,768)張量相加的方式得到輸出,最后再做一個drop_out操作,代碼如下:
self.pos_drop = nn.Dropout(p=drop_ratio)
x = self.pos_drop(x + self.pos_embed)
????????以上就是Embedded Patches的具體流程,可以理解為進入Transformer的預處理,因為Transformer最初是為處理自然語言(NLP)設計的,因此需要將圖像數據轉換成類似文本token的形式。通過Embedded Patches步驟,圖像被分割成一個個patch,并轉換為token向量,從而與NLP中的token處理方式相契合,為后續Transformer的處理做好準備。
?
1.3Dropout/DropPath
????????考慮到后面有DropOut和DropPath這兩種Drop的方法,這里就先總結一下這兩者的區別,
????????Dropout:
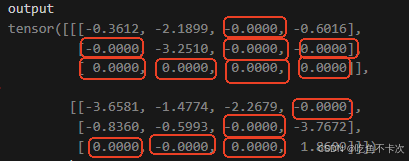
????????假設有一個Shape為(2,3,4)的張量,使用nn.Dropout(p=0.5)可以實現按照p=0.5的概率隨機將某些元素置0,并將未置零的元素乘以1/(1-p)=2倍,如下圖所示:
import torch
import torch.nn as nn
x=torch.randn(2,3,4)
drop_out=nn.Dropout(p=0.5)
output=drop_out(x)

????????DropPath:
????????這是在代碼中自定義的一種Drop方法,代碼如下:
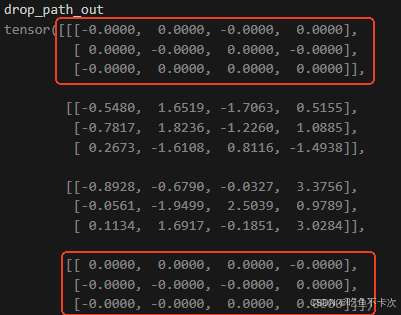
def drop_path(x, drop_prob: float = 0., training: bool = False):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted forchanging the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use'survival rate' as the argument."""if drop_prob == 0. or not training:return xkeep_prob = 1 - drop_probshape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNetsrandom_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)random_tensor.floor_() # binarizeoutput = x.div(keep_prob) * random_tensorreturn output
????????假設有一個Shape為(4,3,4)的張量,使用drop_path(drop_prob=0.5)可以實現按照drop_prob=0.5的概率隨機將某些樣本置0,并將未置零的樣本乘以1/(1-drop_prob)=2倍,如下圖所示:

????????關于為什么需要放大1/(1-p)倍,下面是kimi做出的解釋:

