文章目錄
- 前言
- 一、下載MongoDB
- 1. 下載MongoDB
- 2. 上傳安裝包
- 3. 創建相關目錄
- 二、安裝配置MongoDB
- 1. 解壓MongoDB安裝包
- 2. 重命名MongoDB文件夾名稱
- 3. 修改配置文件
- 4. 分發MongoDB文件夾
- 5. 配置環境變量
- 6. 啟動副本集
- 7. 進入MongoDB客戶端
- 8. 初始化副本集
- 8.1 初始化副本集
- 8.2 添加副本節點
- 三、副本集操作
- 1. 副本集狀態介紹
- 2. 查看副本集成員狀態
- 3. 數據同步
- 3.1 啟用數據同步
- 3.2 測試數據同步
- 4. 故障轉移
- 4.1 終止hadoop1的MongoDB的主節點進程
- 4.2 查看從節點是否有一個自動轉為主節點
- 5. 配置副本集成員
- 5.1 調整副本集成員的優先級
- 5.2 配置隱藏節點
- 5.3 配置延遲節點
- 5.4 配置副本集成員投票權
- 5.5 將副本節點轉為仲裁節點
前言
本文詳細介紹了在Linux環境下安裝和配置MongoDB副本集的完整流程。主要內容包括:下載MongoDB安裝包并上傳至服務器;創建必要的數據和日志目錄;解壓安裝包并配置mongod.conf文件;分發MongoDB到集群節點;配置環境變量;啟動副本集服務;以及初始化副本集并添加節點。通過圖文并茂的方式展示了每個操作步驟的執行過程和驗證方法,最終實現了包含hadoop1(主節點)、hadoop2和hadoop3(副本節點)的三節點MongoDB副本集環境。
一、下載MongoDB
1. 下載MongoDB
MongoDB安裝包下載地址:https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-5.0.30.tgz
2. 上傳安裝包
通過拖移的方式將下載的MongoDB安裝包mongodb-linux-x86_64-rhel70-5.0.30.tgz上傳至虛擬機hadoop1的/export/software目錄。
3. 創建相關目錄
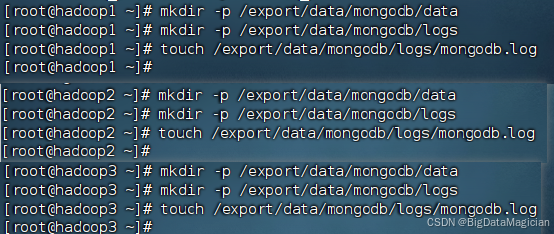
目錄/export/data/mongodb/data用于存放副本數據,目錄/export/data/mongodb/logs用于存放副本集日志,文件/export/data/mongodb/logs/mongodb.log用于保存日志,MongoDB的數據目錄和日志目錄不會自動創建,需要手動創建。分別在虛擬機hadoop1、hadoop2和hadoop3執行如下命令創建相關目錄。