2.Transformer Encoder
????????下面是Transformer Encoder的結構圖,輸入的Shape為(B,197,768),經過Transformer Encoder模塊后輸出的Shape為(B,197,768),并且每一個Transformer Block的輸入和輸出Shape也是不改變的,這樣的block有12個,當然最核心的就是Transformer Block.
????????是不是感覺這個和我們熟悉的SE注意力機制、CBAM注意力機制很相似,CV中的注意力機制主要是在通道維度或者是空間維度計算權重,并通過加權計算來增強重要的信息,削弱不重要的信息,并且保持輸入和輸出的Shape不改變。
????????transformer中的self-attention自注意力機制也是類似的,計算每個token與其他所有token之間的關系(計算權重),從而動態地加權每個token(增強或者削弱),并且保持輸入和輸出的Shape不改變。
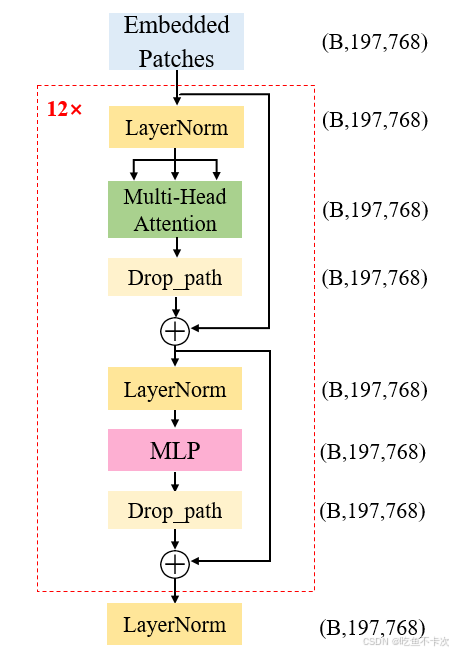
????????下面開始按照流程圖的順序來介紹下Transformer的各部分結構,分別是LayerNorm,Multi-Head Attention,MLP。
2.1LayerNorm
????????經過patch embed后的特征圖Shape為(B,197,768),最先經過LayerNorm模塊,LayerNorm并不會改變特征圖的Shape;既然都提到了標準化了,那么來對比下BatchNorm(BN)和LayerNorm(LN).
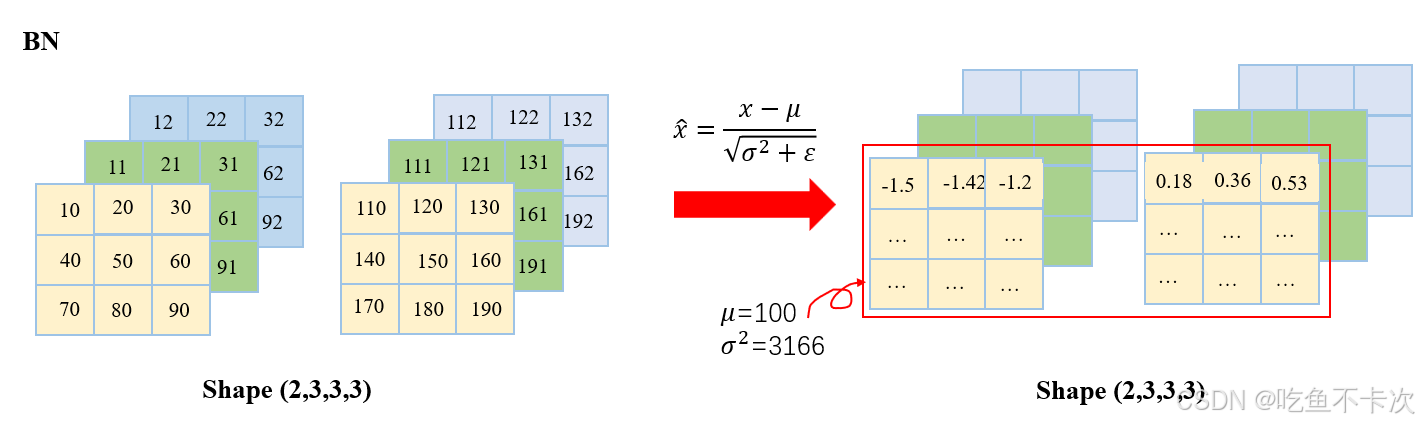
????????BN是對不同樣本的同一特征做標準化,還是推薦看看大佬的博客(Batch Normalization詳解以及pytorch實驗-CSDN博客),下面舉個例子方便理解:
????????假設現在有兩個樣本,也就是batch size=2,每個樣本的有3個通道,每個通道的數據都是3行3列的矩陣,因此可以使用(2,3,3,3)來表示這批數據的Shape。如果我要計算這批數據的BN,那么需要對這兩個樣本的同一特征求均值μ和方差σ2,同一特征也就同一個通道數,在圖中就是黃色區域為通道1,綠色區域為通道2,藍色區域為通道3。
????????以黃色區域的通道1為例,
????????均值,計算得到100;
????????方差,計算得到3166;
????????然后套入標準化公式,計算得到每個標準化之后的值,如下圖所示。
????????同理可以計算其他通道的標準化結果,只需要注意的是標準化的時候計算哪些數據的均值和方差。
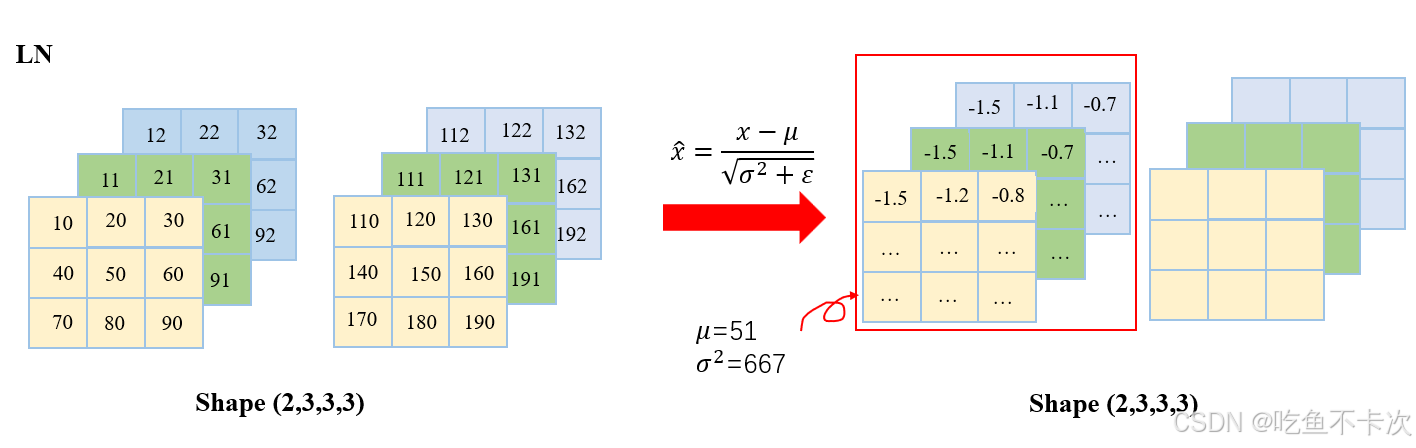
????????LN是對單個樣本的不同特征做標準化,同樣舉個例子來說明一下:
????????LN和BN不相同的是,在創建LayerNorm層時需要指定normalized_shape,指定了normalized_shape就是對這里面的數據求均值和方差。
# 創建一個 LayerNorm 層
layer_norm = nn.LayerNorm(normalized_shape=[3,3,3], eps=1e-5)
????????當normalized_shape=[3,3,3]時,即對每個樣本的3個通道中的三行三列數據求均值和方差。以第一個樣本為例:
????????均值,計算得到51;
????????方差 ,計算得到667;
????????然后套入標準化公式,計算得到每個標準化之后的值,如下圖所示。
????????當normalized_shape=[3]時,默認是對最后一個維度的值求均值和方差,即(10,40,70)為一組求均值和方差再做標準化,(20,50,80)為一組求均值和方差再做標準化,依次類推。
????????之所以提normalized_shape=[3],是因為在Transformer Encoder中的LayerNorm也是對最后一個維度求標準化的,即輸入特征圖的shape為(B,197,768),創建LayerNorm時normalized_shape=[768],這就是對最后一個維度768個數做標準化。
LayerNorm((768,), eps=1e-06, elementwise_affine=True)
2.2Multi-Head Attention
????????這是本文最重要最核心的部分,下圖就是Multi-Head Attention的流程圖,主要有兩方面重要的內容:
????????(1)生成Q/K/V
????????(2)根據公式計算Attention
????????下面的內容就是主要來介紹這兩部分的內容。

?
2.3.1生成Q/K/V
????????如果要將Embedded Patches輸出的token用來生成Q/K/V,主要有以下幾步:
????????(1)Q/K/V是三個矩陣,如果要從一個768維的矩陣擴展成3個768維的矩陣,可以通過一個Linear層來實現,因此將Input的Shape從(B,197,768)變成了(B,197,2304),注意這里只改變最后一維數據的維度值,現在就是有197個token,每個token的維度變成了2304維。
????????(2)接著要把2304維拆成3個768維的矩陣,并且對于每個768維的信息,再次進行劃分出12份,每份64維,其中12就表示Multi-Head 中的12個頭,64維就表示實際上每個Q/K/V的矩陣維度,現在的Shape為(B,197,3,12,64)。
????????(3)最后再交換下維度得到qkv,Shape變成了(3,B,12,197,64),那么Q/K/V矩陣的Shape為(B,12,197,64),且使用qkv[0]表示Q,qkv[1]表示K,qkv[2]表示V。
????????主要代碼如下所示:
#Linear(in_features=768, out_features=2304, bias=True)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2]?
2.3.2 Self-Attention
????????核心就是這條公式,前面我們已經通過Linear得到了Q/K/V矩陣了,并且還知道了每個矩陣的維度是64,也就是d=64,下面分成五步看看這條公式是如何進行計算以及Self-Attention的完整流程。
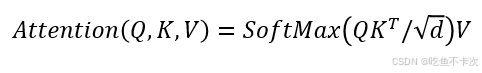
????????假設B=1,即只有一張圖片的時候,得到Q/K/V矩陣的shape為(1,12,197,64),下面為了方便就只寫后面幾維,使用(12,197,64)來表示Q/K/V的Shape了。
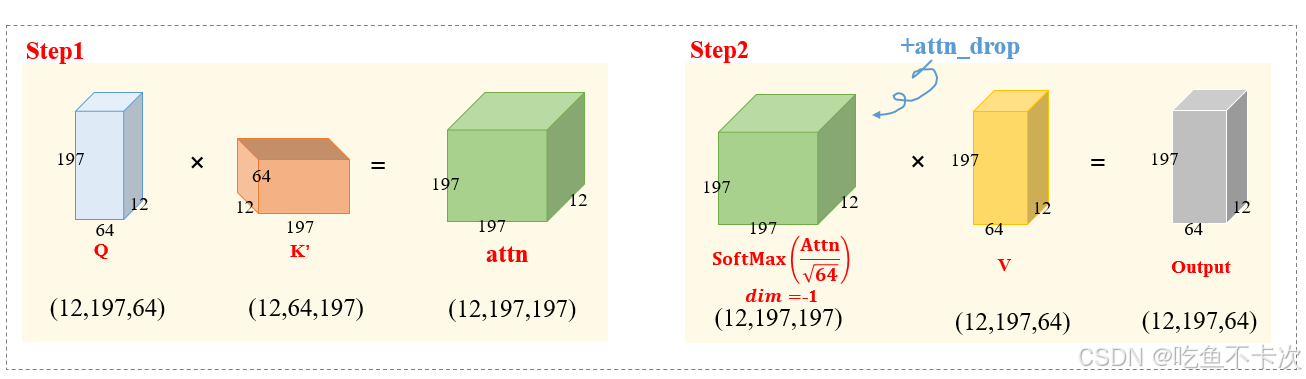
????????(1)首先是Q和K'進行矩陣乘法,對于每個Head,都會得到一個shape為(197,197)的矩陣,因為有12個head,所以得到Shape為(12,197,197)的attn矩陣,也就是公式當中;
????????(2)接下來對attn矩陣的值進行縮放,通過除以sqrt{d}實現,是為了防止數值不穩定,然后再通過Softmax函數歸一化,注意是對(12,197,197)最后一維進行Softmax處理,即對于(197,197)的矩陣,每一行的和為1,得到注意力權重;這里對應公式中的;
????????(3)接著經過attn_drop,實際上也是nn.Dropout(),不過默認值p=0,即不進行dropout操作;
????????(4)最后和V做矩陣乘法運算,得到Shape為(12,197,64)的output矩陣,再transpose和reshape成(197,768)
????????注意:如果B=n,即一次性處理多張照片時,也是相同的步驟流程,那么經過Self-Attention后會得到(B,197,768)的輸出結果。
????????主要代碼如下:
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B, N, C)????????(5)self-attention還有最后一點小尾巴,就是Linear層和Dropout(同樣默認p=0),代碼如下所示:
#Linear(in_features=768, out_features=768, bias=True)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop_ratio)x = self.proj(x)
x = self.proj_drop(x)
?
2.3MLP
????????MLP就比較簡單了,主要就是由兩個Linear層和GELU激活函數構成,然后Dropout默認p=0,即不進行Dropout操作,真想吐槽一下,為啥要設置這么多的Dropout.