mkdir -p /export/data/mongodb/data
mkdir -p /export/data/mongodb/logs
touch /export/data/mongodb/logs/mongodb.log
二、安裝配置MongoDB
1. 解壓MongoDB安裝包
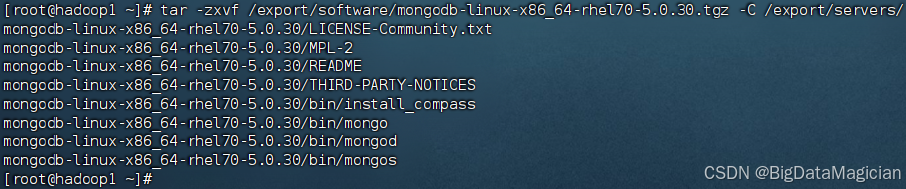
在虛擬機hadoop1上將MongoDB安裝包解壓至/export/servers目錄。
tar -zxvf /export/software/mongodb-linux-x86_64-rhel70-5.0.30.tgz -C /export/servers/
解壓完成如下圖所示。
2. 重命名MongoDB文件夾名稱
把MongoDB文件夾名稱按標準命名方式(軟件名-版本號)重命名。
mv /export/servers/mongodb-linux-x86_64-rhel70-5.0.30/ /export/servers/mongodb-5.0.30

3. 修改配置文件
參數映射說明
| 命令行參數 | 配置文件路徑 | 說明 |
|---|---|---|
--port 27017 | net.port | MongoDB服務監聽的端口 |
--bind_ip hadoop1 | net.bindIp | 監聽的網絡接口(主機名或IP) |
--dbpath=/export/... | storage.dbPath | 數據文件存儲路徑 |
--logpath=/export/... | systemLog.path | 日志文件路徑 |
--logappend | systemLog.logAppend | 以追加模式寫入日志(保留歷史記錄) |
--fork | processManagement.fork | 以守護進程模式運行(后臺運行) |
--replSet bigdata_mongodb | replication.replSetName | 副本集名稱 |
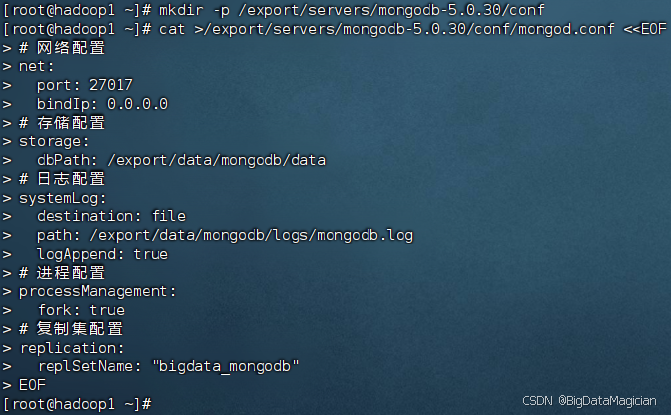
在虛擬機hadoop1執行如下命令創建配置文件目錄,并向配置文件mongod.conf中添加配置內容。
mkdir -p /export/servers/mongodb-5.0.30/conf
cat >/export/servers/mongodb-5.0.30/conf/mongod.conf <<EOF