????????代碼如下:
class Mlp(nn.Module):"""MLP as used in Vision Transformer, MLP-Mixer and related networks"""def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return x
2.4總結
????????(1)Transformer Encoder是由12個Transformer block構成的,也就是紅色虛線內的模塊,每個block的輸入和輸出的Shape都是(B,197,768),所以如果你想縮減下網絡的參數量大小,你可以通過調整block的大小來實現。
????????(2)Transformer block中包含有兩個殘差結構,其中第一個殘差結構包含著最重要的Multi-Head Attention,即用來計算自注意力的模塊;剩下的模塊都是比較簡單的LayerNorm模塊和MLP模塊。
????????(3)經過12個Transformer block后,會再次經過一個LayerNorm得到Transformer_encoder的輸出X,由于下游任務是用作分類,所以最后實際上是把X[:,0]輸出給Cls_Head,即我們再Embeded Patches中插入在最前面的Cls token作為輸出,用來分類預測,Shape為(B,1,768),可以看第0章前言的插圖會更加清晰整個流程。

3.Cls_Head
????????你沒看錯,Cls_Head分類頭只有一層Linear層,輸出維度直接就是類別數,簡單直接,這里我采用的是花卉數據集,一共有五個類別。
#Linear(in_features=768, out_features=5, bias=True)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
4.總結
????????本文只是根據代碼去探討下Vit的網絡結構,相信看完這塊內容,對Vit的網絡結構有一定的了解,但是在第2.2章節也一定會有很多的疑問,為什么要區分Q/K/V?他們到底代表著什么意思?感覺非常得抽象,后面我應該還會再整理一篇博文來探討下transformer中QKV,盡可能可以對這部分知識實現自恰。
)


















 - MongoDB副本集安裝與配置)