# 網絡配置
net:port: 27017bindIp: 0.0.0.0
# 存儲配置
storage:dbPath: /export/data/mongodb/data
# 日志配置
systemLog:destination: filepath: /export/data/mongodb/logs/mongodb.loglogAppend: true
# 進程配置
processManagement:fork: true
# 復制集配置
replication:replSetName: "bigdata_mongodb"
EOF
4. 分發MongoDB文件夾
把虛擬機hadoop1中的MongoDB文件夾復制到虛擬機hadoop2和hadoop3中。
scp -r /export/servers/mongodb-5.0.30/ root@hadoop2:/export/servers/
scp -r /export/servers/mongodb-5.0.30/ root@hadoop3:/export/servers/
5. 配置環境變量
分別在虛擬機hadoop1、hadoop2和hadoop3執行如下命令,向環境變量配置文件/etc/profile追加環境變量內容。配置環境變量后,需要加載環境變量配置文件/etc/profile,使用hadoop的環境變量生效。
echo >> /etc/profile
echo 'export MONGODB_HOME=/export/servers/mongodb-5.0.30' >> /etc/profile
echo 'export PATH=$PATH:$MONGODB_HOME/bin:$MONGODB_HOME/bin' >> /etc/profile
source /etc/profile
配置好環境變量后,分別在虛擬機hadoop1、hadoop2和hadoop3執行如下命令驗證環境變量是否配置成功。
mongo --version
成功如下圖所示。

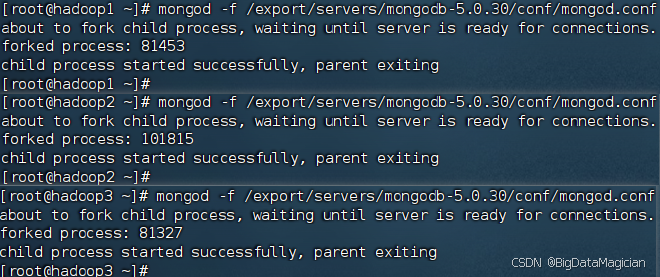
6. 啟動副本集
以副本集模式啟動MongoDB,分別在虛擬機hadoop1、hadoop2和hadoop3執行如下命令啟動MongoDB服務。
mongod -f /export/servers/mongodb-5.0.30/conf/mongod.conf
7. 進入MongoDB客戶端
在虛擬機hadoop1執行如下命令進入hadoop1的MongoDB客戶端。
mongo --host hadoop1 --port 27017
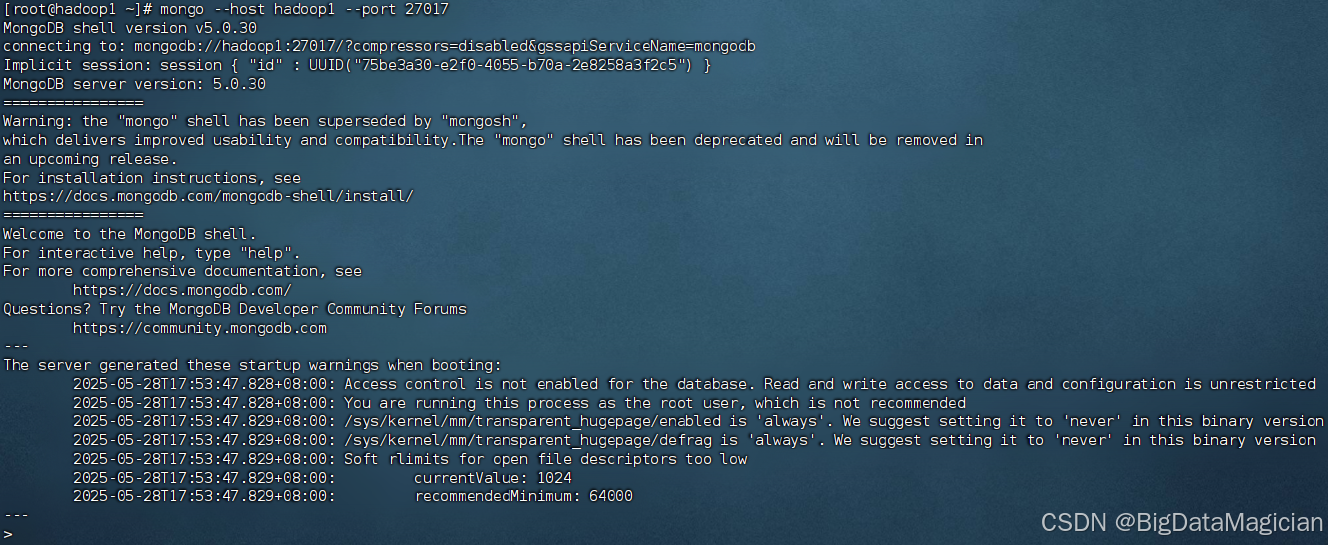
8. 初始化副本集
8.1 初始化副本集
在虛擬機hadoop1執行如下命令初始化副本集。
rs.initiate()
初始化成功如下圖所示。

完成初始化后,節點默認處于SECONDARY(副本節點)狀態,等待幾秒后自動選舉自己為PRLMARY(主節點),如下圖所示。
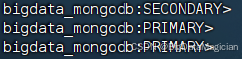
8.2 添加副本節點
在虛擬機hadoop1執行如下命令將服務器hadoop2和hadoop3以副本節點的角色添加到副本集中。
rs.add("hadoop2:27017")
rs.add("hadoop3:27017")
添加成功如下圖所示。
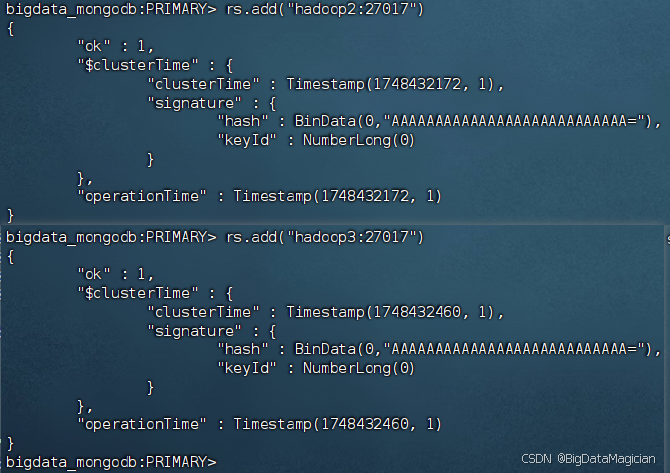
在虛擬機hadoop2執行如下命令進入hadoop2的MongoDB客戶端,查看副本集狀態。
mongo --host hadoop2 --port 27017
如下圖所示,服務器hadoop2是為SECONDARY狀態。
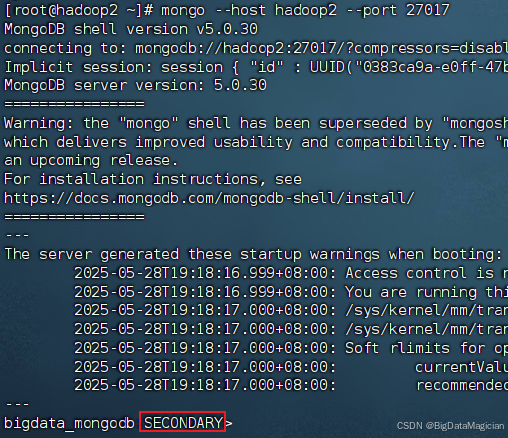
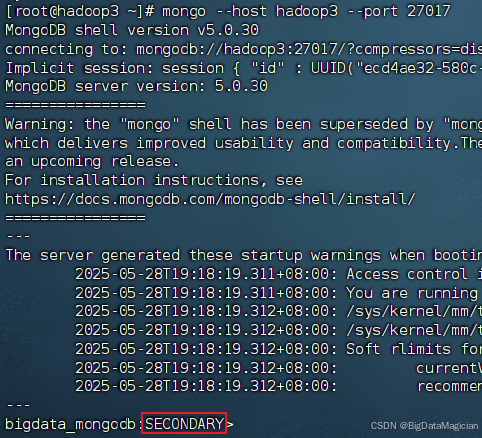
在虛擬機hadoop3執行如下命令進入hadoop3的MongoDB客戶端,查看副本集狀態。
mongo --host hadoop3 --port 27017
如下圖所示,服務器hadoop3是為SECONDARY狀態。
三、副本集操作
1. 副本集狀態介紹
以下是 MongoDB 副本集(Replica Set)狀態的詳細介紹。
| 分類 | 狀態/概念 | 說明 |
|---|---|---|
| 基本架構 | 副本集(Replica Set) | 由多個 MongoDB 節點組成的集群,實現數據冗余、高可用和故障轉移。 |
| 主節點(Primary) | 唯一可寫入的節點,處理所有寫操作,并將變更同步到從節點(Secondary)。 | |
| 從節點(Secondary) | 復制主節點數據,可用于讀操作(默認禁止,需配置 readPreference)。 | |
| 仲裁節點(Arbiter) | 不存儲數據,僅參與選舉投票,用于解決腦裂問題(奇數節點時非必需)。 | |
| 節點狀態 | PRIMARY | 主節點狀態,當前集群唯一寫入節點。 |
SECONDARY | 從節點狀態,同步主節點數據,支持只讀(需配置)。 | |
RECOVERING | 節點正在同步數據(如初次加入副本集或數據同步中),不可讀/寫。 | |
STARTUP | 節點剛啟動,正在初始化,尚未完成同步。 | |
STARTUP2 | 節點已完成初始化,正在嘗試加入副本集。 | |
DOWN | 節點不可用(如進程停止或網絡故障)。 | |
ARBITER | 仲裁節點狀態,僅參與選舉,不存儲數據。 | |
REMOVED | 節點已從副本集中移除(但可能仍存在于配置中)。 | |
| 選舉機制 | 主節點選舉(Election) | 當主節點故障時,從節點通過心跳檢測和投票機制重新選舉新主節點。 |
| 心跳(Heartbeat) | 節點間通過定期心跳(默認2秒)檢測存活狀態。 | |
| 多數派原則(Majority) | 選舉需獲得副本集多數節點(含主節點)的投票才能生效。 | |
| 數據同步 | oplog(操作日志) | 主節點記錄所有寫操作的日志,從節點通過回放 oplog 實現數據同步。 |
| 同步延遲(Replication Lag) | 從節點與主節點的數據延遲時間(正常情況下應接近0)。 | |
| 讀寫策略 | 讀偏好(Read Preference) | 控制讀請求路由到主節點或從節點,支持 primary、primaryPreferred、secondary、secondaryPreferred、nearest 等模式。 |
| 管理命令 | rs.status() | 查看副本集狀態的核心命令,返回各節點狀態、同步信息及選舉相關參數。 |
rs.initiate() | 初始化副本集配置。 | |
rs.add() | 向副本集添加節點。 | |
rs.remove() | 從副本集移除節點。 | |
| 典型場景 | 故障轉移(Failover) | 主節點故障后,從節點自動選舉新主節點,業務自動切換(需驅動支持)。 |
| 負載均衡(Read Scaling) | 將讀請求分發到從節點,減輕主節點壓力(需配置讀偏好)。 | |
| 注意事項 | 節點數量建議 | 推薦奇數個節點(如3/5/7個),避免腦裂(偶數節點需搭配仲裁節點)。 |
| 版本兼容性 | 副本集內節點版本必須一致,否則可能導致同步失敗或功能異常。 |
2. 查看副本集成員狀態
在虛擬機hadoop1執行如下命令查看副本集成員狀態。
rs.status()
返回的部分結果如下圖所示。
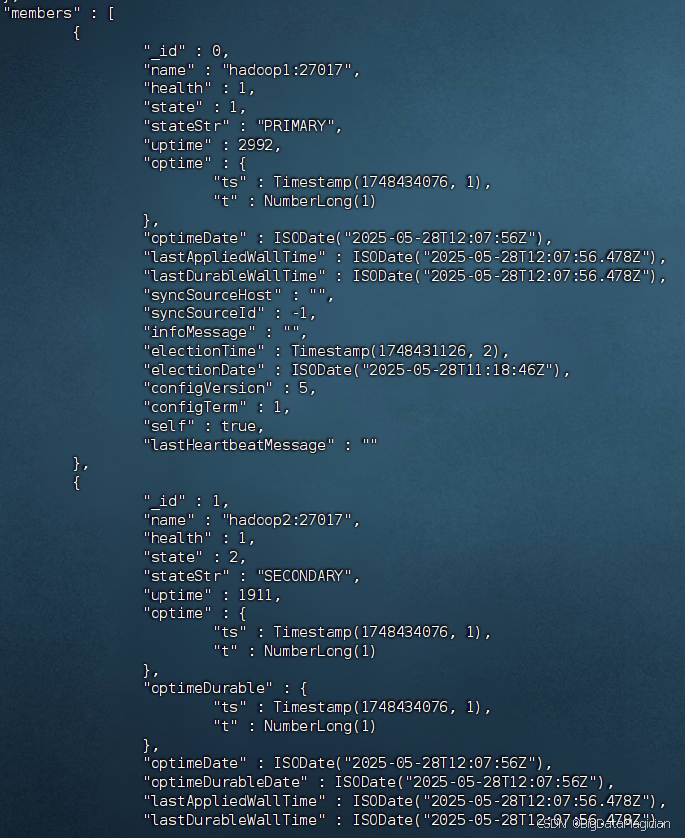
狀態碼對應關系
| 狀態碼 | 狀態字符串 | 說明 |
|---|---|---|
1 | PRIMARY | 主節點 |
2 | SECONDARY | 從節點 |
3 | RECOVERING | 數據同步中(不可用) |
5 | STARTUP | 節點啟動中 |
6 | ARBITER | 仲裁節點 |
8 | DOWN | 節點不可用 |
9 | UNKNOWN | 節點狀態未知(如網絡隔離) |
3. 數據同步
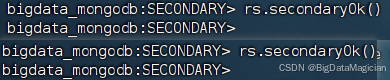
3.1 啟用數據同步
分別在虛擬機hadoop2和hadoop3的MongoDB客服端執行如下命令開啟數據同步。
rs.secondaryOk()
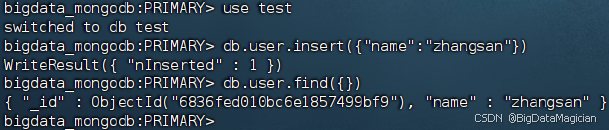
3.2 測試數據同步
在虛擬機hadoop1的MongoDB客服端執行如下命令,切換到test數據庫,并向集合user插入一個文檔。
use test
db.user.insert({"name":"zhangsan"})
db.user.find({})
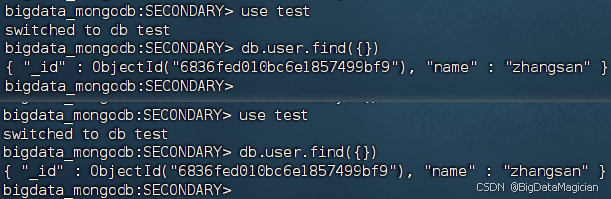
在虛擬機hadoop2和hadoop3的MongoDB客服端執行如下命令,測試數據是否已經同步,可用查詢到數據說明數據已經同步到hadoop2和hadoop3。
use test
db.user.find({})
如下圖所示。
4. 故障轉移
測試方法:終止hadoop1的MongoDB的主節點進程,查看hadoop2和hadoop3這兩個從節點是否會有一個自動轉為主節點。
4.1 終止hadoop1的MongoDB的主節點進程
查看hadoop1的MongoDB服務進程的PID。
ps -ef | grep mongodb
MongoDB服務進程的PID如下圖紅框部分所示。

關閉hadoop1的MongoDB服務進程。
kill -9 <PID>
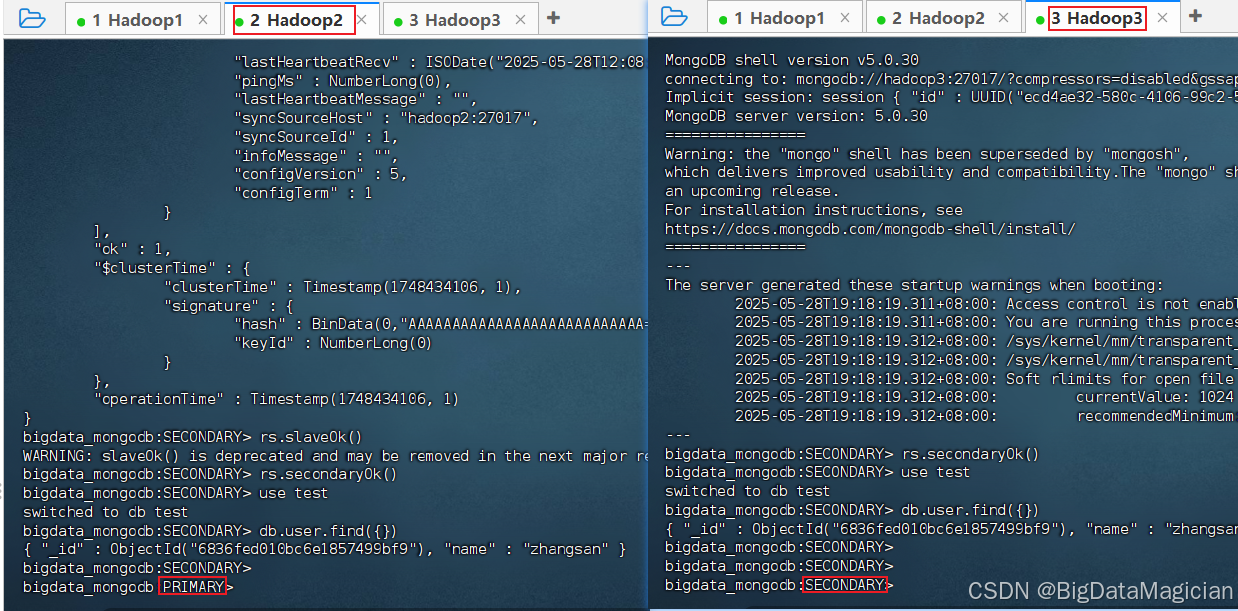
4.2 查看從節點是否有一個自動轉為主節點
如下圖所示,在hadoop2和hadoop3這兩個從節點中,hadoop2轉為了主節點。
5. 配置副本集成員
5.1 調整副本集成員的優先級
在虛擬機主節點的MongoDB客服端執行如下命令把副本集成員信息賦值到變量cfg中。
cfg=rs.conf()
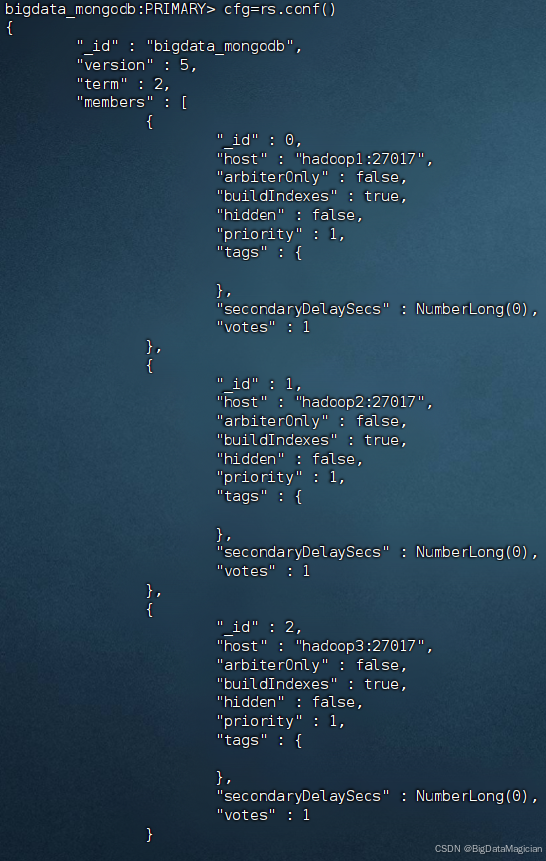
優先級越高越容易被選舉為主節點,優先級的范圍是0-100(值越大優先級越高),所有節點的優先級默認為1,優先級為0不能成為主節點。
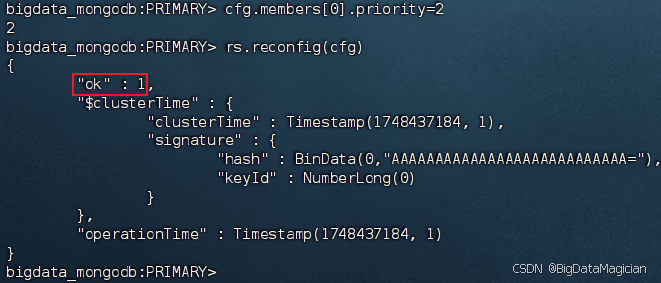
在虛擬機主節點的MongoDB客服端執行如下命令把hadoop1的優先級改為2,并將修改后的配置應用到副本集。
cfg.members[0].priority=2
rs.reconfig(cfg)
配置成功如下圖所示。
重新啟動hadoop1的MongoDB服務
在虛擬機hadoop1執行如下命令啟動MongoDB服務。
mongod -f /export/servers/mongodb-5.0.30/conf/mongod.conf
啟動完成后等待10秒,可以發現hadoop1被重新選舉成為主節點(因為hadoop1的優先級比較高),如下圖所示。
5.2 配置隱藏節點
隱藏節點是副本集中持有數據副本、對客戶端不可見、但可以參與主節點選舉和數據同步的特殊節點,可用于數據備份或離線分析等場景。
在虛擬機主節點的MongoDB客服端執行如下命令把副本集成員信息賦值到變量cfg中。
cfg=rs.conf()
在虛擬機主節點的MongoDB客服端執行如下命令把hadoop2的優先級改為0,使其不能被選舉為主節點。
cfg.members[1].priority=0

在虛擬機主節點的MongoDB客服端執行如下命令把hadoop2設置為隱藏節點。
cfg.members[1].hidden=true

在虛擬機主節點的MongoDB客服端執行如下命令將修改后的配置應用到副本集。
rs.reconfig(cfg)
5.3 配置延遲節點
延遲節點(Delayed Node)是副本集中數據落后于主節點指定時間(如1小時)的從節點,用于數據誤操作恢復、版本驗證等場景。
在虛擬機主節點的MongoDB客服端執行如下命令把副本集成員信息賦值到變量cfg中。
cfg=rs.conf()
在虛擬機主節點的MongoDB客服端執行如下命令把hadoop2的優先級改為0,使其不能被選舉為主節點。
cfg.members[1].priority=0
在虛擬機主節點的MongoDB客服端執行如下命令把hadoop2設置為延遲節點,設置延遲時間為3600秒。
cfg.members[1].secondaryDelaySecs=3600

在虛擬機主節點的MongoDB客服端執行如下命令將修改后的配置應用到副本集。
rs.reconfig(cfg)
5.4 配置副本集成員投票權
副本集成員的投票權是指成員在主節點選舉中是否具備投票資格,允許有七個擁有投票權的成員,由votes參數控制(默認值為1表示有投票權,0表示無投票權),通常用于控制選舉過程或排除特殊節點(如延遲節點、隱藏節點)參與投票。
在虛擬機主節點的MongoDB客服端執行如下命令把副本集成員信息賦值到變量cfg中。
cfg=rs.conf()
在虛擬機主節點的MongoDB客服端執行如下命令把hadoop2的投票權設置為0,使其不能參與投票。
cfg.members[1].votes=0

在虛擬機主節點的MongoDB客服端執行如下命令將修改后的配置應用到副本集。
rs.reconfig(cfg)
5.5 將副本節點轉為仲裁節點
在虛擬機主節點的MongoDB客服端執行如下命令把副本集成員信息賦值到變量cfg中。
cfg=rs.conf()
在虛擬機主節點的MongoDB客服端執行如下命令把服務器hadoop2從副本集中移除。
rs.remove("hadoop2:27017")
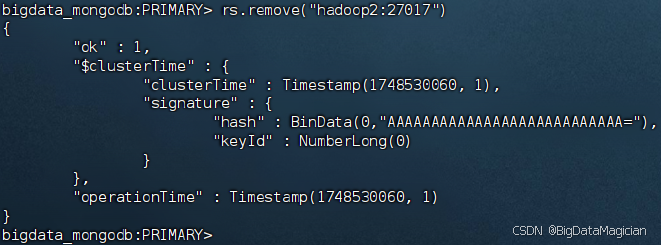
在虛擬機hadoop2上按Ctrl+C關閉MongoDB客服端,并執行如下操作關閉MongoDB服務進程。
查看hadoop2的MongoDB服務進程的PID。
ps -ef | grep mongodb
MongoDB服務進程的PID如下圖紅框部分所示。

關閉hadoop2的MongoDB服務進程。
kill -9 <PID>
在虛擬機hadoop2上執行如下命令備份MongoDB數據存放目錄。
mv /export/data/mongodb/data /export/data/mongodb/data-old
在虛擬機hadoop2上執行如下命令創建新的數據存放目錄,并重新啟動MongoDB服務。
mkdir -p /export/data/mongodb/data
mongod -f /export/servers/mongodb-5.0.30/conf/mongod.conf

在虛擬機主節點的MongoDB客服端執行如下命令以仲裁節點角色將hadoop2添加到副本集中。
rs.addArb("hadoop2:27017")





)

![[ctfshow web入門] web124](http://pic.xiahunao.cn/[ctfshow web入門] web124)




N問N答(如何繪制一個沒有背景的矩形框;如何繪制一個沒有背景的矩形框))






